
Sharding-JDBC分庫連接數(shù)優(yōu)化
一、背景
配運平臺組的快遞訂單履約中心(cp-eofc)及物流平臺履約中心(jdl-uep-ofc)系統(tǒng)都使用了ShardingSphere生態(tài)的sharding-jdbc作為分庫分表中間件, 整個集群采用只分庫不分表的設(shè)計,共16個MYSQL實例,每個實例有32個庫,集群共512個庫.
當(dāng)每增加一臺客戶端主機,一個MYSQl實例最少要增加32個連接(通常都會使用連接池,根據(jù)配置的最大連接數(shù),這個連接數(shù)可能會放大5~10倍).并且通常一個系統(tǒng)都會分為web,provider,worker等多個應(yīng)用,這些應(yīng)用共用一套數(shù)據(jù)源.隨著應(yīng)用機器數(shù)的增加,MYSQL實例的連接數(shù)會很快達(dá)到上限,這就對系統(tǒng)的擴容造成了阻礙,無法橫向的增加機器數(shù),只能縱向的提高機器的配置來應(yīng)對流量的增長.
作為京東物流的核心系統(tǒng),業(yè)務(wù)增長迅速,系統(tǒng)所承接的流量也是逐漸增加,所以急需解決這個制約系統(tǒng)擴展的瓶頸點。
二、分庫分表的相關(guān)概念介紹
2.1 為什么要分庫分表
2.1.1 分庫
隨著業(yè)務(wù)的發(fā)展,單庫中的數(shù)據(jù)量不斷增加,數(shù)據(jù)庫的QPS會越來越高,對數(shù)據(jù)庫的讀寫耗時也會相應(yīng)的增長,這時單庫的讀寫性能必然會成為系統(tǒng)的瓶頸點.這時可以通過將單個數(shù)據(jù)庫拆分為多個數(shù)據(jù)庫的方法,來分擔(dān)數(shù)據(jù)庫的壓力,提升性能.同時多個數(shù)據(jù)庫分布在不同的機器上也提高了數(shù)據(jù)庫的可用性.
2.1.2 分表
隨著單表數(shù)據(jù)量的增加,對于數(shù)據(jù)的查詢和更新,即使在數(shù)據(jù)庫底層有一定的優(yōu)化,但是隨著量變必定會引起質(zhì)變,導(dǎo)致性能急劇下降.這時可以通過分表的方法,將單表數(shù)據(jù)按一定規(guī)則水平拆分到多個表中,減小單表的數(shù)據(jù)量,提升系統(tǒng)性能.
2.2 sharding-jdbc簡介
ShardingSphere
是一套開源的分布式數(shù)據(jù)庫中間件解決方案組成的生態(tài)圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(計劃中)這3款相互獨立的產(chǎn)品組成.他們均提供標(biāo)準(zhǔn)化的數(shù)據(jù)分片、分布式事務(wù)和數(shù)據(jù)庫治理功能,可適用于如Java同構(gòu)、異構(gòu)語言、容器、云原生等各種多樣化的應(yīng)用場景。
Sharding-JDBC
定位為輕量級Java框架,在Java的JDBC層提供的額外服務(wù)。它使用客戶端直連數(shù)據(jù)庫,以jar包形式提供服務(wù),無需額外部署和依賴,可理解為增強版的JDBC驅(qū)動,完全兼容JDBC和各種ORM框架。
適用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。基于任何第三方的數(shù)據(jù)庫連接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意實現(xiàn)JDBC規(guī)范的數(shù)據(jù)庫。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
我們先看下ShardingSphere官網(wǎng)給出的基于Spring命名空間的規(guī)則配置示例:
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:sharding="http://shardingsphere.io/schema/shardingsphere/sharding"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://shardingsphere.io/schema/shardingsphere/shardinghttp://shardingsphere.io/schema/shardingsphere/sharding/sharding.xsd"><!