
Redis中ZSet的底層數(shù)據(jù)結(jié)構(gòu)跳躍表skiplist,你真的了解嗎?

點(diǎn)擊上方老周聊架構(gòu)關(guān)注我
一、前言
老周寫這篇文章的初衷是這樣的,之前項(xiàng)目中有大量使用 Redis 的 ZSet 數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn)各種排行榜的功能。老周以前也寫過關(guān)于跳表的數(shù)據(jù)結(jié)構(gòu),但那是純數(shù)據(jù)結(jié)構(gòu)方面來分析的,今天我們就來從跳躍表在 Redis 中的底層實(shí)現(xiàn)方向來分析。我們都知道 Redis 有五種常用的數(shù)據(jù)結(jié)構(gòu):String、Hash、List、Set 以及 ZSet,其中 ZSet 是 Redis 提供的一個(gè)非常特別的數(shù)據(jù)結(jié)構(gòu),常用作排行榜等功能,以用戶 id 為 value,關(guān)注時(shí)間或者分?jǐn)?shù)作為 score 進(jìn)行排序。
ZSet 有兩種不同的實(shí)現(xiàn),分別是 ziplist 和 skiplist。具體使用哪種結(jié)構(gòu)進(jìn)行存儲(chǔ),規(guī)則如下:
ziplist:滿足以下兩個(gè)條件[value,score] 鍵值對(duì)數(shù)量少于 128 個(gè)
每個(gè)元素的長度小于 64 字節(jié)
skiplist:不滿足以上兩個(gè)條件時(shí)使用跳表、組合了 hash 和 skiplisthash 用來存儲(chǔ) value 到 score 的映射,這樣就可以在 O(1) 時(shí)間內(nèi)找到 value 對(duì)應(yīng)的分?jǐn)?shù)
skiplist 按照從小到大的順序存儲(chǔ)分?jǐn)?shù)
skiplist 每個(gè)元素的值都是 [value,score] 對(duì)
使用 ziplist 的示意圖如下所示:

使用跳表時(shí)的示意圖:

ziplist 壓縮列表本文不是重點(diǎn)討論范圍,我們著重來看下跳躍表 skiplist。
二、什么是跳躍表(skiplist)
跳躍表(skiplist)是一種有序數(shù)據(jù)結(jié)構(gòu),它通過在每個(gè)節(jié)點(diǎn)中維持多個(gè)指向其它節(jié)點(diǎn)的指針,從而達(dá)到快速訪問節(jié)點(diǎn)的目的。和鏈表、字典等數(shù)據(jù)結(jié)構(gòu)被廣泛地應(yīng)用在 Redis 內(nèi)部不同,Redis 只在兩個(gè)地方用到了跳躍表,一個(gè)是實(shí)現(xiàn)有序集合健,另一個(gè)是在集群節(jié)點(diǎn)中用做內(nèi)部數(shù)據(jù)結(jié)構(gòu),除此之外,跳躍表在 Redis 里沒有其它用途。
我們來想一下,為啥 Redis 中這兩個(gè)場景要選擇 skiplist?
既然跳躍表是一種有序數(shù)據(jù)結(jié)構(gòu),那我們就來考慮在有序序列中查找某個(gè)特定元素的情境:
如果該序列用支持隨機(jī)訪問的線性結(jié)構(gòu)(數(shù)組)存儲(chǔ),那么我們很容易地用二分查找來做。
但是考慮到增刪效率和內(nèi)存擴(kuò)展性,很多時(shí)候要用不支持隨機(jī)訪問的線性結(jié)構(gòu)(鏈表)存儲(chǔ),就只能從頭遍歷、逐個(gè)比對(duì)。
作為折衷,如果用二叉樹結(jié)構(gòu)(BST)存儲(chǔ),就可以不靠隨機(jī)訪問特性進(jìn)行二分查找了。
我們知道,普通 BST 插入元素越有序效率越低,最壞情況會(huì)退化回鏈表。因此很多大佬提出了自平衡 BST 結(jié)構(gòu),使其在任何情況下的增刪查操作都保持 O(logn) 的時(shí)間復(fù)雜度。自平衡 BST 的代表就是 AVL 樹及其衍生出來的紅黑樹。如果推廣之,不限于二叉樹的話,我們耳熟能詳?shù)?B 樹和 B+ 樹也屬此類,常用于文件系統(tǒng)和數(shù)據(jù)庫。
自平衡BST顯然很香,但是它仍然有一個(gè)不那么香的點(diǎn):樹的自平衡過程比較復(fù)雜,實(shí)現(xiàn)起來麻煩,在高并發(fā)的情況下,加鎖也會(huì)帶來可觀的overhead。如AVL樹需要LL、LR、RL、RR四種旋轉(zhuǎn)操作保持平衡,紅黑樹則需要左旋、右旋和節(jié)點(diǎn)變色三種操作。下面的動(dòng)圖展示的就是AVL樹在插入元素時(shí)的平衡過程。

那么,有沒有簡單點(diǎn)的、與自平衡 BST 效率相近的實(shí)現(xiàn)方法呢?答案就是跳躍表,并且它簡單很多,下面我們就來看一看。
三、如何理解跳躍表
對(duì)于一個(gè)單鏈表來講,即便鏈表中存儲(chǔ)的數(shù)據(jù)是有序的,如果我們要想在其中查找某個(gè)數(shù)據(jù),也只能從頭到尾遍歷鏈表。這樣查找效率就會(huì)很低,時(shí)間復(fù)雜度會(huì)很高,是 O(n)。

那怎么來提高查找效率呢?請(qǐng)看我下面畫的圖,在該鏈表中,每隔一個(gè)節(jié)點(diǎn)就有一個(gè)附加的指向它在表中前兩個(gè)位置上的節(jié)點(diǎn)的鏈,正因?yàn)槿绱耍谧顗牡那樾蜗拢疃嗫疾?n/2 + 1 個(gè)節(jié)點(diǎn)。比如我們要查 90 這個(gè)節(jié)點(diǎn),按照之前單鏈表的查找的話要 8 個(gè)節(jié)點(diǎn),現(xiàn)在只需 5 個(gè)節(jié)點(diǎn)。

我們來將這種想法擴(kuò)展一下,得到下面的圖,這里每隔 4 個(gè)節(jié)點(diǎn)就有一個(gè)鏈接到該節(jié)點(diǎn)前方的下一個(gè)第 4 節(jié)點(diǎn)的鏈,只有 n/4 + 1 個(gè)節(jié)點(diǎn)被考察。

這里我們利用數(shù)學(xué)的思想,針對(duì)通用性做擴(kuò)展。每隔第 2^i 個(gè)節(jié)點(diǎn)就有一個(gè)鏈接到這個(gè)節(jié)點(diǎn)前方下一個(gè)第 2^i 個(gè)節(jié)點(diǎn)鏈。鏈的總個(gè)數(shù)僅僅是加倍,但現(xiàn)在在一次查找中最多只考察 logn 個(gè)節(jié)點(diǎn)。不難看到一次查找的總時(shí)間消耗為 O(logn),這是因?yàn)椴檎矣上蚯暗揭粋€(gè)新的節(jié)點(diǎn)或者在同一節(jié)點(diǎn)下降到低一級(jí)的鏈組成。在一次查找期間每一步總的時(shí)間消耗最多為 O(logn)。注意,在這種數(shù)據(jù)結(jié)構(gòu)中的查找基本上是折半查找(Binary Search)。
我只舉了兩個(gè)例子,這里你可以自己想象下大量數(shù)據(jù)也就是鏈表長度為 n 的時(shí)候,查找的效率更加的凸顯出來了。
這種鏈表加多級(jí)索引的的結(jié)構(gòu),就是跳躍表。接下來我們來定量的分析下,用跳表查詢到底有多快。
四、跳躍表的時(shí)間復(fù)雜度分析
我們知道,在一個(gè)單鏈表中查詢某個(gè)數(shù)據(jù)的時(shí)間復(fù)雜度是 O(n)。那在一個(gè)具有多級(jí)索引的跳表中,查詢某個(gè)數(shù)據(jù)的時(shí)間復(fù)雜度是多少呢?
我把問題分解一下,先來看這樣一個(gè)問題,如果鏈表里有 n 個(gè)結(jié)點(diǎn),會(huì)有多少級(jí)索引呢?
按照我們上面講的,第一級(jí)索引的鏈節(jié)點(diǎn)個(gè)數(shù)大約就是 n/2 個(gè),第二級(jí)索引的鏈節(jié)點(diǎn)個(gè)數(shù)大約就是 n/4 個(gè),第三級(jí)索引的鏈節(jié)點(diǎn)個(gè)數(shù)大約就是 n/8 個(gè),依次類推,也就是說,第 k 級(jí)索引的鏈節(jié)點(diǎn)個(gè)數(shù)是第 k-1 級(jí)索引的鏈節(jié)點(diǎn)個(gè)數(shù)的 1/2,那第 k 級(jí)索引節(jié)點(diǎn)的個(gè)數(shù)就是 n/(2k)。
假設(shè)索引有 h 級(jí),最高級(jí)的索引有 2 個(gè)節(jié)點(diǎn)。通過上面的公式,我們可以得到 n/(2h)=2,從而求得 h=log2n-1。如果包含原始鏈表這一層,整個(gè)跳表的高度就是 log2n。我們?cè)谔碇胁樵兡硞€(gè)數(shù)據(jù)的時(shí)候,如果每一層都要遍歷 m 個(gè)節(jié)點(diǎn),那在跳表中查詢一個(gè)數(shù)據(jù)的時(shí)間復(fù)雜度就是 O(m*logn)。
那這個(gè) m 的值是多少呢?按照前面這種索引結(jié)構(gòu),我們每一級(jí)索引都最多只需要遍歷 3 個(gè)結(jié)點(diǎn),也就是說 m=3,為什么是 3 呢?我來解釋一下。
假設(shè)我們要查找的數(shù)據(jù)是 x,在第 k 級(jí)索引中,我們遍歷到 y節(jié)點(diǎn)之后,發(fā)現(xiàn) x 大于 y,小于后面的節(jié)點(diǎn) z,所以我們通過 y 的 down 指針,從第 k 級(jí)索引下降到第 k-1 級(jí)索引。在第 k-1 級(jí)索引中,y 和 z 之間只有 3 個(gè)節(jié)點(diǎn)(包含 y 和 z),所以,我們?cè)?k-1 級(jí)索引中最多只需要遍歷 3 個(gè)結(jié)點(diǎn),依次類推,每一級(jí)索引都最多只需要遍歷 3 個(gè)節(jié)點(diǎn)。

通過上面的分析,我們得到 m=3,所以在跳躍表中查詢?nèi)我鈹?shù)據(jù)的時(shí)間復(fù)雜度就是 O(logn)。這個(gè)查找的時(shí)間復(fù)雜度跟二分查找是一樣的。換句話說,我們其實(shí)是基于單鏈表實(shí)現(xiàn)了二分查找,前提是建立了很多級(jí)索引,也就是我們講過的空間換時(shí)間的設(shè)計(jì)思路。
我們的時(shí)間復(fù)雜度很優(yōu)秀,那跳躍表的空間復(fù)雜度是多少呢?
實(shí)際上,在軟件開發(fā)中,我們不必太在意索引占用的額外空間。在講數(shù)據(jù)結(jié)構(gòu)和算法時(shí),我們習(xí)慣性地把要處理的數(shù)據(jù)看成整數(shù),但是在實(shí)際的軟件開發(fā)中,原始鏈表中存儲(chǔ)的有可能是很大的對(duì)象,而索引結(jié)點(diǎn)只需要存儲(chǔ)關(guān)鍵值和幾個(gè)指針,并不需要存儲(chǔ)對(duì)象,所以當(dāng)對(duì)象比索引結(jié)點(diǎn)大很多時(shí),那索引占用的額外空間就可以忽略了。
五、跳躍表的底層結(jié)構(gòu)
Redis 的跳躍表是由 redis.h/zskiplistNode 和 redis.h/zskiplist 兩個(gè)結(jié)構(gòu)定義,其中 zskiplistNode 用于表示跳躍節(jié)點(diǎn),而 zskiplist 結(jié)構(gòu)則用于保存跳躍表節(jié)點(diǎn)的相關(guān)信息,比如節(jié)點(diǎn)的數(shù)量以及指向表頭節(jié)點(diǎn)和表尾節(jié)點(diǎn)的指針等等。

上圖最左邊的是 zskiplist 結(jié)構(gòu),該結(jié)構(gòu)包含以下屬性:
header:指向跳躍表的表頭節(jié)點(diǎn)
tail:指向跳躍表的表尾節(jié)點(diǎn)
level:記錄目前跳躍表內(nèi),層數(shù)最大的那個(gè)節(jié)點(diǎn)層數(shù)(表頭節(jié)點(diǎn)的層數(shù)不計(jì)算在內(nèi))
length:記錄跳躍表的長度,也就是跳躍表目前包含節(jié)點(diǎn)的數(shù)量(表頭節(jié)點(diǎn)不計(jì)算在內(nèi))
位于 zskiplist 結(jié)構(gòu)右側(cè)是四個(gè) zskiplistNode 結(jié)構(gòu),該結(jié)構(gòu)包含以下屬性:
層(level):節(jié)點(diǎn)中用 L1、L2、L3 等字樣標(biāo)記節(jié)點(diǎn)的各個(gè)層,L1 代表第一層,L2 代表第二層,以此類推。每個(gè)層都帶有兩個(gè)屬性:前進(jìn)指針和跨度。前進(jìn)指針用于訪問位于表尾方向的其它節(jié)點(diǎn),而跨度則記錄了前進(jìn)指針?biāo)赶蚬?jié)點(diǎn)和當(dāng)前節(jié)點(diǎn)的距離。
后退(backward)指針:節(jié)點(diǎn)中用 BW 字樣標(biāo)識(shí)節(jié)點(diǎn)的后退指針,它指向位于當(dāng)前節(jié)點(diǎn)的前一個(gè)節(jié)點(diǎn)。后退指針在程序從表尾向表頭遍歷時(shí)使用。
分值(score):各個(gè)節(jié)點(diǎn)中的 1.0、2.0 和 3.0 是節(jié)點(diǎn)所保存的分值。在跳躍表中,節(jié)點(diǎn)按各自所保存的分值從小到大排列。
成員對(duì)象(obj):各個(gè)節(jié)點(diǎn)中的 o1、o2 和 o3 是節(jié)點(diǎn)所保存的成員對(duì)象。
我們接下來看下 Redis 是如何實(shí)現(xiàn) skiplist 的。
5.1 結(jié)構(gòu)定義
zskiplist 的結(jié)構(gòu)定義:

zskiplistNode 的結(jié)構(gòu)定義:

5.2 skiplist 創(chuàng)建

這里需要注意的是常量 ZSKIPLIST_MAXLEVEL,它定義了 zskiplist 的最大層數(shù),值為 32,這也是節(jié)點(diǎn)最高只到 L32 的原因。
5.3 skiplist 插入節(jié)點(diǎn)

其大致執(zhí)行流程如下:
按照前面講過的查找流程,找到合適的插入位置。注意 zset 允許分?jǐn)?shù) score 相同,這時(shí)會(huì)根據(jù)節(jié)點(diǎn)數(shù)據(jù) obj 的字典序來排序。
調(diào)用 zslRandomLevel() 方法,隨機(jī)出要插入的節(jié)點(diǎn)的層數(shù)。
調(diào)用 zslCreateNode() 方法,根據(jù)層數(shù) level、分?jǐn)?shù) score 和數(shù)據(jù) obj 創(chuàng)建出新節(jié)點(diǎn)。
每層遍歷,修改新節(jié)點(diǎn)以及其前后節(jié)點(diǎn)的前向指針 forward 和跳躍長度 span,也要更新最底層的后向指針 backward。
其中維護(hù)了兩個(gè)數(shù)組 update 和 rank。update 數(shù)組用來記錄每一層的最后一個(gè)分?jǐn)?shù)小于待插入 score 的節(jié)點(diǎn),也就是插入位置。rank 數(shù)組用來記錄上述插入位置的上一個(gè)節(jié)點(diǎn)的排名,以便于最后更新 span 值。
5.4 skiplist 刪除節(jié)點(diǎn)

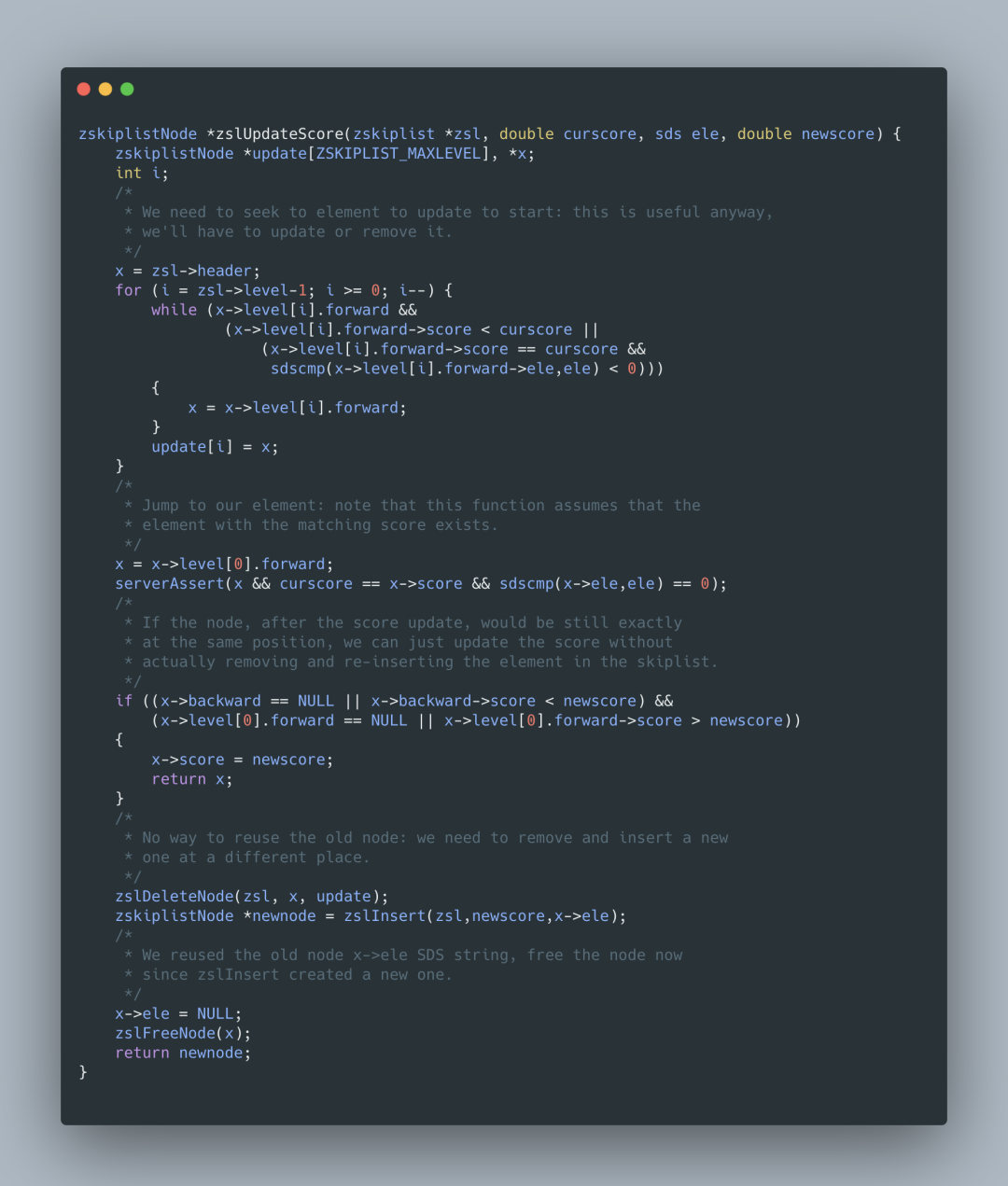
5.5 skiplist 更新節(jié)點(diǎn)
更新的過程和插入的過程都是是使用著 zadd 方法的,先是判斷這個(gè) value 是否存在,如果存在就是更新的過程,如果不存在就是插入過程。在更新的過程是,如果找到了 Value,先刪除掉,再新增,這樣的弊端是會(huì)做兩次的搜索,在性能上來講就比較慢了,在 Redis 5.0 版本中,Redis 的作者 Antirez 優(yōu)化了這個(gè)更新的過程,目前的更新過程是如果判斷這個(gè) value 是否存在,如果存在的話就直接更新,然后再調(diào)整整個(gè)跳躍表的 score 排序,這樣就不需要兩次的搜索過程。
5.6 skiplist 查找節(jié)點(diǎn)

六、skiplist 與平衡樹、哈希表的比較

歡迎大家關(guān)注我的公眾號(hào)【老周聊架構(gòu)】,Java后端主流技術(shù)棧的原理、源碼分析、架構(gòu)以及各種互聯(lián)網(wǎng)高并發(fā)、高性能、高可用的解決方案。
喜歡的話,點(diǎn)贊、再看、分享三連。

點(diǎn)個(gè)在看你最好看