
Redis基礎(chǔ)「5種基本數(shù)據(jù)結(jié)構(gòu)」
公眾號來源:我沒有三顆心臟??
作者:我沒有三顆心臟一、Redis 簡介
"Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker." —— Redis是一個開放源代碼(BSD許可)的內(nèi)存中數(shù)據(jù)結(jié)構(gòu)存儲,用作數(shù)據(jù)庫,緩存和消息代理。(摘自官網(wǎng))
Redis 是一個開源,高級的鍵值存儲和一個適用的解決方案,用于構(gòu)建高性能,可擴展的 Web 應(yīng)用程序。Redis 也被作者戲稱為 數(shù)據(jù)結(jié)構(gòu)服務(wù)器 ,這意味著使用者可以通過一些命令,基于帶有 TCP 套接字的簡單 服務(wù)器-客戶端 協(xié)議來訪問一組 可變數(shù)據(jù)結(jié)構(gòu) 。(在 Redis 中都采用鍵值對的方式,只不過對應(yīng)的數(shù)據(jù)結(jié)構(gòu)不一樣罷了)
Redis 的優(yōu)點
以下是 Redis 的一些優(yōu)點:
- 異常快 - Redis 非常快,每秒可執(zhí)行大約 110000 次的設(shè)置(SET)操作,每秒大約可執(zhí)行 81000 次的讀取/獲取(GET)操作。
- 支持豐富的數(shù)據(jù)類型 - Redis 支持開發(fā)人員常用的大多數(shù)數(shù)據(jù)類型,例如列表,集合,排序集和散列等等。這使得 Redis 很容易被用來解決各種問題,因為我們知道哪些問題可以更好使用地哪些數(shù)據(jù)類型來處理解決。
- 操作具有原子性 - 所有 Redis 操作都是原子操作,這確保如果兩個客戶端并發(fā)訪問,Redis 服務(wù)器能接收更新的值。
- 多實用工具 - Redis 是一個多實用工具,可用于多種用例,如:緩存,消息隊列(Redis 本地支持發(fā)布/訂閱),應(yīng)用程序中的任何短期數(shù)據(jù),例如,web應(yīng)用程序中的會話,網(wǎng)頁命中計數(shù)等。
Redis 的安裝
這一步比較簡單,你可以在網(wǎng)上搜到許多滿意的教程,這里就不再贅述。
給一個菜鳥教程的安裝教程用作參考:https://www.runoob.com/redis/redis-install.html
測試本地 Redis 性能
當你安裝完成之后,你可以先執(zhí)行 redis-server 讓 Redis 啟動起來,然后運行命令 redis-benchmark -n 100000 -q 來檢測本地同時執(zhí)行 10 萬個請求時的性能:
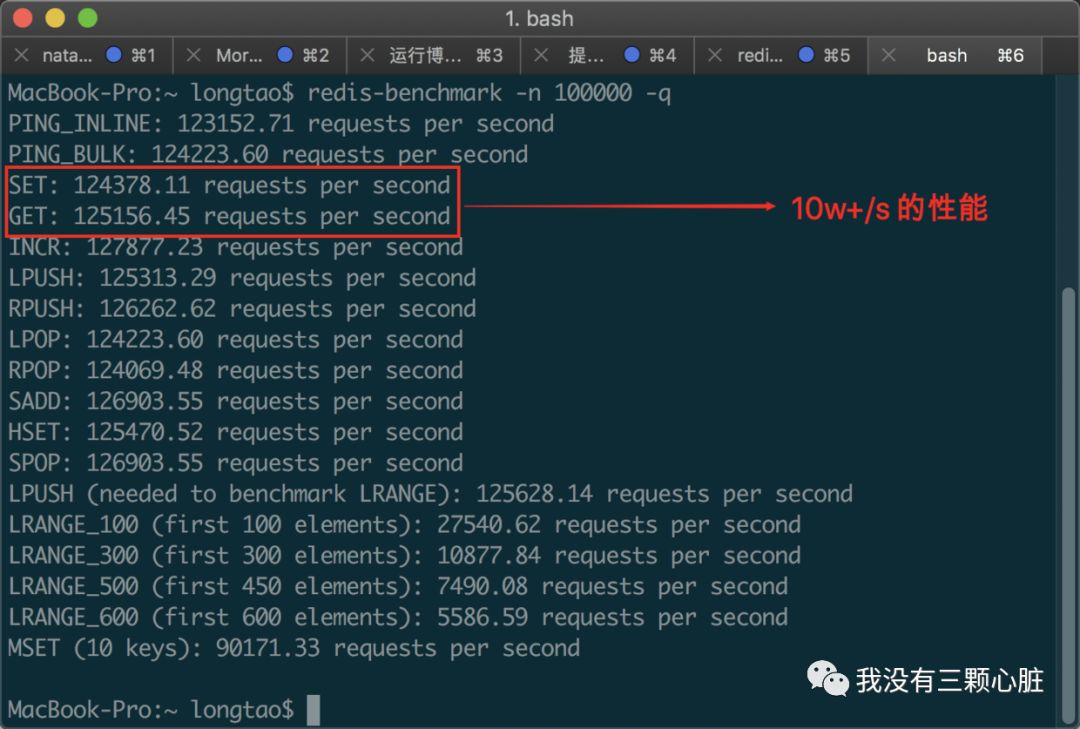
當然不同電腦之間由于各方面的原因會存在性能差距,這個測試您可以權(quán)當是一種 「樂趣」 就好。
二、Redis 五種基本數(shù)據(jù)結(jié)構(gòu)Redis 有 5 種基礎(chǔ)數(shù)據(jù)結(jié)構(gòu),它們分別是:string(字符串)、list(列表)、hash(字典)、set(集合) 和 zset(有序集合)。這 5 種是 Redis 相關(guān)知識中最基礎(chǔ)、最重要的部分,下面我們結(jié)合源碼以及一些實踐來給大家分別講解一下。
