
計算機視覺方向簡介 | 深度學(xué)習(xí)3D重建
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達

作者:?黃浴
https://zhuanlan.zhihu.com/p/74085115
本文已由作者授權(quán),未經(jīng)允許,不得二次轉(zhuǎn)載
最經(jīng)典的計算機視覺問題是3-D重建。基本上可以分成兩種路徑:一是多視角重建,二是運動重建。前者有一個經(jīng)典的方法是多視角立體視覺(MVS,multiple view stereo),就是多幀的立體匹配,這樣采用CNN模型來解決也合理。傳統(tǒng)MVS的方法可以分成兩種:區(qū)域增長(region growing)和深度融合(depth-fusion)。當(dāng)年CMU在美國超級碗(Superbowl)比賽展示的三維重建和視角轉(zhuǎn)化,轟動一時,就是基于此路徑,但最終沒有被產(chǎn)品化(技術(shù)已經(jīng)轉(zhuǎn)讓了)。
后者在機器人領(lǐng)域成為同步定位和制圖(SLAM)技術(shù),有濾波法和關(guān)鍵幀法兩種,后者精度高,在稀疏特征點的基礎(chǔ)上可以采用集束調(diào)整(BA,Bundle Adjustment),著名的方法如PTAM,ORB-SLAM1/2,LSD-SLAM,KinectFusion(RGB-D數(shù)據(jù)),LOAM/Velodyne SLAM(激光雷達數(shù)據(jù))等。運動恢復(fù)結(jié)構(gòu)(SFM)是基于背景不動的前提,計算機視覺的同行喜歡SFM這個術(shù)語,而機器人的同行稱之為SLAM。SLAM比較看重工程化的解決方案,SFM理論上貢獻大。
另外,視覺里程計(VO)是SLAM的一部分,其實只是估計自身運動和姿態(tài)變化。VO是David Nister創(chuàng)立的概念,之前以兩幀圖像計算Essential Matrix的“5點算法”而為人所知。
因為CNN已經(jīng)在特征匹配、運動估計和立體匹配得到應(yīng)用,這樣在SLAM/SFM/VO/MVS的應(yīng)用探索也就成了必然。
? DeepVO
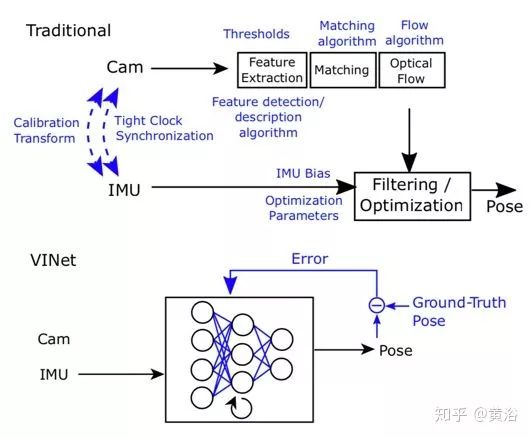
如圖所示,經(jīng)典VO流水線通常包括攝像機標(biāo)定、特征檢測、特征匹配(或跟蹤)、異常值拒絕(例如RANSAC)、運動估計、尺度估計和局部優(yōu)化(集束調(diào)整,BA)。
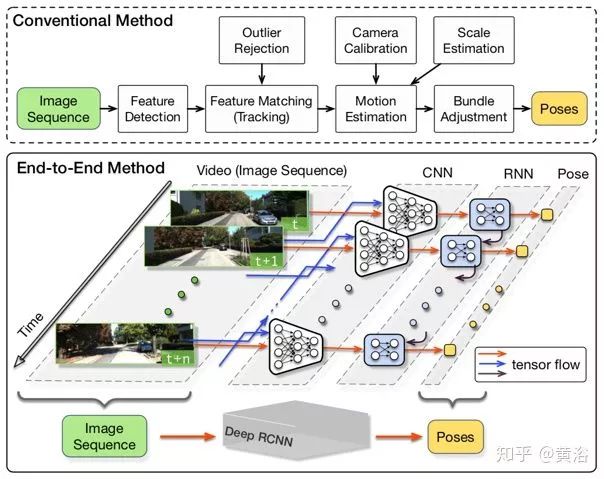
DeepVO基于深度遞歸卷積神經(jīng)網(wǎng)絡(luò)(RCNN)提出了一種端到端單目視覺里程計(VO)框架。由于以端到端的方式進行訓(xùn)練和部署,因此它直接從一系列原始RGB圖像(視頻)中推斷出姿態(tài),而不采用傳統(tǒng)VO流水線中的任何模塊。基于RCNN,它不僅通過CNN自動學(xué)習(xí)VO問題的有效特征表示,而且用深度遞歸神經(jīng)網(wǎng)絡(luò)隱式地建模串聯(lián)動力學(xué)和關(guān)系。
如圖所示是這個端到端VO系統(tǒng)的架構(gòu)圖:采用視頻片段或單目圖像序列作為輸入;在每個時間步,作為RGB圖像幀預(yù)處理,減去訓(xùn)練集的平均RGB值,可以將圖像尺寸調(diào)整為64的倍數(shù);將兩個連續(xù)圖像堆疊在一起以形成深RCNN的張量,學(xué)習(xí)如何提取運動信息和估計姿勢。具體地,圖像張量被饋送到CNN以產(chǎn)生單目VO的有效特征,然后通過RNN進行串行學(xué)習(xí)。每個圖像對在網(wǎng)絡(luò)的每個時間步產(chǎn)生姿勢估計。VO系統(tǒng)隨時間推移而發(fā)展,并在圖像獲取時估計新的姿勢。
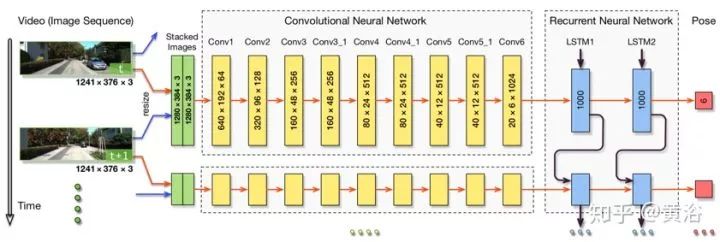
CNN具有9個卷積層,每層之后是除Conv6之外的ReLU激活,總共17層。網(wǎng)絡(luò)中感受野的大小逐漸從7×7減少到5×5,然后逐漸減少到3×3,以捕捉小的有趣特征。引入零填充以適應(yīng)感受野的配置或在卷積之后保持張量的空間維度。其中通道的數(shù)量,即用于特征檢測的濾波器的數(shù)量,會增加以學(xué)習(xí)各種特征。
