
最新數(shù)據(jù)挖掘競賽解決方案梳理!
賽題介紹
科大訊飛:糖尿病遺傳風(fēng)險(xiǎn)檢測挑戰(zhàn)賽。背景:截至2022年,中國糖尿病患者近1.3億。中國糖尿病患病原因受生活方式、老齡化、城市化、家族遺傳等多種因素影響。同時(shí),糖尿病患者趨向年輕化。
糖尿病可導(dǎo)致心血管、腎臟、腦血管并發(fā)癥的發(fā)生。因此,準(zhǔn)確診斷出患有糖尿病個(gè)體具有非常重要的臨床意義。糖尿病早期遺傳風(fēng)險(xiǎn)預(yù)測將有助于預(yù)防糖尿病的發(fā)生。
賽事地址:http://challenge.xfyun.cn/topic/info?type=diabetes&ch=ds22-dw-gzh01
源代碼:https://github.com/datawhalechina/competition-baseline
賽題任務(wù)
在這次比賽中,您需要通過訓(xùn)練數(shù)據(jù)集構(gòu)建糖尿病遺傳風(fēng)險(xiǎn)預(yù)測模型,然后預(yù)測出測試數(shù)據(jù)集中個(gè)體是否患有糖尿病,和我們一起幫助糖尿病患者解決這“甜蜜的煩惱”。
賽題數(shù)據(jù)
賽題數(shù)據(jù)由訓(xùn)練集和測試集組成,具體情況如下:
訓(xùn)練集:共有5070條數(shù)據(jù),用于構(gòu)建您的預(yù)測模型 測試集:共有1000條數(shù)據(jù),用于驗(yàn)證預(yù)測模型的性能。
其中訓(xùn)練集數(shù)據(jù)包含有9個(gè)字段:性別、出生年份、體重指數(shù)、糖尿病家族史、舒張壓、口服耐糖量測試、胰島素釋放實(shí)驗(yàn)、肱三頭肌皮褶厚度、患有糖尿病標(biāo)識(shí)(數(shù)據(jù)標(biāo)簽)。
評(píng)分標(biāo)準(zhǔn)
采用二分類任務(wù)中的F1-score指標(biāo)進(jìn)行評(píng)價(jià),F(xiàn)1-score越大說明預(yù)測模型性能越好,F(xiàn)1-score的定義如下:
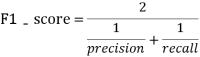
其中:


賽題Baseline
導(dǎo)入數(shù)據(jù)
import pandas as pd
import lightgbm
數(shù)據(jù)預(yù)處理
data1=pd.read_csv('比賽訓(xùn)練集.csv',encoding='gbk')
data2=pd.read_csv('比賽測試集.csv',encoding='gbk')
#label標(biāo)記為-1
data2['患有糖尿病標(biāo)識(shí)']=-1
#訓(xùn)練集和測試機(jī)合并
data=pd.concat([data1,data2],axis=0,ignore_index=True)
#特征工程
"""
人體的成人體重指數(shù)正常值是在18.5-24之間
低于18.5是體重指數(shù)過輕
在24-27之間是體重超重
27以上考慮是肥胖
高于32了就是非常的肥胖。
"""
def BMI(a):
if a<18.5:
return 0
elif 18.5<=a<=24:
return 1
elif 24<a<=27:
return 2
elif 27<a<=32:
return 3
else:
return 4
data['BMI']=data['體重指數(shù)'].apply(BMI)
data['出生年份']=2022-data['出生年份'] #換成年齡
#糖尿病家族史
"""
無記錄
叔叔或者姑姑有一方患有糖尿病/叔叔或姑姑有一方患有糖尿病
父母有一方患有糖尿病
"""
def FHOD(a):
if a=='無記錄':
return 0
elif a=='叔叔或者姑姑有一方患有糖尿病' or a=='叔叔或姑姑有一方患有糖尿病':
return 1
else:
return 2
data['糖尿病家族史']=data['糖尿病家族史'].apply(FHOD)
data['舒張壓']=data['舒張壓'].fillna(-1)
"""
舒張壓范圍為60-90
"""
def DBP(a):
if a<60:
return 0
elif 60<=a<=90:
return 1
elif a>90:
return 2
else:
return a
data['DBP']=data['舒張壓'].apply(DBP)
data
訓(xùn)練數(shù)據(jù)/測試數(shù)據(jù)準(zhǔn)備
train=data[data['患有糖尿病標(biāo)識(shí)'] !=-1]
test=data[data['患有糖尿病標(biāo)識(shí)'] ==-1]
train_label=train['患有糖尿病標(biāo)識(shí)']
train=train.drop(['編號(hào)','患有糖尿病標(biāo)識(shí)'],axis=1)
test=test.drop(['編號(hào)','患有糖尿病標(biāo)識(shí)'],axis=1)
構(gòu)建模型
def select_by_lgb(train_data,train_label,test_data,random_state=2022,metric='auc',num_round=300):
clf=lightgbm
train_matrix=clf.Dataset(train_data,label=train_label)
params={
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': metric,
'seed': 2020,
'nthread':-1 }
model=clf.train(params,train_matrix,num_round)
pre_y=model.predict(test_data)
return pre_y
模型驗(yàn)證
test_data=select_by_lgb(train,train_label,test)
pre_y=pd.DataFrame(test_data)
pre_y['label']=pre_y[0].apply(lambda x:1 if x>0.5 else 0)
result=pd.read_csv('提交示例.csv')
result['label']=pre_y['label']
result.to_csv('baseline.csv',index=False)
上分建議
整理不易,點(diǎn)贊三連↓