
面試必問的 Redis:數(shù)據(jù)結(jié)構(gòu)和基礎(chǔ)概念
前言
在 Java 后端的面試中,redis 應(yīng)該是目前所有框架/中間件中被問到頻率最高的,至少也是之一。
就算把范圍擴(kuò)大到整個(gè) Java 后端面試知識(shí)體系,面試中出現(xiàn)頻率比 redis 高的也不多,可能就那么幾個(gè):HashMap、線程池之類的。?
綜上,redis 在面試中的重要程度評(píng)分可以給到9分,接近滿分。
由于比較重要,知識(shí)點(diǎn)也比較多,所以這邊預(yù)計(jì)分為三篇來呈現(xiàn)。
除了本文之外,另外兩篇,一篇圍繞高可用,主要是持久化、主從復(fù)制、哨兵、集群模式等。
另一篇圍繞 redis 的實(shí)踐,主要是分布式鎖、緩存穿透、緩存雪崩、緩存擊穿等。
正文
redis 是單線程還是多線程
這個(gè)問題應(yīng)該已經(jīng)看到過無數(shù)次了,最近 redis 6 出來之后又被翻出來了。
redis 4.0 之前,redis 是完全單線程的。
redis 4.0 時(shí),redis 引入了多線程,但是額外的線程只是用于后臺(tái)處理,例如:刪除對(duì)象,核心流程還是完全單線程的。這也是為什么有些人說 4.0 是單線程的,因?yàn)樗麄冎傅氖呛诵牧鞒淌菃尉€程的。
這邊的核心流程指的是 redis 正常處理客戶端請(qǐng)求的流程,通常包括:接收命令、解析命令、執(zhí)行命令、返回結(jié)果等。
而在最近,redis 6.0 版本又一次引入了多線程概念,與 4.0 不同的是,這次的多線程會(huì)涉及到上述的核心流程。
redis 6.0 中,多線程主要用于網(wǎng)絡(luò) I/O 階段,也就是接收命令和寫回結(jié)果階段,而在執(zhí)行命令階段,還是由單線程串行執(zhí)行。由于執(zhí)行時(shí)還是串行,因此無需考慮并發(fā)安全問題。
值得注意的時(shí),redis 中的多線程組不會(huì)同時(shí)存在“讀”和“寫”,這個(gè)多線程組只會(huì)同時(shí)“讀”或者同時(shí)“寫”。
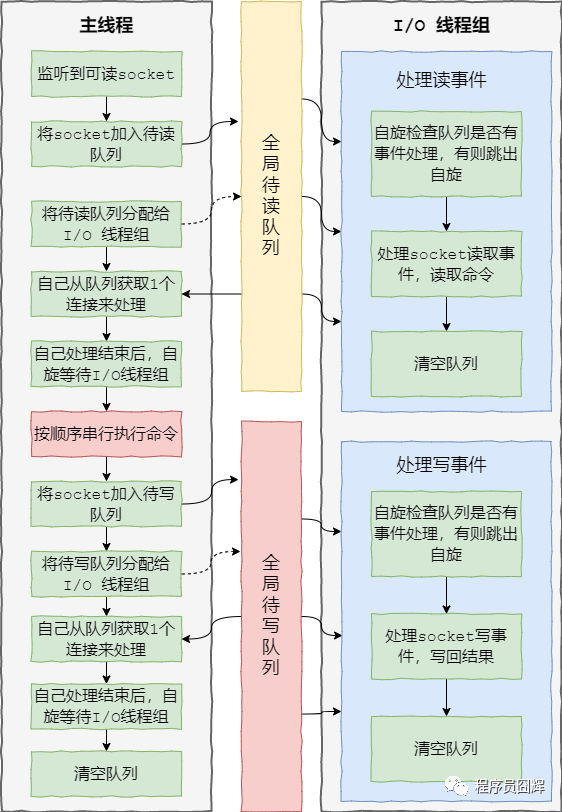
redis 6.0 加入多線程 I/O 之后,處理命令的核心流程如下:
1、當(dāng)有讀事件到來時(shí),主線程將該客戶端連接放到全局等待讀隊(duì)列
2、讀取數(shù)據(jù):1)主線程將等待讀隊(duì)列的客戶端連接通過輪詢調(diào)度算法分配給 I/O 線程處理;2)同時(shí)主線程也會(huì)自己負(fù)責(zé)處理一個(gè)客戶端連接的讀事件;3)當(dāng)主線程處理完該連接的讀事件后,會(huì)自旋等待所有 I/O 線程處理完畢
3、命令執(zhí)行:主線程按照事件被加入全局等待讀隊(duì)列的順序(這邊保證了執(zhí)行順序是正確的),串行執(zhí)行客戶端命令,然后將客戶端連接放到全局等待寫隊(duì)列
