
【機器學(xué)習(xí)基礎(chǔ)】如何在Python中處理不平衡數(shù)據(jù)
特征錦囊:如何在Python中處理不平衡數(shù)據(jù)
? Index
1、到底什么是不平衡數(shù)據(jù)
2、處理不平衡數(shù)據(jù)的理論方法
3、Python里有什么包可以處理不平衡樣本
4、Python中具體如何處理失衡樣本
印象中很久之前有位朋友說要我寫一篇如何處理不平衡數(shù)據(jù)的文章,整理相關(guān)的理論與實踐知識(可惜本人太懶了,現(xiàn)在才開始寫),于是乎有了今天的文章。失衡樣本在我們真實世界中是十分常見的,那么我們在機器學(xué)習(xí)(ML)中使用這些失衡樣本數(shù)據(jù)會出現(xiàn)什么問題呢?如何處理這些失衡樣本呢?以下的內(nèi)容希望對你有所幫助!
? 到底什么是不平衡數(shù)據(jù)
失衡數(shù)據(jù)發(fā)生在分類應(yīng)用場景中,在分類問題中,類別之間的分布不均勻就是失衡的根本,假設(shè)有個二分類問題,target為y,那么y的取值范圍為0和1,當(dāng)其中一方(比如y=1)的占比遠小于另一方(y=0)的時候,就是失衡樣本了。
那么到底是需要差異多少,才算是失衡呢,根本Google Developer的說法,我們一般可以把失衡分為3個程度:
輕度:20-40% 中度:1-20% 極度:<1%
一般來說,失衡樣本在我們構(gòu)建模型的時候看不出什么問題,而且往往我們還可以得到很高的accuracy,為什么呢?假設(shè)我們有一個極度失衡的樣本,y=1的占比為1%,那么,我們訓(xùn)練的模型,會偏向于把測試集預(yù)測為0,這樣子模型整體的預(yù)測準(zhǔn)確性就會有一個很好看的數(shù)字,如果我們只是關(guān)注這個指標(biāo)的話,可能就會被騙了。
? 處理不平衡數(shù)據(jù)的理論方法
在我們開始用Python處理失衡樣本之前,我們先來了解一波關(guān)于處理失衡樣本的一些理論知識,前輩們關(guān)于這類問題的解決方案,主要包括以下:
從數(shù)據(jù)角度:通過應(yīng)用一些欠采樣or過采樣技術(shù)來處理失衡樣本。欠采樣就是對多數(shù)類進行抽樣,保留少數(shù)類的全量,使得兩類的數(shù)量相當(dāng),過采樣就是對少數(shù)類進行多次重復(fù)采樣,保留多數(shù)類的全量,使得兩類的數(shù)量相當(dāng)。但是,這類做法也有弊端,欠采樣會導(dǎo)致我們丟失一部分的信息,可能包含了一些重要的信息,過采樣則會導(dǎo)致分類器容易過擬合。當(dāng)然,也可以是兩種技術(shù)的相互結(jié)合。 從算法角度:算法角度的解決方案就是可以通過對每類的訓(xùn)練實例給予一定權(quán)值的調(diào)整。比如像在SVM這樣子的有參分類器中,可以應(yīng)用grid search(網(wǎng)格搜索)以及交叉驗證(cross validation)來優(yōu)化C以及gamma值。而對于決策樹這類的非參數(shù)模型,可以通過調(diào)整樹葉節(jié)點上的概率估計從而實現(xiàn)效果優(yōu)化。
此外,也有研究員從數(shù)據(jù)以及算法的結(jié)合角度來看待這類問題,提出了兩者結(jié)合體的AdaOUBoost(adaptive over-sampling and undersampling boost)算法,這個算法的新穎之處在于自適應(yīng)地對少數(shù)類樣本進行過采樣,然后對多數(shù)類樣本進行欠采樣,以形成不同的分類器,并根據(jù)其準(zhǔn)確度將這些子分類器組合在一起從而形成強大的分類器,更多的請參考:
AdaOUBoost:https://dl.acm.org/doi/10.1145/1743384.1743408
? Python里有什么包可以處理不平衡樣本
這里介紹一個很不錯的包,叫 imbalanced-learn,大家可以在電腦上安裝一下使用。
官方文檔:https://imbalanced-learn.readthedocs.io/en/stable/index.html
pip?install?-U?imbalanced-learn
使用上面的包,我們就可以實現(xiàn)樣本的欠采樣、過采樣,并且可以利用pipeline的方式來實現(xiàn)兩者的結(jié)合,十分方便,我們下一節(jié)來簡單使用一下吧!
