
【數(shù)據(jù)競(jìng)賽】天池蛋白質(zhì)結(jié)構(gòu)預(yù)測(cè)大賽總結(jié)
比賽名稱:蛋白質(zhì)結(jié)構(gòu)預(yù)測(cè)大賽
比賽鏈接:https://tianchi.aliyun.com/competition/entrance/231781/information
比賽類型:自然語(yǔ)言處理
分享內(nèi)容:Top5分享
比賽背景
蛋白質(zhì)是生命活動(dòng)中重要的組成,蛋白質(zhì)的結(jié)構(gòu)決定了蛋白質(zhì)在生命活動(dòng)中的功能,因此對(duì)蛋白質(zhì)結(jié)構(gòu)進(jìn)行分析具有重要的實(shí)際意義。蛋白質(zhì)結(jié)構(gòu)又可分為一級(jí)結(jié)構(gòu),二級(jí)結(jié)構(gòu),三級(jí)結(jié)構(gòu)和四級(jí)結(jié)構(gòu)。
目前已知一部分氨基酸序列和與其對(duì)應(yīng)的二級(jí)結(jié)構(gòu),通過已有數(shù)據(jù)尋找一級(jí)結(jié)構(gòu)到二級(jí)結(jié)構(gòu)的映射模型,提高通過氨基酸序列進(jìn)行蛋白質(zhì)二級(jí)結(jié)構(gòu)預(yù)測(cè)的準(zhǔn)確性。
比賽數(shù)據(jù)
對(duì)應(yīng)的蛋白質(zhì)氨基酸序列與二級(jí)結(jié)構(gòu)序列共20000組,氨基酸序列和二級(jí)結(jié)構(gòu)序列分別按行對(duì)應(yīng)存放于data_seq_train和data_sec_train文件中構(gòu)成訓(xùn)練數(shù)據(jù),蛋白質(zhì)序列長(zhǎng)度不盡相同,每條蛋白質(zhì)序列與二級(jí)結(jié)構(gòu)序列長(zhǎng)度相同,蛋白質(zhì)序列中字母表示氨基酸類型,二級(jí)結(jié)構(gòu)字母對(duì)應(yīng)當(dāng)前氨基酸構(gòu)成的二級(jí)結(jié)構(gòu),二級(jí)結(jié)構(gòu)中的空白也是一種松散結(jié)構(gòu)的表示。
數(shù)據(jù)樣本:
氨基酸序列:GIVEQCCTSICSLYQLENYCN 二級(jí)結(jié)構(gòu)序列:TTTTSSS HHHHHTTB
Top1方案分享
分享原文:https://tianchi.aliyun.com/forum/postDetail?postId=98363
開源代碼:https://github.com/wudejian789/2020TIANCHI-ProteinSecondaryStructurePrediction-TOP1
賽題理解
本題為根據(jù)蛋白質(zhì)的一級(jí)結(jié)構(gòu)預(yù)測(cè)其二級(jí)結(jié)構(gòu),經(jīng)過比賽期間組內(nèi)師兄的講解,我對(duì)蛋白質(zhì)一級(jí)結(jié)構(gòu)二級(jí)結(jié)構(gòu)的理解如下,如有錯(cuò)誤,歡迎指正。
蛋白質(zhì)可以看成是一條氨基酸序列,在空間中是一種相互交錯(cuò)螺旋的結(jié)構(gòu),像一條互相纏繞的繩子:
這種三維結(jié)構(gòu)叫做蛋白質(zhì)的三級(jí)結(jié)構(gòu),而如果不考慮結(jié)構(gòu)的三維性,或者說把這整條序列拉直,用一個(gè)一維的序列表示,這便是得到了蛋白質(zhì)的一級(jí)結(jié)構(gòu):