1)字符串 string
Redis 中的字符串是一種 動態(tài)字符串,這意味著使用者可以修改,它的底層實現(xiàn)有點類似于 Java 中的 ArrayList,有一個字符數(shù)組,從源碼的 sds.h/sdshdr 文件 中可以看到 Redis 底層對于字符串的定義 SDS,即 Simple Dynamic String 結(jié)構(gòu):
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
你會發(fā)現(xiàn)同樣一組結(jié)構(gòu) Redis 使用泛型定義了好多次,為什么不直接使用 int 類型呢?
因為當字符串比較短的時候,len 和 alloc 可以使用 byte 和 short 來表示,Redis 為了對內(nèi)存做極致的優(yōu)化,不同長度的字符串使用不同的結(jié)構(gòu)體來表示。
SDS 與 C 字符串的區(qū)別
為什么不考慮直接使用 C 語言的字符串呢?因為 C 語言這種簡單的字符串表示方式 不符合 Redis 對字符串在安全性、效率以及功能方面的要求。我們知道,C 語言使用了一個長度為 N+1 的字符數(shù)組來表示長度為 N 的字符串,并且字符數(shù)組最后一個元素總是 '\0'。(下圖就展示了 C 語言中值為 "Redis" 的一個字符數(shù)組)

這樣簡單的數(shù)據(jù)結(jié)構(gòu)可能會造成以下一些問題:
- 獲取字符串長度為 O(N) 級別的操作 → 因為 C 不保存數(shù)組的長度,每次都需要遍歷一遍整個數(shù)組;
- 不能很好的杜絕 緩沖區(qū)溢出/內(nèi)存泄漏 的問題 → 跟上述問題原因一樣,如果執(zhí)行拼接 or 縮短字符串的操作,如果操作不當就很容易造成上述問題;
- C 字符串 只能保存文本數(shù)據(jù) → 因為 C 語言中的字符串必須符合某種編碼(比如 ASCII),例如中間出現(xiàn)的
'\0'可能會被判定為提前結(jié)束的字符串而識別不了;
我們以追加字符串的操作舉例,Redis 源碼如下:
/* Append the specified binary-safe string pointed by 't' of 'len' bytes to the
* end of the specified sds string 's'.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscatlen(sds s, const void *t, size_t len) {
// 獲取原字符串的長度
size_t curlen = sdslen(s);
// 按需調(diào)整空間,如果容量不夠容納追加的內(nèi)容,就會重新分配字節(jié)數(shù)組并復(fù)制原字符串的內(nèi)容到新數(shù)組中
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL; // 內(nèi)存不足
