
終于結(jié)束了!總結(jié)一下這次大賽.

你好呀,我是歪歪。
給大家分享一篇關(guān)于性能挑戰(zhàn)賽的文章,我看了之后受益匪淺。
阿里云舉辦的大賽我從 2016 開始關(guān)注,每年的賽題我都仔細(xì)看了,并思考過解題思路。
雖然每年都是陪跑,但是能讀懂排名靠前的參賽選手的比賽思路,也是一件非常有收獲的事情。
共勉之。
前言
我參加了阿里云舉辦的《第三屆數(shù)據(jù)庫大賽創(chuàng)新上云性能挑戰(zhàn)賽–高性能分析型查詢引擎賽道》,傳送門:
https://tianchi.aliyun.com/competition/entrance/531895/introduction
截止到 8 月 20 日,終于結(jié)束了漫長的賽程。
作為阿里云員工的我,按照賽題規(guī)定,只能參加初賽,不能參加復(fù)賽,出于不影響比賽的目的,終于等到了比賽完全結(jié)束,才動(dòng)筆寫下了這篇參賽總結(jié)。
照例先說成績,這里貼一下排行榜,總共有 1446 只隊(duì)伍,可以看到不少學(xué)生和其他公司的員工都參賽了。
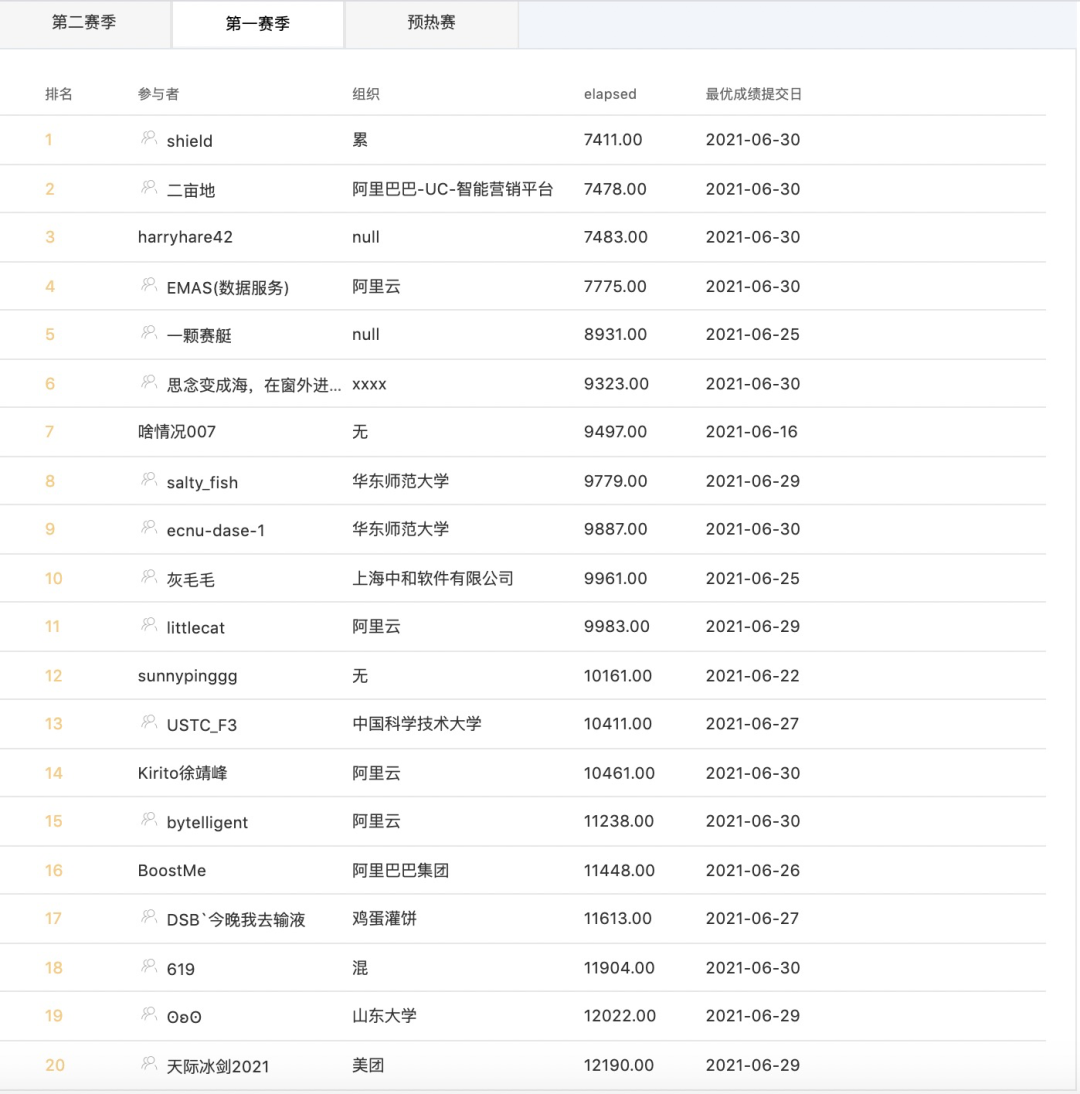
我的成績是第 14 名,內(nèi)部排名也是進(jìn)入了前五。
先簡單點(diǎn)評(píng)下這次比賽吧。
首先是主辦方的出題水平,還是非常高的。
- 全程沒有改過賽題描述
- 全程沒有清過榜單
- 沒有暗改過數(shù)據(jù)
- 賽題做到了“題面描述簡單,實(shí)現(xiàn)具有區(qū)分度”,讓不同水平的參賽者都得到了發(fā)揮
- 評(píng)測友好,失敗不計(jì)算提交次數(shù)
這些點(diǎn)要大大點(diǎn)一個(gè)贊,建議其他比賽的主辦方都來參考下,向這次出題的水準(zhǔn)看齊。
不好的點(diǎn),我也吐槽下:
- 內(nèi)部賽獎(jiǎng)勵(lì)太敷衍了,倒不如送我點(diǎn)公仔來的實(shí)在
- 復(fù)賽延期了兩周,讓很多選手的肝有些吃不消
這篇文章我覺得得先明確一個(gè)定位,復(fù)賽和初賽技術(shù)架構(gòu)相差是很大的,而我沒有參加復(fù)賽,并沒有發(fā)言權(quán),所以就不去詳細(xì)介紹最終的復(fù)賽方案了。
我的這篇文章還是以初賽為主,一方面聊的話題也輕松些,另一方面初賽的架構(gòu)簡單一些,可以供那些希望參加性能挑戰(zhàn)賽而又苦于沒有學(xué)習(xí)資料的同學(xué)、初賽沒有找到優(yōu)化點(diǎn)的同學(xué)一些參考。
賽題介紹
https://tianchi.aliyun.com/competition/entrance/531895/introduction