4、寫回結(jié)果:跟等待讀隊(duì)列處理類似,主線程將等待寫隊(duì)列的客戶端連接使用輪詢調(diào)度算法分配給 I/O 線程處理,同時(shí)自己也會(huì)處理一個(gè),當(dāng)主線程處理完畢后,會(huì)自旋等待所有 I/O 線程處理完畢,最后清空隊(duì)列。
大致流程圖如下:
相關(guān)源碼在 networking.c,核心的方法是:
IOThreadMain、handleClientsWithPendingReadsUsingThreads、
handleClientsWithPendingWritesUsingThreads
為什么 redis 是單線程
在 redis 6.0 之前,redis 的核心操作是單線程的。
因?yàn)?redis 是完全基于內(nèi)存操作的,通常情況下CPU不會(huì)是redis的瓶頸,redis 的瓶頸最有可能是機(jī)器內(nèi)存的大小或者網(wǎng)絡(luò)帶寬。
既然CPU不會(huì)成為瓶頸,那就順理成章地采用單線程的方案了,因?yàn)槿绻褂枚嗑€程的話會(huì)更復(fù)雜,同時(shí)需要引入上下文切換、加鎖等等,會(huì)帶來額外的性能消耗。
而隨著近些年互聯(lián)網(wǎng)的不斷發(fā)展,大家對(duì)于緩存的性能要求也越來越高了,因此 redis 也開始在逐漸往多線程方向發(fā)展。
最近的 6.0 版本就對(duì)核心流程引入了多線程,主要用于解決 redis 在網(wǎng)絡(luò) I/O 上的性能瓶頸。而對(duì)于核心的命令執(zhí)行階段,目前還是單線程的。
redis 為什么使用單進(jìn)程、單線程也很快
1、基于內(nèi)存的操作
2、使用了 I/O 多路復(fù)用模型,select、epoll 等,基于 reactor 模式開發(fā)了自己的網(wǎng)絡(luò)事件處理器
3、單線程可以避免不必要的上下文切換和競爭條件,減少了這方面的性能消耗。
4、以上這三點(diǎn)是 redis 性能高的主要原因,其他的還有一些小優(yōu)化,例如:對(duì)數(shù)據(jù)結(jié)構(gòu)進(jìn)行了優(yōu)化,簡單動(dòng)態(tài)字符串、壓縮列表等。
項(xiàng)目中使用的 redis 版本
這個(gè)問題是我在面試某大廠真實(shí)碰到過的,所以大家平時(shí)在使用中間件和框架時(shí)可以留意下自使用的版本。
下圖是從 redis 官方 github 截的圖,包含了 redis 2.2 之后的所有版本,目前常用的應(yīng)該是:3.2.*、4.0.*、5.0.*。
redis?在項(xiàng)目中的使用場景
緩存、分布式鎖、排行榜(zset)、計(jì)數(shù)(incrby)、消息隊(duì)列(stream)、地理位置(geo)、訪客統(tǒng)計(jì)(hyperloglog)等。
redis常見的數(shù)據(jù)結(jié)構(gòu)
常見的5種:
