
知識蒸餾在推薦系統(tǒng)中的應(yīng)用
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)

作者:張俊林 新浪微博 AI Lab 負(fù)責(zé)人
來源:深度學(xué)習(xí)前沿筆記@知乎專欄
注:轉(zhuǎn)載請聯(lián)系作者本人。
導(dǎo)讀:隨著深度學(xué)習(xí)的快速發(fā)展,優(yōu)秀的模型層出不窮,比如圖像領(lǐng)域的 ResNet、自然語言處理領(lǐng)域的 Bert,這些革命性的新技術(shù)使得應(yīng)用效果快速提升。但是,好的模型性能并非無代價的,你會發(fā)現(xiàn),深度學(xué)習(xí)模型正在變得越來越復(fù)雜,網(wǎng)絡(luò)深度越來越深,模型參數(shù)量也在變得越來越多。而這會帶來一個現(xiàn)實應(yīng)用的問題:將這種復(fù)雜模型推上線,模型響應(yīng)速度太慢,當(dāng)流量大的時候撐不住。
知識蒸餾就是目前一種比較流行的解決此類問題的技術(shù)方向。一般知識蒸餾采取 Teacher-Student 模式:將復(fù)雜模型作為 Teacher,Student 模型結(jié)構(gòu)較為簡單,用 Teacher 來輔助 Student 模型的訓(xùn)練,Teacher 學(xué)習(xí)能力強,可以將它學(xué)到的暗知識 ( Dark Knowledge ) 遷移給學(xué)習(xí)能力相對弱的 Student 模型,以此來增強 Student 模型的泛化能力。復(fù)雜笨重但是效果好的 Teacher 模型不上線,就單純是個導(dǎo)師角色,真正上戰(zhàn)場擋搶撐流量的是靈活輕巧的 Student 小模型。比如 Bert,因為太重,很難直接上線跑,目前很多公司都是采取知識蒸餾的方法,學(xué)會一個輕巧,但是因為被 Teacher 教導(dǎo)過,所以效果也很好的 Student 模型部署上線。
01
知識蒸餾典型方法
目前知識蒸餾已經(jīng)成了獨立研究方向,各種新技術(shù)層出不窮。但是如果粗略歸納一下的話,主流的知識蒸餾技術(shù)有兩個技術(shù)發(fā)展主線:Logits 方法及特征蒸餾方法。
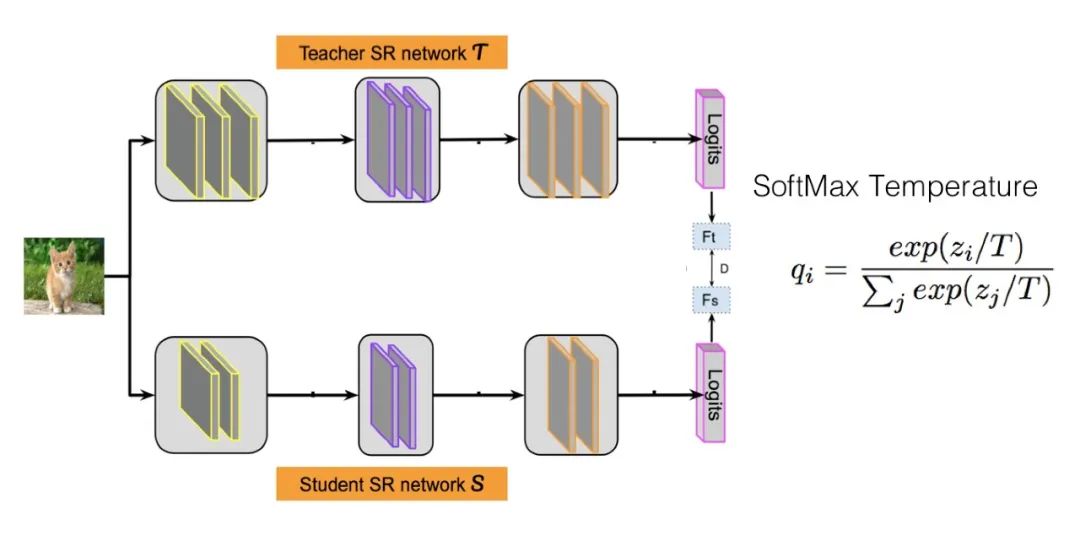
知道了什么是 Logits 后,我們來說什么是 Logits 蒸餾方法。假設(shè)我們有一個 Teacher 網(wǎng)絡(luò),一個 Student 網(wǎng)絡(luò),輸入同一個數(shù)據(jù)給這兩個網(wǎng)絡(luò),Teacher 會得到一個 Logits 向量,代表 Teacher 認(rèn)為輸入數(shù)據(jù)屬于各個類別的可能性;Student 也有一個 Logits 向量,代表了 Student 認(rèn)為輸入數(shù)據(jù)屬于各個類別的可能性。最簡單也是最早的知識蒸餾工作,就是讓 Student 的 Logits 去擬合 Teacher 的 Logits,即 Student 的損失函數(shù)為:

其中,zt 是 Teacher 的 Logits,zs 是 Student 的 Logits。在這里,Teacher 的 Logits 就是傳給 Student 的暗知識。
Hinton 在論文 Distilling the Knowledge in a Neural Network 中提出了稱為 Softmax Temperature 的改進(jìn)方法,并第一次正式提出了"知識蒸餾"的叫法。Softmax Temperature 改造了 Softmax 函數(shù) ( 公式參考上圖 ),引入了溫度 T,這是一個超參數(shù)。如果我們把 T 設(shè)置成1,就是標(biāo)準(zhǔn)的 Softmax 函數(shù),也就是極端兩極分化版本。如果將 T 設(shè)大,則 Softmax 之后的 Logits 數(shù)值,各個類別之間的概率分值差距會縮小,也即是強化那些非最大類別的存在感;反之,則會加大類別間概率的兩極分化。Hinton 版本的知識蒸餾,讓 Student 去擬合 Teacher 經(jīng)過 T 影響后 Softmax 得到的,其實也是讓 Student 去學(xué)習(xí) Teacher 的 Logits,無非是加入 T 后可以動態(tài)調(diào)節(jié) Logits 的分布。Student 的損失函數(shù)由兩項組成,一個子項是 Ground Truth,就是在訓(xùn)練集上的標(biāo)準(zhǔn)交叉熵?fù)p失,讓 Student 去擬合訓(xùn)練數(shù)據(jù),另外一個是蒸餾損失,讓 Student 去擬合 Teacher 的 Logits:

H 是交叉熵?fù)p失函數(shù),f(x) 是 Student 模型的映射函數(shù),y 是 Ground Truth Label,zt 是 Teacher 的 Logits,zs 是 Student 的 Logits, ST() 是 Softmax Temperature 函數(shù),λ 用于調(diào)節(jié)蒸餾 Loss 的影響程度。
一般而言,溫度 T 要設(shè)置成大于1的數(shù)值,這樣會減小不同類別歸屬概率的兩極分化程度,因為 Logits 方法中,Teacher 能夠提供給 Student 的額外信息就包含在 Logits 數(shù)值里。如果我們在蒸餾損失部分,將 T 設(shè)置成1,采用常規(guī)的 Softmax,也就是說兩極分化嚴(yán)重時,那么相對標(biāo)準(zhǔn)的訓(xùn)練數(shù)據(jù),也就是交叉熵?fù)p失,兩者等同,Student 從蒸餾損失中就學(xué)不到任何額外的信息。
另外一種大的知識蒸餾思路是特征蒸餾方法,如上圖所示。它不像 Logits 方法那樣,Student 只學(xué)習(xí) Teacher 的 Logits 這種結(jié)果知識,而是學(xué)習(xí) Teacher 網(wǎng)絡(luò)結(jié)構(gòu)中的中間層特征。最早采用這種模式的工作來自于自于論文:"FITNETS:Hints for Thin Deep Nets",它強迫 Student 某些中間層的網(wǎng)絡(luò)響應(yīng),要去逼近 Teacher 對應(yīng)的中間層的網(wǎng)絡(luò)響應(yīng)。這種情況下,Teacher 中間特征層的響應(yīng),就是傳遞給 Student 的暗知識。在此之后,出了各種新方法,但是大致思路還是這個思路,本質(zhì)是 Teacher 將特征級知識遷移給 Student。因為介紹各種知識蒸餾方法不是我們的主題,這里不展開了,我們盡快切入主題。
02
知識蒸餾在推薦系統(tǒng)中的三個應(yīng)用場景
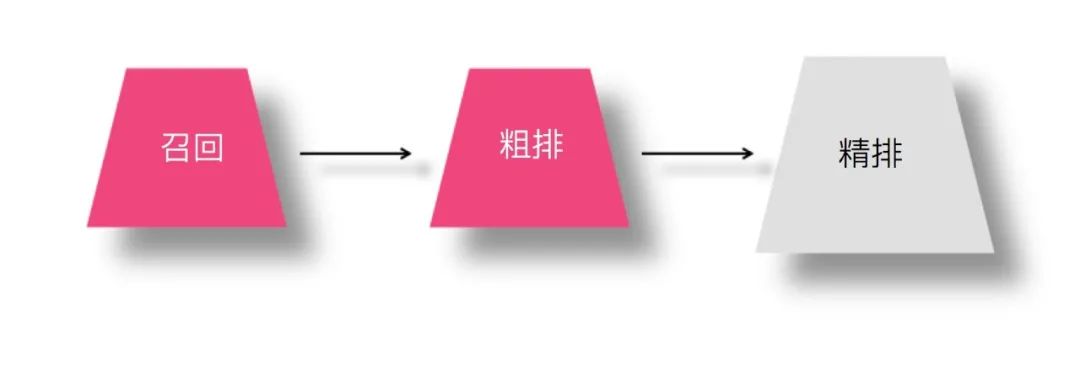
那么,在這種串行級聯(lián)的推薦體系中,知識蒸餾可以應(yīng)用在哪個環(huán)節(jié)呢?假設(shè)我們在召回環(huán)節(jié)采用模型排序 ( FM/FFM/DNN 雙塔等模型 ),那么知識蒸餾在上述三個環(huán)節(jié)都可采用,不同環(huán)節(jié)采用知識蒸餾的目的可能也不太相同。也就是說,精排、粗排以及模型召回環(huán)節(jié)都可以采用知識蒸餾技術(shù)來優(yōu)化現(xiàn)有推薦系統(tǒng)的性能和效果,這里的性能指的線上服務(wù)響應(yīng)速度快,效果指的推薦質(zhì)量好。
1. 精排環(huán)節(jié)采用知識蒸餾
為何在精排環(huán)節(jié)采用知識蒸餾?我們知道,精排環(huán)節(jié)注重精準(zhǔn)排序,所以采用盡量多特征,復(fù)雜模型,以期待獲得優(yōu)質(zhì)的個性化推薦結(jié)果。但是,這同時也意味著復(fù)雜模型的在線服務(wù)響應(yīng)變慢。若承載相同流量,需要增加在線服務(wù)并行程度,也就意味著增加機器資源和成本,比如,DNN 排序模型相對 LR / FM 等非深度模型,在線推理速度下降明顯。此時,我們面臨兩難選擇:要么上簡單模型,但是付出的代價是推薦效果不如復(fù)雜模型好;要么上復(fù)雜模型,雖說效果是提高了,但是要付出額外的機器等資源及成本。有什么技術(shù)方案能夠在兩者之間做個均衡么?就是說,希望找到一個模型,這個模型既有較好的推薦質(zhì)量,又能有快速推理能力。我們可以實現(xiàn)這一目標(biāo)么?可以的,在精排環(huán)節(jié)上知識蒸餾模型即可。

上圖展示了如何在精排環(huán)節(jié)應(yīng)用知識蒸餾:我們在離線訓(xùn)練的時候,可以訓(xùn)練一個復(fù)雜精排模型作為 Teacher,一個結(jié)構(gòu)較簡單的 DNN 排序模型作為 Student。因為 Student 結(jié)構(gòu)簡單,所以模型表達(dá)能力弱,于是,我們可以在 Student 訓(xùn)練的時候,除了采用常規(guī)的 Ground Truth 訓(xùn)練數(shù)據(jù)外,Teacher 也輔助 Student 的訓(xùn)練,將 Teacher 復(fù)雜模型學(xué)到的一些知識遷移給 Student,增強其模型表達(dá)能力,以此加強其推薦效果。在模型上線服務(wù)的時候,并不用那個大 Teacher,而是使用小的 Student 作為線上服務(wù)精排模型,進(jìn)行在線推理。因為 Student 結(jié)構(gòu)較為簡單,所以在線推理速度會大大快于復(fù)雜模型;而因為 Teacher 將一些知識遷移給 Student,所以經(jīng)過知識蒸餾的 Student 推薦質(zhì)量也比單純 Student 自己訓(xùn)練質(zhì)量要高。這就是典型的在精排環(huán)節(jié)采用知識蒸餾的思路。至于具體蒸餾方法,后文會介紹。當(dāng)然,你也可以根據(jù)前文介紹的經(jīng)典知識蒸餾方案,自己試著想想應(yīng)該怎么做。
對于精排環(huán)節(jié)來說,我覺得,知識蒸餾比較適合以下兩種技術(shù)轉(zhuǎn)換場景:
一種是排序模型正在從非 DNN 模型初次向 DNN 模型進(jìn)行模型升級;在超大規(guī)模數(shù)據(jù)場景下,從非 DNN 模型切換到 DNN 模型,切換成本和付出的時間因素可能比你預(yù)想得要高,尤其是線上服務(wù)環(huán)節(jié),切換到 DNN 模型導(dǎo)致大量增加在線服務(wù)機器成本,這對于很多公司來說是無法接受的。如果在做模型升級的時候采取知識蒸餾方案,導(dǎo)致的效果是:相對線上的非 DNN 模型,即使上一個蒸餾小模型,效果也可能是有提升的,同時在線服務(wù)占用資源能降下來 ( 相對直接上個復(fù)雜 DNN 模型 ),在線服務(wù)速度快,所以可以明顯降低模型升級的成本,這樣可以相對容易地切換到 DNN 版本排序模型上來。
第二種情況是:目前盡管線上已經(jīng)采用了 DNN 排序模型,但是模型還非常簡單,這個也有利用知識蒸餾優(yōu)化效果的空間;這種情形下,現(xiàn)有在線模型的服務(wù)速度可能是足夠快的,因為在線服務(wù)模型還比較簡單,即使換成 Student 小模型,在這方面估計也差不太多。但是,可以期待通過知識蒸餾提升線上模型的推薦質(zhì)量。我們可以離線訓(xùn)練一個復(fù)雜但是效果明顯優(yōu)于線上簡單 DNN 排序模塊的模型作為 Teacher,然后通過知識蒸餾,訓(xùn)練一個可以代替目前線上模型的 Student 小模型。如果這樣,是有可能在響應(yīng)速度不降的前提下,模型效果上有所提升的。所以,感覺這種情況也比較適合采用蒸餾模型。
而對于其它情形,比如目前線上已有較為復(fù)雜的 DNN 排序系統(tǒng)的業(yè)務(wù)或者公司,至于是否要上知識蒸餾,則需要面臨一個權(quán)衡:采用知識蒸餾,線上服務(wù)模型從復(fù)雜模型切換成小模型,肯定可以明顯提高線上 QPS,減少服務(wù)資源,效率提升會比較大;但是,有可能推薦質(zhì)量比線上的大模型會有下降。所以,業(yè)務(wù)場景是否接受這種指標(biāo)的臨時下降?這個問題的答案決定了不同的選擇,在有些業(yè)務(wù)場景下,這是需要好好考慮考慮的。不同業(yè)務(wù)環(huán)境可能會作出不同的選擇。
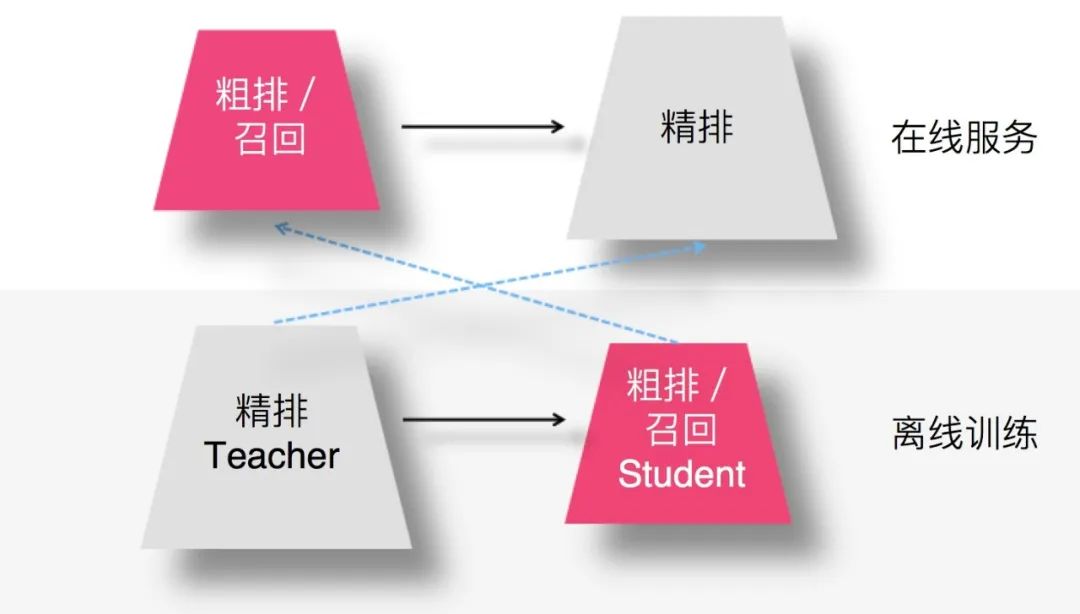
2. 模型召回以及粗排采用知識蒸餾
在模型召回環(huán)節(jié),或者粗排環(huán)節(jié),采取知識蒸餾的方案,是非常自然的一個想法拓展,而且非常合算。目前,這塊基本看不到完全公開細(xì)節(jié)的技術(shù)資料,所以本文我重點談?wù)勗谶@塊可能采用的技術(shù),和幾位同學(xué)討論出若干可能的方案會列在后面,感興趣的同學(xué)可以嘗試一下,在這里是很容易作出收益的,所以特別值得關(guān)注與嘗試,相信這塊用好了,會對完成你的KPI有幫助。
這里所謂的合算,怎么理解呢?因為召回或者粗排環(huán)節(jié),作為精排的前置環(huán)節(jié),有自己承擔(dān)的獨特職責(zé),需要在準(zhǔn)確性和速度方面找到一個平衡點,在保證一定推薦精準(zhǔn)性的前提下,對物品進(jìn)行粗篩,減小精排環(huán)節(jié)壓力。所以,這兩個環(huán)節(jié)本身,從其定位來說,并不追求最高的推薦精度,就算模型效果比精排差些,這也完全不成問題,畢竟在這兩個環(huán)節(jié),如果準(zhǔn)確性不足可以靠返回物品數(shù)量多來彌補。而模型小,速度快則是模型召回及粗排的重要目標(biāo)之一。這就和知識蒸餾本身的特點對上了,所以在這里用是特別合算的。
那么,召回或者粗排怎么用蒸餾呢?如果我們?nèi)缟蠄D所示,用復(fù)雜的精排模型作為 Teacher,召回或粗排模型作為小的 Student,比如 FM 或者雙塔 DNN 模型等,Student 模型模擬精排環(huán)節(jié)的排序結(jié)果,以此來指導(dǎo)召回或粗排 Student 模型的優(yōu)化過程。這樣,我們可以獲得滿足如下特性的召回或者粗排模型:首先,推薦效果好,因為 Student 經(jīng)過復(fù)雜精排模型的知識蒸餾,所以效果雖然弱于,但是可以非常接近于精排模型效果;其次,Student 模型結(jié)構(gòu)簡單,所以速度快,滿足這兩個環(huán)節(jié)對于速度的要求;再次,通過 Student 模型模擬精排模型的排序結(jié)果,可以使得前置兩個環(huán)節(jié)的優(yōu)化目標(biāo)和推薦任務(wù)的最終優(yōu)化目標(biāo)保持一致,在推薦系統(tǒng)中,前兩個環(huán)節(jié)優(yōu)化目標(biāo)保持和精排優(yōu)化目標(biāo)一致,其實是很重要的,但是這點往往在實做中容易被忽略,或者因條件所限無法考慮這一因素,比如非模型召回,從機制上是沒辦法考慮這點的。這里需要注意的一點是:如果召回模型或者粗排模型的優(yōu)化目標(biāo)已經(jīng)是多目標(biāo)的,對于新增的模型蒸餾來說,可以作為多目標(biāo)任務(wù)中新加入的一個新目標(biāo),當(dāng)然,也可以只保留單獨的蒸餾模型,完全替換掉之前的多目標(biāo)模型,貌似這兩種思路應(yīng)該都是可以的,需要根據(jù)具體情況進(jìn)行斟酌選擇。
由以上分析,可見,召回或粗排環(huán)節(jié)的知識蒸餾方案,看上去貌似是為召回和粗排環(huán)節(jié)量身定制的推薦系統(tǒng)優(yōu)化技術(shù)選項,對于召回或者粗排優(yōu)化來說,應(yīng)該是必試的一個技術(shù)選項。
下面我們討論下在推薦系統(tǒng)里,在各個環(huán)節(jié)采用知識蒸餾的可能的具體方法。精排蒸餾有兩篇公開文獻(xiàn)可供參考,而召回或粗排方面的蒸餾技術(shù),很少見相關(guān)公開資料,所以后面列的多數(shù)是我和幾位同學(xué)討論的方案,除個別方法有實踐結(jié)果外,大多方法仍處于設(shè)想階段,目前并未落地,所以不能保證有效性,這點還需要注意。
03
精排環(huán)節(jié)蒸餾方法

目前推薦領(lǐng)域里,在精排環(huán)節(jié)采用知識蒸餾,主要采用 Teacher 和 Student 聯(lián)合訓(xùn)練 ( Joint Learning ) 的方法,而目的是通過復(fù)雜 Teacher 來輔導(dǎo)小 Student 模型的訓(xùn)練,將 Student 推上線,增快模型響應(yīng)速度。
如上圖所示,所謂聯(lián)合訓(xùn)練,指的是在離線訓(xùn)練 Student 模型的時候,增加復(fù)雜 Teacher 模型來輔助 Student,兩者同時進(jìn)行訓(xùn)練,是一種訓(xùn)練過程中的輔導(dǎo)。從網(wǎng)絡(luò)結(jié)構(gòu)來說,Teacher 和 Student 模型共享底層特征 Embedding 層,Teacher 網(wǎng)絡(luò)具有層深更深、神經(jīng)元更多的 MLP 隱層,而 Student 則由較少層深及神經(jīng)元個數(shù)的 MLP 隱層構(gòu)成,兩者的 MLP 部分參數(shù)各自私有。對于所有訓(xùn)練數(shù)據(jù),會同時訓(xùn)練 Teacher 和 Student 網(wǎng)絡(luò),對于 Teacher 網(wǎng)絡(luò)來說,就是常規(guī)的訓(xùn)練過程,以交叉熵作為 Teacher 的損失函數(shù)。而對于 Student 網(wǎng)絡(luò)來說,損失函數(shù)由兩個部分構(gòu)成,一個子項是交叉熵,這是常規(guī)的損失函數(shù),它促使 Student 網(wǎng)絡(luò)去擬合訓(xùn)練數(shù)據(jù);另外一個子項則迫使 Student 輸出的 Logits 去擬合 Teacher 輸出的 Logits,所謂蒸餾,就體現(xiàn)在這個損失函數(shù)子項,通過這種手段讓 Teacher 網(wǎng)絡(luò)增強 Student 網(wǎng)絡(luò)的模型泛化能力。也即:

H 是交叉熵?fù)p失函數(shù),f(x) 是 Student 模型的映射函數(shù),y 是 Ground Truth Label,zt 是 Teacher 的 Logits,zs 是 Student 的 Logits,λ 用于調(diào)節(jié)蒸餾 Loss 的影響程度。
這個模型是阿里媽媽在論文 "Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net" 中提出的,其要點有三:其一兩個模型同時訓(xùn)練;其二,Teacher 和 Student 共享特征 Embedding;其三,通過 Logits 進(jìn)行知識蒸餾。對細(xì)節(jié)部分感興趣的同學(xué)可以參考原始文獻(xiàn)。
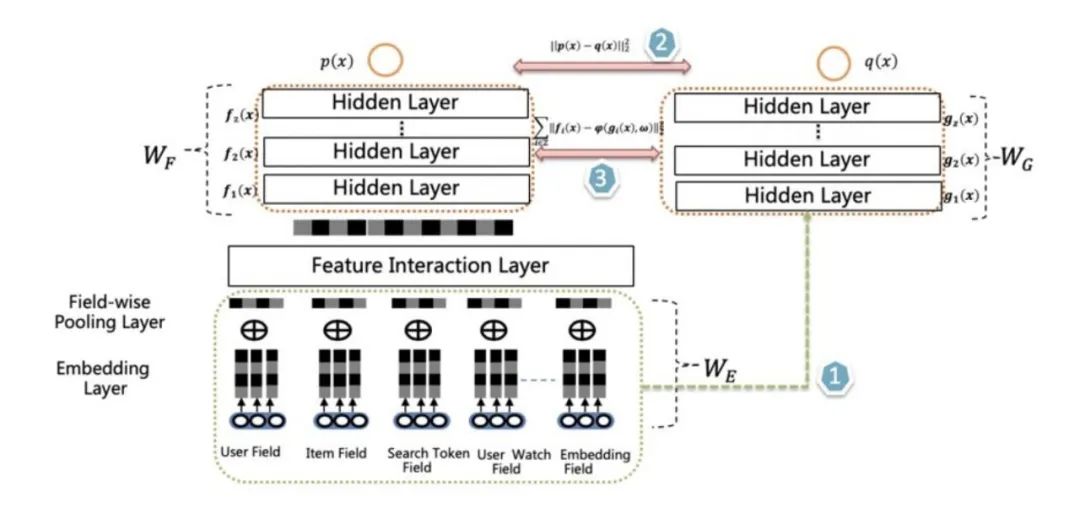
愛奇藝在排序階段提出了雙 DNN 排序模型,可以看作是在阿里的 rocket launching 模型基礎(chǔ)上的進(jìn)一步改進(jìn)。如上圖所示,Student 和 Teacher 共享特征 Embedding 參數(shù)層,Student 模型在損失函數(shù)中加入了擬合 Teacher 輸出階段的 Logits 子項,這兩點和 rocket launching 是類似的。主要改進(jìn)有兩點:首先,為了進(jìn)一步增強 student 的泛化能力,要求 student 的隱層 MLP 的激活也要學(xué)習(xí) Teacher 對應(yīng)隱層的響應(yīng),這點同樣可以通過在 student 的損失函數(shù)中加子項來實現(xiàn)。但是這會帶來一個問題,就是在 MLP 隱層復(fù)雜度方面,Student 和 Teacher 是相當(dāng)?shù)模覀冋f過,一般知識蒸餾,老師要比學(xué)生博學(xué),那么,在這個結(jié)構(gòu)里,Teacher 相比 student,模型復(fù)雜在哪里呢?這引出了第二點不同:雙 DNN 排序模型的 Teacher 在特征 Embedding 層和 MLP 層之間,可以比較靈活加入各種不同方法的特征組合功能,通過這種方式,體現(xiàn) Teacher 模型的較強的模型表達(dá)和泛化能力。
愛奇藝給出的數(shù)據(jù)對比說明了,這種模式學(xué)會的 Student 模型,線上推理速度是 Teacher 模型的5倍,模型大小也縮小了2倍。Student 模型的推薦效果也比 rocket launching 更接近 Teacher 的效果,這說明改進(jìn)的兩點對于 Teacher 傳授給 Student 更強的知識起到了積極作用。更多信息可參考:
04
召回/粗排環(huán)節(jié)蒸餾方法
上面介紹了阿里和愛奇藝在精排方面的兩個知識蒸餾應(yīng)用工作,目前知識蒸餾應(yīng)用在推薦領(lǐng)域的公開資料很少,雖說上面兩個工作是應(yīng)用在精排,目的是加快線上模型推理速度,但是稍微改進(jìn)一下,也可以應(yīng)用在召回模型以及粗排模型。
假設(shè)我們打算使用上述方案改造召回或者粗排模型,一種直觀的想法是:我們基本可以直接參照 rocket launching 的方案稍作改動即可。對于粗排或者召回模型來說,一般大家會用 DNN 雙塔模型建模,只需要將粗排或召回模型作為 Student,精排模型作為 Teacher,兩者聯(lián)合訓(xùn)練,要求 Student 學(xué)習(xí) Teacher 的 Logits,同時采取特征 Embedding 共享。如此這般,就可以讓召回或粗排模型學(xué)習(xí)精排模型的排序結(jié)果。快手曾經(jīng)在 AICon 分享過在粗排環(huán)節(jié)采取上面接近 rocket launching 的蒸餾技術(shù)方案,并取得了效果。
因雙塔結(jié)構(gòu)將用戶側(cè)和物品側(cè)特征分離編碼,所以類似愛奇藝技術(shù)方案的要求 Student 隱層學(xué)習(xí) Teacher 隱層響應(yīng),是很難做到的。粗排尚有可能,設(shè)計簡單網(wǎng)絡(luò) DNN 結(jié)構(gòu)的時候不采取雙塔結(jié)構(gòu)即可,召回環(huán)節(jié)幾無可能,除非把精排模型也改成雙塔結(jié)構(gòu),可能才能實現(xiàn)這點,但這樣可能會影響精排模型的效果。
但是,問題是:我們有必要這么興師動眾,為了訓(xùn)練召回或粗排的蒸餾模型,去聯(lián)合訓(xùn)練精排模型么?貌似如果這樣,召回模型對于排序模型耦合得過于緊密了,也有一定的資源浪費。其實我們未必一定要兩者聯(lián)合訓(xùn)練,也可以采取更節(jié)省成本的兩階段方法。
1. 召回蒸餾的兩階段方法
在專門的知識蒸餾研究領(lǐng)域里,蒸餾過程大都采取兩階段的模式,就是說第一階段先訓(xùn)練好 Teacher 模型,第二階段是訓(xùn)練 Student 的過程,在 Student 訓(xùn)練過程中會使用訓(xùn)練好 Teacher 提供額外的 Logits 等信息,輔助 Student 的訓(xùn)練。
私以為,精排環(huán)節(jié)貌似還是聯(lián)合訓(xùn)練比較好,而召回或粗排環(huán)節(jié)采取兩階段模式估計更有優(yōu)勢。為什么這么說呢?你可以這么想:如果我們的目的是希望訓(xùn)練一個小的 Student 精排模型,貌似沒有太大的必要采取兩階段訓(xùn)練過程,因為無論是聯(lián)合訓(xùn)練也好,還是兩階段訓(xùn)練也好,反正一大一小兩個模型都需要完整訓(xùn)練一遍,消耗的資源類似。而如果聯(lián)合訓(xùn)練,則還可以應(yīng)用特征 embedding 共享、隱層響應(yīng)學(xué)習(xí)等更多可選的技術(shù)改進(jìn)方案。所以貌似沒有太大必要改成兩階段的模式。
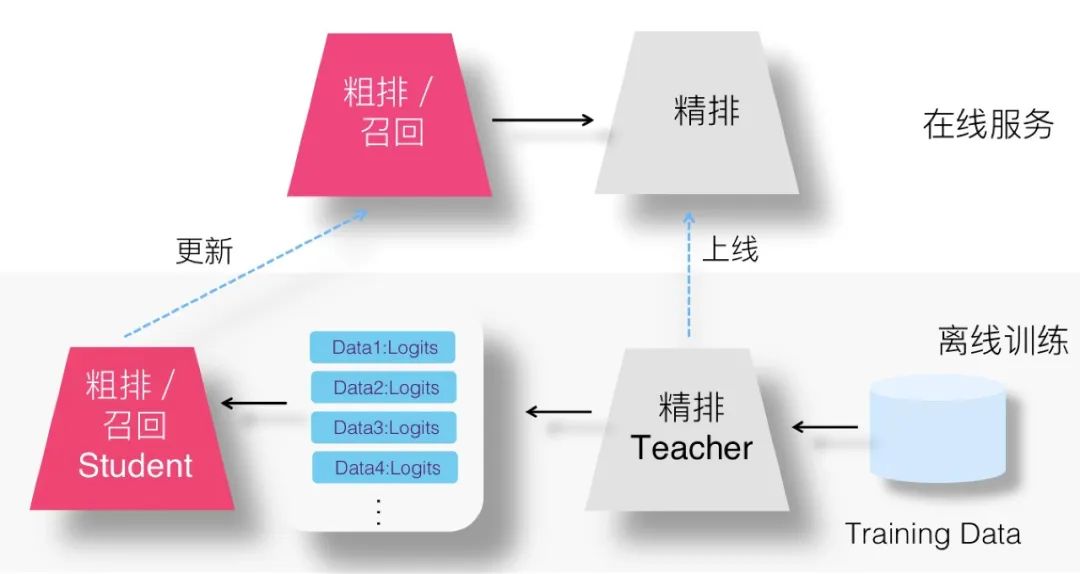
但是,如果是召回模型或粗排模型作為 Student,則情況有所不同。首先,比如隱層響應(yīng)等技術(shù)手段,本來召回或粗排 Student 模型就無法使用 ( 粗排如果不用雙塔,而是簡單 DNN 模型,還是可以的 ),所以聯(lián)合訓(xùn)練相對兩階段訓(xùn)練增加的好處不明顯。至于 Student 和 Teacher 特征 Embedding 共享,如果是在兩階段模式下,則可以改為使用 Teacher 訓(xùn)練好的特征 Embedding 初始化 Student 的特征,這樣貌似損失也不大,所以兩階段模式相對聯(lián)合訓(xùn)練模式,在效果方面并無明顯劣勢。另外,因為我們希望召回或者粗排模型學(xué)習(xí)精排模型,而一般而言,我們能夠拿到一個已經(jīng)訓(xùn)練好的精排模型,比如最近上線的精排模型,既然這樣,我們可以直接用當(dāng)前已訓(xùn)練好的精排模型,讓它把用于召回模型的訓(xùn)練數(shù)據(jù)跑一遍,給每個訓(xùn)練數(shù)據(jù)打上Logits信息,然后,就可以按照與聯(lián)合訓(xùn)練完全一樣的方式去訓(xùn)練召回蒸餾模型了,優(yōu)化目標(biāo)是 Ground Truth 子目標(biāo)和 Logits 蒸餾子目標(biāo)。上圖展示了這一過程。這樣做,明顯我們節(jié)省了精排 Teacher 的聯(lián)合訓(xùn)練迭代成本。不過,這種方法是否有效不確定,感興趣的同學(xué)可以嘗試一下,不過推論起來應(yīng)該是能保證效果的。
上面的方法,還是模仿精排蒸餾方式,無非改成了相對節(jié)省資源的兩階段模式。這里我們關(guān)心另外一個問題:對于召回蒸餾 Student 模型來說,是否一定要優(yōu)化那個 Ground Truth 子目標(biāo)?這可能要分情況看。按理說,蒸餾模型帶上 Ground Truth 優(yōu)化目標(biāo)肯定效果要好于不帶這個子目標(biāo)的模型。如果我們的召回模型或者粗排模型是單目標(biāo)的,比如就優(yōu)化點擊,那么明顯還是應(yīng)該帶上 Ground Truth 優(yōu)化目標(biāo)。但是,事實上,很可能我們手上的召回模型或粗排模型已經(jīng)是多目標(biāo)的了,那么這種情況下,其實蒸餾 Student 模型就沒有太大必要帶 Ground Truth 優(yōu)化目標(biāo),因為多目標(biāo)已經(jīng)各自做了這個事情了。這種情況下,獨立優(yōu)化蒸餾目標(biāo),然后將其作為多目標(biāo)的一個新目標(biāo)加入召回或粗排模型比較合適。
所以,我們下面介紹的方案,就拋掉 Ground Truth 優(yōu)化目標(biāo),單獨優(yōu)化蒸餾目標(biāo)。如果根據(jù)蒸餾 Student 模型是否需要參考 Teacher 提供的 Logits 信息來對方法進(jìn)行分類,又可以進(jìn)一步劃分為參考 Logits 信息的方案,和不參考 Logits 信息的方案。按理說,參考 Logits 信息效果應(yīng)該好些,但是,這樣 Student 仍然對 Teacher 有依賴,而不參考 Logits 信息的方案比較獨立,基本不需要精排模型的直接介入,所需信息直接可以在常規(guī)的推薦系統(tǒng) Log 里拿到,實現(xiàn)起來更具簡單和獨立性。而且,如果精排模型已經(jīng)是多目標(biāo)的,可能很難獲得那個 Logits 數(shù)值,但是我們能夠拿到精排模塊的排序結(jié)果,這意味著 Student 在優(yōu)化蒸餾目標(biāo)的時候,就已經(jīng)朝著多目標(biāo)進(jìn)行優(yōu)化了,是一種在召回或粗排進(jìn)行非精細(xì)化多目標(biāo)方向優(yōu)化的一種簡潔手段,所以有額外的好處。如果出于上述目的,此時明顯用非 Logits 方案更從容。綜合而言,從效果考慮,應(yīng)該考慮引入 Logits,從獨立性和簡潔性角度,可以參考非 Logits 方案。這可能與現(xiàn)實場景相關(guān)。
2. Logits 方案
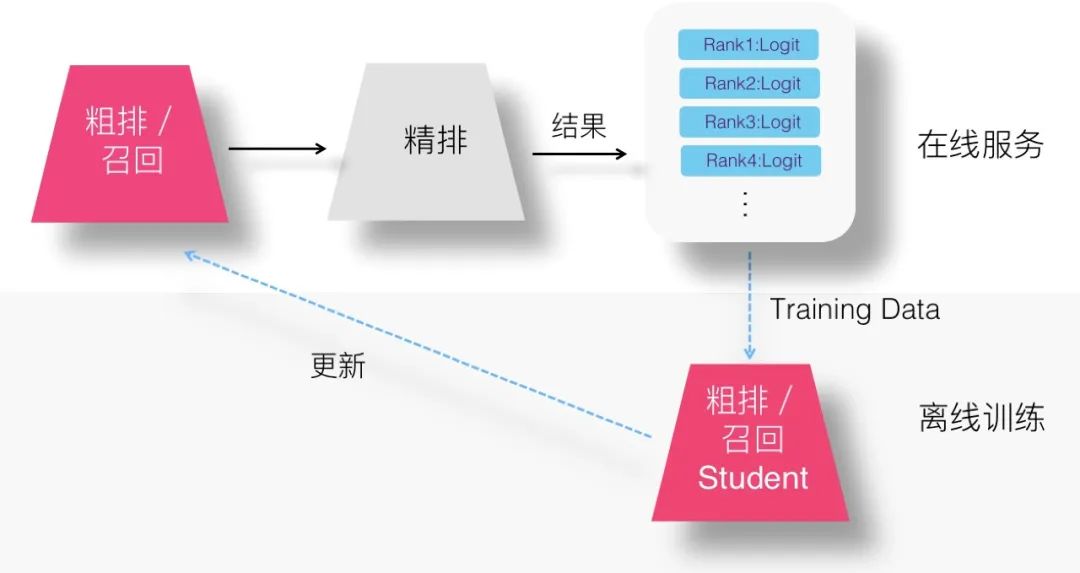
在召回或者精排采用知識蒸餾,此時,精排模型其實身兼二職:主業(yè)是做好線上的精準(zhǔn)排序,副業(yè)是順手可以教導(dǎo)一下召回及粗排模型。所以,其實我們?yōu)榱俗?Teacher 能夠教導(dǎo) Student,在訓(xùn)練 Student 的時候,并不需要專門訓(xùn)練一遍 Teacher 精排模型,因為它就在線上跑著呢。而且我們拋開了 Ground Truth 優(yōu)化子目標(biāo),所以不需要 Teacher 對訓(xùn)練數(shù)據(jù)都過一遍,而只需要多做一件事情:線上精排模型在輸出排序結(jié)果的時候,對于當(dāng)前判斷 <User,Item,Context> 實例,除了給出是否點擊等判斷外,只要把對應(yīng)優(yōu)化目標(biāo)的 Logits 數(shù)值輸出,并計入 Log 即可。這樣,召回或粗排模型可以直接使用訓(xùn)練數(shù)據(jù)中記載的 Logits,來作為 Student 的訓(xùn)練數(shù)據(jù),訓(xùn)練蒸餾模型,上圖展示了這一過程。所以,綜合看,這種 Logits 方案,是更節(jié)省計算資源的方案。當(dāng)然,上述都是我的個人推論,實際效果如何,還需要做對比實驗才能說明問題。
3. Without-Logits 方案
另外一類方法可以進(jìn)一步減少 Student 對 Teacher 的依賴,或適用于無法得到合理 Logits 信息的場合,即 Student 完全不參考 Logits 信息,但是精排作為 Teacher,怎么教導(dǎo) Student 呢?別忘了,精排模型的輸出結(jié)果是有序的,這里面也蘊含了 Teacher 的潛在知識,我們可以利用這個數(shù)據(jù)。也就是說,我們可以讓 Student 模型完全擬合精排模型的排序結(jié)果,以此學(xué)習(xí)精排的排序偏好。我們知道,對于每次用戶請求,推薦系統(tǒng)經(jīng)過幾個環(huán)節(jié),通過精排輸出 Top K 的 Item 作為推薦結(jié)果,這個推薦結(jié)果是有序的,排在越靠前的結(jié)果,應(yīng)該是精排系統(tǒng)認(rèn)為用戶越會點擊的物品。
那么,我們其實可以不用 Logits,粗排或者召回環(huán)節(jié)的 Student 的學(xué)習(xí)目標(biāo)是:像精排模型一樣排序。這時,精排模型仍然是 Teacher,只是傳給召回或粗排模型的知識不再是 Logits,而是一個有序的列表排序結(jié)果,我們希望 Student 從這個排序結(jié)果里面獲取額外的知識。如果這樣的話,對于目前的線上推薦系統(tǒng),不需要做任何額外的工作,因為排序結(jié)果是會記在 Log 里的 ( 也可以用推薦系統(tǒng)在精排之后,經(jīng)過 Re-ranker 重排后的排序結(jié)果,這樣甚至可以學(xué)習(xí)到一些去重打散等業(yè)務(wù)規(guī)則 ),只要拿到 Log 里的信息,我們就可以訓(xùn)練召回或粗排的 Student 蒸餾模型。
也就是說,對于召回或者粗排模型來說,它看到了若干精排的排序結(jié)果列表,精排模型的知識就蘊含在里面,而這可以作為 Student 模型的訓(xùn)練數(shù)據(jù)來訓(xùn)練蒸餾模型。很明顯,這是一個典型的 Learning to Rank 問題。我們知道,對于 LTR 問題,常見的優(yōu)化目標(biāo)包括三種:Point Wise、Pair Wise 和 List Wise。于是,我們可以按照這三種模式來設(shè)計召回模型或粗排模型的蒸餾學(xué)習(xí)任務(wù)。其中,下面文中提到的 Point Wise 方式我們已親試有效,至于 Pair Wise 和 List Wise 蒸餾,仍需實驗才能證明是否有效。
4. Point Wise 蒸餾
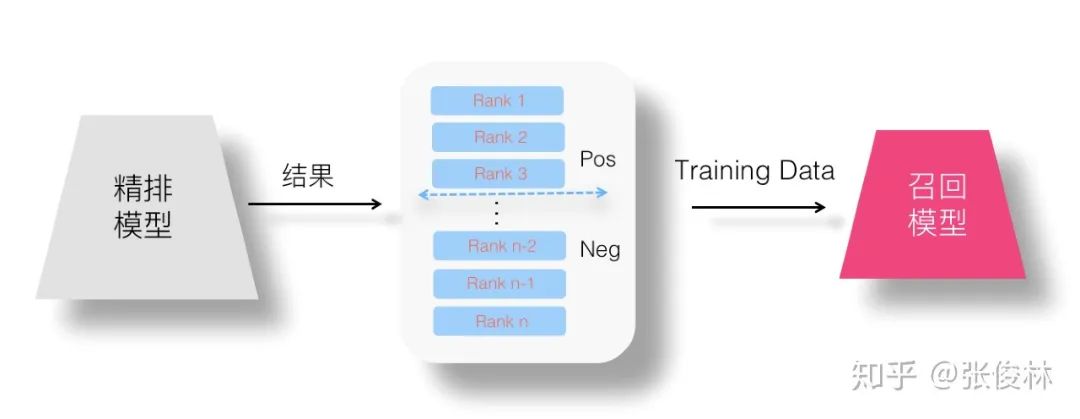
在 Point Wise 優(yōu)化目標(biāo)下理解召回模型蒸餾,就是說,我們把精排模型的有序輸出結(jié)果作為訓(xùn)練數(shù)據(jù),把學(xué)習(xí)目標(biāo)看作一個二分類問題,通過這種方式試圖學(xué)習(xí)精排模型的排序偏好。這種情況下,分類模型的正負(fù)例如何設(shè)定呢?我們不能把精排模型輸出結(jié)果列表里用戶行為過的 Item 作為正例,因為這樣你等于在學(xué)比如點擊或者互動等用戶行為模型,而不是在學(xué)精排模型的排序偏好。一般而言,可以這么做:假設(shè)精排每次返回 N 個結(jié)果,我們?nèi)×斜砬?Top K 的排序靠前的結(jié)果,將其指定為正例,位置K之后的例子,作為負(fù)例。意思是通過排名最高的一部分?jǐn)?shù)據(jù),來學(xué)習(xí)精排模型的排序偏好。這樣,我們就可以拿這些非標(biāo)注的排序結(jié)果來訓(xùn)練召回模型。當(dāng)然,這里的K是個超參,怎么定更合理,可能需要實驗來確定。上圖展示了這一做法。
通過這種方式,我們就可以讓召回模型從精排模型的排序列表中學(xué)到排序偏好知識,達(dá)成知識蒸餾的目標(biāo)。這種做法,有個可以改進(jìn)的點:上述切分正負(fù)例的方法,并未強調(diào)物品排序位置。比如假設(shè) K 值取5,就是排名前5的物品作為正例,之后的作為負(fù)例。正例中排名 Rank 1 的物品,和排名 Rank 4 的物品,都各自作為一條正例,沒有差別。但是,我們知道,Rank 1 應(yīng)該排名比 Rank 4 更高,但模型訓(xùn)練過程并沒有利用這個信息。我們可以通過對正例引入 Loss Weight 的簡單處理方法來引入這一信息,比如引入一個跟位置相關(guān)的 Weight 函數(shù):

其中,Rank Position 是 Item 的排名名次,將其作為變量引入函數(shù),以此映射函數(shù)的數(shù)值作為正例的 Loss Weight,負(fù)例 Loss Weight 權(quán)重與常規(guī)訓(xùn)練一樣,可認(rèn)為缺省 Loss Weight 權(quán)重為1。在具體設(shè)計這個函數(shù)的時候,指導(dǎo)思想是:希望這個函數(shù)能做到,排名越靠前的正例,對應(yīng)的 Loss Weight 越大。將這個 Loss Weight 引入損失函數(shù)中,就可以讓模型更關(guān)注排名靠前的物品。比如,我們可以這么定義函數(shù):

這里,Position 是排名位置,比如:
Rank Position=1,則 Position=1
Rank Position=4,則 Position=4
通過這種定義,就能使得排名靠前的正例,對應(yīng)的 Loss Weight 越大,而 a 可以作為調(diào)節(jié)權(quán)重,來放大或者縮小排名位置的影響。當(dāng)然,這里還可以引入其它各種花樣的 Loss Weight 定義方法。
熱門微博嘗試了上述思路 FM 版本的蒸餾召回模型 ( 多目標(biāo)召回模型基礎(chǔ)上增加蒸餾召回目標(biāo) ),線上 AB 測試效果,在時長、點擊、互動等多個指標(biāo)都有2+%到6+%之間的不同程度的提升作用,目前正在嘗試更多變體模型。
5. Pair Wise 蒸餾
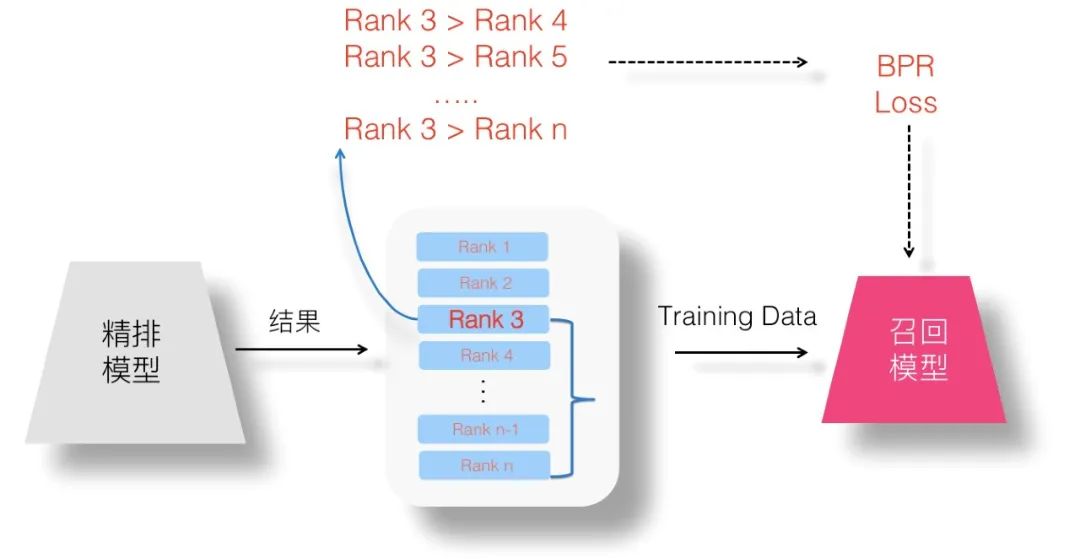
如果我們用 Pair Wise Loss 的方式來看待召回模型優(yōu)化問題,可以這么思考:精排的排序結(jié)果是有序列表,在列表內(nèi)隨機任意抽取兩個 Item,都能維持序關(guān)系。那么很明顯,我們可以構(gòu)造成對的訓(xùn)練數(shù)據(jù),以 Item 為正例,以排在 Item 后面任意某個 Item 作為負(fù)例,以此方式構(gòu)造訓(xùn)練數(shù)據(jù)來訓(xùn)練模型。在推薦領(lǐng)域,最常用的 Pair Wise Loss 是 BPR 損失函數(shù),于是我們可以如法炮制,如上圖所示,假設(shè)對于排在第三位的 Item 作為正例,可以抽取排名在其之后的 Item,構(gòu)造足夠多的成對訓(xùn)練數(shù)據(jù),以此目標(biāo)來優(yōu)化召回模型,使得模型可以學(xué)會 Item 間的序列關(guān)系。

對 <Pos,Neg> 成對的訓(xùn)練數(shù)據(jù),BPR 損失函數(shù)希望某個預(yù)測系統(tǒng)能夠?qū)φ牡梅忠哂谪?fù)例的得分,具體計算方法如上圖所示,因為是個基礎(chǔ)概念,此處不展開介紹。
6. List Wise 蒸餾
Point Wise Loss 將學(xué)習(xí)問題簡化為單 Item 打分問題,Pair Wise Loss 對能夠保持序關(guān)系的訓(xùn)練數(shù)據(jù)對建模,而 List Wise Loss 則對整個排序列表順序關(guān)系建模。List Wise Loss 經(jīng)常被用在排序問題中,但是有個現(xiàn)實困難是訓(xùn)練數(shù)據(jù)不好做,因為排序列表里每個 Item 的價值需要人工標(biāo)注。
我們來考慮下召回蒸餾模型的 List Wise Loss 優(yōu)化目標(biāo)怎么做的問題。既然我們能拿到大量精排給出的有序列表,貌似我們是不缺訓(xùn)練數(shù)據(jù)的,但是這里隱藏著個潛在的問題,問題等會我們再說。我們先說個應(yīng)用案例,Instagram 的推薦系統(tǒng)在初排階段采用知識蒸餾的方法,使用精排作為 Teacher 來指導(dǎo) Student 的優(yōu)化,Student 的優(yōu)化目標(biāo)用的是 NDCG,這是一種非常常用的 List Wise Loss 函數(shù),對 Instagram 推薦系統(tǒng)感興趣的同學(xué)可以參考文章:
Instagram 推薦系統(tǒng):每秒預(yù)測 9000 萬個模型是怎么做到的?
不過遺憾的是,上述文章并未說明是具體怎么做的,只能靠我們自己來摸索一下。其實細(xì)想一下,在這里用 NDCG 來學(xué)習(xí)精排輸出的有序列表,這面臨待解決的問題:用 NDCG 是有前提條件的,有序列表中的每個 Item,都需要帶有一個價值分。比如對于搜索排序來說,最相關(guān) Item 是5分,次相關(guān) Item 是4分,類似這種分?jǐn)?shù),這一般是人工標(biāo)注上的,而 List Wise Loss 就希望排序系統(tǒng)能夠?qū)⒘斜碚w獲得的價值分最大化。上面我們提到存在的問題就是:精排系統(tǒng)只給出了 Item 之間的排序關(guān)系,每個 Item 并沒有提供對應(yīng)的價值分。
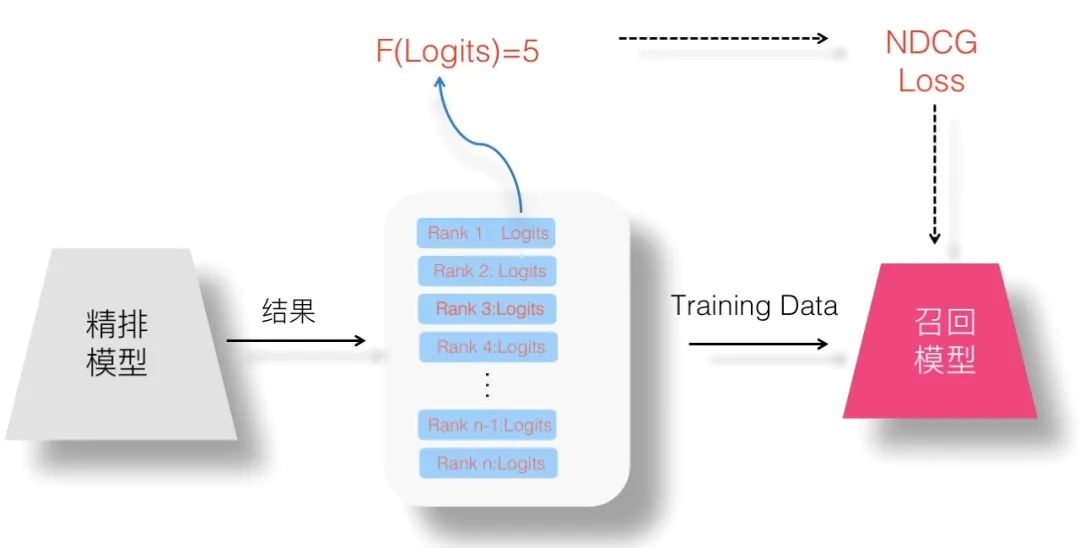
那么,如果想用 NDCG 或者類似的其它 List Wise 損失函數(shù),怎樣才能得到列表內(nèi)每個 Item 的價值分呢?人工打標(biāo)注顯然是不現(xiàn)實的。這里,感覺可以利用一下精排系統(tǒng)輸出的 Logits 信息,假設(shè)我們可以設(shè)計一個函數(shù):

這個函數(shù)以 Logits 分?jǐn)?shù)為輸入變量,將其映射到比如1分到5分幾檔上,Logits 得分越大,則對應(yīng)檔次分越高。如果我們能做到這點,就可以使用 List Wise 損失函數(shù)來訓(xùn)練召回或粗排模型了。這個函數(shù)定義有各種可能的方法,這里不展開,各位有興趣的同學(xué)可以試試。
如果我們想更簡單點,不用 Logits 分?jǐn)?shù),那么有更加簡單粗暴的方法,比如強行將有序列表排在 Top 5 的 Item 設(shè)置成5分,排在6到10位置的 Item 賦予4分…..類似這種。這等價于這么定義 F 函數(shù)的:

這個公式充分展示了工業(yè)界的簡單暴力算法美學(xué),我相信類似的公式充斥于各大公司的代碼倉庫角落里。
聯(lián)合訓(xùn)練召回、粗排及精排模型的設(shè)想
如果我們打算把知識蒸餾這個事情在推薦領(lǐng)域做得更徹底一點,比如在模型召回、粗排以及精排三個環(huán)節(jié)都用上,那么其實可以設(shè)想一種"一帶三"的模型聯(lián)合訓(xùn)練方法。
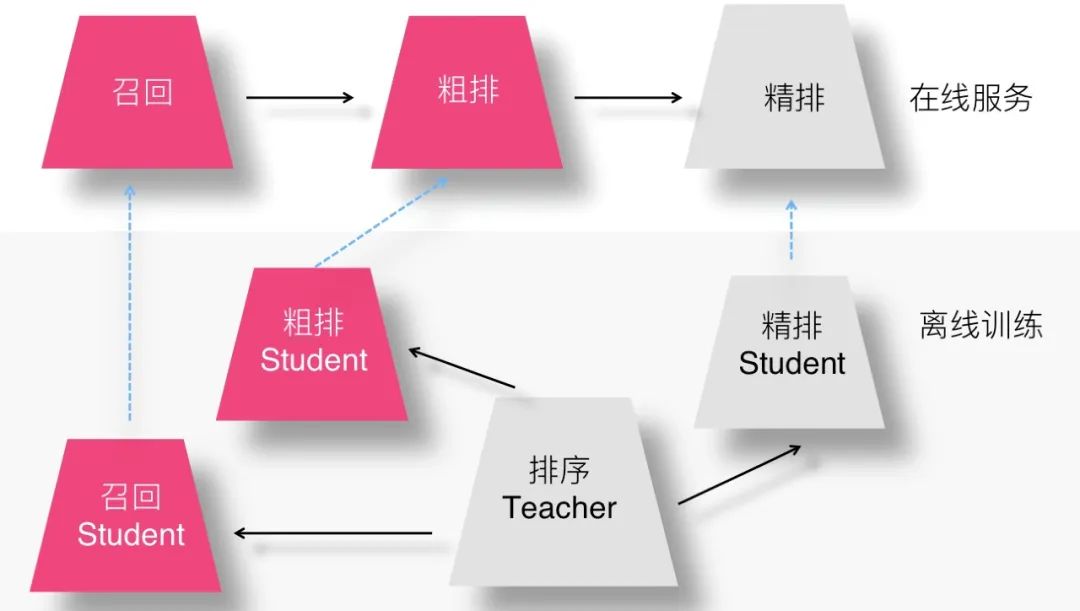
如上圖所示,我們可以設(shè)計一個很復(fù)雜但是效果很好的排序模型作為 Teacher,然后和召回、粗排、精排三個 Student 聯(lián)合訓(xùn)練,精排 Student 可以使用 Logits 以及隱層特征響應(yīng)等各種手段優(yōu)化,追求效果好前提下的盡可能速度快,召回和粗排 Student 則追求在模型小的前提下追求效果盡可能好。因為排序 Teacher 比較復(fù)雜,所以能夠提供盡可能好的模型效果,通過它來帶動三個環(huán)節(jié)蒸餾模型的效果,而模型速度快則是蒸餾方法的題中應(yīng)有之意。
這樣做有不少好處,比如可以一次訓(xùn)練,多環(huán)節(jié)收益;再比如可以最大程度上保持推薦系統(tǒng)各個環(huán)節(jié)的目標(biāo)一致性等;做起來又不太難,所以看上去是個可行的方案。
最后,歸納下全文,推薦系統(tǒng)在各個環(huán)節(jié)采取知識蒸餾方法,是可能達(dá)到提升推薦質(zhì)量的同時,提高推薦系統(tǒng)速度的,一舉兩得,比較容易產(chǎn)生效益,所以是值得深入探索及應(yīng)用的。
致謝:上面列的很多想法是在和幾位同學(xué)的討論中形成或完善的,感謝微博機器學(xué)習(xí)佘青云、王志強等同學(xué)提出的思路和建議。
今天的分享就到這里,謝謝大家。
好消息!
小白學(xué)視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學(xué)視覺」公眾號后臺回復(fù):擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學(xué)校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~