題面可以說是非常簡單的,其實(shí)就是實(shí)現(xiàn)一個(gè)查詢第 N 大的數(shù)函數(shù)。
它的輸入數(shù)據(jù)一共有兩列:

第一行是列名,第二行開始是列的數(shù)據(jù)。
初賽測試數(shù)據(jù):只有一張表 lineitem,只有兩列 L_ORDERKEY (bigint), L_PARTKEY (bigint),數(shù)據(jù)量3億行,單線程查詢 10 次。
如果你還不理解這個(gè)題面是什么意思,建議去看下官方提供的評(píng)測 demo:
https://code.aliyun.com/analytic_db/2021-tianchi-contest-1
本地就能運(yùn)行,debug 跑一遍,既能讀懂題意,也能得到一個(gè)baseline(盡管它不能提交,會(huì)爆內(nèi)存)。
另外需要格外注意的一點(diǎn),千萬不要漏看賽題描述
本題結(jié)合英特爾? 傲騰? 持久內(nèi)存技術(shù)(PMem),探索新介質(zhì)和新軟件系統(tǒng)上極致的持久化和性能
我們的方案一定需要圍繞著存儲(chǔ)介質(zhì)的特性去設(shè)計(jì),你問我持久內(nèi)存 PMem 是啥?
老實(shí)說,我參賽之前對這個(gè)新的技術(shù)也是一知半解,但為了成績,一定需要啃下這個(gè)技術(shù),下面我就先介紹下 PMem。
持久內(nèi)存 PMem 介紹
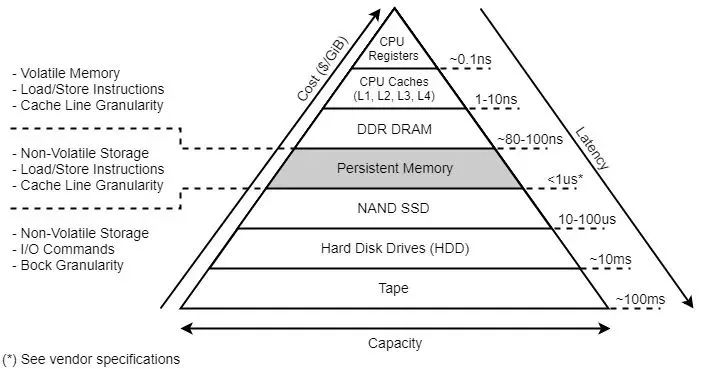
提到內(nèi)存(DRAM)、固態(tài)磁盤(SSD)、機(jī)械硬盤(HDD)這些概念,相信大多數(shù)人不會(huì)感到陌生,都能夠道出這幾個(gè)介質(zhì)的訪問速度差異。而持久內(nèi)存 PMem 這個(gè)概念,相對而言不太為人所知,的確,它是近幾年才興起的一個(gè)概念。
持久內(nèi)存 (PMem) 是駐留在內(nèi)存總線上的固態(tài)高性能按字節(jié)尋址的內(nèi)存設(shè)備。PMem 位于內(nèi)存總線上,支持像 DRAM 一樣訪問數(shù)據(jù),這意味著它具備與 DRAM 相當(dāng)?shù)乃俣群脱舆t,而且兼具 NAND 閃存的非易失性。NVDIMM(非易失性雙列直插式內(nèi)存模塊)和 Intel 3D XPoint DIMM(也稱為 Optane DC 持久內(nèi)存模塊)是持久內(nèi)存技術(shù)的兩個(gè)示例。
當(dāng)我們在討論這些存儲(chǔ)介質(zhì)時(shí),我們有哪些關(guān)注點(diǎn)呢?