String:字符串,最基礎(chǔ)的數(shù)據(jù)類型。
List:列表。
Hash:哈希對(duì)象。
Set:集合。
Sorted Set:有序集合,Set 的基礎(chǔ)上加了個(gè)分值。
高級(jí)的4種:
HyperLogLog:通常用于基數(shù)統(tǒng)計(jì)。使用少量固定大小的內(nèi)存,來統(tǒng)計(jì)集合中唯一元素的數(shù)量。統(tǒng)計(jì)結(jié)果不是精確值,而是一個(gè)帶有0.81%標(biāo)準(zhǔn)差(standard error)的近似值。所以,HyperLogLog適用于一些對(duì)于統(tǒng)計(jì)結(jié)果精確度要求不是特別高的場景,例如網(wǎng)站的UV統(tǒng)計(jì)。
Geo:redis 3.2 版本的新特性。可以將用戶給定的地理位置信息儲(chǔ)存起來, 并對(duì)這些信息進(jìn)行操作:獲取2個(gè)位置的距離、根據(jù)給定地理位置坐標(biāo)獲取指定范圍內(nèi)的地理位置集合。
Bitmap:位圖。
Stream:主要用于消息隊(duì)列,類似于 kafka,可以認(rèn)為是 pub/sub 的改進(jìn)版。提供了消息的持久化和主備復(fù)制功能,可以讓任何客戶端訪問任何時(shí)刻的數(shù)據(jù),并且能記住每一個(gè)客戶端的訪問位置,還能保證消息不丟失。
Redis的字符串(SDS)和C語言的字符串區(qū)別
C字符串 | SDS |
獲取字符串長度的復(fù)雜度為O(N) | 獲取字符串長度的復(fù)雜度為O(1) |
API是不安全的,可能會(huì)造成緩沖區(qū)溢出 | API是安全的,不會(huì)造成緩沖區(qū)溢出 |
修改字符串長度N次必然需要執(zhí)行N次內(nèi)存重分配 | 修改字符串長度N次最多需要執(zhí)行N次內(nèi)存重分配 |
只能保存文本數(shù)據(jù) | 可以保存文本數(shù)據(jù)或者二進(jìn)制數(shù)據(jù) |
可以使用所有的 | 可以使用一部分 |
Sorted Set底層數(shù)據(jù)結(jié)構(gòu)
Sorted Set(有序集合)當(dāng)前有兩種編碼:ziplist、skiplist
ziplist:使用壓縮列表實(shí)現(xiàn),當(dāng)保存的元素長度都小于64字節(jié),同時(shí)數(shù)量小于128時(shí),使用該編碼方式,否則會(huì)使用 skiplist。這兩個(gè)參數(shù)可以通過?zset-max-ziplist-entries、zset-max-ziplist-value 來自定義修改。

skiplist:zset實(shí)現(xiàn),一個(gè)zset同時(shí)包含一個(gè)字典(dict)和一個(gè)跳躍表(zskiplist)
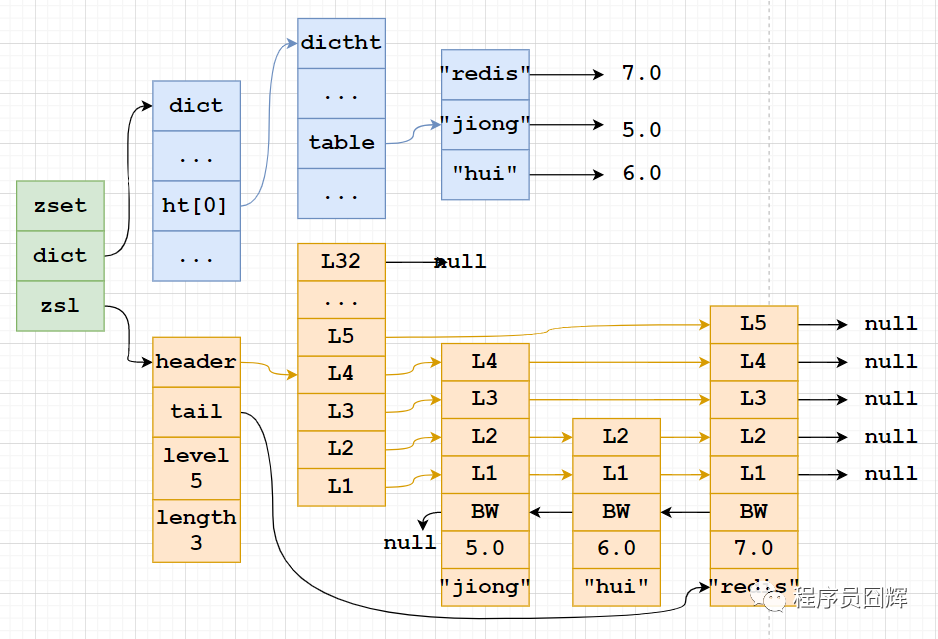
Sorted Set為什么同時(shí)使用字典和跳躍表?
