任務的插入時間復雜度優(yōu)化到 O(1),Timing Wheel時間輪是怎么做到的?

在kafka中,有許多請求并不是立即返回,而且處理完一些異步操作或者等待某些條件達成后才返回,這些請求一般都會帶有timeout參數(shù),表示如果timeout時間后服務端還不滿足返回的條件,就判定此次請求為超時,這時候kafka同樣要返回超時的響應給客戶端,這樣客戶端才知道此次請求超時了。比如ack=-1的producer請求,就需要等待所有的isr備份完成了才可以返回給客戶端,或者到達timeout時間了返回超時響應給客戶端。
上面的場景,可以用延遲任務來實現(xiàn)。也就是定義一個任務,在timeout時間后執(zhí)行,執(zhí)行的內容一般就是先檢查返回條件是否滿足,滿足的話就返回客戶端需要的響應,如果還是不滿足,就發(fā)送超時響應給客戶端。
對于延遲操作,java自帶的實現(xiàn)有Timer和ScheduledThreadPoolExecutor。這兩個的底層數(shù)據(jù)結構都是基于一個延遲隊列,在準備執(zhí)行一個延遲任務時,將其插入到延遲隊列中。這些延遲隊列其實就是一個用最小堆實現(xiàn)的優(yōu)先級隊列,因此,插入一個任務的時間復雜度是O(logN),取出一個任務執(zhí)行后調整堆的時間也是O(logN)。
如果要執(zhí)行的延遲任務不多,O(logN)的速度已經夠快了。但是對于kafka這樣一個高吞吐量的系統(tǒng)來說,O(logN)的速度還不夠,為了追求更快的速度,kafka的設計者使用了Timing Wheel的數(shù)據(jù)結構,讓任務的插入時間復雜度達到了O(1)。
Timing Wheel
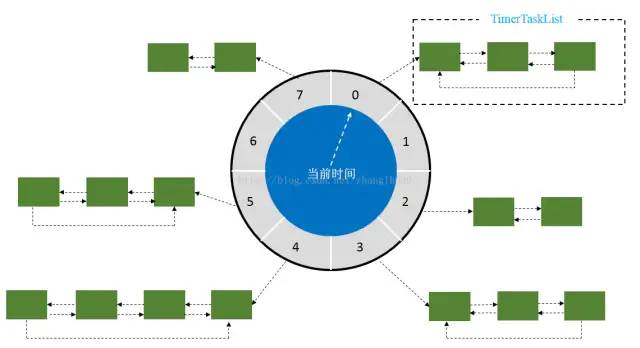
上面是時間輪的一個結構圖,該時間輪有8個槽,當前時間指向0號槽。
我們再看一下Kafka里面TimingWheel的數(shù)據(jù)結構
private[timer]?class?TimingWheel(tickMs:?Long,?wheelSize:?Int,?startMs:?Long,?taskCounter:?AtomicInteger,?queue:?DelayQueue[TimerTaskList])?{
??private[this]?val?interval?=?tickMs?*?wheelSize
??private[this]?val?buckets?=?Array.tabulate[TimerTaskList](wheelSize)?{?_?=>?new?TimerTaskList(taskCounter)?}
??private[this]?var?currentTime?=?startMs?-?(startMs?%?tickMs)?//?rounding?down?to?multiple?of?tickMs
}
tickMs:表示一個槽所代表的時間范圍,kafka的默認值的1ms
wheelSize:表示該時間輪有多少個槽,kafka的默認值是20
startMs:表示該時間輪的開始時間
taskCounter:表示該時間輪的任務總數(shù)
queue:是一個TimerTaskList的延遲隊列。每個槽都有它一個對應的TimerTaskList,TimerTaskList是一個雙向鏈表,有一個expireTime的值,這些TimerTaskList都被加到這個延遲隊列中,expireTime最小的槽會排在隊列的最前面。
interval:時間輪所能表示的時間跨度,也就是tickMs*wheelSize
buckets:表示TimerTaskList的數(shù)組,即各個槽。
currentTime:表示當前時間,也就是時間輪指針指向的時間
運行原理
當新增一個延遲任務時,通過buckets[expiration / tickMs % wheelSize]先計算出它應該屬于哪個槽。比如延遲任務的delayMs=2ms,當前時間currentTime是0ms,則expiration=delayMs+startMs=2ms,通過前面的公式算出它應該落于2號槽。并把任務封裝成TimerTaskEntry然后加入到TimerTaskList鏈表中。