本節(jié)開頭的金字塔圖片的三條邊直觀地詮釋了眾多存儲(chǔ)介質(zhì)在造價(jià)、訪問延時(shí)、容量三方面的對比。我下面從訪問延時(shí)、造價(jià)和持久化特性三個(gè)方面做一下對比。
訪問延時(shí)
內(nèi)存 DRAM 的訪問延時(shí)在 80~100ns,固態(tài)硬盤 SSD 的訪問延時(shí)在 10~100us,而持久內(nèi)存介于兩者之間,比內(nèi)存慢 10 倍,比固態(tài)硬盤快 10~100 倍。
造價(jià)
目前為止,將 PMem 技術(shù)正式商用的公司,貌似只有 Intel,也就是本次比賽的贊助商。
Intel optane DC persistent memory 是 Intel 推出的基于 3D Xpoint 技術(shù)的持久內(nèi)存產(chǎn)品,其代號(hào)為 Apace Pass (AEP)。
所以大家今后如果看到其他人提到 AEP,基本心理就有數(shù)了,說的就是 PMem 這個(gè)存儲(chǔ)介質(zhì)。
在某電商平臺(tái)看看這東西怎么賣的:
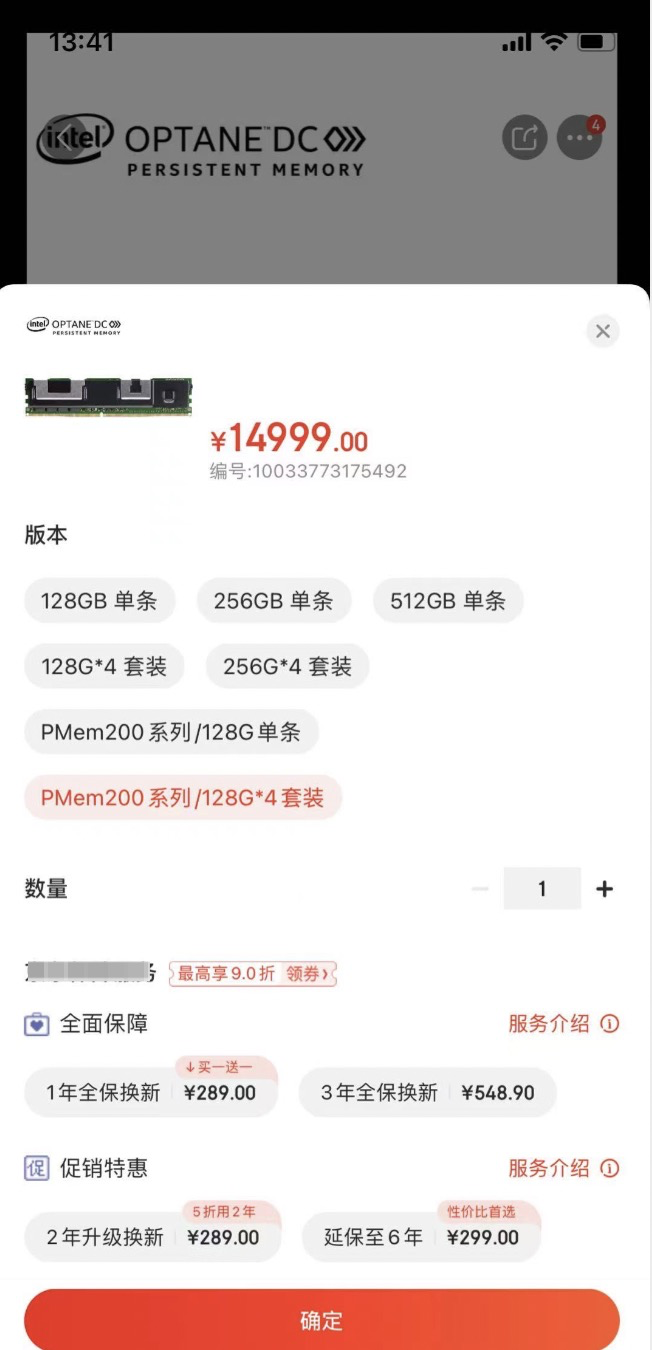
好家伙,128 * 4 條,賣 15000,折合下來,一根 PMem 就要 3000~4000。
同時(shí)我們也注意到,傲騰系列的 PMem 產(chǎn)品最高規(guī)格也就只有 512G,基本佐證了金字塔中的 Capacity 這一維度,屬于內(nèi)存嫌大,磁盤嫌小的一個(gè)數(shù)值。
持久化
這東西咱們的電腦可以裝嗎?
當(dāng)然可以,直接插在內(nèi)存條上就成。
我們都知道內(nèi)存是易失性的存儲(chǔ),磁盤是持久化的存儲(chǔ),而介于兩者之間的持久內(nèi)存,持久化特性是什么樣的呢?
這一點(diǎn),不能望文生義地認(rèn)為 PMem 就是持久化的,而是要看其工作模式:
Memory Mode 和 AppDirect Mode。
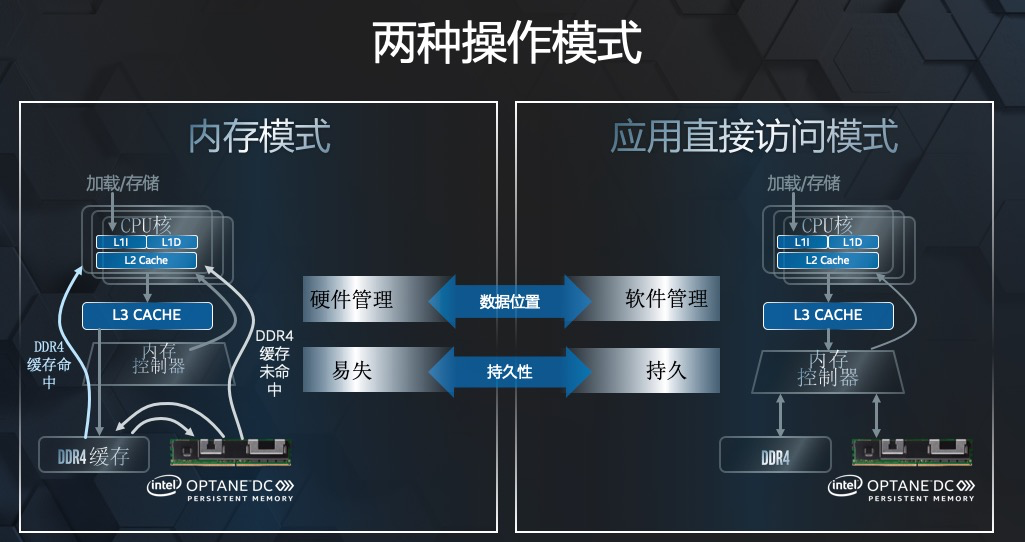
本文就不過多展開介紹了這兩種模式了。
簡單來說,PMem 工作在 Memory Mode 時(shí),是易失性的,這時(shí)候,你需要使用專門的一套系統(tǒng)指令去進(jìn)行存取。
PMem 工作在 AppDirect Mode 時(shí),可以直接把 PMem 當(dāng)成一塊磁盤來用,PMem 背后適配了一整套文件系統(tǒng)的指令,使得常規(guī)的文件操作可以完全兼容的跑在 PMem 之上。
我花了這么大的篇幅介紹 PMem,仍然只介紹了 PMem 特性非常小的一部分,最多讓大家知道 PMem 是個(gè)啥,至于怎么利用好這塊盤,我后邊會(huì)花專門的一篇文章去介紹。
回到賽題,盡管 intel 提供了一套 PMem 專用的 API:
https://github.com/pmem/pmemkv-java
但由于比賽限定了不能引入三方類庫。

所以等于直接告訴了參賽選手,PMem 這塊盤是工作在 AppDirect Mode 之下的,大家可以完全把它當(dāng)成一塊磁盤去存取。
這個(gè)時(shí)候,選手們就需要圍繞 PMem 的特性,去設(shè)計(jì)存儲(chǔ)引擎的架構(gòu),可能你在固態(tài)硬盤、常規(guī)文件操作中的一些認(rèn)知會(huì)被顛覆。
這很正常,畢竟 PMem 的出現(xiàn),就是為了顛覆傳統(tǒng)存儲(chǔ)架構(gòu)而生的。
在不能直接操作 PMem 的情況下選手們需要設(shè)計(jì) PMem 友好的架構(gòu)。
賽題剖析
此次的數(shù)據(jù)輸入方式和之前的比賽有很大的不同,選手們需要自行去解析文件,獲得輸入數(shù)據(jù),同時(shí)進(jìn)行處理,如何高效的處理文件是很大的一塊優(yōu)化點(diǎn)。
初賽一共 3 億行數(shù)據(jù),一共 2 列,內(nèi)存一共 4 G,稍微計(jì)算下就會(huì)發(fā)現(xiàn),全部存儲(chǔ)在內(nèi)存中是存不下的(不考慮壓縮),所以需要用到 PMem 充當(dāng)存儲(chǔ)引擎。
查詢的需求是查找到第 N 大的數(shù),所以我們的架構(gòu)一定是需要做到整體有序,允許局部無序。
賽題數(shù)據(jù)的說明尤為重要:
測試數(shù)據(jù)隨機(jī),均勻分布。
看過我之前文章的讀者,應(yīng)當(dāng)敏銳地注意到了均勻分布這個(gè)關(guān)鍵詞,這意味著我們又可以使用數(shù)據(jù)的頭 n 位來分區(qū)了。
這里先給出初賽的最終架構(gòu),明確下如何串聯(lián)各個(gè)流程:
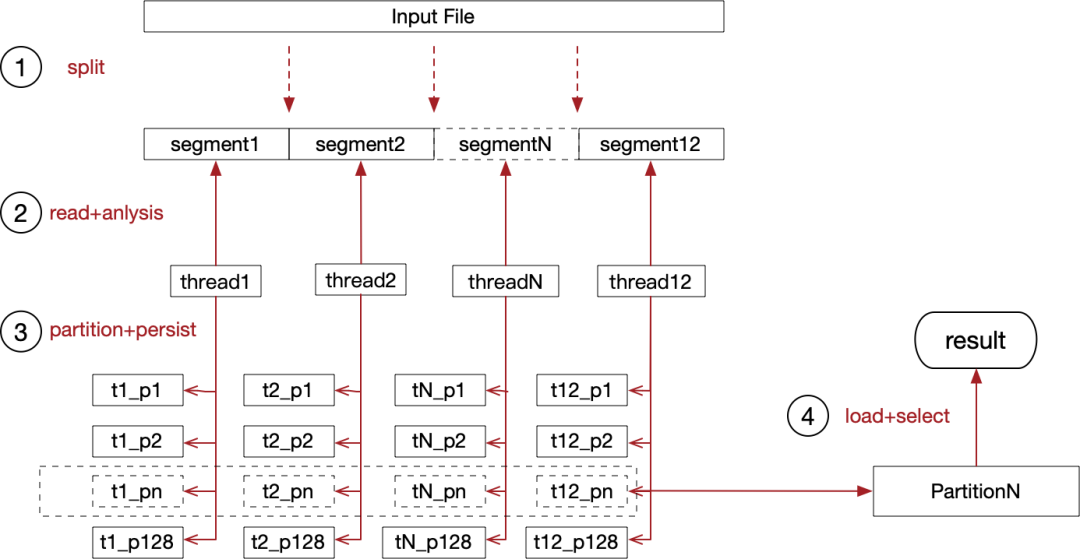
把大象放進(jìn)冰箱總共需要三步,這道題目僅僅多了一步。
第一步:將輸入文件從邏輯上分成 12 等分,這樣 12 個(gè)線程可以并發(fā)讀取輸入文件。可以借助預(yù)處理程序,找到等分的邊界。
第二步:每個(gè)線程都需要讀取各自的文件分片,將讀取到的文件流在內(nèi)存中解析成 long,并且需要根據(jù)逗號(hào)、換行符來區(qū)分出兩列數(shù)據(jù)。
第三步:讀取到 long 之后,需要根據(jù)頭 n 位進(jìn)行分區(qū),例如選擇頭 8 位,可以獲得 2^(8-1) 即 128 個(gè)分區(qū),因?yàn)楸荣愔械臄?shù)據(jù)都是正數(shù),所以減了一個(gè)符號(hào)位。這樣分區(qū)之后,可以保證分區(qū)之間有序,分區(qū)內(nèi)部無序。
第四步:獲取第 N 大的數(shù)字時(shí),可以直接根據(jù)分區(qū)內(nèi)的數(shù)據(jù)量,直接定位到最終在哪個(gè)分區(qū),這樣就可以確保只加載一部分?jǐn)?shù)據(jù)到內(nèi)存中。t1_pn ~ t12_pn 在邏輯上組成了 partitionN,將 partitionN 的數(shù)據(jù)加載進(jìn)內(nèi)存之后,這道題就變成:查詢無序數(shù)組中第 N 大數(shù)的問題了。
實(shí)現(xiàn)細(xì)節(jié)
以下的實(shí)現(xiàn)細(xì)節(jié),我會(huì)給出實(shí)現(xiàn)難度,以供大家參考,打分標(biāo)準(zhǔn):編碼實(shí)現(xiàn)難度,容不容易想到等綜合評(píng)分。
多線程按分區(qū)讀文件(難度:2 顆星)
輸入文件按行來分隔數(shù)據(jù),第一時(shí)間聯(lián)想到的就是 JDK 提供的 java.io.BufferedReader#readLine() 方法。
但稍微懂點(diǎn)文件 IO 基礎(chǔ)的讀者都應(yīng)該意識(shí)到,文件 IO 要想快,一定得順序按塊讀,所以 readLine 這種方法,想都不用想,必定是低效的。
那有人問了,博主,你給解釋解釋,什么叫按塊讀?