-數(shù)據(jù)源ds0-><bean id="ds0" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"><property name="driverClassName" value="com.mysql.jdbc.Driver" /><property name="url" value="jdbc:mysql://localhost:3306/ds0" /><property name="username" value="root" /><property name="password" value="" /></bean><!-數(shù)據(jù)源ds1-><bean id="ds1" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"><property name="driverClassName" value="com.mysql.jdbc.Driver" /><property name="url" value="jdbc:mysql://localhost:3306/ds1" /><property name="username" value="root" /><property name="password" value="" /></bean><!-分片策略-><sharding:inline-strategy id="databaseStrategy" sharding-column="user_id" algorithm-expression="ds$->{user_id % 2}" /><sharding:inline-strategy id="orderTableStrategy" sharding-column="order_id" algorithm-expression="t_order$->{order_id % 2}" /><sharding:inline-strategy id="orderItemTableStrategy" sharding-column="order_id" algorithm-expression="t_order_item$->{order_id % 2}" /><!-sharding數(shù)據(jù)源配置-><sharding:data-source id="shardingDataSource"><sharding:sharding-rule data-source-names="ds0,ds1"><sharding:table-rules><sharding:table-rule logic-table="t_order" actual-data-nodes="ds$->{0..1}.t_order$->{0..1}" database-strategy-ref="databaseStrategy" table-strategy-ref="orderTableStrategy" /><sharding:table-rule logic-table="t_order_item" actual-data-nodes="ds$->{0..1}.t_order_item$->{0..1}" database-strategy-ref="databaseStrategy" table-strategy-ref="orderItemTableStrategy" /></sharding:table-rules></sharding:sharding-rule></sharding:data-source></beans>
配置總結(jié):
-
需要配置多個數(shù)據(jù)源ds0,ds1;
-
分片策略中配置分片鍵(sharding-column)和分片表達(dá)式(algorithm-expression)需符合groovy語法;
-
在sharding數(shù)據(jù)源中<sharding:table-rule>標(biāo)簽中配置邏輯表名(logic-table),庫分片策略(database-strategy-ref)和表分片策略(table-strategy-ref),actual-data-node屬性由數(shù)據(jù)源名 + 表名組成,以小數(shù)點分隔,用于廣播表;
三、問題分析與解決方案
3.1 問題分析
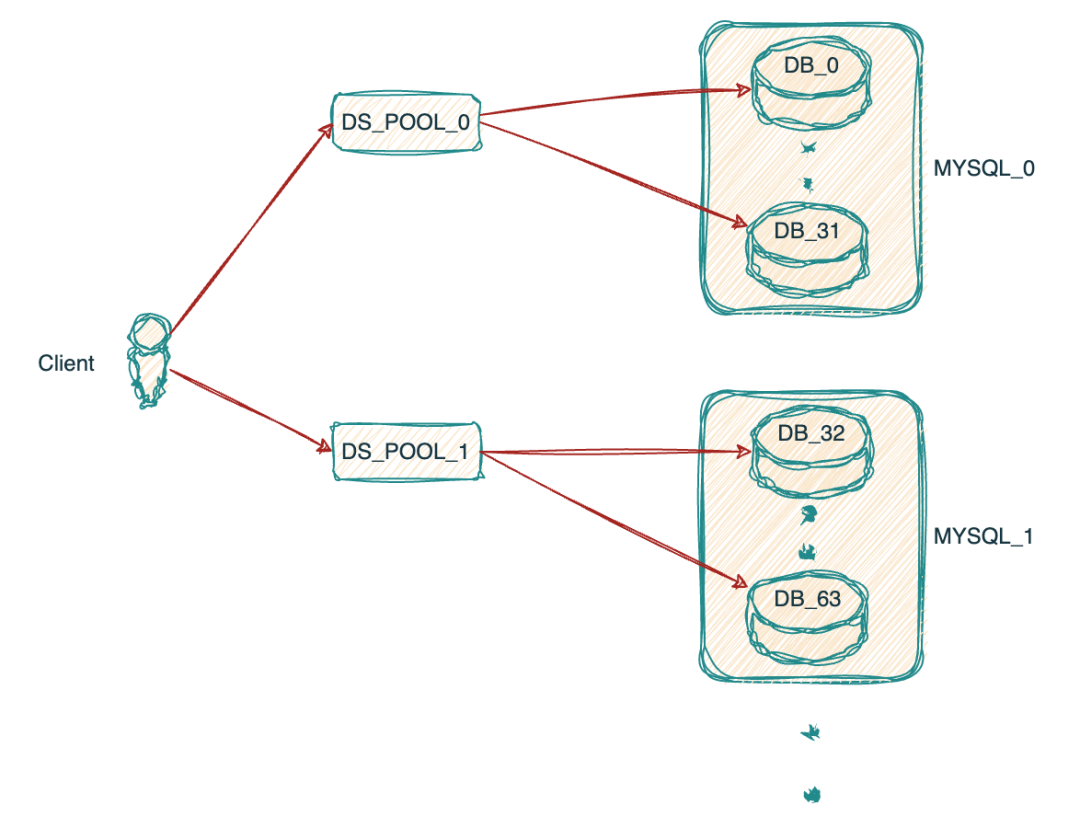
正如文章開頭提到的目前我們的MYSQL集群架構(gòu)如下,16個MYSQL實例,每個實例有32個庫,集群共512個庫.當(dāng)客戶端主機啟動后與MYSQL_0實例中的32個庫連接,分別會建立32個數(shù)據(jù)源,連接池配置的最大連接數(shù)為5,也就是說極端情況下一個客戶端與一個MYSQL實例最多會建立32*5=160個連接數(shù).對于物流的一些核心系統(tǒng)在大促時擴容上百臺是很常見的,所以很快單個實例的最大連接數(shù)就會觸達(dá)上限.