之后,kafka會啟動一個線程,去推動時間輪的指針轉動。其實現(xiàn)原理其實就是通過queue.poll()取出放在最前面的槽的TimerTaskList。由于queue是一個延遲隊列,如果隊列中的expireTime沒有到達,該操作會阻塞住,直到expireTime到達。如果通過queue.poll()取到了TimerTaskList,說明該槽里面的任務時間都已經到達。這時候就可以遍歷該TimerTaskList中的任務,然后執(zhí)行對應的操作了。
針對上面的例子,就2號槽有任務,所以當取出2號槽的TimerTaskList后,會先將currentTime = timeMs - (timeMs % tickMs),其中timeMs也就是該TimerTaskList的expireTime,也就是2Ms。所以,這時currentTime=2ms,也就是時間輪指針指向2Ms。
時間溢出處理
在kafka的默認實現(xiàn)中,tickMs=1Ms,wheelSize=20,這就表示該時間輪所能表示的延遲時間范圍是0~20Ms,那如果延遲時間超過20Ms要如何處理呢?Kafka對時間輪做了一層改進,使時間輪變成層級的時間輪。
一開始,第一層的時間輪所能表示時間范圍是0~20Ms之間,假設現(xiàn)在出現(xiàn)一個任務的延遲時間是200Ms,那么kafka會再創(chuàng)建一層時間輪,我們稱之為第二層時間輪。
第二層時間輪的創(chuàng)建代碼如下
overflowWheel?=?new?TimingWheel(
??????????tickMs?=?interval,
??????????wheelSize?=?wheelSize,
??????????startMs?=?currentTime,
??????????taskCounter?=?taskCounter,
??????????queue
)
也就是第二層時間輪每一個槽所能表示的時間是第一層時間輪所能表示的時間范圍,也就是20Ms。槽的數(shù)量還是一樣,其他的屬性也是繼承自第一層時間輪。這時第二層時間輪所能表示的時間范圍就是0~400Ms了。
之后通過buckets[expiration / tickMs % wheelSize]算出延遲時間為200Ms的任務應該位于第二層時間輪的10號槽位。
同理,如果第二層時間輪的時間范圍還容納不了新的延遲任務,就會創(chuàng)建第三層、第四層...
值得注意的是,只有當前時間輪無法容納目標延遲任務所能表示的時間時,才需要創(chuàng)建更高一級的時間輪,或者說把該任務加到更高一級的時間輪中(如果該時間輪已創(chuàng)建)。
一些細節(jié)
當時間輪的指針指向1號槽時,即currentTime=1Ms,說明0號槽的任務都已經到期了,這時0號槽就會被拿出來復用,可以容納20~21Ms延遲時間的任務。也就是說,如果currentTime=0Ms時進來一個21Ms的延遲任務,就需要創(chuàng)建更高一級的時間輪,但是如果currentTime=1Ms時進來一個21Ms的延遲任務,就可以直接把它放到0號槽中,當currentTime=21時,指針又指向0號槽 細心的同學可能發(fā)現(xiàn),第一層的0號槽所能表示的任務延遲時間范圍是01Ms,對應的TimerTaskList的expireTime是0Ms。第二層的0號槽鎖能表示的任務延遲時間范圍是020Ms,對應的TimerTaskList的expireTime也是0Ms。他們的TimerTaskList又都是放在一個延遲隊列中。這時候執(zhí)行 queue.poll()會把這兩個TimerTaskList都取出來,然后遍歷鏈表的時候還會判斷該任務是否達到執(zhí)行時間了,如果沒有的話,這些任務還會被塞回時間輪中。這時由于第一層指針的轉動,原先處于第二層時間輪中的任務可能會重新落到第一層時間輪上面。
源碼解析
添加新的延遲任務
//SystemTimer.scala??
private?def?addTimerTaskEntry(timerTaskEntry:?TimerTaskEntry):?Unit?=?{
????if?(!timingWheel.add(timerTaskEntry))?{
??????//?Already?expired?or?cancelled
??????if?(!timerTaskEntry.cancelled)
????????taskExecutor.submit(timerTaskEntry.timerTask)
????}
??}
往時間輪添加新的任務
//TimingWheel
def?add(timerTaskEntry:?TimerTaskEntry):?Boolean?=?{
????//獲取任務的延遲時間
????val?expiration?=?timerTaskEntry.expirationMs
????//先判斷任務是否已經完成
????if?(timerTaskEntry.cancelled)?{
??????false
??????//如果任務已經到期
????}?else?if?(expiration???????false
??????//判斷當前時間輪所能表示的時間范圍是否可以容納該任務
????}?else?if?(expiration???????//?根據(jù)任務的延遲時間算出應該位于哪個槽
??????val?virtualId?=?expiration?/?tickMs
??????val?bucket?=?buckets((virtualId?%?wheelSize.toLong).toInt)
??????bucket.add(timerTaskEntry)
??????//?設置TimerTaskList的expireTime
??????if?(bucket.setExpiration(virtualId?*?tickMs))?{
????????//把TimerTaskList加入到延遲隊列
????????queue.offer(bucket)
??????}
??????true
????}?else?{
??????//如果時間超出當前所能表示的最大范圍,則創(chuàng)建新的時間輪,并把任務添加到那個時間輪上面
??????if?(overflowWheel?==?null)?addOverflowWheel()
??????overflowWheel.add(timerTaskEntry)
????}
??}
??private[this]?def?addOverflowWheel():?Unit?=?{
????synchronized?{
??????if?(overflowWheel?==?null)?{
????????overflowWheel?=?new?TimingWheel(
??????????tickMs?=?interval,
??????????wheelSize?=?wheelSize,
??????????startMs?=?currentTime,
??????????taskCounter?=?taskCounter,
??????????queue
????????)
??????}
????}
??}
從上面的代碼可以看出,對于當前時間輪是否可以容納目標任務,是通過expiration < currentTime + interval來計算的,也就是根據(jù)時間輪的指針往后推interval時間就是時間輪所能表示的時間范圍。
時間輪指針的推進
?//SystemTimer.scala?
def?advanceClock(timeoutMs:?Long):?Boolean?=?{
??????//從延遲隊列中取出最近的一個槽,如果槽的expireTime沒到,此操作會阻塞timeoutMs
????var?bucket?=?delayQueue.poll(timeoutMs,?TimeUnit.MILLISECONDS)
????if?(bucket?!=?null)?{
??????writeLock.lock()
??????try?{
????????while?(bucket?!=?null)?{
????????????//推進時間輪的指針
??????????timingWheel.advanceClock(bucket.getExpiration())
????????????//把TimerTaskList的任務都取出來重新add一遍,add的時候會檢查任務是否已經到期
??????????bucket.flush(reinsert)
??????????bucket?=?delayQueue.poll()
????????}
??????}?finally?{
????????writeLock.unlock()
??????}
??????true
????}?else?{
??????false
????}
??}
//TimingWheel
def?advanceClock(timeMs:?Long):?Unit?=?{
????if?(timeMs?>=?currentTime?+?tickMs)?{
????????//推進時間輪的指針
??????currentTime?=?timeMs?-?(timeMs?%?tickMs)
??????//?推進上層時間輪的指針
??????if?(overflowWheel?!=?null)?overflowWheel.advanceClock(currentTime)
????}
??}
總結
相比于常用的DelayQueue的時間復雜度O(logN),TimingWheel的數(shù)據(jù)結構在插入任務時只要O(1),獲取到達任務的時間復雜度也遠低于O(logN)。另外,kafka的TimingWheel在插入任務之前還會先檢查任務是否完成,對于那些在任務超時直接就完成指定操作的場景,TimingWheel的表現(xiàn)更加優(yōu)秀。