GPTGTGESKCPLMVKVLDAV······
這些字母G、A、V等便是代表一個(gè)個(gè)的氨基酸,其中主要包含有20種常見的氨基酸。
用這樣的序列表示蛋白質(zhì)比起原始的三維結(jié)構(gòu)確實(shí)方便不少,但卻丟失了三維的結(jié)構(gòu)信息,蛋白質(zhì)的結(jié)構(gòu)決定其功能,這里的結(jié)構(gòu)不止是序列本身,更多的還依賴其三維結(jié)構(gòu)。
因此便出現(xiàn)了蛋白質(zhì)的二級(jí)結(jié)構(gòu),它是一條與一級(jí)結(jié)構(gòu)長(zhǎng)度相等的一維序列,用以表征一級(jí)結(jié)構(gòu)種的各位置的氨基酸在三維空間種的形態(tài),以保留一部分的三維結(jié)構(gòu)信息。
這里的' '、'E'、'T'等都是對(duì)應(yīng)位置的氨基酸在空間種的形態(tài)(與一級(jí)結(jié)構(gòu) GPTGTGESKCPLMVKVLDAV······ 是一一對(duì)應(yīng)的),例如'T'代表的就是該位置的氨基酸在空間中是一種氫鍵轉(zhuǎn)折的形態(tài)。
本賽題就是需要通過蛋白質(zhì)的一級(jí)結(jié)構(gòu),預(yù)測(cè)其二級(jí)結(jié)構(gòu),在深度學(xué)習(xí)種是一種典型的N-N的seq2seq問題。
賽題理解
不難想到,蛋白質(zhì)三維結(jié)構(gòu)的形成,其實(shí)主要是受某些力的作用,不同氨基酸的分子量、體積、質(zhì)量等性質(zhì)都有差異,這些小分子間會(huì)受到分子間作用力的影響,換句話說,分子間作用力等多種因素共同作用,讓蛋白質(zhì)形成了這樣的一種相對(duì)穩(wěn)定的空間結(jié)構(gòu),以達(dá)到一種穩(wěn)態(tài);而倘若你強(qiáng)行把它拉直,它也會(huì)由于受力不均,又開始相互纏繞,以達(dá)到穩(wěn)態(tài)。
因此,對(duì)于某條蛋白質(zhì)的二級(jí)結(jié)構(gòu)中第i個(gè)位置的空間形態(tài),其不止是取決于對(duì)應(yīng)一級(jí)結(jié)構(gòu)中位置i的氨基酸,還取決于位置i周圍氨基酸甚至整條序列的情況。
定義一級(jí)結(jié)構(gòu)中位置i及其上下文的整條片段為X,對(duì)應(yīng)的二級(jí)結(jié)構(gòu)中位置i的形態(tài)為Y,我統(tǒng)計(jì)了整個(gè)訓(xùn)練數(shù)據(jù)中 P(Y|X) 的情況,并計(jì)算了在不同窗口大小時(shí)。
思路分享
這類題首先需要解決的是輸入序列的編碼問題,很自然的可以想到onehot和word2vec兩種編碼方法,本次賽題我們都進(jìn)行了嘗試。
Onehot與基本理化性質(zhì)編碼+滑窗法+淺層NN
氨基酸的基本理化性質(zhì)包括分子量、等電點(diǎn)、解離常數(shù)、范德華半徑、水中溶解度、側(cè)臉疏水性,以及形成α螺旋可能性、形成β螺旋可能性、轉(zhuǎn)向概率等(來自Chou-Fasman算法),這些數(shù)據(jù)百度都很容易找到。
然后是窗口大小的選擇。經(jīng)過測(cè)試,隱層節(jié)點(diǎn)數(shù)為1024,當(dāng)窗口大小達(dá)到79以上時(shí),線下MaF達(dá)到飽和,為0.749。再調(diào)節(jié)隱層大小為2048,最后的線下MaF為0.767。
該模型提交后線上結(jié)果為0.7312。(滑窗模型其實(shí)等價(jià)于基于整條序列的CNN模型)
