
CV語義分割實踐指南!
遙感技術已成為獲取地表覆蓋信息最為行之有效的手段,已經(jīng)成功應用于地表覆蓋檢測、植被面積檢測和建筑物檢測任務。本文以天池學習賽地表建筑物識別為例,對語義分割類項目的實踐全流程進行了解析。具體流程如下:
賽題理解
賽題名稱:零基礎入門語義分割-地表建筑物識別 賽題地址:https://tianchi.aliyun.com/competition/entrance/531872/information
1.1 賽題數(shù)據(jù)
本賽題使用航拍數(shù)據(jù),需要參賽選手完成地表建筑物識別,將地表航拍圖像素劃分為有建筑物和無建筑物兩類。
如下圖,左邊為原始航拍圖,右邊為對應的建筑物標注。
1.2 數(shù)據(jù)標簽
賽題為語義分割任務,因此具體的標簽為圖像像素類別。在賽題數(shù)據(jù)中像素屬于2類(無建筑物和有建筑物),因此標簽為有建筑物的像素。賽題原始圖片為jpg格式,標簽為RLE編碼的字符串。
RLE全稱(run-length encoding),翻譯為游程編碼或行程長度編碼,對連續(xù)的黑、白像素數(shù)以不同的碼字進行編碼。RLE是一種簡單的非破壞性資料壓縮法,經(jīng)常用在在語義分割比賽中對標簽進行編碼。
RLE與圖片之間的轉(zhuǎn)換代碼詳見本文第二節(jié)Baseline代碼解析。
1.3 評價指標
賽題使用Dice coefficient來衡量選手結(jié)果與真實標簽的差異性,Dice coefficient可以按像素差異性來比較結(jié)果的差異性。Dice coefficient的具體計算方式如下:
其中是預測結(jié)果, 為真實標簽的結(jié)果。當與完全相同時Dice coefficient為1,排行榜使用所有測試集圖片的平均Dice coefficient來衡量,分數(shù)值越大越好。
1.4 解題思路
由于本次賽題是一個典型的語義分割任務,因此可以直接使用語義分割的模型來完成:
步驟1:使用FCN模型模型跑通具體模型訓練過程,并對結(jié)果進行預測提交; 步驟2:在現(xiàn)有基礎上加入數(shù)據(jù)擴增方法,并劃分驗證集以監(jiān)督模型精度; 步驟3:使用更加強大模型結(jié)構(gòu)(如Unet和PSPNet)或尺寸更大的輸入完成訓練; 步驟4:訓練多個模型完成模型集成操作;
Baseline代碼分析
Ⅰ.將圖片編碼為rle格式
import numpy as np
import pandas as pd
import cv2
# 將圖片編碼為rle格式
def rle_encode(im):
'''
im: numpy array, 1 - mask, 0 - background
Returns run length as string formated
'''
pixels = im.flatten(order = 'F')
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)Ⅱ.將rle格式進行解碼為圖片
# 將rle格式進行解碼為圖片
def rle_decode(mask_rle, shape=(512, 512)):
'''
mask_rle: run-length as string formated (start length)
shape: (height,width) of array to return
Returns numpy array, 1 - mask, 0 - background
'''
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
return img.reshape(shape, order='F')
RLE編碼的時候返回的時候每兩個數(shù)字有空格為間隔,利用s = mask_rle.split()將空格去掉。
s[0:][::2]表示(從1開始的)索引,s[1:][::2]表示個數(shù)。于是starts存的是索引,lengths存的是個數(shù),兩者為一一對應關系。
starts \-= 1轉(zhuǎn)化為(從0開始的)索引。
后續(xù)就是創(chuàng)建一副全0的一維序列,填充1,再按列排序,轉(zhuǎn)為二維的二值圖,就解碼成圖片了。
如果輸入的mask_rle是空的,那么返回的就是全為0的mask,可以觀察數(shù)據(jù)發(fā)現(xiàn),部分圖片的地表建筑不存在,他們的rle標簽也就是空的。
Ⅲ.定義數(shù)據(jù)集
class TianChiDataset(D.Dataset):
def __init__(self, paths, rles, transform, test_mode=False):
self.paths = paths
self.rles = rles
self.transform = transform
self.test_mode = test_mode
self.len = len(paths)
self.as_tensor = T.Compose([
T.ToPILImage(),
T.Resize(IMAGE_SIZE),
T.ToTensor(),
T.Normalize([0.625, 0.448, 0.688],
[0.131, 0.177, 0.101]),
])
# get data operation
def __getitem__(self, index):
#img = cv2.imread(self.paths[index])
img = np.array(Image.open(self.paths[index]))
if not self.test_mode:
mask = rle_decode(self.rles[index])
augments = self.transform(image=img, mask=mask)
return self.as_tensor(augments['image']), augments['mask'][None]#(3,256,256),(1,256,256)
else:
return self.as_tensor(img), ''
def __len__(self):
"""
Total number of samples in the dataset
"""
return self.len
定義數(shù)據(jù)集,主要作了數(shù)據(jù)的預處理。其中,我將opencv的讀取圖片換成了PIL讀取,因為路徑中包含中文augments['mask'][None]中的[None],將(256,256)的mask形狀轉(zhuǎn)為(1,256,256),起到升維作用。
Ⅳ.可視化一下效果
這一步主要是為了驗證上述的代碼。用了rle_encode(rle_decode(RLE標簽))==RLE標簽來驗證之前寫的RLE編碼和解碼正確性。
train_mask = pd.read_csv('數(shù)據(jù)集/train_mask.csv', sep='\t', names=['name', 'mask'])
train_mask['name'] = train_mask['name'].apply(lambda x: '數(shù)據(jù)集/train/' + x)
img = cv2.imread(train_mask['name'].iloc[0])
mask = rle_decode(train_mask['mask'].iloc[0])
print(rle_encode(mask) == train_mask['mask'].iloc[0])
train_mask['name'].apply(lambda x: '數(shù)據(jù)集/train/' + x)這一步就是在圖片前補全下路徑
0 KWP8J3TRSV.jpg
1 DKI3X4VFD3.jpg
2 AYPOE51XNI.jpg
3 1D9V7N0DGF.jpg
4 AWXXR4VYRI.jpg
0 數(shù)據(jù)集/train/KWP8J3TRSV.jpg
1 數(shù)據(jù)集/train/DKI3X4VFD3.jpg
2 數(shù)據(jù)集/train/AYPOE51XNI.jpg
3 數(shù)據(jù)集/train/1D9V7N0DGF.jpg
4 數(shù)據(jù)集/train/AWXXR4VYRI.jpg
實例化數(shù)據(jù)集
dataset = TianChiDataset(
train_mask['name'].values,
train_mask['mask'].fillna('').values,
trfm, False
)
fillna('')起到補全缺失值為''的作用
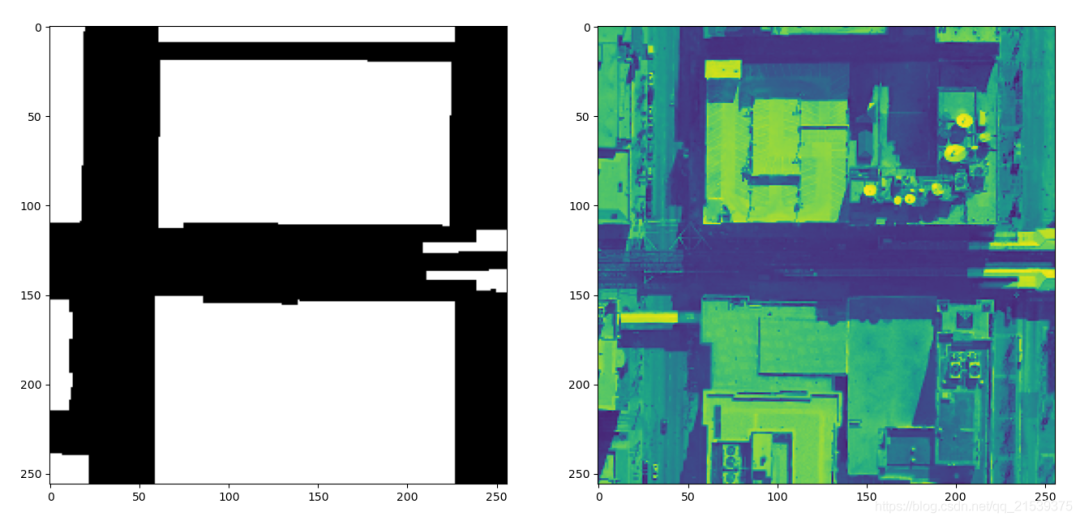
可視化
image, mask = dataset[0]
plt.figure(figsize=(16,8))
plt.subplot(121)
plt.imshow(mask[0], cmap='gray')
plt.subplot(122)
plt.imshow(image[0])
plt.show()# 補上
看一下第二張圖片
image, mask = dataset[1]
沒有建筑物,mask全黑。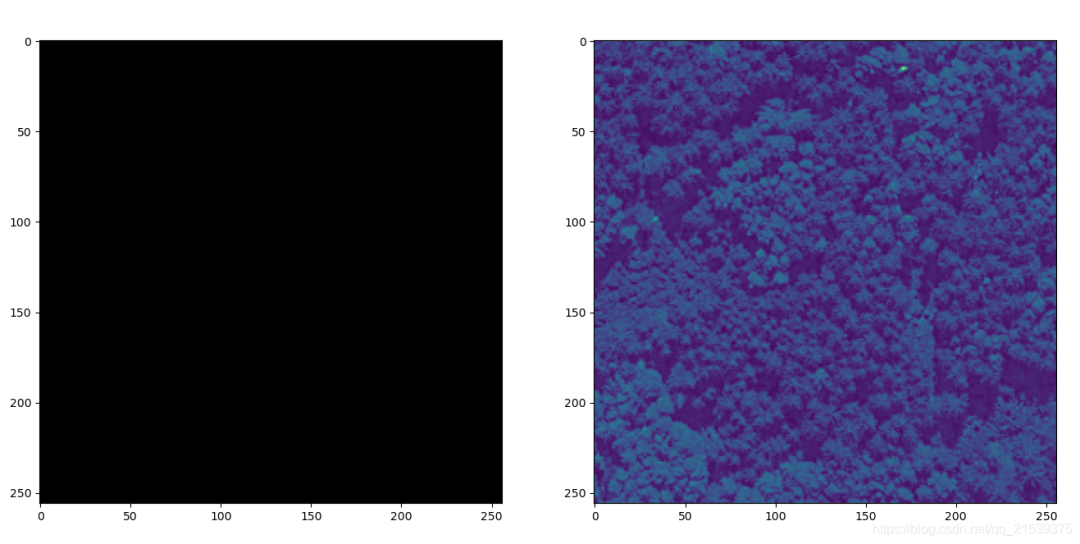
Ⅴ.加載數(shù)據(jù)集
#定義數(shù)據(jù)集
train_mask = pd.read_csv('數(shù)據(jù)集/train_mask.csv', sep='\t', names=['name', 'mask'])
train_mask['name'] = train_mask['name'].apply(lambda x: '數(shù)據(jù)集/train/' + x)
dataset = TianChiDataset(
train_mask['name'].values,
train_mask['mask'].fillna('').values,
trfm, False
)
#劃分數(shù)據(jù)集(按index手動去劃分)
valid_idx, train_idx = [], []
for i in range(len(dataset)):
if i % 7 == 0:
valid_idx.append(i)
else:
# elif i % 7 == 1:
train_idx.append(i)
train_ds = D.Subset(dataset, train_idx)
valid_ds = D.Subset(dataset, valid_idx)
# print(len(dataset))#30000
# print(len(train_ds))#4286
# print(len(valid_ds))#4286
# define training and validation data loaders
loader = D.DataLoader(
train_ds, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
vloader = D.DataLoader(
valid_ds, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)
D.subset是按照索引序列來劃分數(shù)據(jù)集的, 于是按照每7個數(shù)據(jù)里面,1個當作驗證集,6個當作訓練集。最后放入數(shù)據(jù)加載器中。
Ⅵ.定義模型、優(yōu)化器、損失函數(shù)
# 定義模型
model = get_model()
model.to(DEVICE)
#model.load_state_dict(torch.load("model_best.pth"))
#定義優(yōu)化器
optimizer = torch.optim.AdamW(model.parameters(),
lr=1e-4, weight_decay=1e-3)
#定義損失函數(shù)
bce_fn = nn.BCEWithLogitsLoss()
dice_fn = SoftDiceLoss()
def loss_fn(y_pred, y_true):
bce = bce_fn(y_pred, y_true)
dice = dice_fn(y_pred.sigmoid(), y_true)
return 0.8 * bce + 0.2 * dice
Ⅶ.進行訓練
header = r'''
Train | Valid
Epoch | Loss | Loss | Time, m
'''
# Epoch metrics time
raw_line = '{:6d}' + '\u2502{:7.3f}' * 2 + '\u2502{:6.2f}'
print(header)
EPOCHES = 10
best_loss = 10
for epoch in range(1, EPOCHES + 1):
losses = []
start_time = time.time()
model.train()
for image, target in tqdm(loader):#取消了tqdm
image, target = image.to(DEVICE), target.float().to(DEVICE)
optimizer.zero_grad()
output = model(image)['out']
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
# print(loss.item())
vloss = validation(model, vloader, loss_fn)
print(raw_line.format(epoch, np.array(losses).mean(), vloss,
(time.time() - start_time) / 60 ** 1))
losses = []
if vloss < best_loss:
best_loss = vloss
torch.save(model.state_dict(), 'model_best.pth')
print("save successful!")
Ⅷ.使用模型對測試集進行預測
trfm = T.Compose([
T.ToPILImage(),
T.Resize(IMAGE_SIZE),
T.ToTensor(),
T.Normalize([0.625, 0.448, 0.688],
[0.131, 0.177, 0.101]),
])
subm = []
model.load_state_dict(torch.load("./model_best.pth"))
model.eval()
test_mask = pd.read_csv('數(shù)據(jù)集/test_a_samplesubmit.csv', sep='\t', names=['name', 'mask'])
test_mask['name'] = test_mask['name'].apply(lambda x: '數(shù)據(jù)集/test_a/' + x)
for idx, name in enumerate(tqdm(test_mask['name'].iloc[:])):
image = np.array(Image.open(name))#改成PIL
image = trfm(image)
with torch.no_grad():
image = image.to(DEVICE)[None]
score = model(image)['out'][0][0]
score_sigmoid = score.sigmoid().cpu().numpy()
score_sigmoid = (score_sigmoid > 0.5).astype(np.uint8)
score_sigmoid = cv2.resize(score_sigmoid, (512, 512))
# break
subm.append([name.split('/')[-1], rle_encode(score_sigmoid)])
subm = pd.DataFrame(subm)
subm.to_csv('./tmp.csv', index=None, header=None, sep='\t')
Ⅸ.可視化模型預測結(jié)果
from file1 import rle_decode
from PIL import Image
import pandas as pd
import numpy as np
subm = pd.read_csv("./tmp.csv",sep="\t",names=["name","mask"])
def show_predict_pic(num=0):
plt.figure(figsize=(16,8))
plt.subplot(121)
plt.imshow(rle_decode(subm.fillna('').iloc[num,1]), cmap='gray')
plt.subplot(122)
plt.imshow(np.array(Image.open('數(shù)據(jù)集/test_a/' + subm.iloc[num,0])))
plt.show()
if __name__ == '__main__':
show_predict_pic(num=10)
查看第10張圖片的預測結(jié)果