目前客戶端連接連接數(shù)據(jù)庫集群形式如圖所示:
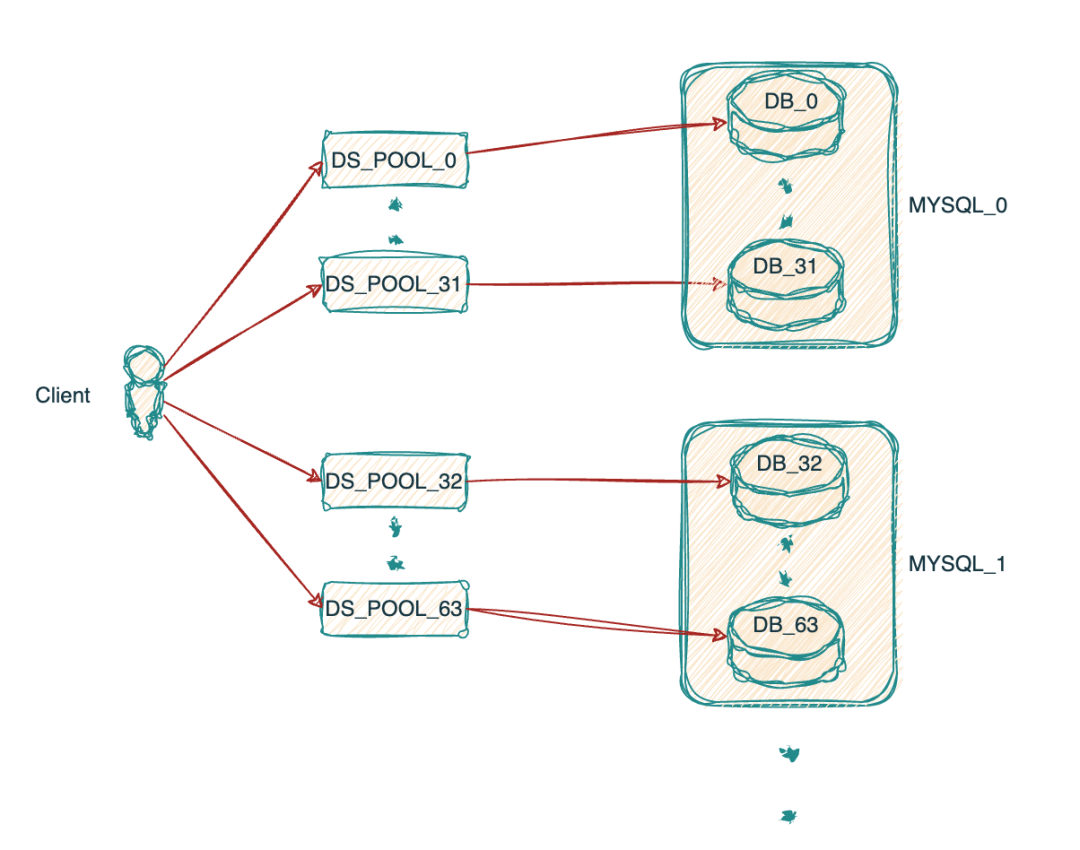
??3.2 可行方案
我們的目標(biāo)就是降低單個MYSQL實例的連接數(shù),其中我們共探討了幾種方案如下:
3.2.1 單實例不分庫只分表
這樣一個客戶端與單個數(shù)據(jù)庫實例只需通過一個連接池連接,大大降低了連接數(shù).但這種方案改變了現(xiàn)有的分片規(guī)則,需要新建一套數(shù)據(jù)庫集群,根據(jù)新規(guī)則同步歷史數(shù)據(jù)和增量數(shù)據(jù),還有新舊數(shù)據(jù)驗證,但難度和風(fēng)險最高的還是線上切換過程,可能會造成數(shù)據(jù)不一致,且一旦出問題回滾方案也會非常復(fù)雜.