主要是為了性能。
單獨(dú)使用字典:在執(zhí)行范圍型操作,比如zrank、zrange,字典需要進(jìn)行排序,至少需要O(NlogN)的時(shí)間復(fù)雜度及額外O(N)的內(nèi)存空間。
單獨(dú)使用跳躍表:根據(jù)成員查找分值操作的復(fù)雜度從O(1)上升為O(logN)。
Sorted Set為什么使用跳躍表,而不是紅黑樹?
1)跳表的性能和紅黑樹差不多。
2)跳表更容易實(shí)現(xiàn)和調(diào)試。
網(wǎng)上有同學(xué)說是因?yàn)樽髡卟粫?huì)紅黑樹,我覺得挺有可能的。

Hash?對(duì)象底層結(jié)構(gòu)
Hash 對(duì)象當(dāng)前有兩種編碼:ziplist、hashtable
ziplist:使用壓縮列表實(shí)現(xiàn),每當(dāng)有新的鍵值對(duì)要加入到哈希對(duì)象時(shí),程序會(huì)先將保存了鍵的節(jié)點(diǎn)推入到壓縮列表的表尾,然后再將保存了值的節(jié)點(diǎn)推入到壓縮列表表尾。
因此:1)保存了同一鍵值對(duì)的兩個(gè)節(jié)點(diǎn)總是緊挨在一起,保存鍵的節(jié)點(diǎn)在前,保存值的節(jié)點(diǎn)在后;2)先添加到哈希對(duì)象中的鍵值對(duì)會(huì)被放在壓縮列表的表頭方向,而后來添加的會(huì)被放在表尾方向。

hashtable:使用字典作為底層實(shí)現(xiàn),哈希對(duì)象中的每個(gè)鍵值對(duì)都使用一個(gè)字典鍵值來保存,跟 java 中的 HashMap 類似。

Hash 對(duì)象的擴(kuò)容流程
hash 對(duì)象在擴(kuò)容時(shí)使用了一種叫“漸進(jìn)式 rehash”的方式,步驟如下:
1、計(jì)算新表 size、掩碼,為新表 ht[1] 分配空間,讓字典同時(shí)持有 ht[0]?和 ht[1] 兩個(gè)哈希表。
2、將 rehash 索引計(jì)數(shù)器變量 rehashidx 的值設(shè)置為0,表示 rehash 正式開始。
3、在 rehash 進(jìn)行期間,每次對(duì)字典執(zhí)行添加、刪除、査找、更新操作時(shí),程序除了執(zhí)行指定的操作以外,還會(huì)觸發(fā)額外的 rehash 操作,在源碼中的?_dictRehashStep?方法。
_dictRehashStep:從名字也可以看出來,大意是 rehash 一步,也就是 rehash 一個(gè)索引位置。
該方法會(huì)從?ht[0] 表的 rehashidx 索引位置上開始向后查找,找到第一個(gè)不為空的索引位置,將該索引位置的所有節(jié)點(diǎn)?rehash 到 ht[1],當(dāng)本次 rehash 工作完成之后,將 ht[0]?的 rehashidx?位置清空,同時(shí)將 rehashidx 屬性的值加一。
4、將 rehash 分?jǐn)偟矫總€(gè)操作上確實(shí)是非常妙的方式,但是萬一此時(shí)服務(wù)器比較空閑,一直沒有什么操作,難道 redis 要一直持有兩個(gè)哈希表嗎?
