
求求你別再用OFFSET和LIMIT分頁了
點擊上方藍(lán)色字體,選擇“標(biāo)星公眾號”
優(yōu)質(zhì)文章,第一時間送達(dá)
作者 | Ivo Pereira? ?譯者 | 無名??策劃 | 小智
不需要擔(dān)心數(shù)據(jù)庫性能優(yōu)化問題的日子已經(jīng)一去不復(fù)返了。
隨著時代的進(jìn)步,隨著野心勃勃的企業(yè)想要變成下一個 Facebook,隨著為機(jī)器學(xué)習(xí)預(yù)測收集盡可能多數(shù)據(jù)的想法的出現(xiàn),作為開發(fā)人員,我們要不斷地打磨我們的 API,讓它們提供可靠和有效的端點,從而毫不費力地瀏覽海量數(shù)據(jù)。
如果你做過后臺開發(fā)或數(shù)據(jù)庫架構(gòu),你可能是這么分頁的:
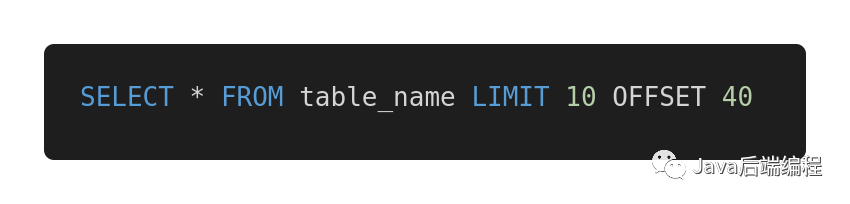
如果你真的是這么分頁,那么我不得不抱歉地說,你這樣做是錯的。
你不以為然?沒關(guān)系。Slack、Shopify 和 Mixmax 這些公司都在用我們今天將要討論的方式進(jìn)行分頁。
我想你很難找出一個不使用 OFFSET 和 LIMIT 進(jìn)行數(shù)據(jù)庫分頁的人。對于簡單的小型應(yīng)用程序和數(shù)據(jù)量不是很大的場景,這種方式還是能夠“應(yīng)付”的。
如果你想從頭開始構(gòu)建一個可靠且高效的系統(tǒng),在一開始就要把它做好。
今天我們將探討已經(jīng)被廣泛使用的分頁方式存在的問題,以及如何實現(xiàn)高性能分頁。
1OFFSET 和 LIMIT 有什么問題?
正如前面段落所說的那樣,OFFSET 和 LIMIT 對于數(shù)據(jù)量少的項目來說是沒有問題的。
但是,當(dāng)數(shù)據(jù)庫里的數(shù)據(jù)量超過服務(wù)器內(nèi)存能夠存儲的能力,并且需要對所有數(shù)據(jù)進(jìn)行分頁,問題就會出現(xiàn)。
為了實現(xiàn)分頁,每次收到分頁請求時,數(shù)據(jù)庫都需要進(jìn)行低效的全表掃描。
什么是全表掃描?全表掃描 (又稱順序掃描) 就是在數(shù)據(jù)庫中進(jìn)行逐行掃描,順序讀取表中的每一行記錄,然后檢查各個列是否符合查詢條件。這種掃描是已知最慢的,因為需要進(jìn)行大量的磁盤 I/O,而且從磁盤到內(nèi)存的傳輸開銷也很大。
這意味著,如果你有 1 億個用戶,OFFSET 是 5 千萬,那么它需要獲取所有這些記錄 (包括那么多根本不需要的數(shù)據(jù)),將它們放入內(nèi)存,然后獲取 LIMIT 指定的 20 條結(jié)果。
也就是說,為了獲取一頁的數(shù)據(jù):
10萬行中的第5萬行到第5萬零20行
需要先獲取 5 萬行。這么做是多么低效?