Word2vec+深層NN
NN的結(jié)構(gòu)設(shè)計(jì)主要參考論文《Protein Secondary Structure Prediction Using Cascaded Convolutional and Recurrent Neural Networks》,這是一篇使用深度學(xué)習(xí)進(jìn)行蛋白質(zhì)二級(jí)結(jié)構(gòu)預(yù)測(cè)的經(jīng)典論文,文中使用了CNN+BiGRU的結(jié)構(gòu)進(jìn)行蛋白質(zhì)二級(jí)結(jié)構(gòu)預(yù)測(cè),模型結(jié)構(gòu)如下:
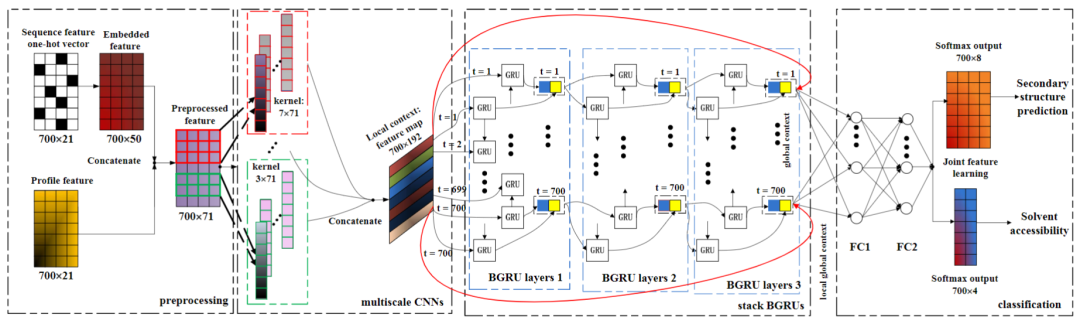
該模型先通過CNN捕獲局部信息,再通過RNN融入全局信息,是NLP長(zhǎng)文本任務(wù)的常見baseline模型。這里基本照搬了模型結(jié)構(gòu),但將編碼部分改為了word2vec預(yù)訓(xùn)練的結(jié)構(gòu),詞向量大小為128,其它結(jié)構(gòu)和參數(shù)與原文一致,文章可從github項(xiàng)目目錄進(jìn)行下載。
此處還需注意一定的是,如果embedding層是單獨(dú)對(duì)每個(gè)氨基酸進(jìn)行編碼的話,那么詞表大小為23(數(shù)據(jù)集中共23種字母)。而在NLP種經(jīng)常用到的一種叫做n-gram的技術(shù),即將多個(gè)詞綁定在以此形成整體,這個(gè)技術(shù)在蛋白質(zhì)序列種也用得比較多,成為k-mers。
倘若使用k-mers構(gòu)建詞表的話,假定k=3,那么詞表的大小就是232323=12167,這樣相當(dāng)于在編碼時(shí)將上下文也考慮了進(jìn)去,增加了詞的多樣性,在一定程度上可以提高模型的學(xué)習(xí)能力,但也會(huì)增大過擬合的風(fēng)險(xiǎn)。
這里我也分別嘗試了k=1和k=3的兩個(gè)模型情況,線下分別為0.719和0.706,線上分別為0.7576和0.7518。
這兩個(gè)模型的輸入和數(shù)據(jù)劃分都有較大差異,顯然會(huì)有一定的融合收益,將二者的結(jié)果進(jìn)行加權(quán)平均后,線上結(jié)果為0.7702。
最終模型
將以上幾個(gè)模型的特征輸入都有著較大不同,進(jìn)行簡(jiǎn)單加權(quán)融合后,線上結(jié)果到達(dá)0.7770。
在得到以上結(jié)果后,進(jìn)一步分析問題:
模型真正學(xué)會(huì)的到底是什么:模型主要是記憶了大量由X->Y的固定映射或搭配,然后根據(jù)不同搭配的置信度進(jìn)行決策,學(xué)會(huì)如何權(quán)衡不同搭配以得到更加正確的結(jié)果,這也是選用單層小窗口CNN時(shí)嚴(yán)重欠擬合的原因。
氨基酸的編碼表示:蛋白質(zhì)總共包括的氨基酸種類較少,在本數(shù)據(jù)中只有23種,只需要一個(gè)23維的onehot向量就可以表示,這也是簡(jiǎn)單的onehot編碼+大窗口CNN能如此有效的原因,也驗(yàn)證了前面的觀點(diǎn),即模型主要是記憶了大量由X->Y的隱射,預(yù)測(cè)時(shí)根據(jù)所記憶的大量先驗(yàn)知識(shí),對(duì)輸出進(jìn)行決策。
綜上,我們?cè)O(shè)計(jì)了最終的模型:在3.2部分的模型中,將embedding部分改成了25維onehot編碼+14維理化特征+25維word2vec特征,其中onehot和理化特征部分在訓(xùn)練過程中是frozen的,而word2vec會(huì)隨著訓(xùn)練進(jìn)行finetune;其次是加大了CNN部分的窗口,設(shè)置成了[1,9,81]。
最終按次方案訓(xùn)練了一個(gè)3折的模型,線下MaF平均為0.756。將3折的模型加權(quán)平均后線上分?jǐn)?shù)為0.7832。
Top2方案分享
分享原文:https://tianchi.aliyun.com/notebook-ai/detail?postId=97920
建模思路
由于氨基酸序列和二級(jí)結(jié)構(gòu)序列的長(zhǎng)度相等,我們考慮將序列中的某個(gè)氨基酸作為樣本 ,其對(duì)應(yīng)位置的二級(jí)結(jié)構(gòu)作為標(biāo)簽 ,作為多分類任務(wù)。下面部分的代碼進(jìn)行數(shù)據(jù)預(yù)處理,將原始數(shù)據(jù)轉(zhuǎn)換為單個(gè)氨基酸的樣本,并保留了序列順序,以id標(biāo)記屬于統(tǒng)一序列的氨基酸。
特征工程
作為樹模型中非常重要的一部分,我們考慮了這些特征:
首先將氨基酸和二級(jí)序列編碼為連續(xù)的數(shù)值型變量(label encode),以便輸入模型。 除了當(dāng)前位置的氨基酸外,構(gòu)造前后各20個(gè)氨基酸的shift特征,并都作為categorical feature輸入模型。 將當(dāng)前氨基酸所屬蛋白質(zhì)序列含有的各種氨基酸數(shù)目和占比作為特征。 將當(dāng)前位置的氨基酸及其前后各10個(gè)氨基酸作為窗口,統(tǒng)計(jì)各類氨基酸的數(shù)目。
以下的特征嘗試過,但收效甚微,后續(xù)不予考慮:
氨基酸的PseAA特征(一些理化屬性)及相關(guān)特征。 氨基酸word2vec后的embedding向量
模型訓(xùn)練及tricks
首先用了6折交叉驗(yàn)證(cv)進(jìn)行訓(xùn)練,每折大概450輪左右早停。然而docker提交運(yùn)行時(shí)間限制30分鐘,測(cè)試集上預(yù)測(cè)如果使用交叉驗(yàn)證的模型,預(yù)測(cè)時(shí)間完全不夠。
考慮使用全部訓(xùn)練集進(jìn)行訓(xùn)練,手動(dòng)調(diào)試迭代輪數(shù)。提交時(shí)發(fā)現(xiàn)全數(shù)據(jù)訓(xùn)練的模型大概使用580輪為最佳,30分鐘可以運(yùn)行兩個(gè)全數(shù)據(jù)訓(xùn)練模型,因此使用了兩個(gè)全數(shù)據(jù)訓(xùn)練模型的融合。
Top3方案分享
分享原文:https://tianchi.aliyun.com/notebook-ai/detail?postId=98092
開源代碼:https://github.com/yjh126yjh/TianChi_Protein-Secondary-Structure-Prediction
特征選擇與處理
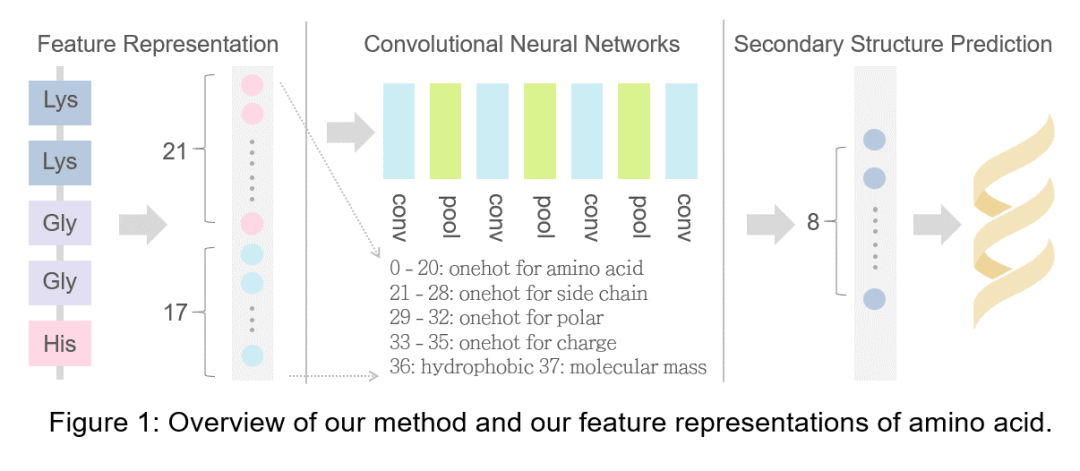
由于自然界中只存在20種常見氨基酸,題目中出現(xiàn)23種,有2種特別少,我們按照生物學(xué)對(duì)氨基酸的分類標(biāo)準(zhǔn)將其歸入X,代表未知氨基酸。