memcpy(s+curlen, t, len); // 追加目標字符串到字節(jié)數(shù)組中
sdssetlen(s, curlen+len); // 設(shè)置追加后的長度
s[curlen+len] = '\0'; // 讓字符串以 \0 結(jié)尾,便于調(diào)試打印
return s;
}
- 注:Redis 規(guī)定了字符串的長度不得超過 512 MB。
對字符串的基本操作
安裝好 Redis,我們可以使用 redis-cli 來對 Redis 進行命令行的操作,當然 Redis 官方也提供了在線的調(diào)試器,你也可以在里面敲入命令進行操作:http://try.redis.io/#run
設(shè)置和獲取鍵值對
> SET key value
OK
> GET key
"value"
正如你看到的,我們通常使用 SET 和 GET 來設(shè)置和獲取字符串值。
值可以是任何種類的字符串(包括二進制數(shù)據(jù)),例如你可以在一個鍵下保存一張 .jpeg 圖片,只需要注意不要超過 512 MB 的最大限度就好了。
當 key 存在時,SET 命令會覆蓋掉你上一次設(shè)置的值:
> SET key newValue
OK
> GET key
"newValue"
另外你還可以使用 EXISTS 和 DEL 關(guān)鍵字來查詢是否存在和刪除鍵值對:
> EXISTS key
(integer) 1
> DEL key
(integer) 1
> GET key
(nil)
批量設(shè)置鍵值對
> SET key1 value1
OK
> SET key2 value2
OK
> MGET key1 key2 key3 # 返回一個列表
1) "value1"
2) "value2"
3) (nil)
> MSET key1 value1 key2 value2
> MGET key1 key2
1) "value1"
2) "value2"
過期和 SET 命令擴展
可以對 key 設(shè)置過期時間,到時間會被自動刪除,這個功能常用來控制緩存的失效時間。(過期可以是任意數(shù)據(jù)結(jié)構(gòu))
> SET key value1
> GET key
"value1"
> EXPIRE name 5 # 5s 后過期
... # 等待 5s
> GET key
(nil)
等價于 SET + EXPIRE 的 SETNX 命令:
> SETNX key value1
... # 等待 5s 后獲取
> GET key
(nil)
> SETNX key value1 # 如果 key 不存在則 SET 成功
(integer) 1
> SETNX key value1 # 如果 key 存在則 SET 失敗
(integer) 0
> GET key
"value" # 沒有改變
計數(shù)
如果 value 是一個整數(shù),還可以對它使用 INCR 命令進行 原子性 的自增操作,這意味著及時多個客戶端對同一個 key 進行操作,也決不會導(dǎo)致競爭的情況:
> SET counter 100
> INCR count
(interger) 101
> INCRBY counter 50
(integer) 151
返回原值的 GETSET 命令
對字符串,還有一個 GETSET 比較讓人覺得有意思,它的功能跟它名字一樣:為 key 設(shè)置一個值并返回原值:
> SET key value
> GETSET key value1
"value"
這可以對于某一些需要隔一段時間就統(tǒng)計的 key 很方便的設(shè)置和查看,例如:系統(tǒng)每當由用戶進入的時候你就是用 INCR 命令操作一個 key,當需要統(tǒng)計時候你就把這個 key 使用 GETSET 命令重新賦值為 0,這樣就達到了統(tǒng)計的目的。
2)列表 list
Redis 的列表相當于 Java 語言中的 LinkedList,注意它是鏈表而不是數(shù)組。這意味著 list 的插入和刪除操作非常快,時間復(fù)雜度為 O(1),但是索引定位很慢,時間復(fù)雜度為 O(n)。
我們可以從源碼的 adlist.h/listNode 來看到對其的定義:
/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
可以看到,多個 listNode 可以通過 prev 和 next 指針組成雙向鏈表:
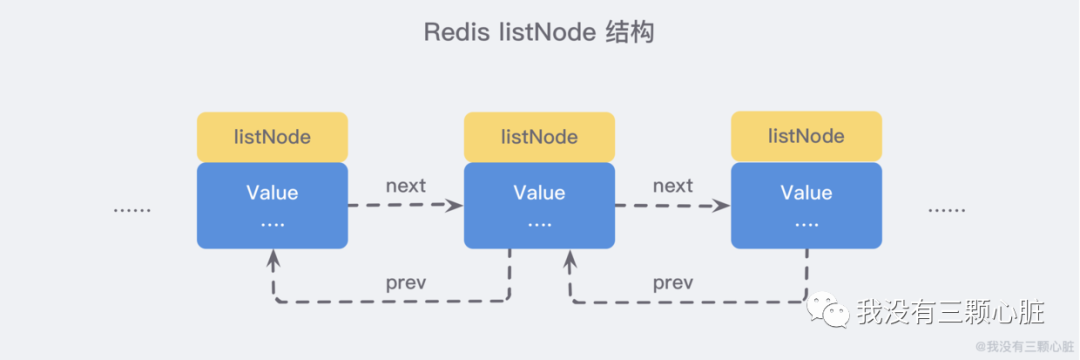
雖然僅僅使用多個 listNode 結(jié)構(gòu)就可以組成鏈表,但是使用 adlist.h/list 結(jié)構(gòu)來持有鏈表的話,操作起來會更加方便:
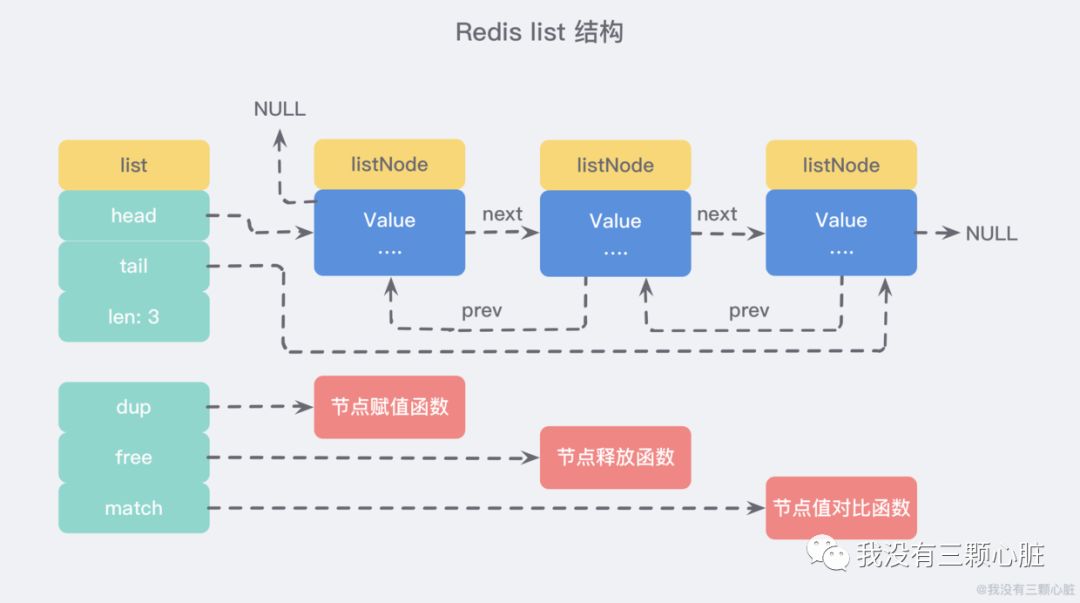
鏈表的基本操作
LPUSH和RPUSH分別可以向 list 的左邊(頭部)和右邊(尾部)添加一個新元素;LRANGE命令可以從 list 中取出一定范圍的元素;LINDEX命令可以從 list 中取出指定下表的元素,相當于 Java 鏈表操作中的get(int index)操作;
示范:
> rpush mylist A
(integer) 1
> rpush mylist B
(integer) 2
> lpush mylist first
(integer) 3
> lrange mylist 0 -1 # -1 表示倒數(shù)第一個元素, 這里表示從第一個元素到最后一個元素,即所有
1) "first"
2) "A"
3) "B"
list 實現(xiàn)隊列
隊列是先進先出的數(shù)據(jù)結(jié)構(gòu),常用于消息排隊和異步邏輯處理,它會確保元素的訪問順序:
> RPUSH books python java golang
(integer) 3
> LPOP books
"python"
> LPOP books
"java"
> LPOP books
"golang"
> LPOP books
(nil)
list 實現(xiàn)棧
棧是先進后出的數(shù)據(jù)結(jié)構(gòu),跟隊列正好相反:
> RPUSH books python java golang
> RPOP books
"golang"
> RPOP books
"java"
> RPOP books
"python"
> RPOP books
(nil)
3)字典 hash