通過堆疊兩個LSTM層來構(gòu)造深度RNN,其中LSTM的隱藏狀態(tài)是另一個的輸入。在DeepVO網(wǎng)絡(luò)中,每個LSTM層具有1000個隱藏狀態(tài)。深度RNN基于從CNN生成的視覺特征在每個時間步輸出姿勢估計。隨著相機移動并獲取圖像,這個進程隨時間而繼續(xù)。
? UnDeepVO
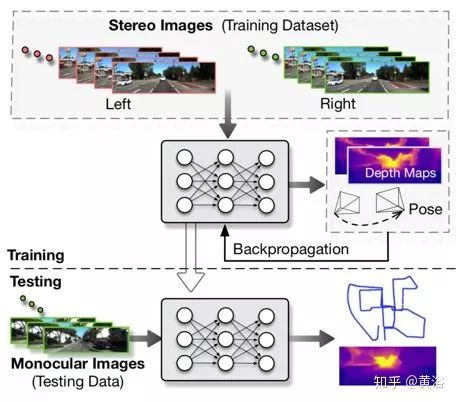
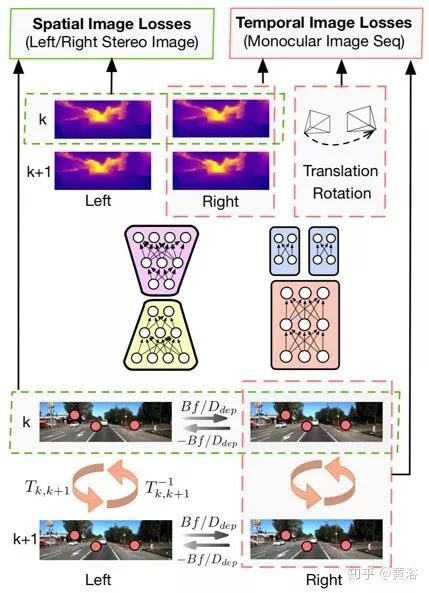
UnDeepVO能夠通過使用深度神經(jīng)網(wǎng)絡(luò)估計單目相機的6-DoF姿勢及其視野的深度。有兩個顯著特征:一個是無監(jiān)督深度學(xué)習(xí)方案,另一個是絕對的深度恢復(fù)。訓(xùn)練UnDeepVO時,通過使用立體圖像對恢復(fù)尺度來,但測試時,使用連續(xù)的單眼圖像。UnDeepVO還是一個單目系統(tǒng)。網(wǎng)絡(luò)訓(xùn)練的損失函數(shù)基于時空密集信息,如圖所示。
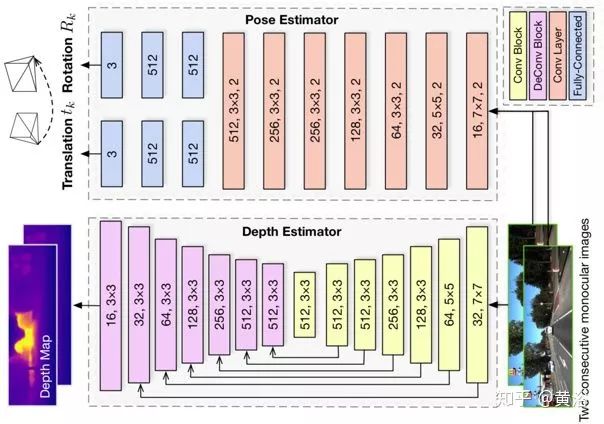
下圖所示時UnDeepVO的架構(gòu)圖。姿勢估計器是基于VGG的CNN架構(gòu),需要兩個連續(xù)的單目圖像作為輸入,并預(yù)測它們之間的6-自由度(DoF)變換矩陣。由于旋轉(zhuǎn)(由歐拉角表示)具有高度非線性,與平移相比通常難以訓(xùn)練。對于有監(jiān)督的訓(xùn)練,一種流行的解決方案是將旋轉(zhuǎn)估計損失給予更大的權(quán)重,如同歸一化。為了更好地?zé)o監(jiān)督學(xué)習(xí)訓(xùn)練旋轉(zhuǎn)預(yù)測,在最后一個卷積層之后用兩組獨立的全連接層將平移和旋轉(zhuǎn)分離。這樣為獲得更好的性能,引入一個權(quán)重標(biāo)準(zhǔn)化的旋轉(zhuǎn)預(yù)測和平移預(yù)測。深度估計器主要基于編碼器-解碼器架構(gòu)以生成致密深度圖。與其他方法不同的是, UnDeepVO直接預(yù)測深度圖,這是因為以這種方式訓(xùn)練時整個系統(tǒng)更容易收斂。
如圖所示,用立體圖像序列的時空幾何一致性來定義損失函數(shù)。空間幾何一致性表示左右圖像對中的對應(yīng)點之間的外極線約束,而時間幾何一致性表示兩個連續(xù)單目圖像中的對應(yīng)點之間的幾何投影約束。這些約束構(gòu)造最后的損失函數(shù)并使其最小化,而UnDeepVO學(xué)習(xí)端對端無監(jiān)督方式估計尺度化的6-DoF姿勢和深度圖。簡單提一下,空間損失函數(shù)包括光度一致性損失(Photometric Consistency Loss)、視差一致性損失(Disparity Consistency Loss)和姿態(tài)一致性損失(Pose Consistency Loss);時間損失函數(shù)包括光度一致性損失和3-D幾何校準(zhǔn)損失(3D Geometric Registration Loss)。
? VINet
如圖是比較傳統(tǒng)VIO(visual-inertial odometry)和基于深度學(xué)習(xí)的VINet方法。VINet時一種使用視覺和慣性傳感器進行運動估計的流形(on-manifold)序列到序列的學(xué)習(xí)方法。其優(yōu)點在于:消除相機和IMU之間繁瑣的手動同步,無需手動校準(zhǔn);模型自然地結(jié)合特定領(lǐng)域信息,顯著地減輕漂移。
VINet的架構(gòu)圖見下圖所示。該模型包括CNN-RNN網(wǎng)絡(luò),為VIO任務(wù)量身定制。整個網(wǎng)絡(luò)是可微分的,可以進行端到端訓(xùn)練實現(xiàn)運動估計。網(wǎng)絡(luò)的輸入是單目RGB圖像和IMU數(shù)據(jù),即一個6維向量,包含陀螺儀測量的加速度和角速度的x,y,z分量。網(wǎng)絡(luò)輸出是7維向量 - 3維平移和4維四元數(shù)(quaternion)- 姿勢變化。從本質(zhì)上講,它學(xué)習(xí)將圖像和IMU數(shù)據(jù)的輸入序列轉(zhuǎn)換為姿勢的映射。