3.2.2 使用支持彈性擴展的數(shù)據(jù)庫
使用京東的jed,tidb等支持彈性擴展的數(shù)據(jù)庫,將數(shù)據(jù)同步到新庫中,這類數(shù)據(jù)庫的優(yōu)勢是開發(fā)人員只需關(guān)注業(yè)務(wù),不需要再去處理數(shù)據(jù)庫連接這些底層細(xì)節(jié).
3.2.3 使用sharding-proxy
Sharding-Proxy的定位是透明化的數(shù)據(jù)庫代理,我們可以在服務(wù)器上部署一套Sharding-Proxy,客戶端只需連接proxy服務(wù),再由proxy服務(wù)器連接MYSQL集群,這樣MYSQL集群的連接數(shù)只與proxy服務(wù)器的數(shù)量有關(guān),與客戶端解耦.
3.2.4 通過改造sharding-jdbc
理論上我們只要獲取數(shù)據(jù)庫實例上某個庫的連接,我們就可以通過"庫名.表名"的方式訪問這臺實例上其他庫中的數(shù)據(jù)(當(dāng)然前提是用戶要擁有要訪問庫的權(quán)限),我們是否可以通過改造sharding-jdbc來實現(xiàn)這種訪問方式?
以上幾種方案,3.2.1和3.2.2都需要新建數(shù)據(jù)庫,同步歷史和增量數(shù)據(jù),還涉及線上切換數(shù)據(jù)源,3.2.3需要部署一套proxy服務(wù),并且為了高可用必定要以集群方式部署,這三種方案工作量和風(fēng)險都較高,我們基于成本最小原則,最終選擇改造sharding-jdbc的方案.
3.3 探究sharding-jdbc
3.3.1 工作流程
sharding-jdbc的工作流程可以分為以下步驟:
-
sql解析-詞法解析和語法解析;
-
sql路由-根據(jù)解析上下文匹配數(shù)據(jù)庫和表的分片策略,并生成路由路徑;
-
sql改寫-將邏輯SQL改寫為在真實數(shù)據(jù)庫中可以正確執(zhí)行的SQL;
-
sql執(zhí)行-使用多線程并發(fā)執(zhí)行sql;
-
結(jié)果歸并-將從各個數(shù)據(jù)節(jié)點獲取的多數(shù)據(jù)結(jié)果集,組合成為一個結(jié)果集并正確的返回至請求客戶端;
顯然數(shù)據(jù)庫和表的分片是在sql路由階段處理,所以我們以sql路由邏輯為入口分析下源碼.
3.3.2 源碼分析
ShardingStandardRoutingEngine類中的route方法為計算路由的入口,返回的結(jié)果是數(shù)據(jù)庫和表的分片集合:
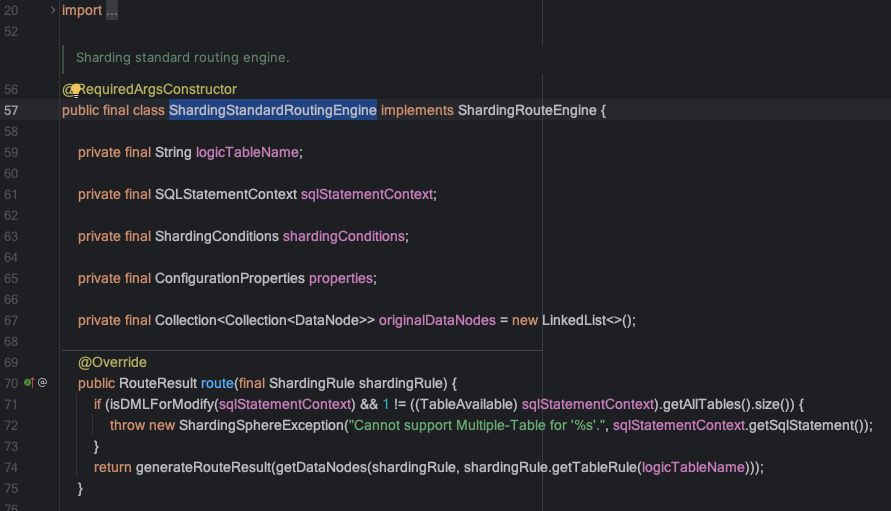
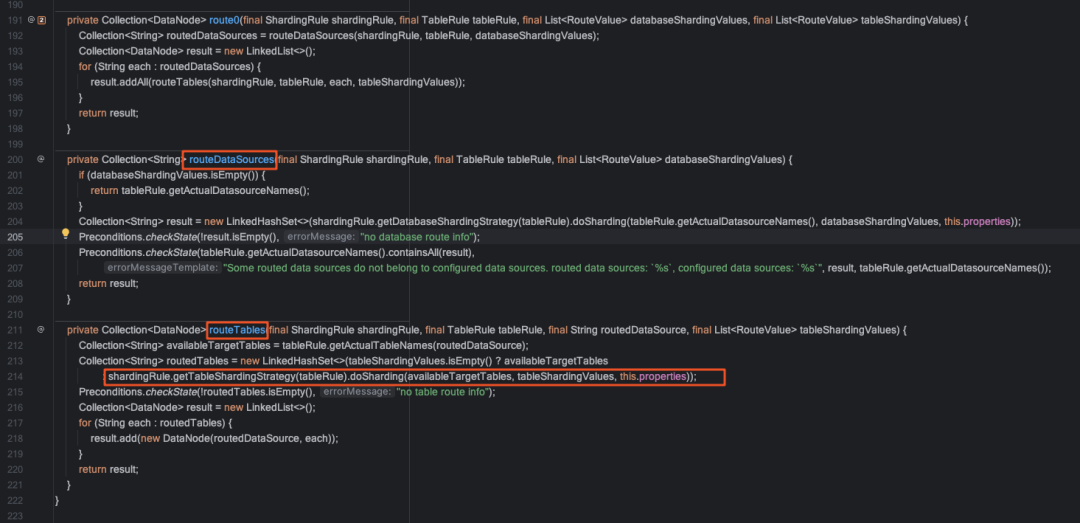
?route方法中的核心邏輯在該類的route0方法中,其中routeDataSources方法負(fù)責(zé)database路由,routeTables方法負(fù)責(zé)table路由,實際路由計算在StandardShardingStrategy的doSharding方法中,我們繼續(xù)深入.
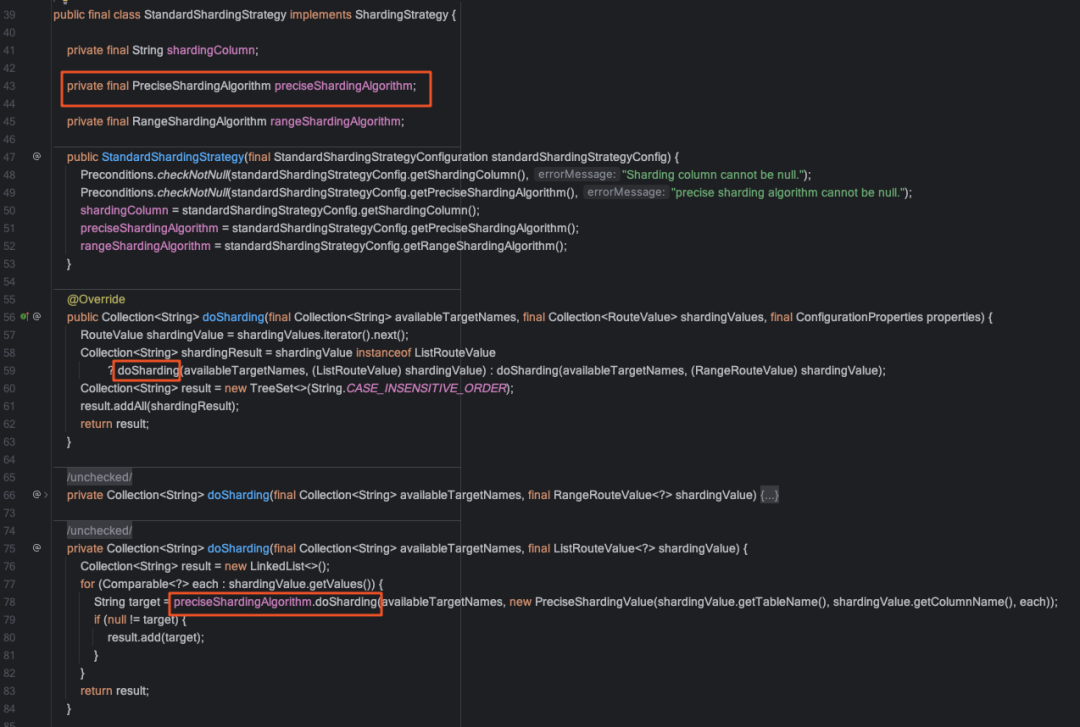
?在StandardShardingStrategy類中有兩個成員屬性,preciseShardingAlgorithm(精準(zhǔn)分片算法),rangeShardingAlgorithm(范圍分片算法),由于我們的sql都只指定分片鍵精準(zhǔn)查詢,使用的都是preciseShardingAlgorithm計算出的結(jié)果,PreciseShardingAlgorithm是個接口,那我們就可以實現(xiàn)這個接口來自定義分片算法.