答案當(dāng)然不是的。我們知道,redis 除了文件事件外,還有時(shí)間事件,redis 會(huì)定期觸發(fā)時(shí)間事件,這些時(shí)間事件用于執(zhí)行一些后臺(tái)操作,其中就包含 rehash 操作:當(dāng) redis 發(fā)現(xiàn)有字典正在進(jìn)行 rehash 操作時(shí),會(huì)花費(fèi)1毫秒的時(shí)間,一起幫忙進(jìn)行 rehash。
5、隨著操作的不斷執(zhí)行,最終在某個(gè)時(shí)間點(diǎn)上,ht[0] 的所有鍵值對(duì)都會(huì)被 rehash 至 ht[1],此時(shí) rehash 流程完成,會(huì)執(zhí)行最后的清理工作:釋放 ht[0] 的空間、將 ht[0] 指向 ht[1]、重置 ht[1]、重置 rehashidx 的值為 -1。
相關(guān)源碼在 dict.c,核心方法是:dictExpand、dictRehashMilliseconds、dictRehash、dictFind、
漸進(jìn)式 rehash 的優(yōu)點(diǎn)
漸進(jìn)式 rehash 的好處在于它采取分而治之的方式,將 rehash 鍵值對(duì)所需的計(jì)算工作均攤到對(duì)字典的每個(gè)添加、刪除、查找和更新操作上,從而避免了集中式 rehash 而帶來的龐大計(jì)算量。
在進(jìn)行漸進(jìn)式 rehash 的過程中,字典會(huì)同時(shí)使用 ht[0] 和 ht[1] 兩個(gè)哈希表, 所以在漸進(jìn)式 rehash 進(jìn)行期間,字典的刪除、査找、更新等操作會(huì)在兩個(gè)哈希表上進(jìn)行。例如,要在字典里面査找一個(gè)鍵的話,程序會(huì)先在 ht[0] 里面進(jìn)行査找,如果沒找到的話,就會(huì)繼續(xù)到 ht[1] 里面進(jìn)行査找,諸如此類。
另外,在漸進(jìn)式 rehash 執(zhí)行期間,新增的鍵值對(duì)會(huì)被直接保存到 ht[1], ht[0] 不再進(jìn)行任何添加操作,這樣就保證了 ht[0] 包含的鍵值對(duì)數(shù)量會(huì)只減不增,并隨著 rehash 操作的執(zhí)行而最終變成空表。
rehash 流程在數(shù)據(jù)量大的時(shí)候會(huì)有什么問題嗎
1、擴(kuò)容期開始時(shí),會(huì)先給 ht[1] 申請(qǐng)空間,所以在整個(gè)擴(kuò)容期間,會(huì)同時(shí)存在 ht[0] 和 ht[1],會(huì)占用額外的空間。
2、擴(kuò)容期間同時(shí)存在 ht[0] 和 ht[1],查找、刪除、更新等操作有概率需要操作兩張表,耗時(shí)會(huì)增加。
3、redis 在內(nèi)存使用接近 maxmemory 并且有設(shè)置驅(qū)逐策略的情況下,出現(xiàn) rehash 會(huì)使得內(nèi)存占用超過?maxmemory,觸發(fā)驅(qū)逐淘汰操作,導(dǎo)致 master/slave 均有有大量的 key 被驅(qū)逐淘汰,從而出現(xiàn) saster/slave 主從不一致。
Redis的事件處理器
redis 基于 reactor 模式開發(fā)了自己的網(wǎng)絡(luò)事件處理器,由4個(gè)部分組成:套接字、I/O 多路復(fù)用程序、文件事件分派器(dispatcher)、以及事件處理器。
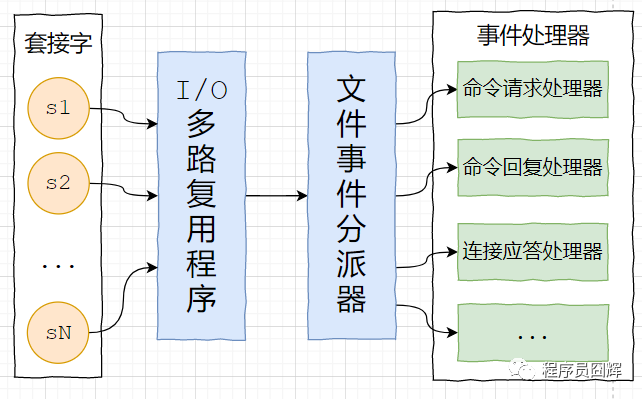
套接字:socket 連接,也就是客戶端連接。當(dāng)一個(gè)套接字準(zhǔn)備好執(zhí)行連接、寫入、讀取、關(guān)閉等操作時(shí), 就會(huì)產(chǎn)生一個(gè)相應(yīng)的文件事件。因?yàn)橐粋€(gè)服務(wù)器通常會(huì)連接多個(gè)套接字, 所以多個(gè)文件事件有可能會(huì)并發(fā)地出現(xiàn)。
I/O 多路復(fù)用程序:提供 select、epoll、evport、kqueue 的實(shí)現(xiàn),會(huì)根據(jù)當(dāng)前系統(tǒng)自動(dòng)選擇最佳的方式。負(fù)責(zé)監(jiān)聽多個(gè)套接字,當(dāng)套接字產(chǎn)生事件時(shí),會(huì)向文件事件分派器傳送那些產(chǎn)生了事件的套接字。