? Python中具體如何處理失衡樣本
為了更好滴理解,我們引入一個數(shù)據(jù)集,來自于UCI機器學(xué)習(xí)存儲庫的營銷活動數(shù)據(jù)集。(數(shù)據(jù)集大家可以自己去官網(wǎng)下載:https://archive.ics.uci.edu/ml/machine-learning-databases/00222/ ?下載bank-additional.zip 或者到公眾號后臺回復(fù)關(guān)鍵字“bank”來獲取吧。)
我們在完成imblearn庫的安裝之后,就可以開始簡單的操作了(其余更加復(fù)雜的操作可以直接看官方文檔),以下我會從4方面來演示如何用Python處理失衡樣本,分別是:
? 1、隨機欠采樣的實現(xiàn)
? 2、使用SMOTE進行過采樣
? 3、欠采樣和過采樣的結(jié)合(使用pipeline)
? 4、如何獲取最佳的采樣率?
??? 那我們開始吧!
#?導(dǎo)入相關(guān)的庫(主要就是imblearn庫)
from?collections?import?Counter
from?sklearn.model_selection?import?train_test_split
from?sklearn.model_selection?import?cross_val_score
import?pandas?as?pd
import?numpy?as?np
import?warnings
warnings.simplefilter(action='ignore',?category=FutureWarning)
from?sklearn.svm?import?SVC
from?sklearn.metrics?import?classification_report,?roc_auc_score
from?numpy?import?mean
#?導(dǎo)入數(shù)據(jù)
df?=?pd.read_csv(r'./data/bank-additional/bank-additional-full.csv',?';')?#?'';''?為分隔符
df.head()
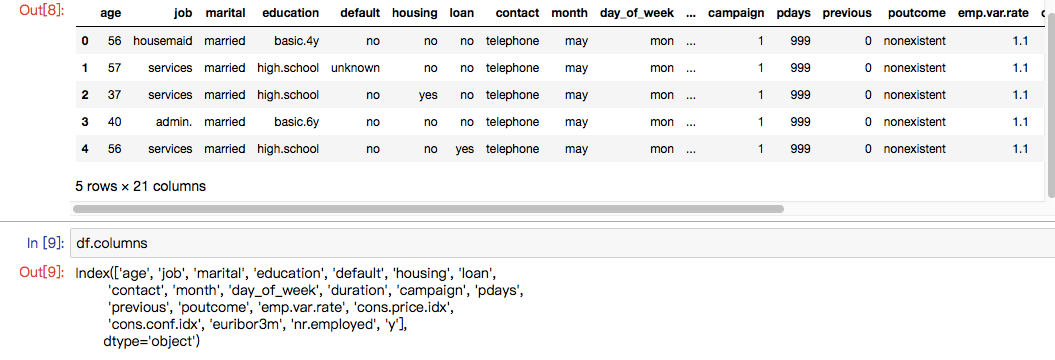
數(shù)據(jù)集是葡萄牙銀行的某次營銷活動的數(shù)據(jù),其營銷目標(biāo)就是讓客戶訂閱他們的產(chǎn)品,然后他們通過與客戶的電話溝通以及其他渠道獲取到的客戶信息,組成了這個數(shù)據(jù)集。
關(guān)于字段釋義,可以看下面的截圖:

我們可以大致看看數(shù)據(jù)集是不是失衡樣本:
df['y'].value_counts()/len(df)
#no?????0.887346
#yes????0.112654
#Name:?y,?dtype:?float64
可以看出少數(shù)類的占比為11.2%,屬于中度失衡樣本。
#?只保留數(shù)值型變量(簡單操作)
df?=?df.loc[:,
['age',?'duration',?'campaign',?'pdays',
???????'previous',?'emp.var.rate',?'cons.price.idx',
???????'cons.conf.idx',?'euribor3m',?'nr.employed','y']]
#?target由?yes/no?轉(zhuǎn)為?0/1
df['y']?=?df['y'].apply(lambda?x:?1?if?x=='yes'?else?0)
df['y'].value_counts()
#0????36548
#1?????4640
#Name:?y,?dtype:?int64
? 1、隨機欠采樣的實現(xiàn)
欠采樣在imblearn庫中也是有方法可以用的,那就是 under_sampling.RandomUnderSampler,我們可以使用把方法引入,然后調(diào)用它。可見,原先0的樣本有21942,欠采樣之后就變成了與1一樣的數(shù)量了(即2770),實現(xiàn)了50%/50%的類別分布。
#?1、隨機欠采樣的實現(xiàn)
#?導(dǎo)入相關(guān)的方法
from?imblearn.under_sampling?import?RandomUnderSampler
#?劃分因變量和自變量
X?=?df.iloc[:,:-1]
y?=?df.iloc[:,-1]
#?劃分訓(xùn)練集和測試集
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,y,test_size=0.40)
#?統(tǒng)計當(dāng)前的類別占比情況
print("Before?undersampling:?",?Counter(y_train))
#?調(diào)用方法進行欠采樣
undersample?=?RandomUnderSampler(sampling_strategy='majority')
#?獲得欠采樣后的樣本
X_train_under,?y_train_under?=?undersample.fit_resample(X_train,?y_train)
#?統(tǒng)計欠采樣后的類別占比情況
print("After?undersampling:?",?Counter(y_train_under))
#?調(diào)用支持向量機算法?SVC
model=SVC()
clf?=?model.fit(X_train,?y_train)
pred?=?clf.predict(X_test)
print("ROC?AUC?score?for?original?data:?",?roc_auc_score(y_test,?pred))
clf_under?=?model.fit(X_train_under,?y_train_under)