Redis 中的字典相當于 Java 中的 HashMap,內(nèi)部實現(xiàn)也差不多類似,都是通過 "數(shù)組 + 鏈表" 的鏈地址法來解決部分 哈希沖突,同時這樣的結(jié)構(gòu)也吸收了兩種不同數(shù)據(jù)結(jié)構(gòu)的優(yōu)點。源碼定義如 dict.h/dictht 定義:
typedef struct dictht {
// 哈希表數(shù)組
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩碼,用于計算索引值,總是等于 size - 1
unsigned long sizemask;
// 該哈希表已有節(jié)點的數(shù)量
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
// 內(nèi)部有兩個 dictht 結(jié)構(gòu)
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
table 屬性是一個數(shù)組,數(shù)組中的每個元素都是一個指向 dict.h/dictEntry 結(jié)構(gòu)的指針,而每個 dictEntry 結(jié)構(gòu)保存著一個鍵值對:
typedef struct dictEntry {
// 鍵
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 指向下個哈希表節(jié)點,形成鏈表
struct dictEntry *next;
} dictEntry;
可以從上面的源碼中看到,實際上字典結(jié)構(gòu)的內(nèi)部包含兩個 hashtable,通常情況下只有一個 hashtable 是有值的,但是在字典擴容縮容時,需要分配新的 hashtable,然后進行 漸進式搬遷 (下面說原因)。
漸進式 rehash
大字典的擴容是比較耗時間的,需要重新申請新的數(shù)組,然后將舊字典所有鏈表中的元素重新掛接到新的數(shù)組下面,這是一個 O(n) 級別的操作,作為單線程的 Redis 很難承受這樣耗時的過程,所以 Redis 使用 漸進式 rehash 小步搬遷:
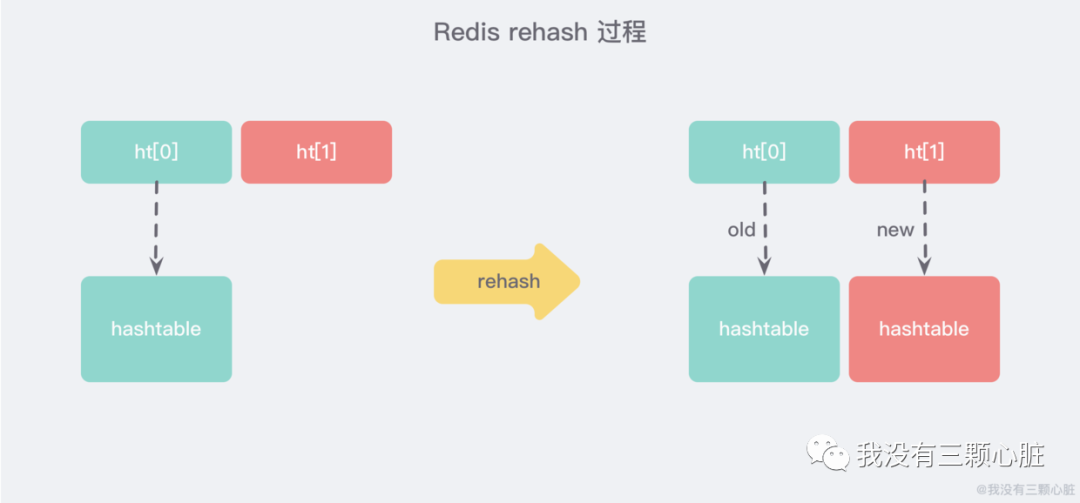
漸進式 rehash 會在 rehash 的同時,保留新舊兩個 hash 結(jié)構(gòu),如上圖所示,查詢時會同時查詢兩個 hash 結(jié)構(gòu),然后在后續(xù)的定時任務(wù)以及 hash 操作指令中,循序漸進的把舊字典的內(nèi)容遷移到新字典中。當搬遷完成了,就會使用新的 hash 結(jié)構(gòu)取而代之。
擴縮容的條件
正常情況下,當 hash 表中 元素的個數(shù)等于第一維數(shù)組的長度時,就會開始擴容,擴容的新數(shù)組是 原數(shù)組大小的 2 倍。不過如果 Redis 正在做 bgsave(持久化命令),為了減少內(nèi)存也得過多分離,Redis 盡量不去擴容,但是如果 hash 表非常滿了,達到了第一維數(shù)組長度的 5 倍了,這個時候就會 強制擴容。