如果你不相信,可以看看這個例子:
https://www.db-fiddle.com/f/3JSpBxVgcqL3W2AzfRNCyq/1?ref=hackernoon.com
左邊的 Schema SQL 將插入 10 萬行數(shù)據(jù),右邊有一個性能很差的查詢和一個較好的解決方案。只需單擊頂部的 Run,就可以比較它們的執(zhí)行時間。第一個查詢的運行時間至少是第二個查詢的 30 倍。
數(shù)據(jù)越多,情況就越糟。看看我對 10 萬行數(shù)據(jù)進(jìn)行的 PoC。
https://github.com/IvoPereira/Efficient-Pagination-SQL-PoC?ref=hackernoon.com
現(xiàn)在你應(yīng)該知道這背后都發(fā)生了什么:OFFSET 越高,查詢時間就越長。
2替代方案
你應(yīng)該這樣做:

這是一種基于指針的分頁。
你要在本地保存上一次接收到的主鍵 (通常是一個 ID) 和 LIMIT,而不是 OFFSET 和 LIMIT,那么每一次的查詢可能都與此類似。
為什么?因為通過顯式告知數(shù)據(jù)庫最新行,數(shù)據(jù)庫就確切地知道從哪里開始搜索(基于有效的索引),而不需要考慮目標(biāo)范圍之外的記錄。
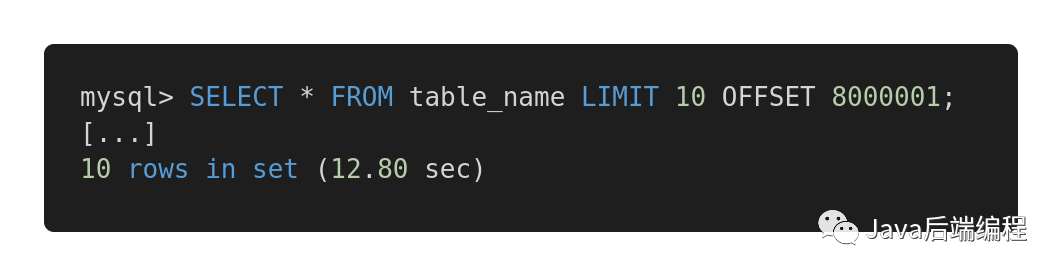

返回同樣的結(jié)果,第一個查詢使用了 12.80 秒,而第二個僅用了 0.01 秒。
要使用這種基于游標(biāo)的分頁,需要有一個惟一的序列字段 (或多個),比如惟一的整數(shù) ID 或時間戳,但在某些特定情況下可能無法滿足這個條件。
我的建議是,不管怎樣都要考慮每種解決方案的優(yōu)缺點,以及需要執(zhí)行哪種查詢。
如果需要基于大量數(shù)據(jù)做查詢操作,Rick James 的文章提供了更深入的指導(dǎo)。
http://mysql.rjweb.org/doc.php/lists
如果我們的表沒有主鍵,比如是具有多對多關(guān)系的表,那么就使用傳統(tǒng)的 OFFSET/LIMIT 方式,只是這樣做存在潛在的慢查詢問題。我建議在需要分頁的表中使用自動遞增的主鍵,即使只是為了分頁。
英文原文
https://hackernoon.com/please-dont-use-offset-and-limit-for-your-pagination-8ux3u4y
PS:歡迎在留言區(qū)留下你的觀點,一起討論提高。如果今天的文章讓你有新的啟發(fā),歡迎轉(zhuǎn)發(fā)分享給更多人。
Java后端編程交流群已成立
公眾號運營至今,離不開小伙伴們的支持。為了給小伙伴們提供一個互相交流的平臺,特地開通了官方交流群。掃描下方二維碼備注 進(jìn)群 或者關(guān)注公眾號 Java后端編程 后獲取進(jìn)群通道。
—————END—————
推薦閱讀:
最近面試BAT,整理一份面試資料《Java面試BAT通關(guān)手冊》,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構(gòu)等等。
獲取方式:關(guān)注公眾號并回復(fù)?666?領(lǐng)取,更多內(nèi)容陸續(xù)奉上。
明天見(??ω??)??