最簡單的做法是按照固定 4kb 的 buffer 來讀取文件,在內(nèi)存中,自行判斷逗號(hào)、換行符來區(qū)分兩列數(shù)據(jù),不斷移動(dòng)這個(gè) 4kb 的塊,這就是按塊讀了。
if?(readBufferArray[i]?==?'\n')?{
}?
if(readBufferArray[i]?==?',')?{
}
光是按塊讀還不夠,為了充分發(fā)揮 IO 特性,還可以用上多線程,按照上圖中的第一步,我的方案將文件分成了 12 份,這樣 12 個(gè)線程可以齊頭并進(jìn)地進(jìn)行讀取和解析。
經(jīng)過測試,多線程比單線程要快 70 多秒,所以沒有使用多線程的選手,名次肯定不會(huì)高,這是一個(gè)通用優(yōu)化點(diǎn)。
Long 轉(zhuǎn)換(難度:1 顆星)
將文件中的字節(jié)讀取到內(nèi)存中,一定會(huì)經(jīng)過 byte[] 到 long 的轉(zhuǎn)換過程,千萬不要小看這個(gè)環(huán)節(jié),這可是眾多選手分?jǐn)?shù)的分水嶺。
先來看下 demo 中給出的方案:
String[]?columns?=?reader.readLine().split(",");
Long.parseLong(row[i]);
這里面存在兩個(gè)問題
- 1.先轉(zhuǎn) String,再轉(zhuǎn)成 Long,多了一次無效轉(zhuǎn)換
- 2.Long.parseLong 方法比較低效,有很多無用判斷
我貼一下我方案的偽代碼:
long?val?=?0;
for?(int?i?=?0;?i?<?size;?i++)?{
????val?=?val?*?10?+?(readBuffer[i]?-?'0');
}
直接從字節(jié)數(shù)組中解析出 Long。
解析出 Long 主要還是為了落盤的時(shí)候進(jìn)行數(shù)據(jù)對齊,主流方案應(yīng)該都會(huì)解析。
按頭 n 位分桶落盤(難度:1 顆星)
在讀取到一個(gè) Long 之后,我們可以按照數(shù)據(jù)的頭 n 位,將其寫入對應(yīng)的分區(qū)文件中。
這其實(shí)也是一個(gè)通用的優(yōu)化點(diǎn),我在《華為云 TaurusDB 性能挑戰(zhàn)賽賽題總結(jié)》也介紹過,分區(qū)之后,可以保證分區(qū)之間有序,即 partition1 中的任意數(shù)據(jù)一定小于 partition2 中的任意數(shù)據(jù)。
分區(qū)之間無序,主要是為了可以實(shí)現(xiàn)分區(qū)文件的順序?qū)憽?/p>
至于 n 具體是多少,取決于我們想分多個(gè)區(qū)。
分區(qū)太多,會(huì)導(dǎo)致整體寫入速度下降;分區(qū)太少,讀取階段加載的數(shù)據(jù)會(huì)過多,甚至可能導(dǎo)致內(nèi)存放不下。
每個(gè)寫線程維護(hù)自己的分區(qū)文件(難度:3 顆星)
在賽題剖析里面,我給出了我最終方案的流程圖,里面有一個(gè)細(xì)節(jié),每個(gè)讀取線程從 1/12 個(gè)文件分片中讀取解析到的 Long 數(shù)值,寫入了自己線程編號(hào)對應(yīng)的文件中,進(jìn)行落盤。
并沒有采用寫入同一個(gè)分區(qū)文件這樣的設(shè)計(jì)。對比下兩種做法的利弊:
- 寫線程寫入同一個(gè)分區(qū)文件。好處是讀取階段不需要聚合多份分區(qū)文件,壞處是多個(gè)線程寫入同一個(gè)分區(qū)需要加鎖,會(huì)導(dǎo)致競爭。
- 寫線程寫入自己的分區(qū)文件。好處是不需要加鎖寫,壞處是讀取階段需要聚合讀取。
也好理解,兩個(gè)方案的優(yōu)劣正好相反,稍微分析一下,由于初賽的查詢只有 10 次,所以聚合的開銷不會(huì)太大,再加上,我們本來就希望讀取能做到并發(fā),聚合沒有那么可怕。反而是寫入時(shí)加鎖導(dǎo)致的沖突,會(huì)嚴(yán)重浪費(fèi) CPU。
該優(yōu)化點(diǎn),幫助我的方案從 80s 縮短到 50s。
分支預(yù)測優(yōu)化(難度:4 顆星)
這次比賽因?yàn)橛辛?PMem,導(dǎo)致瓶頸根本不出在 IO 上。
以往比賽中,大家都是想盡一切方法,把 CPU 讓給 IO。
而這次比賽,PMem 直接起飛了,導(dǎo)致大家需要考慮,怎么優(yōu)化 CPU。
而 JVM 虛擬機(jī)的一系列機(jī)制中,就有很多注意事項(xiàng),是跟 CPU 優(yōu)化相關(guān)的。
在解析 Long 時(shí),我們需要從 4kb 的讀緩沖區(qū)中解析出 Long 數(shù)值,由于文件中的數(shù)值是以不定長的字節(jié)數(shù)組形式出現(xiàn)的,我們只能通過判斷逗號(hào)、換行符來解析出數(shù)值,所以難免會(huì)寫出這樣的代碼:
int?blockReadPosition?=?0;
for?(int?i?=?0;?i?<?size;?i++)?{
????if?(readBufferArray[i]?==?'\n')?{
????????partRaceEngine.add(threadNo,?val);
????????val?=?0;
????????blockReadPosition?=?i?+?1;
????}?else?if(readBufferArray[i]?==?',')?{
????????orderRaceEngine.add(threadNo,?val);
????????val?=?0;
????????blockReadPosition?=?i?+?1;
????}?else?{
????????val?=?val?*?10?+?(readBufferArray[i]?-?'0');
????}
}
思考下,這段代碼會(huì)有什么邏輯問題嗎?