當(dāng)多個(gè)文件事件并發(fā)出現(xiàn)時(shí), I/O 多路復(fù)用程序會(huì)將所有產(chǎn)生事件的套接字都放到一個(gè)隊(duì)列里面,然后通過這個(gè)隊(duì)列,以有序、同步、每次一個(gè)套接字的方式向文件事件分派器傳送套接字:當(dāng)上一個(gè)套接字產(chǎn)生的事件被處理完畢之后,才會(huì)繼續(xù)傳送下一個(gè)套接字。
文件事件分派器:接收 I/O 多路復(fù)用程序傳來的套接字, 并根據(jù)套接字產(chǎn)生的事件的類型, 調(diào)用相應(yīng)的事件處理器。
事件處理器:事件處理器就是一個(gè)個(gè)函數(shù), 定義了某個(gè)事件發(fā)生時(shí), 服務(wù)器應(yīng)該執(zhí)行的動(dòng)作。例如:建立連接、命令查詢、命令寫入、連接關(guān)閉等等。
Redis 刪除過期鍵的策略(緩存失效策略、數(shù)據(jù)過期策略)
定時(shí)刪除:在設(shè)置鍵的過期時(shí)間的同時(shí),創(chuàng)建一個(gè)定時(shí)器,讓定時(shí)器在鍵的過期時(shí)間來臨時(shí),立即執(zhí)行對(duì)鍵的刪除操作。對(duì)內(nèi)存最友好,對(duì) CPU 時(shí)間最不友好。
惰性刪除:放任鍵過期不管,但是每次獲取鍵時(shí),都檢査鍵是否過期,如果過期的話,就刪除該鍵;如果沒有過期,就返回該鍵。對(duì) CPU 時(shí)間最優(yōu)化,對(duì)內(nèi)存最不友好。
定期刪除:每隔一段時(shí)間,默認(rèn)100ms,程序就對(duì)數(shù)據(jù)庫進(jìn)行一次檢査,刪除里面的過期鍵。至 于要?jiǎng)h除多少過期鍵,以及要檢査多少個(gè)數(shù)據(jù)庫,則由算法決定。前兩種策略的折中,對(duì) CPU 時(shí)間和內(nèi)存的友好程度較平衡。
Redis 使用惰性刪除和定期刪除。
Redis?的內(nèi)存驅(qū)逐(淘汰)策略
當(dāng) redis 的內(nèi)存空間(maxmemory 參數(shù)配置)已經(jīng)用滿時(shí),redis 將根據(jù)配置的驅(qū)逐策略(maxmemory-policy 參數(shù)配置),進(jìn)行相應(yīng)的動(dòng)作。
當(dāng)前 redis 的淘汰策略有以下8種。
noeviction:默認(rèn)策略,不淘汰任何 key,直接返回錯(cuò)誤
allkeys-lru:在所有的 key 中,使用?LRU 算法淘汰部分 key
allkeys-lfu:在所有的 key 中,使用 LFU 算法淘汰部分 key
allkeys-random:在所有的 key 中,隨機(jī)淘汰部分 key
volatile-lru:在設(shè)置了過期時(shí)間的?key?中,使用?LRU?算法淘汰部分 key
volatile-lfu:在設(shè)置了過期時(shí)間的 key 中,使用 LFU 算法淘汰部分 key
volatile-random:在設(shè)置了過期時(shí)間的 key 中,隨機(jī)淘汰部分 key
volatile-ttl:在設(shè)置了過期時(shí)間的 key 中,挑選 TTL(time to live,剩余時(shí)間)短的 key 淘汰
最后
我不能保證所寫的每個(gè)地方都是對(duì)的,但是至少能保證所寫每一句話、每一行代碼都經(jīng)過了認(rèn)真的推敲、仔細(xì)的斟酌。
如果你覺得本文寫的還不錯(cuò),對(duì)你有幫助,請(qǐng)通過【點(diǎn)贊】讓我知道,支持我寫出更好的文章,這對(duì)我很重要。如果有什么問題和建議,也歡迎【留言】一起交流探討。
推薦閱讀
兩年Java開發(fā)工作經(jīng)驗(yàn)面試總結(jié)
4 年 Java 經(jīng)驗(yàn)面試總結(jié)、心得體會(huì)
字節(jié)、美團(tuán)、快手核心部門面試總結(jié)(真題解析)