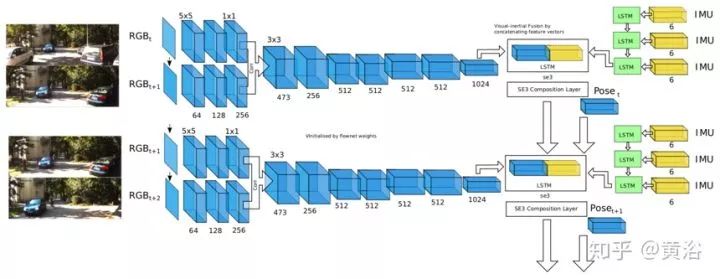
CNN-RNN網(wǎng)絡(luò)執(zhí)行從輸入數(shù)據(jù)到李代數(shù)se(3)的映射。指數(shù)圖將它們轉(zhuǎn)換為特殊的歐幾里德群SE(3),然后可以在SE(3)中組成各個運動以形成軌跡。這樣,網(wǎng)絡(luò)需要近似的功能仍然隨著時間的推移保持受限,因為相機幀到幀的運動是由平臺在軌跡過程中復(fù)雜動力學(xué)定義的。借助RNN模型,網(wǎng)絡(luò)可以學(xué)習(xí)平臺的復(fù)雜運動動力學(xué),并考慮到那些難以手工建模的序列依賴性。下圖是其中SE(3) 級聯(lián)層(composition layer)的示意圖:無參數(shù)層,主要連接SE(3)群上幀之間的變換。
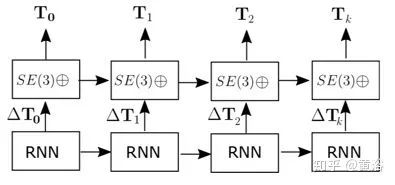
在LSTM模型中,隱藏狀態(tài)被轉(zhuǎn)移到下一個時間步,但輸出本身不會反饋到輸入。在里程計情況下,先前狀態(tài)的可用性特別重要,因為輸出基本上是每步增量位移的累積。因此,直接連接SE(3)級聯(lián)層產(chǎn)生的姿態(tài)輸出,作為下個時間步核心LSTM的輸入。
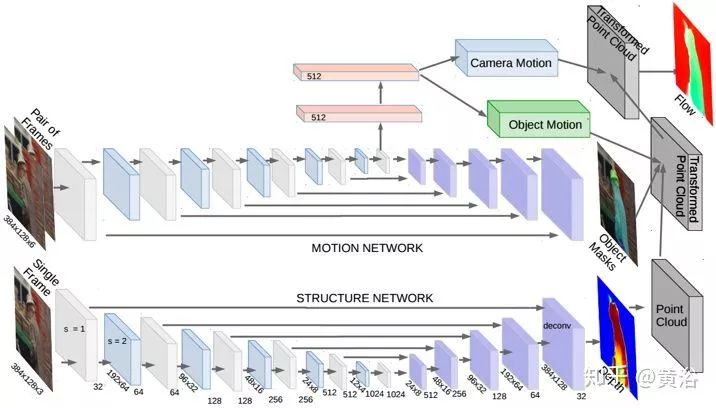
? SfM-Net
SfM-Net是一種用于視頻運動估計幾何覺察的神經(jīng)網(wǎng)絡(luò),根據(jù)場景、目標(biāo)深度、相機運動、3D目標(biāo)旋轉(zhuǎn)和平移等來分解幀像素運動。給定一圖像幀序列,SfM-Net預(yù)測深度、分割、相機和剛體運動,并轉(zhuǎn)換為密集的幀到幀運動場(光流),可以及時地對幀進行差分變形以匹配像素和反向傳播。該模型可以通過不同程度的監(jiān)督進行訓(xùn)練:1)通過重投影光度誤差(完全無監(jiān)督)自我監(jiān)督訓(xùn)練,2)自身運動(攝像機運動)監(jiān)督訓(xùn)練,或3)由深度圖(例如,RGBD傳感器)監(jiān)督訓(xùn)練。
下圖是SfM-Net的流程圖。給定一對圖像幀作為輸入,模型將幀到幀像素運動分解為3D場景深度、3D攝像機旋轉(zhuǎn)和平移、一組運動掩碼和相應(yīng)的3D剛性旋轉(zhuǎn)和平移運動。然后,將得到的3D場景流反投影到2D光流中并相應(yīng)地變形完成從這幀到下一幀的匹配像素。其中前向一致性檢查會約束估計的深度值。
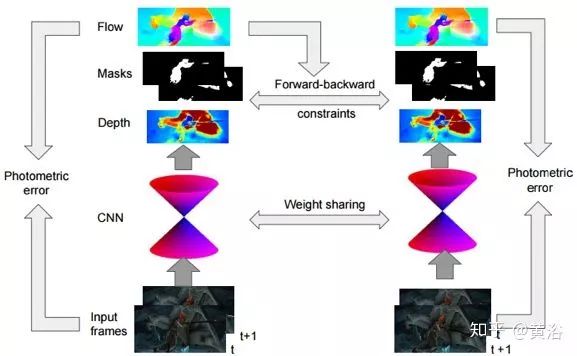
如下圖是SfM-Net的架構(gòu)圖:對于每對連續(xù)幀It,It+1,一個conv / deconv子網(wǎng)絡(luò)能預(yù)測深度dt,而另一個conv / deconv子網(wǎng)絡(luò)預(yù)測一組K個分割掩碼mt;運動掩碼編碼器的最粗特征圖通過全連接層進一步解碼,輸出攝像機和K個分割的3D旋轉(zhuǎn)和平移;使用估計的或已知的相機內(nèi)參數(shù)將預(yù)測的深度轉(zhuǎn)換為每幀點云;然后,根據(jù)預(yù)測的3D場景流(scene flow)對其進行變換,由3D攝像機運動和獨立的3D掩碼運動組成;將變換后的3D深度再投射回2D的下一圖像幀,從而提供相應(yīng)的2D光流場;可差分后向變形映射將圖像幀It+1到It,并且梯度可基于像素誤差來計算;對逆圖像幀對It+1,It重復(fù)該過程來強加“前向-后向約束”,并且通過估計的場景運動約束深度dt和dt+1保持一致性。
如圖是一些SfM-Net結(jié)果例子。在KITTI 2015,基礎(chǔ)事實的分割和光流與SfM-Net預(yù)測的運動掩碼和光流相比。模型以完全無監(jiān)督的方式進行訓(xùn)練。

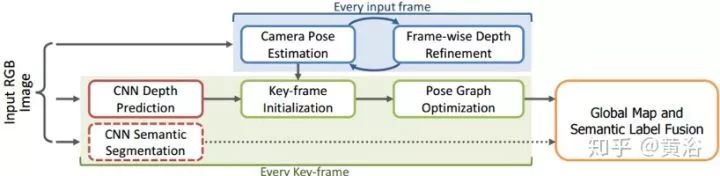
? CNN-SLAM
借助于CNN的深度圖預(yù)測方法,CNN-SLAM可以用于精確和密集的單目圖像重建。CNN預(yù)測的致密深度圖和單目SLAM直接獲得的深度結(jié)果融合在一起。在單目SLAM接近失敗的圖像位置例如低紋理區(qū)域,其融合方案對深度預(yù)測賦予特權(quán),反之亦然。深度預(yù)測可以估計重建的絕對尺度,克服單目SLAM的一個主要局限。最后,從單幀獲得的語義標(biāo)簽和致密SLAM融合,可得到語義連貫的單視圖場景重建結(jié)果。
如圖是CNN-SLAM的架構(gòu)圖。CNN-SLAM采用基于關(guān)鍵幀的SLAM范例,特別是直接半致密(direct semi-dense)法作為基準(zhǔn)。這種方法將不同視覺幀收集作為關(guān)鍵幀,其姿態(tài)經(jīng)過基于姿態(tài)圖(pose-graph)的優(yōu)化方法全局修正。同時,通過幀與其最近的關(guān)鍵幀之間的變換估計,實現(xiàn)每個輸入幀的姿態(tài)估計。
下面是一些結(jié)果:辦公室場景(左)和NYU Depth V2數(shù)據(jù)集的兩個廚房場景(中,右),第一行是重建,第二行是語義標(biāo)簽。

? PoseNet
PoseNet是一個實時單目6 DOF重定位系統(tǒng)。它訓(xùn)練CNN模型以端映端方式從RGB圖像回歸6-DOF相機姿態(tài),無需額外的工程或圖形優(yōu)化。該算法可以在室內(nèi)和室外實時運行,每幀5ms。通過一個有效的23層深度卷積網(wǎng)絡(luò),PoseNet實現(xiàn)圖像平面的回歸,對于那些照明差、運動模糊并具有不同內(nèi)參數(shù)的攝像頭(其中SIFT校準(zhǔn)失敗)場景算法魯棒。產(chǎn)生的姿勢特征可推廣到其他場景,僅用幾十個訓(xùn)練樣例就可以回歸姿態(tài)參數(shù)。
PoseNet使用GoogLeNet作為姿態(tài)回歸網(wǎng)絡(luò)的基礎(chǔ);用仿射回歸器替換所有3個softmax分類器;移除softmax層,并修改每個最終全聯(lián)接層輸出表示3-D位置(3)和朝向四元數(shù)(4)的7維姿態(tài)向量;在特征大小為2048的最終回歸器之前插入另一個全聯(lián)接層;在測試時,將四元數(shù)朝向矢量單位歸一化。
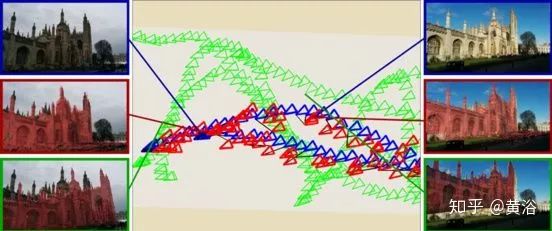
如圖是PoseNet的結(jié)果展示。綠色是訓(xùn)練示例,藍色是測試示例和紅色顯示姿勢預(yù)測。
需要補充一下,姿勢回歸采用以下目標(biāo)損失函數(shù)的隨機梯度下降來訓(xùn)練:
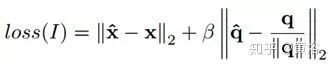
其中x是位置向量,q是四元數(shù)向量,β是選擇的比例因子,以保持位置和朝向誤差的預(yù)期值近似相等。
? VidLoc
VidLoc是一種用于視頻片段6-DoF定位的遞歸卷積模型。即使僅考慮短序列(20幀),它也可以平滑姿態(tài)的估計并且可以大大減少定位誤差。
如圖是VidLoc的架構(gòu)模型。CNN部分的目標(biāo)是從輸入圖像中提取相關(guān)的特征,這些特征可用于預(yù)測圖像的全局姿態(tài)。CNN由堆疊的卷積和池化層構(gòu)成,對輸入圖像操作。這里主要處理時間順序的多個圖像,采用VidLoc CNN的GoogleNet架構(gòu),其實只使用GoogleNet的卷積層和池化層,并刪除所有全連接層。
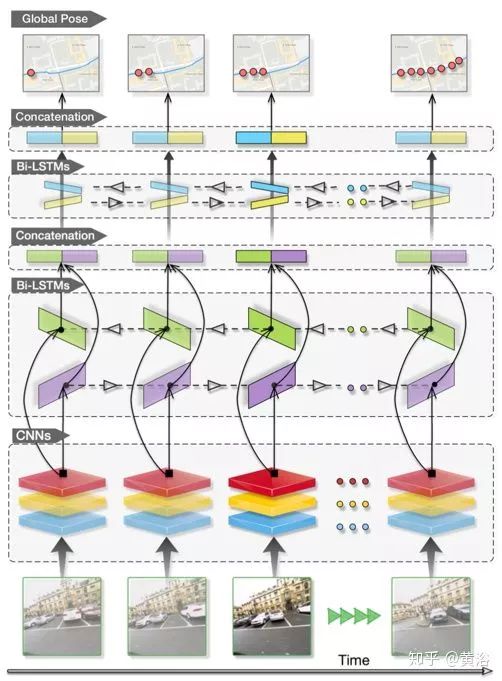
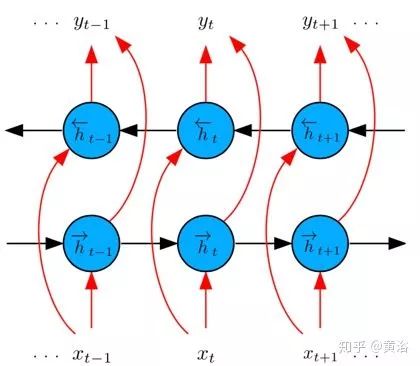
當(dāng)輸入連續(xù)時間的圖像流時,利用時間規(guī)律性可以獲得大量的姿態(tài)信息。例如,相鄰圖像通常包含相同目標(biāo)的視圖,這可以提高特定位置的置信度,并且?guī)g的運動也存在嚴(yán)格約束。為捕獲這些動態(tài)相關(guān)性,在網(wǎng)絡(luò)中使用LSTM模型。LSTM擴展了標(biāo)準(zhǔn)RNN,能夠?qū)W習(xí)長期時間依賴性,是通過遺忘門、輸入和輸出復(fù)位門以及存儲器單元來實現(xiàn)的。進出存儲器單元的信息流由遺忘門和輸入門調(diào)節(jié),這允許網(wǎng)絡(luò)在訓(xùn)練期間克服梯度消失問題,能夠?qū)W習(xí)長期的相關(guān)性。LSTM輸入是CNN輸出,由一系列特征向量xt組成。LSTM將輸入序列映射到輸出序列,輸出序列參數(shù)化為7維向量的全局姿態(tài)組成yt,包括平移向量和朝向四元數(shù)。為充分利用時間連續(xù)性,這里L(fēng)STM模型采用雙向結(jié)構(gòu),如圖所示。
為了模擬姿態(tài)估計的不確定性,采用混合密度網(wǎng)絡(luò)(mixture density networks)方法。這種方法用混合模型取代了高斯模型,可以對多模態(tài)后驗輸出分布建模。
? NetVLAD
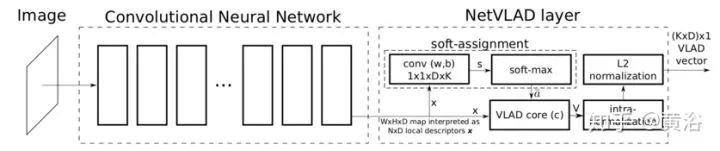
大規(guī)模基于視覺的位置識別問題要求快速準(zhǔn)確地識別給定查詢照片的位置。NetVLAD是一種CNN架構(gòu)中的一層,幫助整個架構(gòu)直接以端到端的方式用于位置識別。其主要組成部分是一個通用“局部聚合描述子向量”(VLAD,Vector of Locally Aggregated Descriptors)層,受到圖像檢索中特征描述子池化法VLAD的啟發(fā)。該層可以很容易地插入任何CNN架構(gòu)中,并且可以通過反向傳播(BP)進行訓(xùn)練。根據(jù)一個定義的弱監(jiān)督排名損失(ranking loss)可以訓(xùn)練從谷歌街景時間機(Google Street View Time Machine)下載的相同位置的圖像,以端到端的方式學(xué)習(xí)該架構(gòu)參數(shù)。
如圖是帶NetVLAD層的CNN結(jié)構(gòu)。該層用標(biāo)準(zhǔn)CNN層(卷積,softmax,L2歸一化)和一個易于實現(xiàn)的聚合層NetVLAD來實現(xiàn)“VLAD核”聚合,可在有向無環(huán)圖(DCG)中連接。
給定N個D-維局部圖像特征描述符{xi}作為輸入,將K個聚類中心(“視覺詞”){ck}作為VLAD參數(shù),輸出VLAD圖像表示V是K×D維矩陣。該矩陣可轉(zhuǎn)換為矢量,歸一化后可作為圖像表示。V的(j,k)元素計算如下:
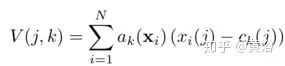
其中xi(j)和ck(j)分別是第i個特征描述符和第k個聚類中心的第j維。ak(xi)將描述符xi的成員資格記錄為第k個視覺單詞,即如果集群ck是最接近解釋xi的集群則為1,否則為0。
VLAD的不連續(xù)性源來自描述符xi到聚類中心ck的硬分布ak(xi)。為了使之可微分,將其替換為描述子的多個聚類軟分配,即
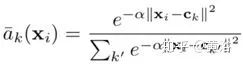
將上式的平方項展開,很容易看出exp()項在分子和分母之間消掉,導(dǎo)致如下軟分配
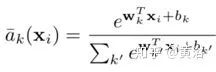
其中向量wk和標(biāo)量bk
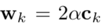
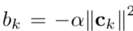
這樣最終的“VLAD核”聚合公式變成
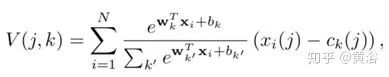
其中{wk},{bk}和{ck}是每個群集k的可訓(xùn)練參數(shù)集。
在VLAD編碼,來自不同圖像但劃歸同一聚類的兩個特征描述子對兩個圖像之間相似性測度的貢獻是殘差向量之間的標(biāo)量積,其中殘差向量是描述符與聚類錨點(anchor point)之間的差。錨點ck可以被解釋為特定聚類k的新坐標(biāo)系原點。在標(biāo)準(zhǔn)VLAD中,錨點被選為聚類中心(×),以便數(shù)據(jù)庫中的殘差均勻分布。然而如圖所示,在監(jiān)督學(xué)習(xí)設(shè)置中,來自不匹配圖像的兩個描述子可以學(xué)習(xí)更好的錨點,使新殘差向量之間的標(biāo)量積很小。
? Learned Stereo Machine
伯克利分校提出的一個用于多視角立體視覺的深度學(xué)習(xí)系統(tǒng),即學(xué)習(xí)立體視覺機(LSM)。與最近其他一些基于學(xué)習(xí)的3D重建方法相比,沿著觀察光線做特征投影和反投影,它利用了問題的基礎(chǔ)3D幾何關(guān)系。通過可微分地定義這些操作,能夠端到端地學(xué)習(xí)用于量度3D重建任務(wù)的系統(tǒng)。這種端到端學(xué)習(xí)能夠在符合幾何約束的同時共同推理形狀的先驗知識,能夠比傳統(tǒng)方法需要更少的圖像(甚至單個圖像)進行重建以及完成看不見的表面。
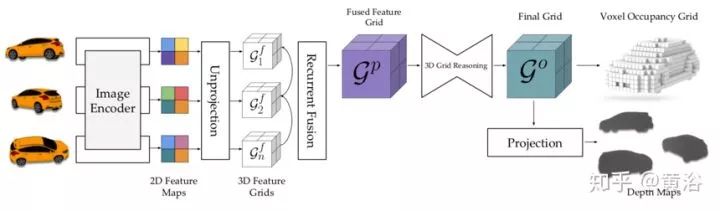
如圖是LSM概述:一個或多個視圖和攝像頭姿態(tài)作為輸入;通過特征編碼器處理圖像,然后使用可微分的反投影操作將其投影到3D世界坐標(biāo)系中。
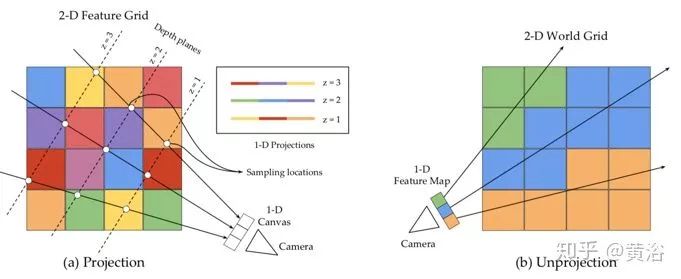
如圖給出1D圖和2D網(wǎng)格之間的投影和反投影示意圖。(a)投影操作沿光線以等間隔z值采樣值到1D圖像中。在z平面的采樣特征堆疊成通道形成投影的特征圖。(b)反投影操作從特征圖(1-D)中獲取特征,并沿光線放置在相應(yīng)與之相交的網(wǎng)格塊。
然后,以遞歸方式匹配這些網(wǎng)格G以產(chǎn)生融合網(wǎng)格Gp,這里采用的是門控遞歸單元(GRU)模型。接著,通過3D CNN將其轉(zhuǎn)換為Go。最后,LSM可以產(chǎn)生兩種輸出 - 從Go解碼的體素占有網(wǎng)格(體素 LSM)或在投影操作之后解碼的每視角的深度圖(深度LSM)。
下圖給出V-LSM的一些結(jié)果,


如圖給出D-LSM的一些例子。

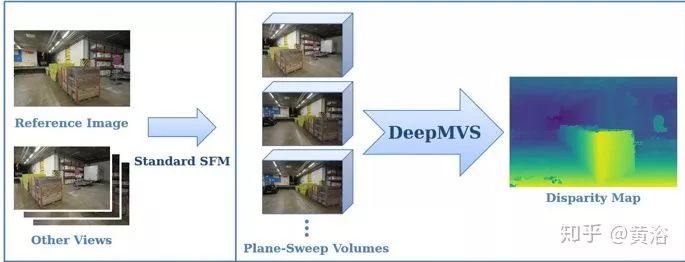
? DeepMVS
DeepMVS是一種用于多視角立體視覺(MVS)重建的深度卷積神經(jīng)網(wǎng)絡(luò)(ConvNet)。將任意數(shù)量各種姿態(tài)的圖像作為輸入,首先產(chǎn)生一組平面掃描體積(plane-sweep volumes),并使用DeepMVS網(wǎng)絡(luò)來預(yù)測高質(zhì)量的視差圖。其關(guān)鍵特點是(1)在照片級真實感的合成數(shù)據(jù)集上進行預(yù)訓(xùn)練;(2)在一組無序圖像上聚合信息的有效方法;(3)在預(yù)訓(xùn)練的VGG-19網(wǎng)絡(luò)集成多層特征激活函數(shù)。使用ETH3D基準(zhǔn)驗證了DeepMVS的功效。
算法流程分四步。首先,預(yù)處理輸入圖像序列,然后生成平面掃描容積(plane-sweep volumes)。接著,網(wǎng)絡(luò)估計平面掃描容積的視差圖,最后細化結(jié)果。如圖所示。
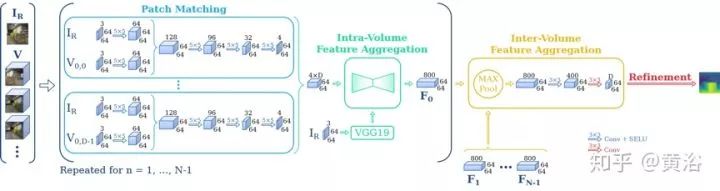
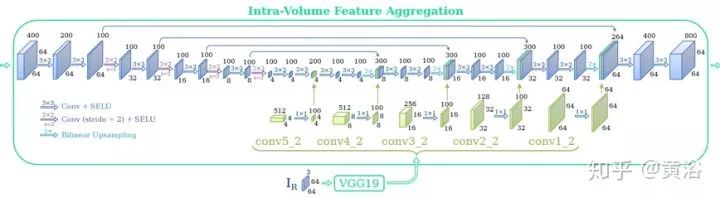
下面兩個圖分別顯示帶超參數(shù)的DeepMVS體系結(jié)構(gòu)。整個網(wǎng)絡(luò)分三部分:1)補丁匹配(patch matching)網(wǎng)絡(luò),2)容積內(nèi)特征聚合(intra volume feature aggregation)網(wǎng)絡(luò),3)容積之間特征聚合(inter volume feature aggregation)網(wǎng)絡(luò)。除了最后一層,網(wǎng)絡(luò)中所有卷積層都跟著一個可縮放指數(shù)線性單元(Scaled Exponential Linear Unit ,SELU)層。
為了進一步改進性能,將全連通條件隨機場(DenseCRF)應(yīng)用到視差預(yù)測結(jié)果。
? MVSNet
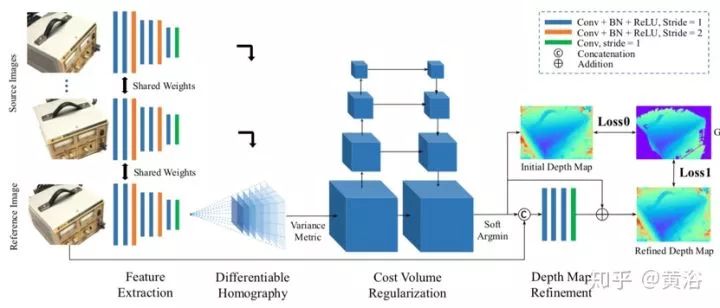
給定參考圖像I1和一組其相鄰圖像{Ii} Ni = 2,MVSNet提出了一種端到端深度神經(jīng)網(wǎng)絡(luò)來推斷參考深度圖D。在其網(wǎng)絡(luò)中,首先通過2D網(wǎng)絡(luò)從輸入圖像中提取深度圖像特征{ Fi} Ni = 1。然后,通過可微分的單應(yīng)性(Homography)變換將2D圖像特征變形到參考相機坐標(biāo)系,這樣在3D空間中構(gòu)建特征容積{Vi} Ni = 1。為了處理任意N視角圖像輸入,基于方差的成本測度將N個特征容積映射到一個成本容積C。與其他立體視覺和MVS算法類似,MVSNet使用多尺度3D CNN正則化成本容積,并通過軟argmin 操作回歸參考深度圖D。在MVSNet末端應(yīng)用一個細化網(wǎng)絡(luò)進一步增強預(yù)測深度圖的性能。由于在特征提取期間縮小了深度圖像特征{Fi} Ni = 1,因此輸出深度圖大小是每個維度中原始圖像大小的1/4。
MVSNet在DTU數(shù)據(jù)集以及Tanks and Temples數(shù)據(jù)集的中間集展示了最先進的性能,其中包含具有“從外看里”的攝像頭軌跡和小深度范圍的場景。但是,用16 GB內(nèi)存 Tesla P100 GPU卡,MVSNet只能處理H×W×D = 1600×1184×256的最大重建尺度,并且會在較大的場景中失敗,即Tanks and Temples的高級集合。
如圖是MVSNet網(wǎng)絡(luò)設(shè)計圖。輸入圖像通過2D特征提取網(wǎng)絡(luò)和可微分單應(yīng)性變形生成成本容積。從正則化的概率容積回歸最終的深度圖輸出,并且用參考圖像細化。
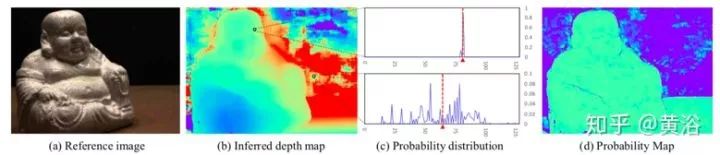
下圖是推斷的深度圖、概率分布和概率圖。(a)DTU數(shù)據(jù)集的一個參考圖像; (b)推斷的深度圖; (c)內(nèi)點像素(頂部)和出格點像素(底部)的概率分布,其中x軸是深度假設(shè)索引,y軸是概率,紅色線是軟argmin結(jié)果; (d)概率圖。
? Recurrent MVSNet
MVS方法的一個主要限制是可擴展性:耗費內(nèi)存的成本容積(cost volume)正則化使得學(xué)習(xí)的MVS難以應(yīng)用于高分辨率場景。Recurrent MVSNet是一種基于遞歸神經(jīng)網(wǎng)絡(luò)的可擴展多視角立體視覺框架。遞歸多視角立體視覺網(wǎng)絡(luò)(R-MVSNet)不是一次性正則化整個3-D成本容積,而是通過門控遞歸單元(GRU)網(wǎng)絡(luò)串行地沿深度值方向正則化2-D成本圖。這大大減少了內(nèi)存消耗,并使高分辨率重建成為可能。
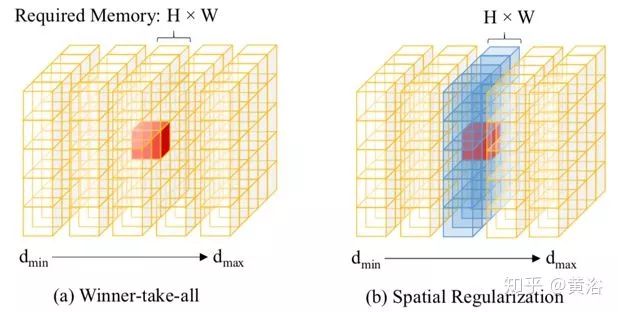
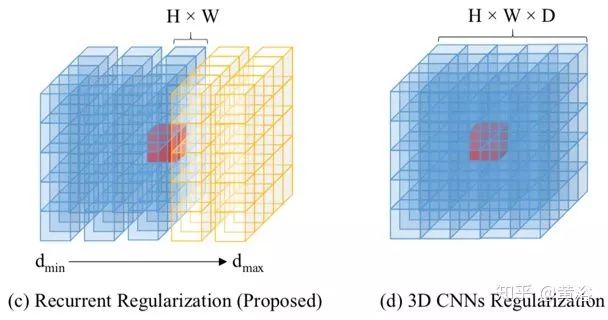
下圖比較了不同正則化方案的策略。一次性全局正則化成本容積C的替代方案是串行地沿深度方向處理成本容積。最簡單的順序方法是贏家通吃(WTA)的平面掃描(plane sweeping)立體視覺法,它粗略地用較好的值替換逐像素深度值,因此受到噪聲的影響(如圖(a))。為此,成本聚合法過濾不同深度的匹配成本容積C(d)(如圖(b)),以便收集每個成本估算的空間上下文信息。遵循串行處理的思想,這里采用一種基于卷積GRU的更強大的遞歸正則化方案。該方法能夠在深度方向上收集空間和單向上下文信息(如圖(c)),與全空間3D CNN(如圖(d))相比,這實現(xiàn)了差不多的正則化結(jié)果,但是 運行時內(nèi)存更加有效。
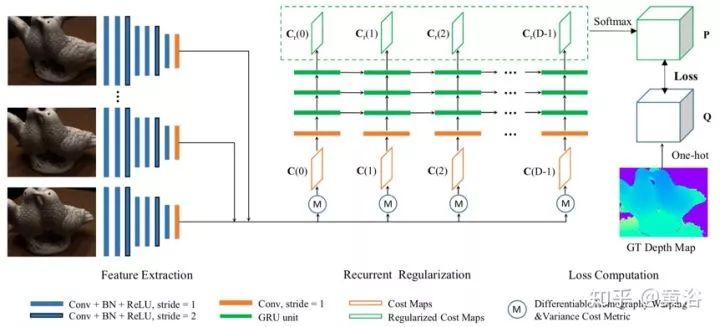
下圖是R-MVSNet的框圖介紹。從輸入圖像中提取深度圖像特征,然后將其變形到參考相機坐標(biāo)系的前向平行平面。在不同深度處計算成本圖并由卷積GRU串行地正則化處理。網(wǎng)絡(luò)被訓(xùn)練為具有交叉熵(cross-entropy)損失的分類問題。
如圖是R-MVSNet的重建流水線直觀圖:(a)DTU圖像;(b)來自網(wǎng)絡(luò)的初始深度圖;(c)最終深度圖估計;(d)基礎(chǔ)事實深度圖;(e)輸出點云;(f)深度圖濾波的概率估計圖;(g)初始深度圖的梯度圖;(h)細化后的梯度圖。

參考文獻
1. Kendall A, Grimes M, Cipolla R. “Posenet: A convolutional network for real-time 6-dof camera relocalization”,IEEE ICCV. 2015
2. Li X, Belaroussi R. “Semi-Dense 3D Semantic Mapping from Monocular SLAM”. arXiv 1611.04144, 2016.
3. J McCormac et al. “SemanticFusion: Dense 3D semantic mapping with convolutional neural networks”. arXiv 1609.05130, 2016
4. R Arandjelovic et al. “NetVLAD: CNN architecture for weakly supervised place recognition”, CVPR 2016
5. B Ummenhofer et al., "DeMoN: Depth and Motion Network for Learning Monocular Stereo", CVPR 2017
6. R Li et al. “UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning”. arXiv 1709.06841, 2017.
7. S Wang et al.,“DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks”, arXiv 1709.08429, 2017
8. R Clark et al. "VidLoc: 6-doF video-clip relocalization". arXiv 1702.06521,2017
9. R Clark et al. "VINet: Visual-Inertial Odometry as a Sequence-to-Sequence Learning Problem." AAAI. 2017
10. D DeTone, T Malisiewicz, A Rabinovich. “Toward Geometric Deep SLAM”. ?arXiv 1707.07410, 2017.
11. S Vijayanarasimhan et al.,“SfM-Net: Learning of Structure and Motion from Video”, arXiv 1704.07804, 2017
12. K Tateno K et al. “CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction”. ?arXiv 1704.03489, 2017.
13. J Zhang et al. “Neural SLAM : Learning to Explore with External Memory”,arXiv 1706.09520, 2017
14. Wu J, Ma L, Hu X. “Delving deeper into convolutional neural networks for camera relocalization”,IEEE ICRA, 2017
15. A Kar, C Haene, J Malik, “Learned Stereo Machine”, NIPS, 2017
16. P Huang et al.,“DeepMVS: Learning Multi-view Stereopsis”, CVPR 2018
17. Y. Yao et al., “Mvsnet: Depth inference for unstructured multi-view stereo”. ECCV, 2018.
18. Y Yao et al.,“Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference”, CVPR 2019
19. G Zhai et al.,“PoseConvGRU: A Monocular Approach for Visual Ego-motion Estimation by Learning”, arXiv 1906.08095, 2019
20. X Han, H Laga, M Bennamoun,“Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era”, arXiv 1906.06543, 2019
好消息!?
小白學(xué)視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學(xué)視覺」公眾號后臺回復(fù):擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學(xué)校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學(xué)習(xí)進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~