?同時在sharding-sphere官網(wǎng)上也找到了相應(yīng)的標(biāo)簽支持:

?? 所以我們只需要自己實現(xiàn)PreciseShardingAlgorithm接口并配置在標(biāo)簽內(nèi)即可實現(xiàn)自定義分片策略.
3.4 改造步驟
3.4.1 庫分片改造
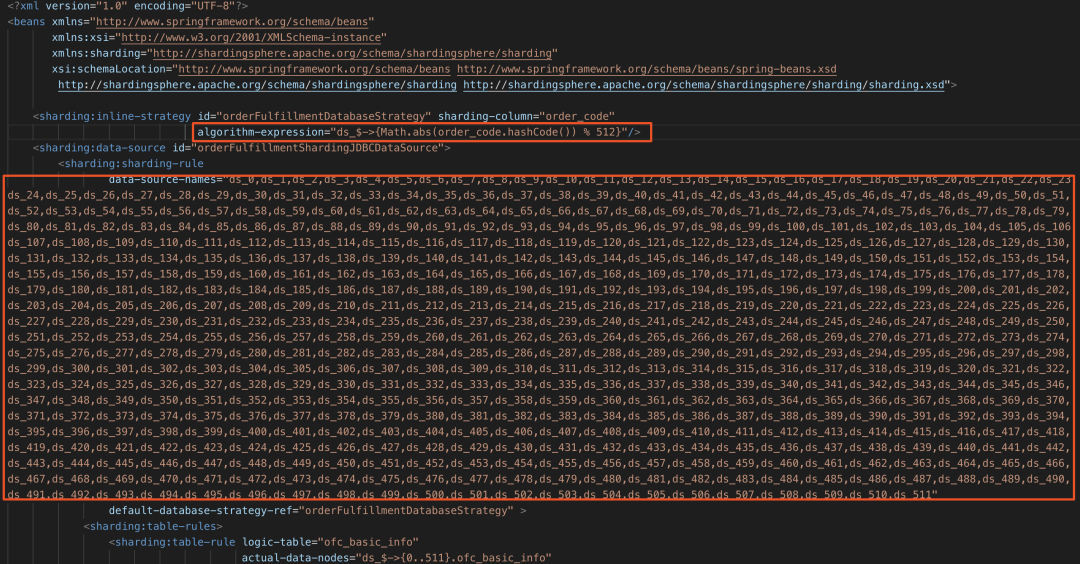
目前應(yīng)用配置了ds_0~ds_511共512個數(shù)據(jù)源,我們只需配置ds_0~ds_15共16個數(shù)據(jù)源,每個數(shù)據(jù)源配置的是單個實例上的第一個庫.
對于分片規(guī)則,我們可以依然使用<sharding:inline-strategy>標(biāo)簽,只需對Groovy表達(dá)式進行重寫,分片鍵為order_code,之前分片算法為(Math.abs(order_code.hashCode()) % 512)即用order_code列的哈希值對512取模得到0~511,我們只需要將結(jié)果再整除32即可得到0~16,即表達(dá)式改寫為(Math.abs(order_code.hashCode()) % 512).intdiv(32).
改造前分庫規(guī)則配置:
?? 改造后分庫規(guī)則配置: ?
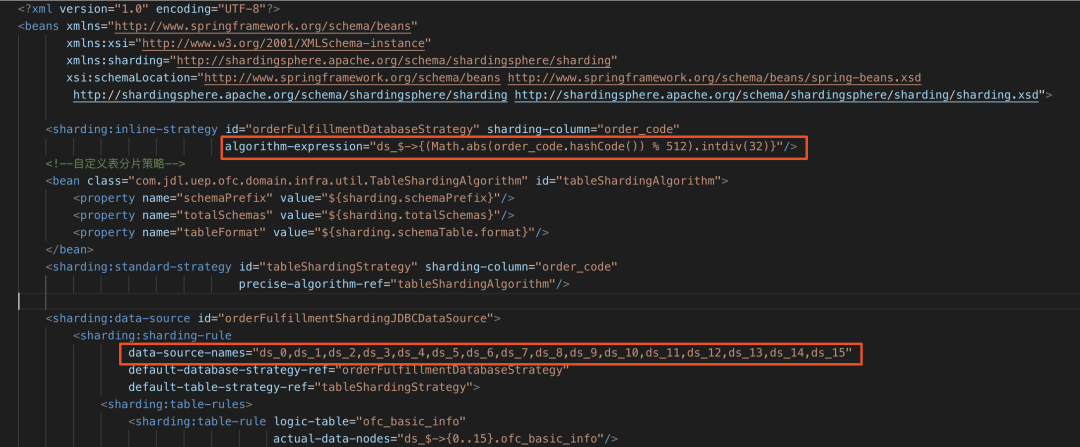
?? 3.4.2 表分片改造
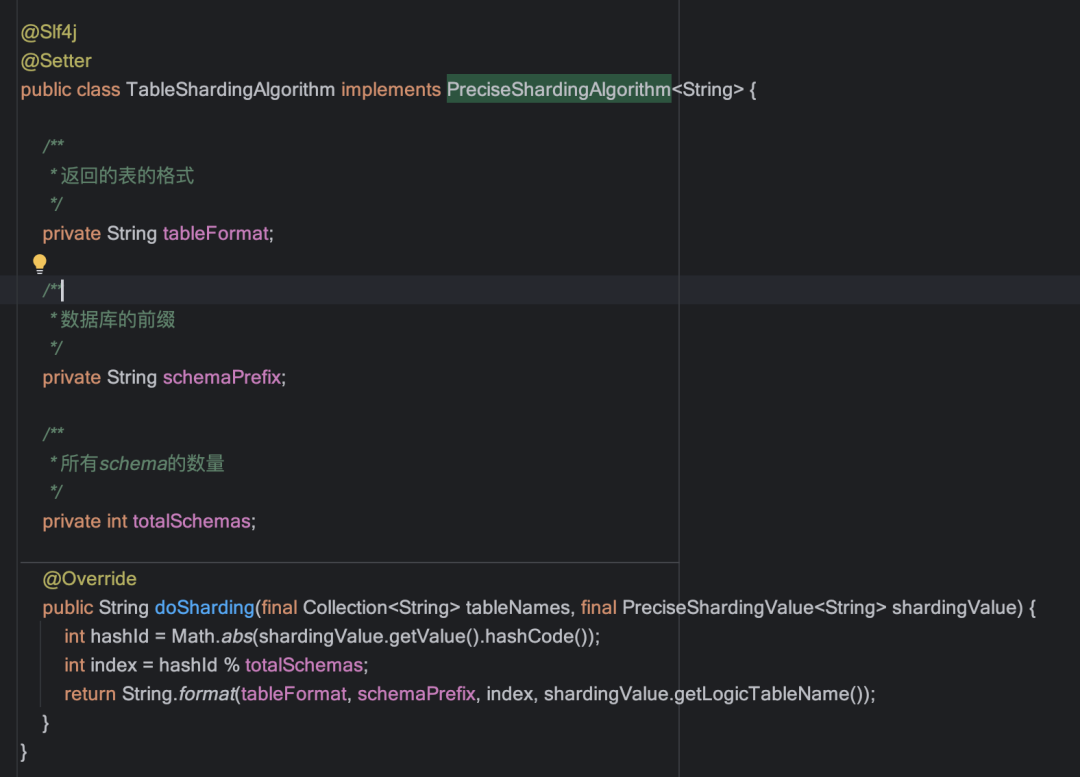
實現(xiàn)PreciseShardingAlgorithm接口,重寫表分片算法,使計算結(jié)果返回"實際庫名+表名"的形式;
例如:查詢DB_31庫上t_order表的user_id=35711的數(shù)據(jù),數(shù)據(jù)庫分片算法返回的數(shù)據(jù)源為"DB_0",表分片算法返回"DB_31.t_order";
自定義表分片算法:
?? 在xml中定義<sharding:standard-strategy>標(biāo)簽,其屬性precise-algorithm-ref配置為我們自定義的分表算法.
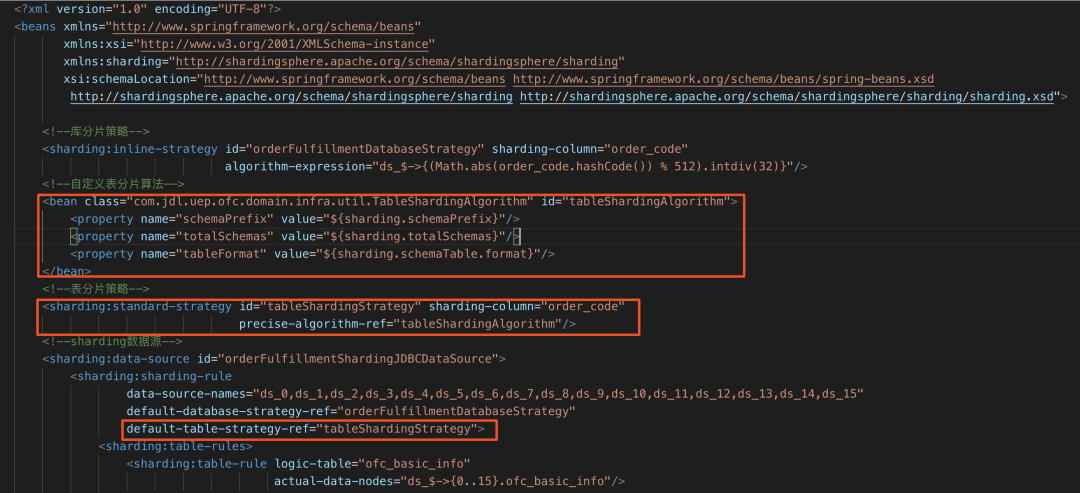
?? 3.4.3 數(shù)據(jù)庫連接池參數(shù)調(diào)整
改造前是一個庫對應(yīng)一個數(shù)據(jù)源連接池,改造后一個實例上的32個庫共用一個數(shù)據(jù)源連接池,那么連接池的最大連接數(shù),最小空閑連接數(shù)等參數(shù)需要相應(yīng)的做調(diào)整.這個需要根據(jù)業(yè)務(wù)流量做合理的評估,當(dāng)然最嚴(yán)謹(jǐn)?shù)倪€是要以壓測結(jié)果作為依據(jù).
改造后客戶端連接集群的形式如圖:
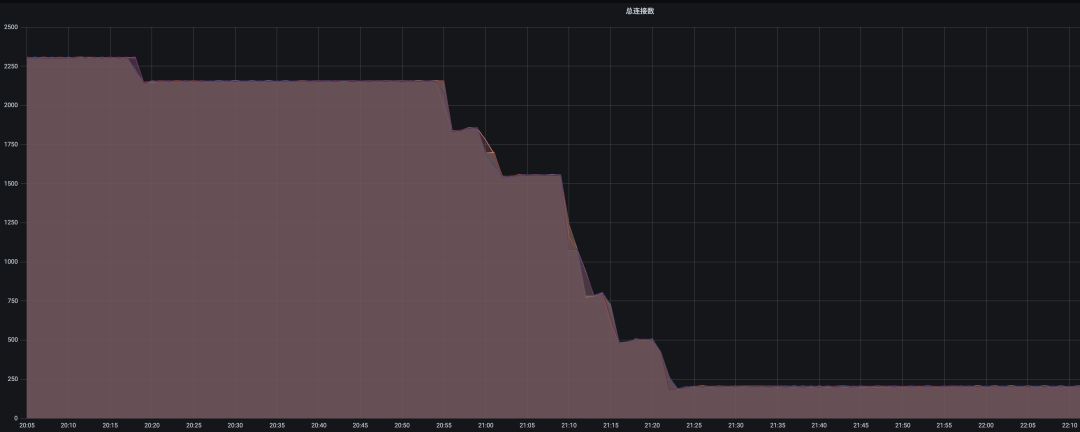
?? 優(yōu)化前后數(shù)據(jù)庫集群連接數(shù)對比:
四、小插曲
在改寫庫分片規(guī)則的Groovy表達(dá)式時,整除32直接在原有表達(dá)式上配置"/32"即Math.abs(order_code.hashCode()) % 512 / 32 ,在調(diào)試中發(fā)現(xiàn)執(zhí)行sql會報"no database route info"錯誤信息,經(jīng)過debug發(fā)現(xiàn)sharding-jdbc計算分片規(guī)則時會出現(xiàn)小數(shù)(例如:ds_14.6857),導(dǎo)致找不到數(shù)據(jù)源,這是因為Groovy沒有提供專用的整數(shù)除法運算符,所以要用.intdiv()方法,最終表達(dá)式改寫為(Math.abs(order_code.hashCode()) % 512).intdiv(32).
五、總結(jié)
本文介紹了分庫分表的概念及優(yōu)勢,以及sharding-jdbc分庫分表中間件,探究了sharding-jdbc的路由規(guī)則的執(zhí)行流程.當(dāng)然在系統(tǒng)設(shè)計之初,對于數(shù)據(jù)庫的分庫分表,到底需不需要做?是多分庫好還是多分表好?并沒有一個放之四海而皆準(zhǔn)的法則,需結(jié)合系統(tǒng)的特點(例如qps,tps,單表數(shù)據(jù)量,磁盤規(guī)格,數(shù)據(jù)保留時間,業(yè)務(wù)增量,數(shù)據(jù)冷熱方案等因素)來決策權(quán)衡,有利有弊才需決策,有取有舍才需權(quán)衡.
-end-