對(duì)于一個(gè)一級(jí)結(jié)構(gòu)的字母,我們選擇38維的特征向量來表示它,其中前21維為21種氨基酸的onehot,考慮到氨基酸側(cè)鏈性質(zhì)對(duì)結(jié)構(gòu)影響較大,我們?cè)O(shè)置后17維為氨基酸的理化性質(zhì)onehot,這里理化性質(zhì)主要包括側(cè)鏈殘基的類別,帶電性,極性,親疏水性,相對(duì)分子量等,具體數(shù)據(jù)來源于Table of standard amino acid abbreviations and properties。
此外,為了便于處理,我們統(tǒng)一將不同長(zhǎng)度的氨基酸序列padding到700,保證比目前已知的最長(zhǎng)氨基酸序列長(zhǎng),因此20000條氨基酸序列處理后可得到(20000 × 700 × 38)。
模型介紹與訓(xùn)練
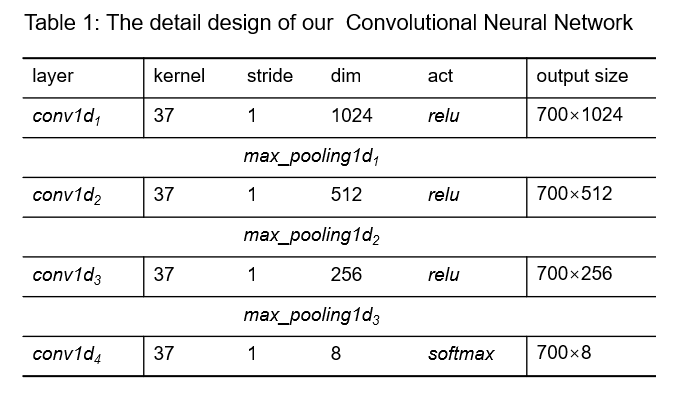
我們使用了一個(gè)樸素的四層卷積神經(jīng)網(wǎng)絡(luò)模型,每層的kernel_size均選擇37,以一個(gè)較大的局部感受野模擬氨基酸序列的長(zhǎng)程作用,使用較高維度的輸出通道學(xué)習(xí)更多更復(fù)雜的特征,同時(shí)使用dropout和pooling防止過擬合。我們使用95%的數(shù)據(jù)用于訓(xùn)練,5%的數(shù)據(jù)用于驗(yàn)證,網(wǎng)絡(luò)訓(xùn)練時(shí)的參數(shù)如下:
-learning_rate: 0.00005
-drop_out: 0.4
-batch_dim: 128
-nn_epochs: 300
-loss: 'categorical_crossentropy'
-optimizers: Adam
在我們四塊2080Ti的機(jī)器上,大概40s一個(gè)epoch,然后大概在280 epoch的時(shí)候有最佳結(jié)果,最佳score對(duì)應(yīng)的模型參數(shù)及測(cè)試的代碼均上傳GitHub。
Top5方案分享
分享原文:https://tianchi.aliyun.com/notebook-ai/detail?postId=98009
本方案將賽題建模為一維的語(yǔ)義分割,主要看重語(yǔ)義分割模型能夠?qū)崿F(xiàn)“像素點(diǎn)”的分類。采用的特征有:
氨基酸代號(hào)onehot 氨基酸理化特征:疏水值,帶電性,分子量,pI,族類,Pa,Pb,Pt,Fi,Fi1,Fi2,Fi3,Pe
由于本人非生化相關(guān)專業(yè),故僅僅是從論文、百科中搜集到特征值并直接使用,并未作進(jìn)一步分析。
特征構(gòu)造
經(jīng)分析,題目中的氨基酸序列除了常見的20種氨基酸外,還有3種氨基酸。由于僅查到了20種常見氨基酸的特征數(shù)據(jù),故對(duì)這3種氨基酸的特征分別采用-1、-2、-3填充。
數(shù)值特征歸一化到[0,1]區(qū)間,“族類”特征采用onehot編碼。對(duì)序列進(jìn)行padding使長(zhǎng)度一致,padding的部分采用新的onehot編碼以示區(qū)分,特征值填充為全0。
網(wǎng)絡(luò)構(gòu)造
網(wǎng)絡(luò)構(gòu)造參考了EfficientDet中的BiFPN結(jié)構(gòu),大幅簡(jiǎn)化了backbone層數(shù)。經(jīng)測(cè)試kernel size稍大些效果較好。
focal_loss效果不佳, mobile block拖慢了訓(xùn)練速度,實(shí)際上沒有使用。這里為了程序的完整性予以保留。
往期精彩回顧
本站qq群851320808,加入微信群請(qǐng)掃碼: