
BERT meet KG第二彈:新訓(xùn)練方式,新問題視角
作者簡介:周昆?@Francis Lancelot,中國人民大學(xué)博士,導(dǎo)師為文繼榮教授和趙鑫教授,研究方向是預(yù)訓(xùn)練模型和會話推薦系統(tǒng)。
引言:在上一篇文章中,F(xiàn)rancis Lancelot:BERT meet Knowledge Graph:預(yù)訓(xùn)練模型與知識圖譜相結(jié)合的研究進(jìn)展,我survey了已有的嘗試在BERT中加入知識圖譜的8篇相關(guān)工作。由于該方向的迅速發(fā)展,這半年的時間里又浮現(xiàn)了一大批相關(guān)的研究工作。他們引入了更新的模型結(jié)構(gòu)和訓(xùn)練方法,也有新的視角,這篇我將對其中有代表性的7篇進(jìn)行分析,歡迎大家批評和交流。
1.Coarse-to-Fine Pre-training for Named Entity Recognition
這篇論文是中科院的柳廳文老師和西湖大學(xué)的張?jiān)览蠋熞黄鸢l(fā)表于EMNLP2020上的一篇文章,其考慮一種特殊的預(yù)訓(xùn)練方式來得到專用于NER(命名實(shí)體識別)的預(yù)訓(xùn)練模型。
https://arxiv.org/abs/2010.08210arxiv.org
這篇論文考慮一種coarse-to-fine的預(yù)訓(xùn)練方式,即學(xué)習(xí)的知識粒度由粗到細(xì)。這篇文章沿用了前人的基于閱讀理解中span預(yù)測的NER框架,然后提出了三步走的策略。第一步,利用維基百科給出的錨點(diǎn)來識別出若干實(shí)體,并訓(xùn)練模型區(qū)別實(shí)體詞和非實(shí)體詞;第二步,利用每個實(shí)體對應(yīng)的類型,訓(xùn)練一個實(shí)體類型匹配模型,來幫助模型學(xué)習(xí)如何初步確定實(shí)體的類別;第三步,對于每個類別下的實(shí)體,模型將其對應(yīng)的表示進(jìn)行聚類,從而得到更加細(xì)粒度的類別標(biāo)簽,并給予模型來學(xué)習(xí)。該流程圖如下所示,且最終得到的模型還需要在NER任務(wù)上進(jìn)行fine-tune:
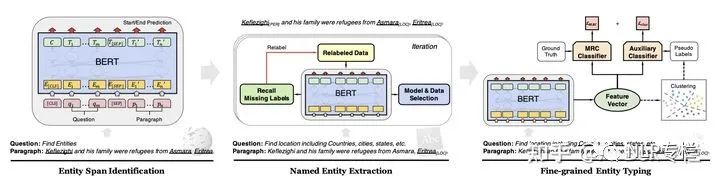
以上coarse-to-fine的訓(xùn)練方式使得模型能夠逐步的獲取NER任務(wù)相關(guān)的信息,并逐步的更新模型參數(shù),使其能夠取得比直接訓(xùn)練更適合于NER的表示。這篇論文采用的訓(xùn)練方式較其他論文更加novel,值得參考。
2.LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
這篇論文來自于日本和華盛頓大學(xué)的研究機(jī)構(gòu),并發(fā)表于EMNLP2020。其也關(guān)注于如何更充分利用實(shí)體信息以增強(qiáng)預(yù)訓(xùn)練語言模型。
https://www.aclweb.org/anthology/2020.emnlp-main.523.pdfwww.aclweb.org
這篇論文認(rèn)為現(xiàn)有的預(yù)訓(xùn)練模型的一個瓶頸在于模型并未區(qū)別考慮實(shí)體和普通單詞。為解決該問題,本文提出了一個在標(biāo)注entity的大規(guī)模語料庫上預(yù)訓(xùn)練的Transformer模型,通過一個entity-aware的自注意力機(jī)制和針對entity的預(yù)訓(xùn)練任務(wù),以增強(qiáng)該部分entity信息,其模型結(jié)構(gòu)如下圖所示:
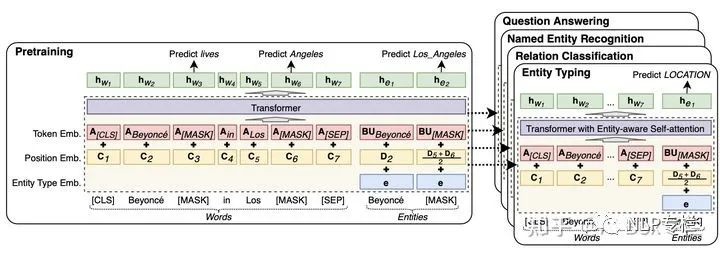
從圖中可以看出,該模型在embedding層添加了一個entity type embedding layer,其通過直接指出word與entity來增強(qiáng)模型對其的理解。不同于傳統(tǒng)的Transformer層,本文在entity-aware層區(qū)別word與entity,分別采用不同的矩陣變換以計(jì)算其對應(yīng)的attention權(quán)重,該方法簡單明確的增強(qiáng)了這兩種信息的建模。此外,本文還采用MLM的改進(jìn)版本,即針對entity的mask與還原。該模型在多個知識相關(guān)任務(wù)和QA任務(wù)上均取得了SOTA的效果。
3.Entity Enhanced BERT Pre-training for Chinese NER
這篇論文是由西湖大學(xué)的張?jiān)览蠋煱l(fā)表于EMNLP2020。其關(guān)注于如何更充分利用實(shí)體信息以增強(qiáng)預(yù)訓(xùn)練語言模型在中文NER上的表現(xiàn)。
https://www.aclweb.org/anthology/2020.emnlp-main.518.pdfwww.aclweb.org
中文NER任務(wù)相比較于其他任務(wù)來說,lexicon知識能夠在其上取得較大的增益。該部分信息在真實(shí)世界中容易獲取,且已經(jīng)在很多模型中展示其優(yōu)勢。但是在預(yù)訓(xùn)練模型上還未有人進(jìn)行過嘗試。這篇論文首先采用一個新詞發(fā)現(xiàn)策略來識別文檔中的entity,其基于互信息以識別文檔中的實(shí)體;然后采用特殊的cahr-entity自注意力機(jī)制來捕捉中文字與實(shí)體之間的關(guān)系,最終采用特殊的任務(wù)來進(jìn)行模型預(yù)訓(xùn)練。其結(jié)構(gòu)如下圖所示:
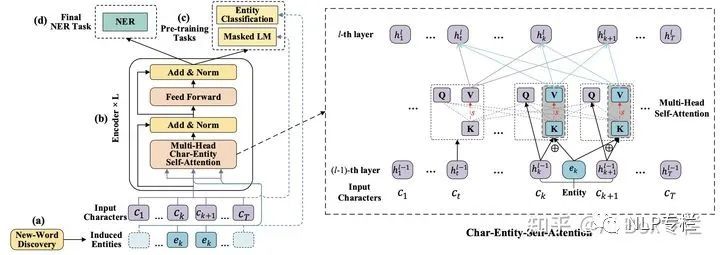
由圖中可以看出,由于文檔中的若干char可能會屬于同一個entity,本文將其一起輸入給自注意力層。通過改變char和entity作為自注意力層的QKV輸入方式,以實(shí)現(xiàn)將entity信息融入到Transformer層中。其中對于有對應(yīng)entity的char,其表示變成原始的char和entity表示的加權(quán)求和。此外,為訓(xùn)練以上模型,本文除MLM以外,還采用一個實(shí)體分類任務(wù),即識別當(dāng)前char屬于哪一個實(shí)體,以此將char和entity映射到同一個空間。本文的模型在NER任務(wù)fine-tune后,取得了在多個中文NER數(shù)據(jù)集上的SOTA效果。
4.Pre-training Entity Relation Encoder with Intra-span and Inter-span Information
這篇論文是由上交的嚴(yán)駿馳老師與華東師范大學(xué),平安科技發(fā)表于EMNLP2020。其關(guān)注于對Span-level信息的建模,并對entity和relation這部分信息以加強(qiáng)。
https://www.aclweb.org/anthology/2020.emnlp-main.132.pdfwww.aclweb.org
在傳統(tǒng)的BERT的Transformer層的基礎(chǔ)上,這篇論文引入了一個Span Encoder來對句子中的entity和relation進(jìn)行建模,其采用一個基于CNN+maxpooling的方法,在BERT得到的表示的基礎(chǔ)上進(jìn)行建模。之后本文提出了三種特殊的預(yù)訓(xùn)練策略,分別從token-level,span-level和span pair level進(jìn)行建模。如下圖所示:
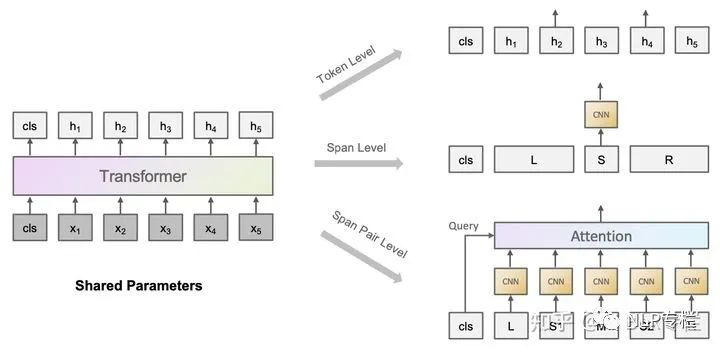
其中token-level的訓(xùn)練目標(biāo)關(guān)注于將一個token包含的多個sub-token中除first sub-token均進(jìn)行mask,然后利用這個first sub-token以還原整個token。而span-level的目標(biāo)則關(guān)注于首先對一個span內(nèi)部的token進(jìn)行shuffle,然后由模型識別這些token屬于哪一種shuffle后的順序類型。span pair level則考慮對給出的一個句子,首先挖去其中的部分span,然后將殘缺的句子和僅包含該span的句子互相進(jìn)行匹配,采用對比學(xué)習(xí)的損失函數(shù)進(jìn)行訓(xùn)練。以上三個預(yù)訓(xùn)練任務(wù)使得模型可以學(xué)習(xí)到許多span相關(guān)的信息,進(jìn)而提升對entity/relation的理解。
5.ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning
這篇論文是由清華的黃民烈老師與微信合作的論文。其關(guān)注于利用對比學(xué)習(xí)技術(shù)對實(shí)體和關(guān)系信息進(jìn)行增強(qiáng),以提升預(yù)訓(xùn)練模型表現(xiàn)。
https://arxiv.org/pdf/2012.15022.pdfarxiv.org
這篇文章認(rèn)為以后的知識驅(qū)動的預(yù)訓(xùn)練語言模型過于關(guān)注于對Entity和Relation單獨(dú)的建模,并未考慮兩者之間的復(fù)雜交互,故而無法較好的理解文本中真正的知識信息。為解決這一問題,本文提出兩個基于對比學(xué)習(xí)的任務(wù),即Entity Discrimination和Relation Discrimination。如下圖所示:
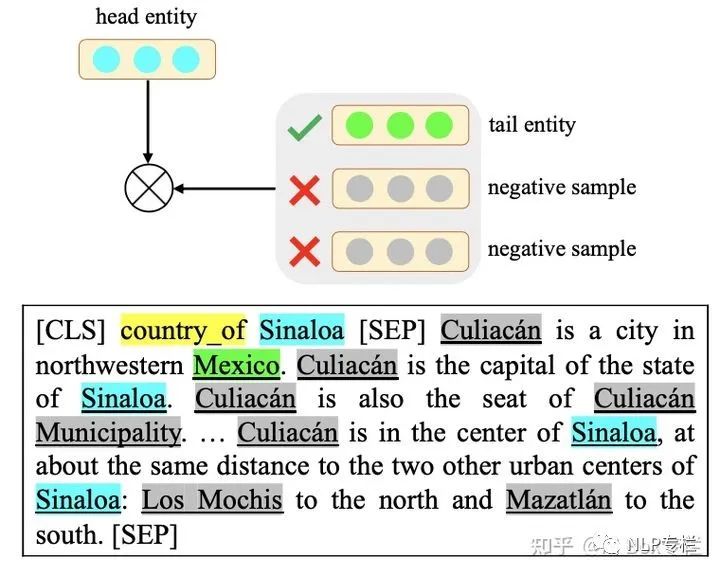
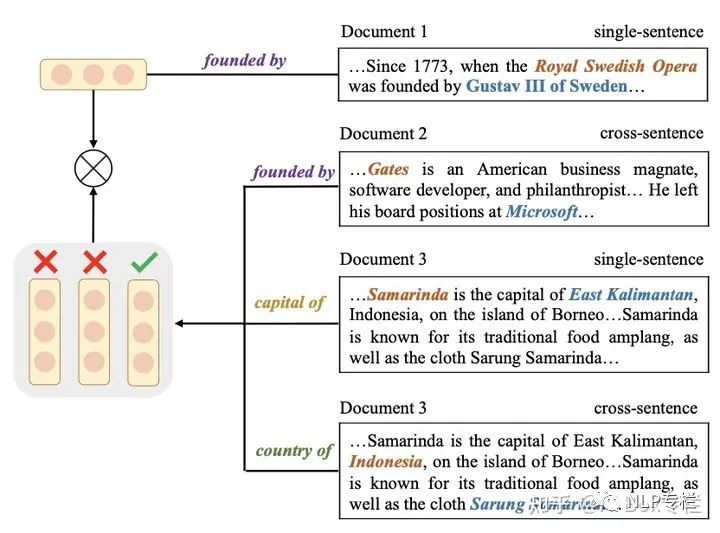
對于entity discrimination任務(wù),模型將頭實(shí)體和關(guān)系拼接到一起,并和包含尾實(shí)體的文檔相拼接,以輸入給BERT。對于這個輸入,尾實(shí)體作為正例,而文檔中的其他實(shí)體則作為負(fù)例,可以進(jìn)行對比學(xué)習(xí)。對于relation discrimination任務(wù),模型考慮不同文檔中相同relation對應(yīng)的entity直接的關(guān)系,這里我們把包含同樣relation的triple所在的兩個文檔作為正例,而不同relation的作為負(fù)例,也采用對比學(xué)習(xí)進(jìn)行訓(xùn)練。最終本文采用一個多任務(wù)學(xué)習(xí)的框架,加入MLM來進(jìn)一步增強(qiáng)整個模型的效果。該方法在許多文檔理解任務(wù)上均取得了很好的效果。
6.KgPLM: Knowledge-guided Language Model Pre-training via Generative and Discriminative Learning
這篇論文是由華為諾亞方舟實(shí)驗(yàn)室發(fā)表的論文。其關(guān)注于結(jié)合已有的生成式和判別式的預(yù)訓(xùn)練任務(wù),以得到更好的知識引導(dǎo)的語言模型。
https://arxiv.org/pdf/2012.03551v1.pdfarxiv.org
這篇文章關(guān)注于如何訓(xùn)練更好的知識引導(dǎo)的預(yù)訓(xùn)練語言模型,其考慮知識補(bǔ)全任務(wù)和知識驗(yàn)證任務(wù)。其具體實(shí)現(xiàn)則是一個生成式模型和一個判別性模型。其中生成式模型基于MLM來對被mask的一段進(jìn)行補(bǔ)全;判別性模型則基于一個二分類模型判斷其中是否有部分被替換成錯誤的token。如下圖所示:

除此之外,這篇文章還考慮了將這兩個任務(wù)做成pipeline還是雙塔模型的形式,實(shí)驗(yàn)表明這兩種方式各有優(yōu)劣,且在許多QA任務(wù)上均有提升。
7.LANGUAGE MODELS ARE OPEN KNOWLEDGE GRAPHS
這篇論文是由清華大學(xué)和UCB投稿于ICLR的論文。其從一個非常新穎的角度,即能否利用預(yù)訓(xùn)練模型來構(gòu)造知識圖譜。
https://arxiv.org/pdf/2010.11967.pdfarxiv.org
這篇論文認(rèn)為預(yù)訓(xùn)練語言模型本身就擁有許多知識信息,可以直接將這部分信息抽取出來構(gòu)成新的知識圖譜并用于各類下游任務(wù)。這篇論文使用預(yù)訓(xùn)練模型中的attention機(jī)制來進(jìn)行知識的搜索,其設(shè)置了start,yield和stop這幾個action,以實(shí)現(xiàn)從文本中識別對應(yīng)的candidate fact,如下圖所示:
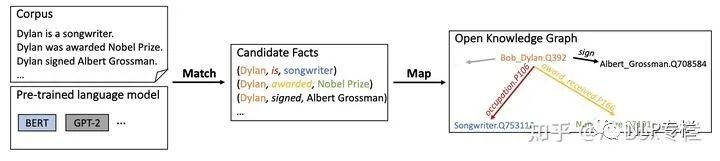
基于圖中的策略,模型基于beam search選擇得分最高的結(jié)果作為candidate fact;然后采用一系列預(yù)定義的過濾機(jī)制以去除噪聲。之后,這篇文章將這些candidate中的entity和relation匹配到已有的KG中;同時對部分無法匹配的entity和relation進(jìn)行保留,最終得到整個知識圖譜。本文還對比了得到的知識圖譜相比較于其他知識圖譜的優(yōu)劣,并對其進(jìn)行相關(guān)分析。這篇論文提出了很有趣的角度,可以供大家繼續(xù)挖掘。