
視覺Transformer BERT預訓練新方式:中科大、MSRA等提出PeCo,優(yōu)于MAE、BEiT
點擊“凹凸域”,馬上關注
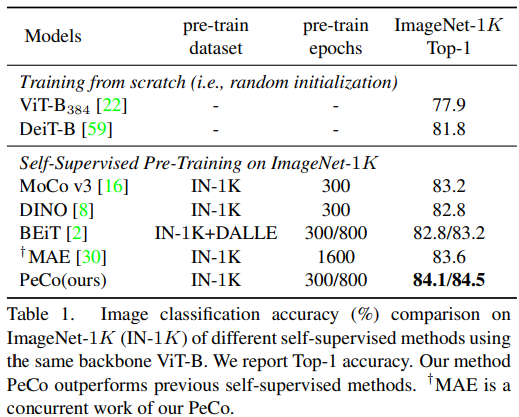
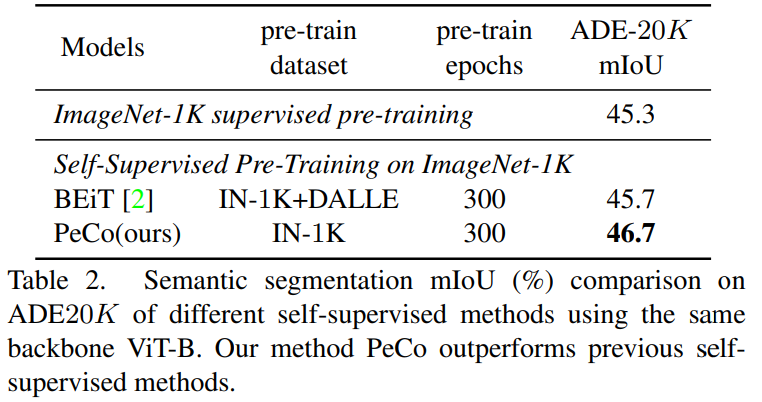
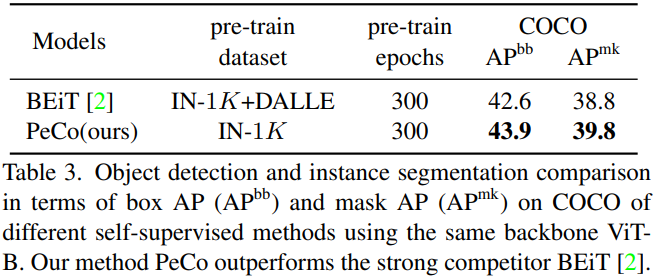
來自中國科學技術大學、微軟亞研等機構的研究者提出了 PeCo,用于視覺 transformer 的 BERT 預訓練,在多項任務上實現(xiàn)最高性能。

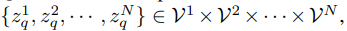 其中,VQ-VAE 包含三個主要部分:編碼器、量化器和解碼器。編碼器負責將輸入圖像映射到中間潛在向量 z = Enc(x);量化器根據(jù)最近鄰分配原則負責將位置 (i, j) 處的向量量化為來自 Codebook 對應的碼字(codewords):
其中,VQ-VAE 包含三個主要部分:編碼器、量化器和解碼器。編碼器負責將輸入圖像映射到中間潛在向量 z = Enc(x);量化器根據(jù)最近鄰分配原則負責將位置 (i, j) 處的向量量化為來自 Codebook 對應的碼字(codewords):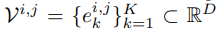

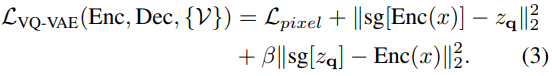

 的感知度量可以表示為:
的感知度量可以表示為: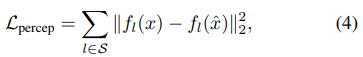

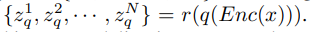 。 掩碼圖像建模的目標是從掩碼輸入中恢復相應的視覺 token,其中一部分輸入 token 已被掩碼掉。準確地說,令 M 為掩碼索引集合,掩碼輸入
。 掩碼圖像建模的目標是從掩碼輸入中恢復相應的視覺 token,其中一部分輸入 token 已被掩碼掉。準確地說,令 M 為掩碼索引集合,掩碼輸入 表示為:
表示為:




點擊“凹凸域”,馬上關注
請點擊上方卡片,專注計算機人工智能方向的研究
評論
圖片
表情