當(dāng)然沒有,相信很多選手也會(huì)這么判斷。
但不妨分析下,輸入文件大概有 10G 左右,所有的字節(jié)都會(huì)經(jīng)過 if 判斷一次,而實(shí)際上,大多數(shù)的字符并不是 \n 和 , 。
這會(huì)導(dǎo)致 CPU 被浪費(fèi)在分支預(yù)測上。
我的優(yōu)化思路也很簡單,直接用循環(huán),干掉 if/else 判斷
for?(int?i?=?0;?i?<?size;?i++)?{
???byte?temp?=?readBufferArray[i];
???do?{
???????val?=?val?*?10?+?(temp?-?'0');
???????temp?=?readBufferArray[++i];
???}?while?(temp?!=?',');
???orderRaceEngine.add(threadNo,?val);
???val?=?0;
???//?skip?,
???i++;
???temp?=?readBufferArray[i];
???do?{
???????val?=?val?*?10?+?(temp?-?'0');
???????temp?=?readBufferArray[++i];
???}?while?(temp?!=?'\n');
???partRaceEngine.add(threadNo,?val);
???val?=?0;
???//?skip?\n
}
readPosition?+=?size;
一般來說,再?zèng)]有辦法去掉 if/else 的前提下,我們可以遵循的一個(gè)最佳實(shí)踐是,將容易命中的條件放到最前面。
該優(yōu)化幫助我從 48s 優(yōu)化到了 24s。
另外,也可以利用數(shù)據(jù)特性,因?yàn)榇蠖鄶?shù)數(shù)據(jù)是 19 位的數(shù)字,可以直接判斷第 20 位是不是 , 或者 \n 從而減少分支預(yù)測的次數(shù)。
quickSelect(難度:4 顆星)
在查詢階段,查詢一個(gè)分區(qū)內(nèi)第 N 大的數(shù),最簡單的思路是排序之后直接返回,a[N],受到評(píng)測 demo 的影響,很多選手可能忽略了可以使用 quickSelect 算法。
Quick Select 你可能沒聽過,但快速排序(Quick Sort)你肯定有所耳聞,其實(shí)他們兩個(gè)算法的作者都是 Hoare,并且思想也非常接近:
選取一個(gè)基準(zhǔn)元素 pivot,將數(shù)組切分(partition)為兩個(gè)子數(shù)組,比 pivot 大的扔左子數(shù)組,比 pivot 小的扔右子數(shù)組,然后遞推地切分子數(shù)組。
Quick Select 不同于 Quick Sort 之處在于其沒有對每個(gè)子數(shù)組做切分,而是對目標(biāo)子數(shù)組做切分。
其次,Quick Select 與Quick Sort 一樣,是一個(gè)不穩(wěn)定的算法。
pivot 選取直接影響了算法的好壞,最壞情況下的時(shí)間復(fù)雜度達(dá)到了 O(n2)。
Quick Select 的 Java 實(shí)現(xiàn)如下:
public?static?long?quickSelect(long[]?nums,?int?start,?int?end,?int?k)?{
????????if?(start?==?end)?{
????????????return?nums[start];
????????}
????????int?left?=?start;
????????int?right?=?end;
????????long?pivot?=?nums[(start?+?end)?/?2];
????????while?(left?<=?right)?{
????????????while?(left?<=?right?&&?nums[left]?>?pivot)?{
????????????????left++;
????????????}
????????????while?(left?<=?right?&&?nums[right]?<?pivot)?{
????????????????right--;
????????????}
????????????if?(left?<=?right)?{
????????????????long?temp?=?nums[left];
????????????????nums[left]?=?nums[right];