pred_under?=?clf_under.predict(X_test)
print("ROC?AUC?score?for?undersampled?data:?",?roc_auc_score(y_test,?pred_under))
# Output:
#Before?undersampling:??Counter({0:?21942,?1:?2770})
#After?undersampling:??Counter({0:?2770,?1:?2770})
#ROC?AUC?score?for?original?data:??0.603521152028
#ROC?AUC?score?for?undersampled?data:??0.829234085179
? 2、使用SMOTE進行過采樣
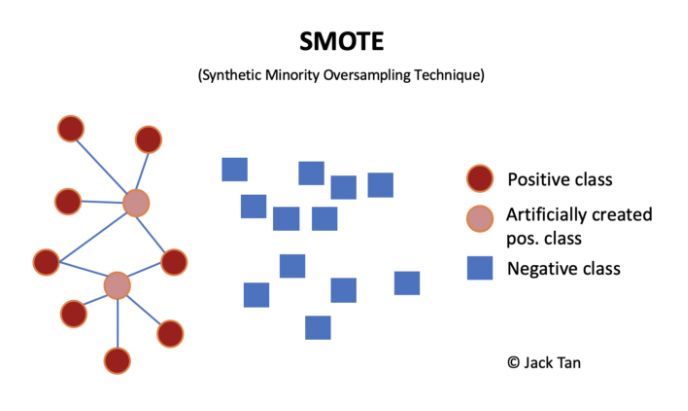
過采樣技術(shù)中,SMOTE被認為是最為流行的數(shù)據(jù)采樣算法之一,它是基于隨機過采樣算法的一種改良版本,由于隨機過采樣只是采取了簡單復(fù)制樣本的策略來進行樣本的擴增,這樣子會導(dǎo)致一個比較直接的問題就是過擬合。因此,SMOTE的基本思想就是對少數(shù)類樣本進行分析并合成新樣本添加到數(shù)據(jù)集中。
算法流程如下:
(1)對于少數(shù)類中每一個樣本x,以歐氏距離為標(biāo)準(zhǔn)計算它到少數(shù)類樣本集中所有樣本的距離,得到其k近鄰。
(2)根據(jù)樣本不平衡比例設(shè)置一個采樣比例以確定采樣倍率N,對于每一個少數(shù)類樣本x,從其k近鄰中隨機選擇若干個樣本,假設(shè)選擇的近鄰為xn。
(3)對于每一個隨機選出的近鄰xn,分別與原樣本按照如下的公式構(gòu)建新的樣本。
#?2、使用SMOTE進行過采樣
#?導(dǎo)入相關(guān)的方法
from?imblearn.over_sampling?import?SMOTE
#?劃分因變量和自變量
X?=?df.iloc[:,:-1]
y?=?df.iloc[:,-1]
#?劃分訓(xùn)練集和測試集
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,y,test_size=0.40)
#?統(tǒng)計當(dāng)前的類別占比情況
print("Before?oversampling:?",?Counter(y_train))
#?調(diào)用方法進行過采樣
SMOTE?=?SMOTE()
#?獲得過采樣后的樣本
X_train_SMOTE,?y_train_SMOTE?=?SMOTE.fit_resample(X_train,?y_train)
#?統(tǒng)計過采樣后的類別占比情況
print("After?oversampling:?",Counter(y_train_SMOTE))
#?調(diào)用支持向量機算法?SVC
model=SVC()
clf?=?model.fit(X_train,?y_train)
pred?=?clf.predict(X_test)
print("ROC?AUC?score?for?original?data:?",?roc_auc_score(y_test,?pred))
clf_SMOTE=?model.fit(X_train_SMOTE,?y_train_SMOTE)
pred_SMOTE?=?clf_SMOTE.predict(X_test)
print("ROC?AUC?score?for?oversampling?data:?",?roc_auc_score(y_test,?pred_SMOTE))
# Output:
#Before?oversampling:??Counter({0:?21980,?1:?2732})
#After?oversampling:??Counter({0:?21980,?1:?21980})
#ROC?AUC?score?for?original?data:??0.602555700614
#ROC?AUC?score?for?oversampling?data:??0.844305732561
? 3、欠采樣和過采樣的結(jié)合(使用pipeline)
那如果我們需要同時使用過采樣以及欠采樣,那該怎么做呢?其實很簡單,就是使用 pipeline來實現(xiàn)。
#??3、欠采樣和過采樣的結(jié)合(使用pipeline)
#?導(dǎo)入相關(guān)的方法
from?imblearn.over_sampling?import?SMOTE
from?imblearn.under_sampling?import?RandomUnderSampler
from?imblearn.pipeline?import?Pipeline
#?劃分因變量和自變量
X?=?df.iloc[:,:-1]
y?=?df.iloc[:,-1]
#??定義管道
model?=?SVC()
over?=?SMOTE(sampling_strategy=0.4)
under?=?RandomUnderSampler(sampling_strategy=0.5)
steps?=?[('o',?over),?('u',?under),?('model',?model)]
pipeline?=?Pipeline(steps=steps)
#?評估效果
scores?=?cross_val_score(pipeline,?X,?y,?scoring='roc_auc',?cv=5,?n_jobs=-1)
score?=?mean(scores)
print('ROC?AUC?score?for?the?combined?sampling?method:?%.3f'?%?score)
# Output:
#ROC?AUC?score?for?the?combined?sampling?method:?0.937
? 4、如何獲取最佳的采樣率?
在上面的栗子中,我們都是默認經(jīng)過采樣變成50:50,但是這樣子的采樣比例并非最優(yōu)選擇,因此我們引入一個叫 最佳采樣率的概念,然后我們通過設(shè)置采樣的比例,采樣網(wǎng)格搜索的方法去找到這個最優(yōu)點。
# 4、如何獲取最佳的采樣率?
#?導(dǎo)入相關(guān)的方法
from?imblearn.over_sampling?import?SMOTE
from?imblearn.under_sampling?import?RandomUnderSampler
from?imblearn.pipeline?import?Pipeline
#?劃分因變量和自變量
X?=?df.iloc[:,:-1]
y?=?df.iloc[:,-1]
#?values?to?evaluate
over_values?=?[0.3,0.4,0.5]
under_values?=?[0.7,0.6,0.5]
for?o?in?over_values:
??for?u?in?under_values:
????#?define?pipeline
????model?=?SVC()
????over?=?SMOTE(sampling_strategy=o)
????under?=?RandomUnderSampler(sampling_strategy=u)
????steps?=?[('over',?over),?('under',?under),?('model',?model)]
????pipeline?=?Pipeline(steps=steps)
????#?evaluate?pipeline
????scores?=?cross_val_score(pipeline,?X,?y,?scoring='roc_auc',?cv=5,?n_jobs=-1)
????score?=?mean(scores)
????print('SMOTE?oversampling?rate:%.1f,?Random?undersampling?rate:%.1f?,?Mean?ROC?AUC:?%.3f'?%?(o,?u,?score))
????
# Output:????
#SMOTE?oversampling?rate:0.3,?Random?undersampling?rate:0.7?,?Mean?ROC?AUC:?0.938
#SMOTE?oversampling?rate:0.3,?Random?undersampling?rate:0.6?,?Mean?ROC?AUC:?0.936
#SMOTE?oversampling?rate:0.3,?Random?undersampling?rate:0.5?,?Mean?ROC?AUC:?0.937
#SMOTE?oversampling?rate:0.4,?Random?undersampling?rate:0.7?,?Mean?ROC?AUC:?0.938
#SMOTE?oversampling?rate:0.4,?Random?undersampling?rate:0.6?,?Mean?ROC?AUC:?0.937
#SMOTE?oversampling?rate:0.4,?Random?undersampling?rate:0.5?,?Mean?ROC?AUC:?0.938
#SMOTE?oversampling?rate:0.5,?Random?undersampling?rate:0.7?,?Mean?ROC?AUC:?0.939
#SMOTE?oversampling?rate:0.5,?Random?undersampling?rate:0.6?,?Mean?ROC?AUC:?0.938
#SMOTE?oversampling?rate:0.5,?Random?undersampling?rate:0.5?,?Mean?ROC?AUC:?0.938
從結(jié)果日志來看,最優(yōu)的采樣率就是過采樣0.5,欠采樣0.7。
最后,想和大家說的是沒有絕對的套路,只有合適的套路,無論是欠采樣還是過采樣,只有合適才最重要。還有,欠采樣的確會比過采樣“省錢”哈(從訓(xùn)練時間上很直觀可以感受到)。
? References
[1] SMOTE算法 https://www.jianshu.com/p/13fc0f7f5565
[2] How to deal with imbalanced data in Python
往期精彩回顧
獲取本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群請掃碼: