
一文快速了解Kafka
初學(xué)Kafka,肯定會被各種概念搞得很頭疼,所以整理下Kafka進(jìn)階學(xué)習(xí)必須要了解的概念。
這篇博客也作為后續(xù)Kafka深入理解的前置信息。
什么是Kafka
Kafka基于Scala和Java語言開發(fā),設(shè)計中大量使用了批量處理和異步的思想,最高可以每秒處理百萬級別的消息,是用于構(gòu)建實時數(shù)據(jù)管道和流的應(yīng)用程序。
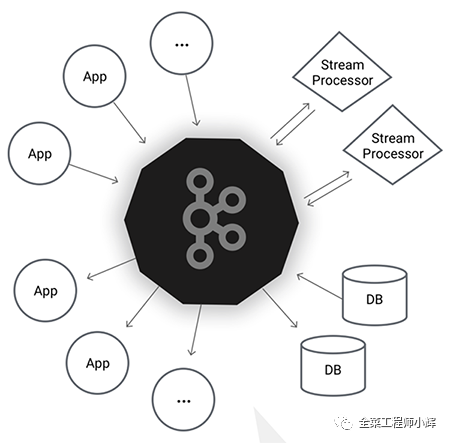
Kafka的應(yīng)用場景
Kafka是一個分布式流式處理平臺。流平臺具有三個關(guān)鍵功能:
消息隊列:發(fā)布和訂閱消息流,這個功能類似于消息隊列,這也是Kafka被歸類為消息隊列的原因。
容錯的持久方式存儲記錄消息流:Kafka會把消息持久化到磁盤,有效避免消息丟失的風(fēng)險。
流式處理平臺:在消息發(fā)布的時候進(jìn)行處理,Kafka提供了一個完整的流式處理類庫。
Kafka主要有兩大應(yīng)用場景:
消息隊列:建立實時流數(shù)據(jù)管道,可靠地在系統(tǒng)或應(yīng)用程序之間獲取數(shù)據(jù)。
數(shù)據(jù)處理:構(gòu)建實時的流數(shù)據(jù)處理程序來轉(zhuǎn)換或處理數(shù)據(jù)流。

注:Kafka在2.8預(yù)覽版中,采用Raft元數(shù)據(jù)模式,取消了對Zookeeper的依賴。
Kafka的版本里程碑
| 版本號 | 備注 |
|---|---|
| 0.8 | 引入了副本機(jī)制,成為了一個真正意義上完備的分布式高可靠消息隊列解決方案 |
| 0.8.2 | 新版本 Producer API,即需要指定 Broker 地址的 Producer |
| 0.9 | 增加了基礎(chǔ)的安全認(rèn)證 / 權(quán)限,Java 重寫了新版本消費者 API |
| 0.10 | 引入了 Kafka Streams |
| 0.11 | 提供冪等性 Producer API 以及事務(wù)(Transaction) API,對 Kafka 消息格式做了重構(gòu)。 |
| 1.0 | Kafka Streams 的各種改進(jìn) |
| 2.0 | Kafka Streams 的各種改進(jìn) |
Kafka的優(yōu)勢
高吞吐、低延時:這是 Kafka 顯著的特點,Kafka 能夠達(dá)到百萬級的消息吞吐量,延遲可達(dá)毫秒級。
持久化存儲:Kafka 的消息最終持久化保存在磁盤之上,提供了順序讀寫以保證性能,并且通過 Kafka 的副本機(jī)制提高了數(shù)據(jù)可靠性。
分布式可擴(kuò)展:Kafka的數(shù)據(jù)是分布式存儲在不同broker節(jié)點的,以topic組織數(shù)據(jù)并且按Partition進(jìn)行分布式存儲,整體的擴(kuò)展性都非常好。
高容錯性:集群中任意一個 broker 節(jié)點宕機(jī),Kafka 仍能對外提供服務(wù)。
Kafka基本結(jié)構(gòu)
Kafka具有四個核心API:
Producer API:發(fā)布消息到1個或多個topic(主題)中。
Consumer API:來訂閱一個或多個topic,并處理產(chǎn)生的消息。
Streams API:充當(dāng)一個流處理器,從1個或多個topic消費輸入流,并生產(chǎn)一個輸出流到1個或多個輸出topic,有效地將輸入流轉(zhuǎn)換到輸出流。
Connector API:可構(gòu)建或運行可重用的生產(chǎn)者或消費者,將topic連接到現(xiàn)有的應(yīng)用程序或數(shù)據(jù)系統(tǒng)。例如,連接到關(guān)系數(shù)據(jù)庫的連接器可以捕獲表的每個變更。

Kafka的關(guān)鍵術(shù)語
Producer:消息和數(shù)據(jù)的生產(chǎn)者,向Kafka的一個Topic發(fā)布消息的進(jìn)程/代碼/服務(wù)。
Consumer:消息和數(shù)據(jù)的消費者,訂閱數(shù)據(jù)(Topic)并且處理發(fā)布的消息的進(jìn)程/代碼/服務(wù)。
Consumer Group:對于同一個Topic,會廣播給不同的Group。在一個Group中,一條消息只能被消費組中一個的Consumer消費。
Consumer Group中不能有比Partition數(shù)量更多的消費者,否則多出的消費者一直處于空等待,不會收到消息。

Topic:每條發(fā)布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。作用是對數(shù)據(jù)進(jìn)行區(qū)分、隔離。
Broker:Kafka集群中的每個Kafka節(jié)點。保存Topic的一個或多個Partition。
Partition:物理概念,Kafka下數(shù)據(jù)儲存的基本單元。一個Topic數(shù)據(jù),會被分散存儲到多個Partition,每一個Partition都是一個順序的、不可變的消息隊列,并且可以持續(xù)的添加消息。
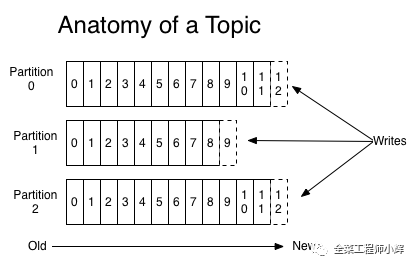
注:
每一個Topic的信息被切分為多個Partitions。若Partition數(shù)量設(shè)置成1個,則可以保證消息消費的順序性。
如果某Topic有N個Partition,集群有N個Broker,那么每個Broker存儲該topic的一個Partition。
如果某Topic有N個Partition,集群有(N+M)個Broker,那么其中有N個Broker存儲該Topic的一個Partition,剩下的M個Broker不存儲該Topic的Partition數(shù)據(jù)。
如果某Topic有N個Partition,集群中Broker數(shù)目少于N個,那么一個Broker存儲該Topic的一個或多個Partition。在實際生產(chǎn)環(huán)境中,盡量避免這種情況的發(fā)生,這種情況容易導(dǎo)致Kafka集群數(shù)據(jù)不均衡。
當(dāng)Broker收到消息,根據(jù)分區(qū)算法選擇將其存儲到哪一個 Partition。其路由機(jī)制為優(yōu)先按照指定Partition來路由;若未指定patition但指定key,則通過對key的value進(jìn)行hash選出一個patition;如果patition和key都未指定,則輪詢選出一個patition。
Offset:偏移量,分區(qū)中的消息位置,由Kafka自身維護(hù),Consumer消費時也要保存一份Offset以維護(hù)消費過的消息位置。
Replication:同一個Partition可能會有多個副本,多個副本之間數(shù)據(jù)是一樣的,增加容錯性與可擴(kuò)展性。
注:
當(dāng)集群中的有Broker掛掉的情況,系統(tǒng)可以主動的使用Replication提供服務(wù)。
系統(tǒng)默認(rèn)設(shè)置每一個Topic的Replication系數(shù)為1,可以在創(chuàng)建Topic時單獨設(shè)置。
Replication的基本單位是Topic的Partition。
所有的讀和寫都由Leader進(jìn),F(xiàn)ollowers只是做為數(shù)據(jù)的備份。
Follower必須能夠及時復(fù)制Leader的數(shù)據(jù)。
Replication Leader:一個Partition的多個副本上,需要一個Leader負(fù)責(zé)該Partition上與Producer和Consumer交互。一個Partition只對應(yīng)一個Replication Leader。
Replication Follower:Follower跟隨Leader,所有寫請求都會廣播給所有Follower,F(xiàn)ollower與Leader保持?jǐn)?shù)據(jù)同步。
ReplicaManager:負(fù)責(zé)管理當(dāng)前Broker所有分區(qū)和副本的信息,處理KafkaController發(fā)起的一些請求,副本狀態(tài)的切換、添加/讀取消息等。
Rebalance。消費者組內(nèi)某個消費者實例掛掉后,其他消費者實例自動重新分配訂閱主題分區(qū)的過程。Rebalance是Kafka消費者端實現(xiàn)高可用的重要手段。
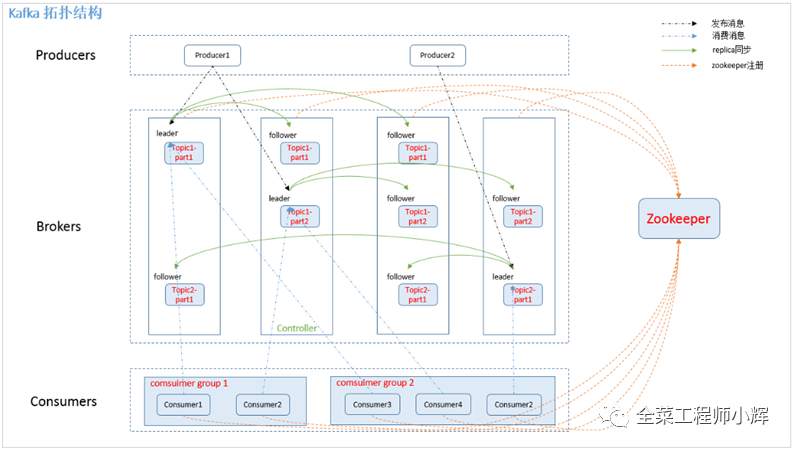
Kafka通過Zookeeper管理集群配置,選舉Leader,以及在Consumer Group發(fā)生變化時進(jìn)行Rebalance。
Kafka的復(fù)制機(jī)制
如何將所有Replication均勻分布到整個集群
為了更好的做負(fù)載均衡,Kafka盡量將所有的Partition均勻分配到整個集群上。一個典型的部署方式是一個Topic的Partition數(shù)量大于Broker的數(shù)量。同時為了提高Kafka的容錯能力,也需要將同一個Partition的Replication盡量分散到不同的機(jī)器。如果所有的Replication都在同一個Broker上,那一旦該Broker宕機(jī),該Partition的所有Replication都無法工作,也就達(dá)不到HA的效果。同時,如果某個Broker宕機(jī)了,需要保證它上面的負(fù)載可以被均勻的分配到其它幸存的所有Broker上。
Kafka分配Replication的算法如下:
將所有Broker(假設(shè)共n個Broker)和待分配的Partition排序。
將第i個Partition分配到第(i % n)個Broker上。
將第i個Partition的第j個Replication分配到第((i + j) % n)個Broker上。
HW高水位與LEO
HW是High Watermark的縮寫,俗稱高水位,它標(biāo)識了一個特定的消息偏移量(Offset),消費者只能拉取到這個Offset之前的消息。

如圖所示,它代表一個日志文件,這個日志文件中有 9 條消息,第一條消息的Offset(LogStartOffset)為0,最后一條消息的Offset為8,Offset為9的消息用虛線框表示,代表下一條待寫入的消息。日志文件的HW為6,表示消費者只能拉取到Offset在0至5之間的消息,而Offset為6的消息對消費者而言是不可見的。
LEO是Log End Offset的縮寫,它標(biāo)識當(dāng)前日志文件中下一條待寫入消息的Offset,圖中Offset為9的位置即為當(dāng)前日志文件的LEO,LEO的大小相當(dāng)于當(dāng)前日志分區(qū)中最后一條消息的Offset值加1。分區(qū)ISR集合中的每個副本都會維護(hù)自身的LEO,而ISR集合中最小的LEO即為分區(qū)的HW,對消費者而言只能消費HW之前的消息。
ISR副本集合
ISR全稱是“In-Sync Replicas”,是分區(qū)中正在與Leader副本進(jìn)行同步的Replication列表。正常情況下ISR必定包含Leader副本。
ISR列表是持久化在Zookeeper中的,任何在ISR列表中的副本都有資格參與Leader選舉。
ISR列表是動態(tài)變化的,副本被包含在ISR列表中的條件是由參數(shù)replica.lag.time.max.ms控制的,參數(shù)含義是副本同步落后于Leader的最大時間間隔,默認(rèn)10s,意思就是如果說某個Follower所在的Broker因為JVM FullGC之類的問題,卡頓相對Leader延時超過10s,就會被從 ISR 中排除。Kafka之所以這樣設(shè)計,主要是為了減少消息丟失,只有與Leader副本進(jìn)行實時同步的Follower副本才有資格參與Leader選舉,這里指相對實時。
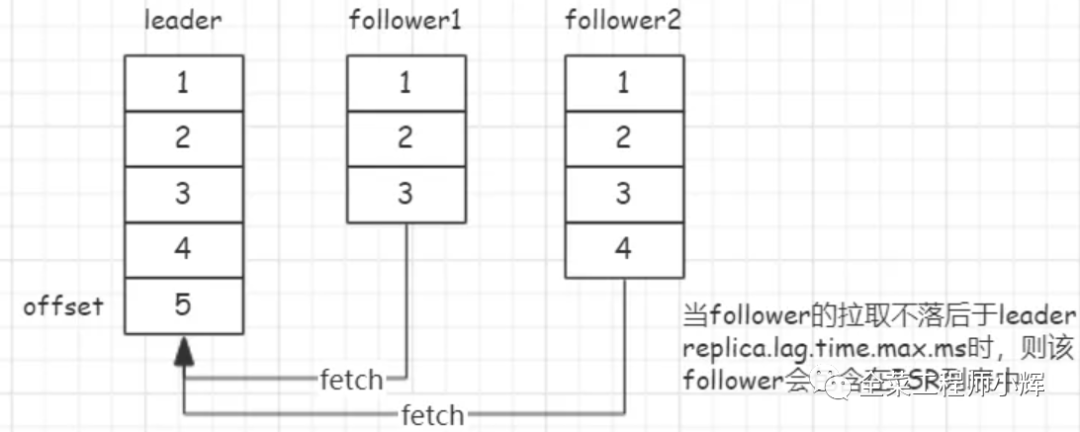
注:
分區(qū)中的所有副本統(tǒng)稱為AR(Assigned Replicas)。ISR集合是AR集合中的一個子集。
與Leader副本同步滯后過多的副本(不包括Leader副本)組成OSR(Out-of-Sync Replicas)
復(fù)制機(jī)制
如圖所示,假設(shè)某個分區(qū)的ISR集合中有3個副本,即一個Leader副本和2個Follower副本,此時分區(qū)的LEO和HW都為3。消息3和消息4從生產(chǎn)者發(fā)出之后會被先存入Leader副本。
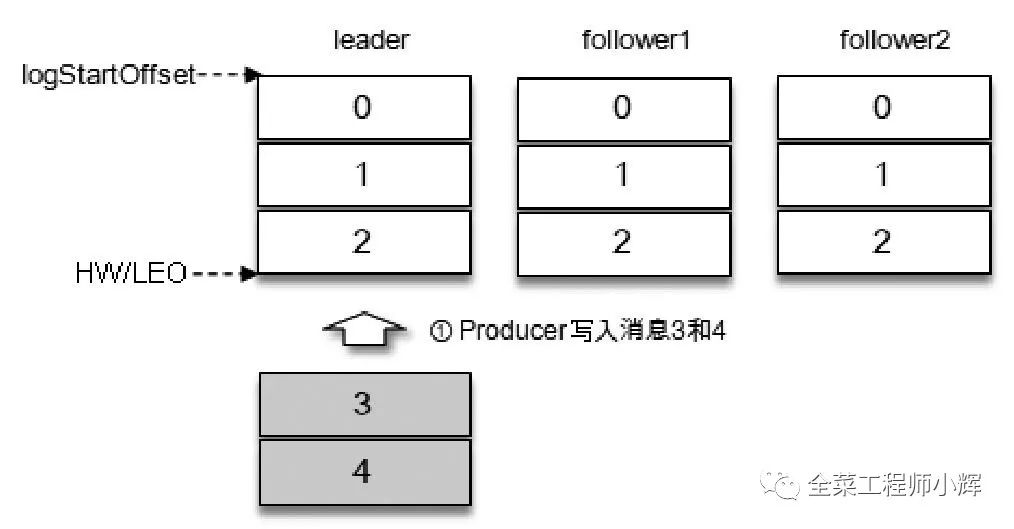
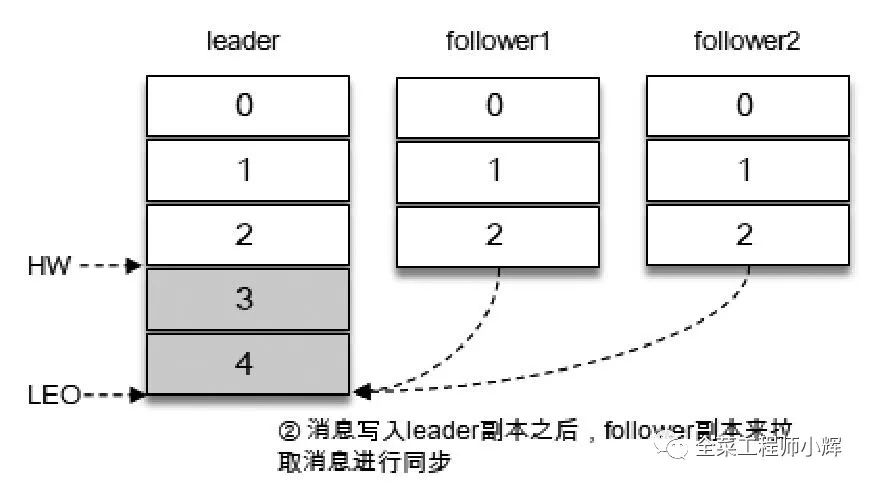
在消息寫入Leader副本之后,F(xiàn)ollower副本會發(fā)送拉取請求來拉取消息3和消息4以進(jìn)行消息同步。
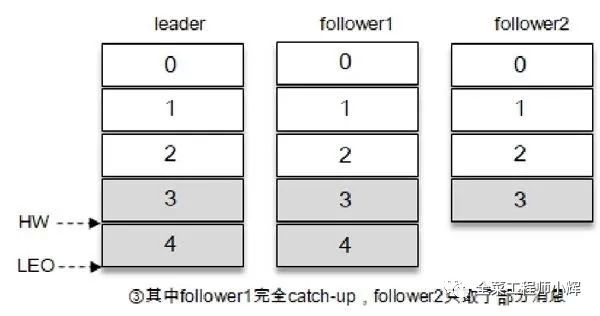
在同步過程中,不同的Follower副本的同步效率也不盡相同。在某一時刻Follower1完全跟上了Leader副本而Follower2只同步了消息3,如此Leader副本的LEO為5,F(xiàn)ollower1的LEO為5,F(xiàn)ollower2的LEO為4,那么當(dāng)前分區(qū)的HW取最小值4,此時消費者可以消費到offset為0至3之間的消息。
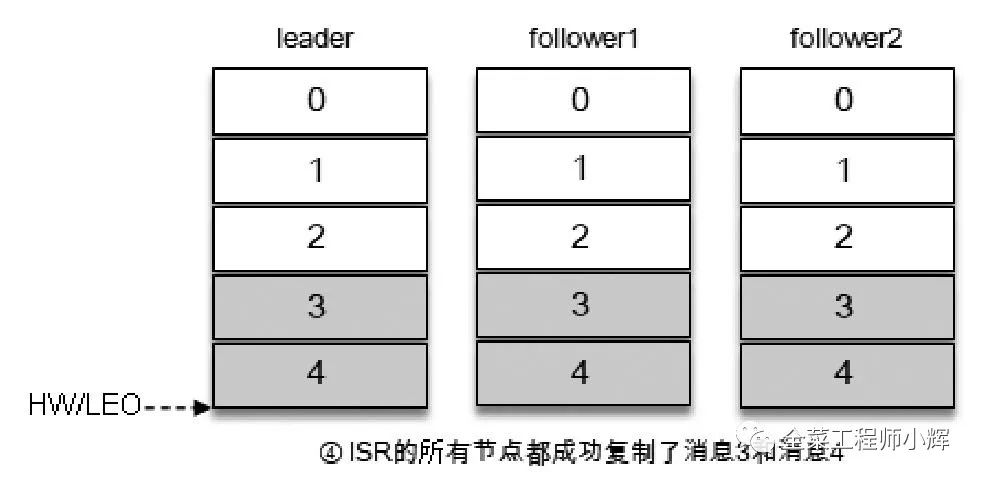
當(dāng)所有的副本都成功寫入了消息3和消息4,整個分區(qū)的HW和LEO都變?yōu)?,因此消費者可以消費到offset為4的消息了。
關(guān)于讀寫分離
Kafka并不支持讀寫分區(qū),生產(chǎn)消費端所有的讀寫請求都是由Replication Leader副本處理的,Replication Follower副本的主要工作就是從Leader副本處異步拉取消息,進(jìn)行消息數(shù)據(jù)的同步,并不對外提供讀寫服務(wù)。
Kafka之所以這樣設(shè)計,主要是為了保證讀寫一致性,因為副本同步是一個異步的過程,如果當(dāng)Follower副本還沒完全和Leader同步時,從Follower副本讀取數(shù)據(jù)可能會讀不到最新的消息。
Kafka的消息發(fā)送機(jī)制
Producer采用push模式將消息發(fā)布到Broker,每條消息都被append到patition中,屬于順序?qū)懘疟P(順序?qū)懘疟P效率比隨機(jī)寫內(nèi)存要高,保障kafka吞吐率)。
Producer寫入消息序列圖如下所示:
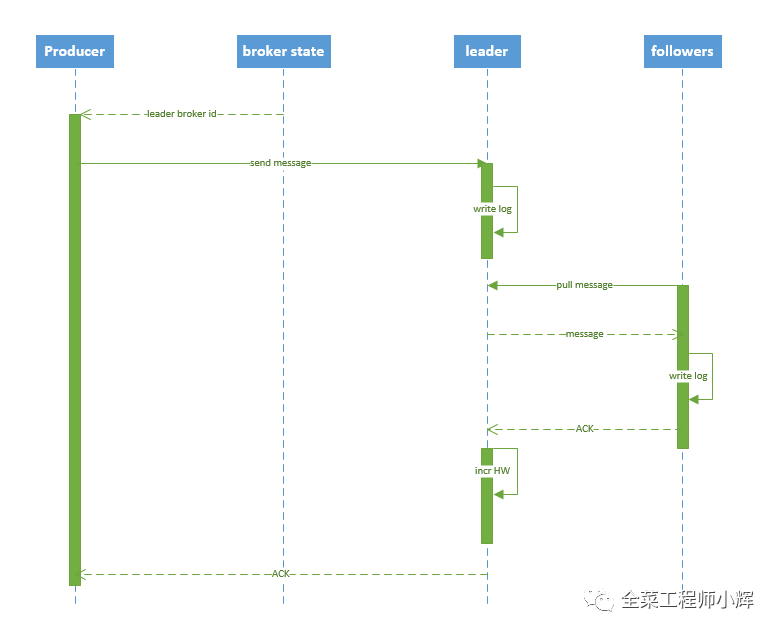
流程說明:
Producer先從Zookeeper的"/brokers/.../state"節(jié)點找到該Partition的Leader。
Producer將消息發(fā)送給該Leader。
Leader將消息寫入本地log。
followers從Leader pull消息,寫入本地log后Leader發(fā)送ACK。
Leader收到所有ISR中的replica的ACK后,增加HW并向Producer發(fā)送ACK。
Broker保存消息
每個patition物理上對應(yīng)一個文件夾(該文件夾存儲該patition的所有消息和索引文件)
無論消息是否被消費,Kafka都會保留所有消息。有兩種策略可以刪除舊數(shù)據(jù):
基于時間:log.retention.hours=168
基于大小:log.retention.bytes=1073741824
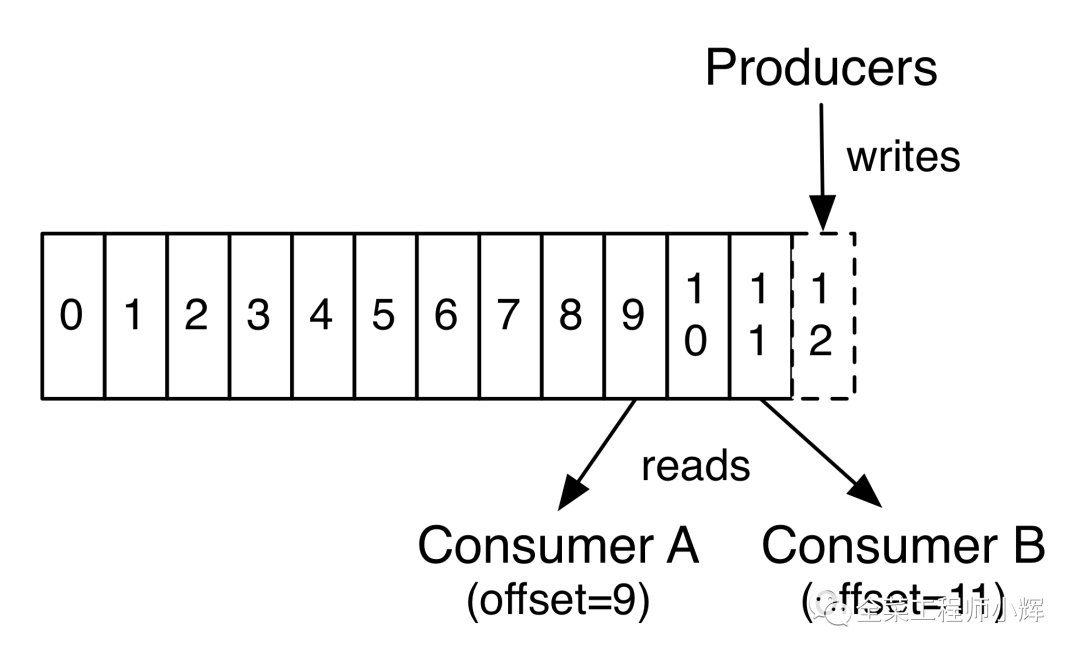
Consumer消費消息
Kafka集群保持所有的消息,直到它們過期(無論消息是否被消費)。實際上消費者所持有的僅有的元數(shù)據(jù)就是這個offset(偏移量),也就是說offset由消費者來控制:正常情況當(dāng)消費者消費消息的時候,偏移量也線性的的增加。但是實際偏移量由消費者控制,消費者可以將偏移量重置為更早的位置,重新讀取消息。可以看到這種設(shè)計對消費者來說操作自如,一個消費者的操作不會影響其它消費者對此log的處理。
參考:
一文看懂大數(shù)據(jù)領(lǐng)域的六年巨變:https://www.infoq.cn/article/b8*EMm6AeiHDfI3SfT11
https://kafka.apache.org/documentation/
https://stackoverflow.com/questions/tagged/apache-kafka?sort=newest&pageSize=15
Kafka權(quán)威指南