????????????????nums[right]?=?temp;
????????????????left++;
????????????????right--;
????????????}
????????}
????????if?(start?+?k?-?1?<=?right)?{
????????????return?quickSelect(nums,?start,?right,?k);
????????}
????????if?(start?+?k?-?1?>=?left)?{
????????????return?quickSelect(nums,?left,?end,?k?-?(left?-?start));
????????}
????????return?nums[right?+?1];
????}
該優(yōu)化幫我從 24s 優(yōu)化到 17s。
查詢階段多線程讀分區(qū)(難度:2 顆星)
前文提到了為了避免寫入階段的沖突,每個(gè)線程維護(hù)了自己的分區(qū)文件,在查詢時(shí),則需要聚合多個(gè)線程的數(shù)據(jù)。
這個(gè)時(shí)候不要忘記也可以多線程讀取,因?yàn)槌踬惖脑u(píng)測程序是單線程測評(píng)的,IO 無法打滿,需要我們控制多線程,充分利用 IO。
該優(yōu)化幫我從 17s 優(yōu)化到了 15s。
循環(huán)展開(難度:4 顆星)
盡管得知我們可以知道字節(jié)數(shù)組的長度,從而用循環(huán)來解析出 Long,但根據(jù) JMH 的優(yōu)化項(xiàng)來看,手動(dòng)展開循環(huán),可以讓程序更加地快,例如像下面這樣。

這樣的優(yōu)化大概僅僅能提升 1s~2s,甚至不到,但越是到前排,1~2s 的優(yōu)化就越會(huì)顯得彌足珍貴。
總結(jié)
還有很多之前我提到過的一些通用優(yōu)化技巧,例如順序讀寫、讀寫緩沖、對象復(fù)用等等,就不在這里繼續(xù)贅述了,盡管 PMem 和固態(tài)硬盤這兩種介質(zhì)有一定的差異,但這些優(yōu)化技巧依舊是通用的。
因?yàn)檫@次比賽,IO 的速度實(shí)在是太快了,導(dǎo)致優(yōu)化的方向變成如何優(yōu)化 CPU,合理分配 CPU,讓 CPU 更多地分配給瓶頸操作,這是其他比賽中沒有過的經(jīng)歷。
還有一些點(diǎn)是通過調(diào)參來實(shí)現(xiàn)的,例如文件分片數(shù),讀寫緩沖區(qū)的大小,讀寫的線程數(shù)等等,也會(huì)導(dǎo)致成績相差非常大,這就需要不斷地肝,不斷地 benchmark 了。
不光是成功的優(yōu)化點(diǎn)值得分享,也拿一個(gè)失敗的優(yōu)化分享一下,例如,將一半的數(shù)據(jù)存儲(chǔ)在內(nèi)存中,最終發(fā)現(xiàn),申請內(nèi)存的時(shí)間,倒不如拿去進(jìn)行文件 IO,最終放棄了,可以見得在合理的架構(gòu)設(shè)計(jì)下,PMem 的表現(xiàn)的確彪悍,不輸于內(nèi)存存取。
這次 ADB 的性能挑戰(zhàn)賽,雖然只參加了初賽,但收獲的技能點(diǎn)還是不少的。
印象最深的便是 PMem 這塊盤的表現(xiàn)和我理解中的 SSD 還是有一定差距的,導(dǎo)致之前的一些經(jīng)驗(yàn)不能直接在這場比賽中運(yùn)用。
我也大概了解了很多復(fù)賽前排選手使用到了很多的奇技淫巧,每一個(gè)看似奇葩的優(yōu)化點(diǎn)背后,可能都蘊(yùn)含著該選手對操作系統(tǒng)、文件系統(tǒng)、編程語言等方面超出常人的認(rèn)知,值得喝彩。
感到遺憾的地方還是有的。
這次比賽只能讓 PMem 工作在 APP Direct 模式下,沒有能夠真正做到顛覆性。
如果有一場比賽,能夠支持 Memory Mode,那我應(yīng)該能收獲到對持久內(nèi)存更加深刻的認(rèn)知。
我一直反復(fù)安利我的讀者盡可能地參加各類性能挑戰(zhàn)賽,特別是在校生、實(shí)習(xí)生或者剛進(jìn)入職場的新人,這種比賽是實(shí)踐的最好機(jī)會(huì),看書不是。
好了,最后,我將我的代碼開源在了 github:
https://github.com/lexburner/2021-tianchi-adb-race
推薦???:Java如何綁定線程到指定CPU上執(zhí)行?
我是 why,你也可以叫我小歪,一個(gè)主要寫代碼,經(jīng)常寫文章,偶爾拍視頻的程序猿。
歡迎關(guān)注我呀。