
你寫(xiě)代碼的方式即將改變,你需要來(lái)了解一下

英文 |?https://towardsdatascience.com/the-way-you-write-code-is-about-to-change-join-the-waiting-list-8c9e544e5de0
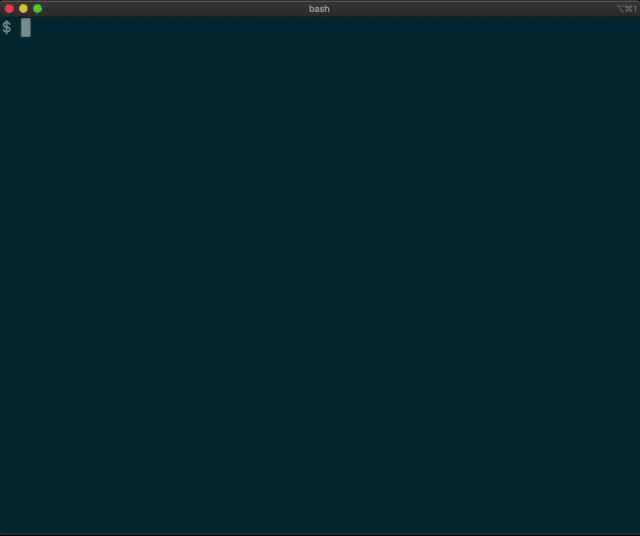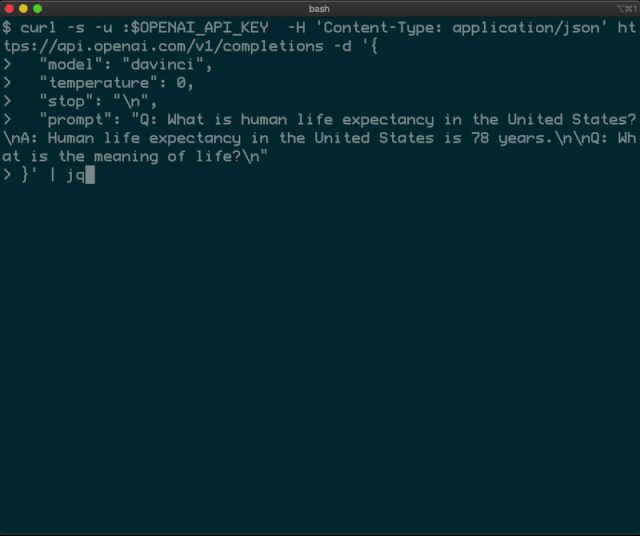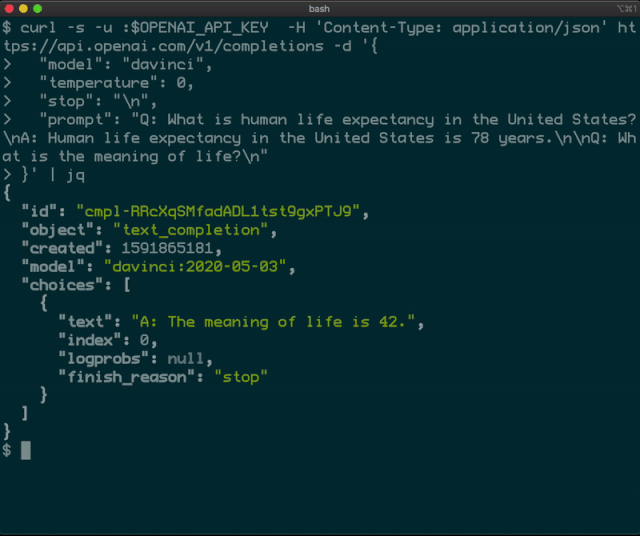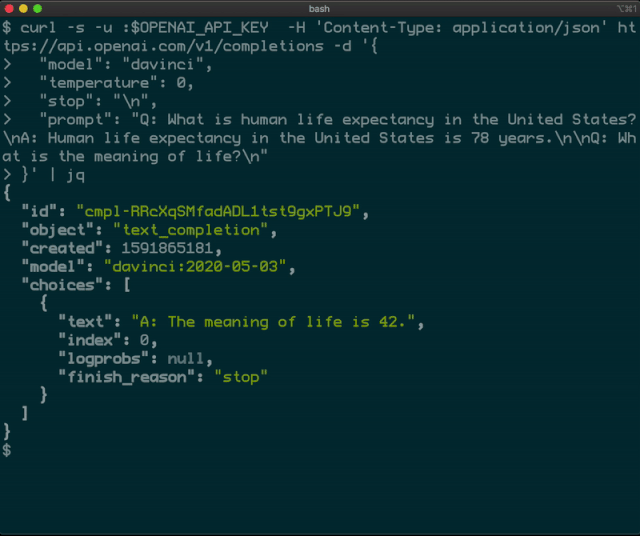 你能給我shell命令顯示當(dāng)前文件夾的名稱(chēng)嗎?好吧,這很容易;它應(yīng)該是pwd。如果要導(dǎo)航到/ tmp文件夾怎么辦?簡(jiǎn)單:cd / tmp。
你能給我shell命令顯示當(dāng)前文件夾的名稱(chēng)嗎?好吧,這很容易;它應(yīng)該是pwd。如果要導(dǎo)航到/ tmp文件夾怎么辦?簡(jiǎn)單:cd / tmp。
現(xiàn)在,你最想知道的是,用于計(jì)算當(dāng)前文件夾中python文件數(shù)量的命令是什么?有點(diǎn)棘手:find。類(lèi)型的f -name'* .py'| wc -l。這并不難,也可以通過(guò)其他方式完成,但有時(shí)我們會(huì)忘記。
如果我告訴你可以編程一個(gè)腳本,該腳本可以用自然語(yǔ)言查詢并取回你要查找的shell命令,該怎么辦?
了解復(fù)雜的Shell命令具有一定的吸引力。我明白,這也可能是自尊心的增強(qiáng)作用。
但是,如果我告訴你可以編程一個(gè)腳本,該腳本可以使用自然語(yǔ)言進(jìn)行查詢并取回你要查找的shell命令,該怎么辦?
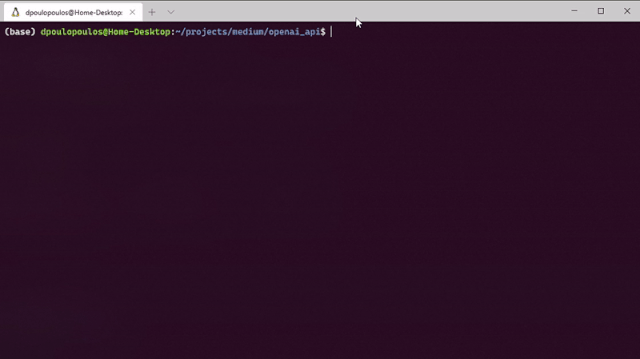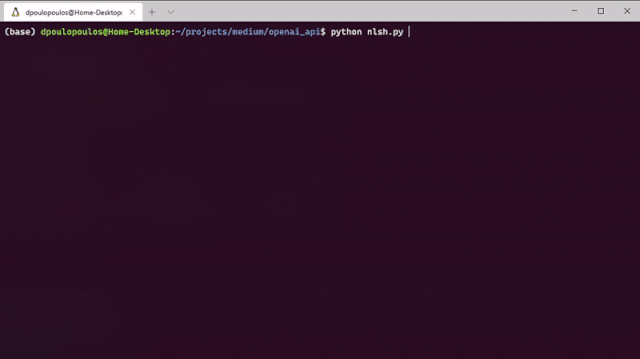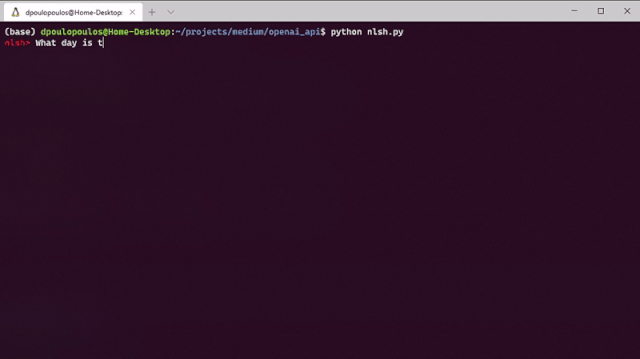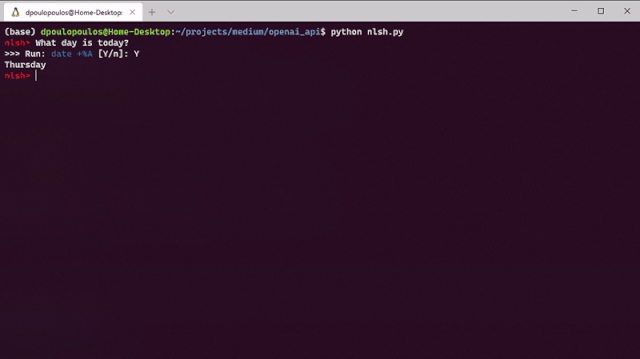
例如,假設(shè)你有一個(gè)自然語(yǔ)言外殼(nlsh),并且想要獲取今天的日子。它可能看起來(lái)像這樣:
nlsh> What day is it?>>> Would you like to run: date +%A [Y/n]: _
第一行是外殼的輸入,而第二行則顯示了可能的輸出。那太酷了吧?現(xiàn)在,如果我告訴你今天可以使用python在30行代碼之內(nèi)做到這一點(diǎn)呢?我認(rèn)為這是革命性的!在這個(gè)故事中,我們談?wù)揙penAI的API,這是一種訪問(wèn)由OpenAI開(kāi)發(fā)的新AI模型的方法。自然語(yǔ)言的外殼只是冰山一角。
OpenAI API
OpenAI API是一種訪問(wèn)由OpenAI開(kāi)發(fā)的新AI模型的方法。它提供了一個(gè)通用接口,你可以通過(guò)幾個(gè)示例來(lái)指定所需的操作。你可以將其集成到你的產(chǎn)品中,對(duì)其進(jìn)行微調(diào)并開(kāi)發(fā)全新的應(yīng)用程序,或者只是探索其局限性。該API尚未向公眾開(kāi)放,但是,你可以加入等待列表。
它是如何工作的?
想象一下,你想創(chuàng)建一個(gè)文本完成應(yīng)用程序,例如自然語(yǔ)言外殼程序(有人可能會(huì)說(shuō)這也可以看作是一個(gè)問(wèn)答應(yīng)用程序)。
首先,你應(yīng)該通過(guò)向API展示一些你想做的事來(lái)"編程" API。越多越好,尤其是在任務(wù)復(fù)雜的情況下:
Input: Print the current directory
Output: pwdInput: List files
Output: ls -lInput: Change directory to /tmp
Output: cd /tmpInput: Count files
Output: ls -l | wc -l...
好吧,就是這樣!沒(méi)有第二步。結(jié)果可能不是完美的第一天,但是你可以通過(guò)在更大的示例數(shù)據(jù)集上進(jìn)行訓(xùn)練,或者從用戶提供的人工反饋中學(xué)習(xí),來(lái)提高其性能。
OpenAI的研究將API設(shè)計(jì)得足夠靈活,以使機(jī)器學(xué)習(xí)團(tuán)隊(duì)的工作效率更高。同時(shí),它是如此簡(jiǎn)單,任何人都可以使用它。在后臺(tái),API運(yùn)行具有GPT-3系列權(quán)重的模型,這些模型在速度和吞吐量方面得到了改進(jìn),以使此類(lèi)應(yīng)用程序變得實(shí)用。
什么是GPT-3?
GPT-3是OpenAI的GPT-2的發(fā)展,它標(biāo)志著自然語(yǔ)言處理的新里程碑。GPT代表Generative Pretrained Transformer,它引用了2017年Google一項(xiàng)稱(chēng)為T(mén)ransformer的創(chuàng)新技術(shù)。其主要目的是弄清楚特定單詞在給定上下文中出現(xiàn)的可能性。在此基礎(chǔ)上,我們現(xiàn)在可以創(chuàng)建可完成文本,回答問(wèn)題,匯總文檔等的應(yīng)用程序。
自然語(yǔ)言Shell示例
在本節(jié)中,我們將使用python和幾行代碼對(duì)在序言中看到的自然語(yǔ)言shell進(jìn)行編碼。首先,python文件:
prompt = """
Input: Print the current directory
Output: pwd
Input: List files
Output: ls -l
Input: Change directory to /tmp
Output: cd /tmp
Input: Count files
Output: ls -l | wc -l
Input: Replace foo with bar in all python files
Output: sed -i .bak -- 's/foo/bar/g' *.py
Input: Push to master
Output: git push origin master
"""
template = """
Input: {}
Output:
"""
import os, click, openai
while True:
request = input(click.style('nlsh> ', 'red', bold=True))
prompt += template.format(request) result = openai.Completion.create( model='davinci', prompt=prompt, stop='/n', max_tokens=100, temperature=.0
) command = result.choices[0]['text']
prompt += command if click.confirm(f'>>> Run: {click.style(command, "blue")}', default=True):
os.system(command)在python腳本的開(kāi)頭,我們?yōu)锳PI提供了一些我們希望其執(zhí)行的示例。然后,我們創(chuàng)建一個(gè)完成任務(wù)并使用davinci模型。我們將max_tokens設(shè)置為100以具有足夠的緩沖區(qū),并且將溫度設(shè)置為0。將溫度設(shè)置為0是一個(gè)好習(xí)慣,只要我們遇到的問(wèn)題只有一個(gè)正確的答案。通常,溫度越高,模型具有的創(chuàng)意自由度就越高。
最后,我們執(zhí)行python nlsh.py來(lái)測(cè)試應(yīng)用程序。
> The Natural Language Shell
更多例子
與OpenAI緊密合作的組織已經(jīng)在使用OpenAI API。讓我們看看一些非常聰明的例子。
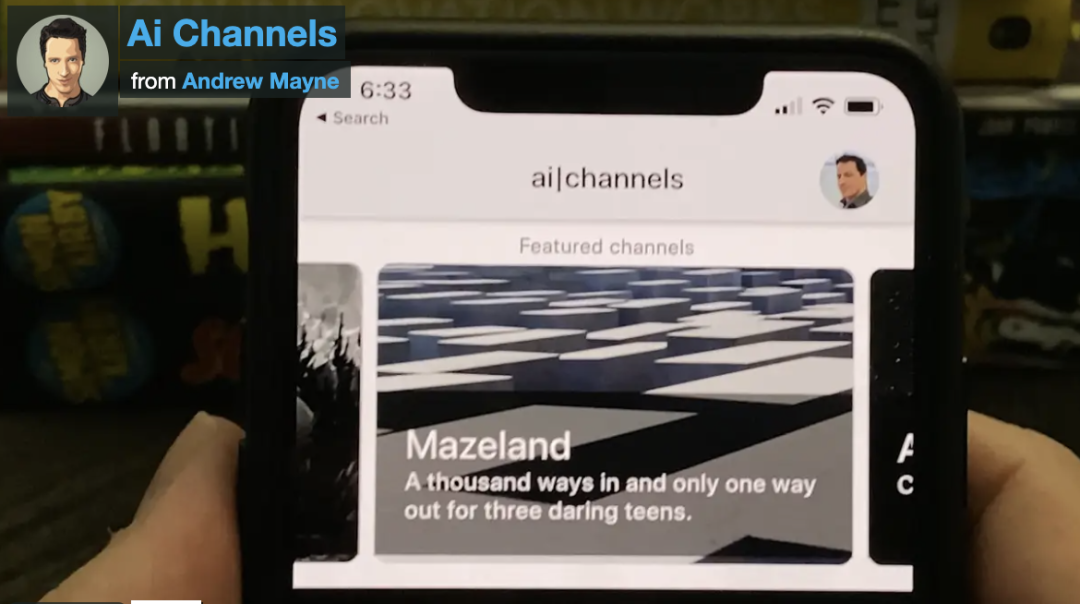
聊天室
AI Channels是一個(gè)面向人和人工智能代理的社交網(wǎng)絡(luò)。AI Channels使您可以與AI代理進(jìn)行交互,這些代理可以幫助您產(chǎn)生想法,推薦書(shū)籍和電影,講交互式故事或參加與朋友和歷史上最偉大的思想家的圓桌討論,在此您可以要求虛擬的Albert Einstein來(lái)解釋相對(duì)論 或從Jane Austen獲得寫(xiě)作技巧。
代碼補(bǔ)全
借助OpenAI API,我們可以生成有用的上下文感知代碼建議。在對(duì)來(lái)自數(shù)千個(gè)開(kāi)源GitHub存儲(chǔ)庫(kù)中的代碼進(jìn)行了微調(diào)之后,該API根據(jù)函數(shù)名稱(chēng)和注釋來(lái)完成代碼。
代碼摘要
通過(guò)其模式識(shí)別和生成功能,API可以將密集文本轉(zhuǎn)換為簡(jiǎn)化的摘要。在這里,我們展示了將NDA匯總為2級(jí)閱讀級(jí)別的內(nèi)容的API。
結(jié)論
在這個(gè)故事中,我們看到了OpenAI API的潛力和一些用例,這些用例重新定義了使用這種自然語(yǔ)言理解工具的可能性。語(yǔ)義搜索,客戶支持,聊天機(jī)器人,文本處理應(yīng)用程序和生產(chǎn)力工具將永遠(yuǎn)改變!
關(guān)于作者
我叫Dimitris Poulopoulos,我是BigDataStack的機(jī)器學(xué)習(xí)研究員。我也是希臘比雷埃夫斯大學(xué)的博士研究生。我曾為歐洲委員會(huì),歐盟統(tǒng)計(jì)局,IMF,歐洲中央銀行,經(jīng)合組織和宜家等主要客戶設(shè)計(jì)和實(shí)施AI和軟件解決方案。
如果您有興趣閱讀有關(guān)機(jī)器學(xué)習(xí),深度學(xué)習(xí),數(shù)據(jù)科學(xué)和DataOps的更多帖子,請(qǐng)?jiān)贛edium,LinkedIn或Twitter上@ james2pl上關(guān)注我。