當 hash 表因為元素逐漸被刪除變得越來越稀疏時,Redis 會對 hash 表進行縮容來減少 hash 表的第一維數(shù)組空間占用。所用的條件是 元素個數(shù)低于數(shù)組長度的 10%,縮容不會考慮 Redis 是否在做 bgsave。
字典的基本操作
hash 也有缺點,hash 結(jié)構(gòu)的存儲消耗要高于單個字符串,所以到底該使用 hash 還是字符串,需要根據(jù)實際情況再三權(quán)衡:
> HSET books java "think in java" # 命令行的字符串如果包含空格則需要使用引號包裹
(integer) 1
> HSET books python "python cookbook"
(integer) 1
> HGETALL books # key 和 value 間隔出現(xiàn)
1) "java"
2) "think in java"
3) "python"
4) "python cookbook"
> HGET books java
"think in java"
> HSET books java "head first java"
(integer) 0 # 因為是更新操作,所以返回 0
> HMSET books java "effetive java" python "learning python" # 批量操作
OK
4)集合 set
Redis 的集合相當于 Java 語言中的 HashSet,它內(nèi)部的鍵值對是無序、唯一的。它的內(nèi)部實現(xiàn)相當于一個特殊的字典,字典中所有的 value 都是一個值 NULL。
集合 set 的基本使用
由于該結(jié)構(gòu)比較簡單,我們直接來看看是如何使用的:
> SADD books java
(integer) 1
> SADD books java # 重復(fù)
(integer) 0
> SADD books python golang
(integer) 2
> SMEMBERS books # 注意順序,set 是無序的
1) "java"
2) "python"
3) "golang"
> SISMEMBER books java # 查詢某個 value 是否存在,相當于 contains
(integer) 1
> SCARD books # 獲取長度
(integer) 3
> SPOP books # 彈出一個
"java"
5)有序列表 zset
這可能使 Redis 最具特色的一個數(shù)據(jù)結(jié)構(gòu)了,它類似于 Java 中 SortedSet 和 HashMap 的結(jié)合體,一方面它是一個 set,保證了內(nèi)部 value 的唯一性,另一方面它可以為每個 value 賦予一個 score 值,用來代表排序的權(quán)重。
它的內(nèi)部實現(xiàn)用的是一種叫做 「跳躍表」 的數(shù)據(jù)結(jié)構(gòu),由于比較復(fù)雜,所以在這里簡單提一下原理就好了:
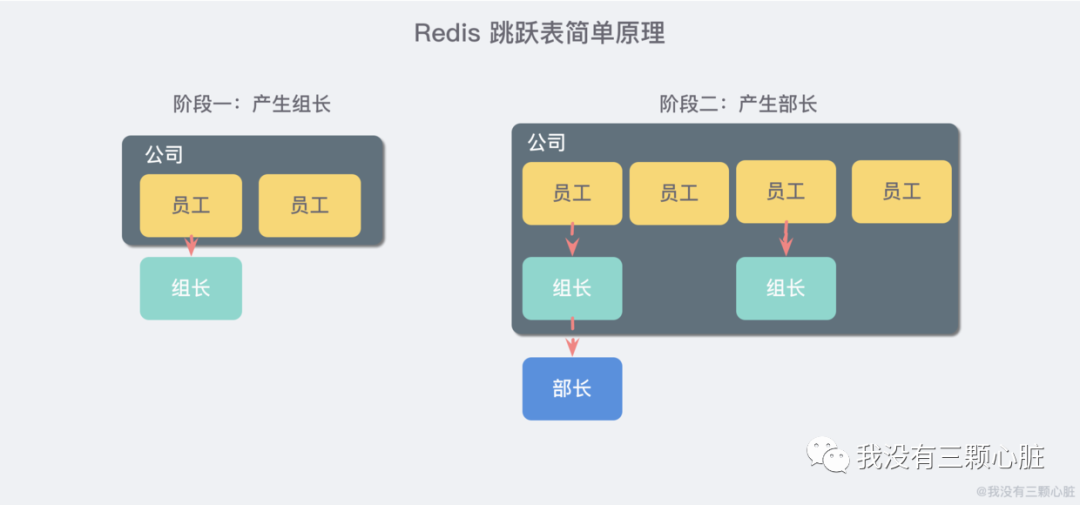
想象你是一家創(chuàng)業(yè)公司的老板,剛開始只有幾個人,大家都平起平坐。后來隨著公司的發(fā)展,人數(shù)越來越多,團隊溝通成本逐漸增加,漸漸地引入了組長制,對團隊進行劃分,于是有一些人又是員工又有組長的身份。
再后來,公司規(guī)模進一步擴大,公司需要再進入一個層級:部門。于是每個部門又會從組長中推舉一位選出部長。
跳躍表就類似于這樣的機制,最下面一層所有的元素都會串起來,都是員工,然后每隔幾個元素就會挑選出一個代表,再把這幾個代表使用另外一級指針串起來。然后再在這些代表里面挑出二級代表,再串起來。最終形成了一個金字塔的結(jié)構(gòu)。
想一下你目前所在的地理位置:亞洲 > 中國 > 某省 > 某市 > ....,就是這樣一個結(jié)構(gòu)!
有序列表 zset 基礎(chǔ)操作
> ZADD books 9.0 "think in java"
> ZADD books 8.9 "java concurrency"
> ZADD books 8.6 "java cookbook"
> ZRANGE books 0 -1 # 按 score 排序列出,參數(shù)區(qū)間為排名范圍
1) "java cookbook"
2) "java concurrency"
3) "think in java"
> ZREVRANGE books 0 -1 # 按 score 逆序列出,參數(shù)區(qū)間為排名范圍
1) "think in java"
2) "java concurrency"
3) "java cookbook"
> ZCARD books # 相當于 count()
(integer) 3
> ZSCORE books "java concurrency" # 獲取指定 value 的 score
"8.9000000000000004" # 內(nèi)部 score 使用 double 類型進行存儲,所以存在小數(shù)點精度問題
> ZRANK books "java concurrency" # 排名
(integer) 1
> ZRANGEBYSCORE books 0 8.91 # 根據(jù)分值區(qū)間遍歷 zset
1) "java cookbook"
2) "java concurrency"
> ZRANGEBYSCORE books -inf 8.91 withscores # 根據(jù)分值區(qū)間 (-∞, 8.91] 遍歷 zset,同時返回分值。inf 代表 infinite,無窮大的意思。
1) "java cookbook"
2) "8.5999999999999996"
3) "java concurrency"
4) "8.9000000000000004"
> ZREM books "java concurrency" # 刪除 value
(integer) 1
> ZRANGE books 0 -1
1) "java cookbook"
2) "think in java"
如果大家想要實時關(guān)注我更新的文章以及分享的干貨的話,可以關(guān)注我的公眾號Java3y。
獲取Java精美腦圖

?獲取Java學(xué)習(xí)路線
獲取開發(fā)常用工具
?加入技術(shù)交流群
在公眾號下回復(fù)「888」即可獲取!!
點個在看 ,分享到朋友圈
,分享到朋友圈 ,對我真的很重要!!
,對我真的很重要!!