在現(xiàn)實(shí)世界中,我們收集的數(shù)據(jù)在大多數(shù)時(shí)候是嚴(yán)重不平衡的,所謂不平衡數(shù)據(jù)集就是訓(xùn)練樣本不是平均分布在目標(biāo)類中,例如,如果我們以個(gè)人貸款分類問(wèn)題為例,就很容易得到“未批準(zhǔn)”的數(shù)據(jù),而不是“已批準(zhǔn)”的信息,結(jié)果,模型會(huì)更偏向具有大量訓(xùn)練實(shí)例的類,這降低了模型的預(yù)測(cè)能力。在典型的二元分類問(wèn)題中,它還會(huì)II型錯(cuò)誤的增加。這一障礙不僅局限于機(jī)器學(xué)習(xí)模型,而且也主要存在于計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理領(lǐng)域。這些問(wèn)題可以通過(guò)對(duì)每個(gè)區(qū)域分別使用不同的技術(shù)來(lái)有效地處理。注意:本文將簡(jiǎn)要概述各種可用的數(shù)據(jù)增強(qiáng)方法,但不深入技術(shù)細(xì)節(jié),這里展示的所有圖像都來(lái)自Kaggle。目錄
- 機(jī)器學(xué)習(xí)——不平衡數(shù)據(jù)(上采樣和下采樣)
- 計(jì)算機(jī)視覺(jué)——不平衡數(shù)據(jù)(圖像數(shù)據(jù)增強(qiáng))
- NLP——不平衡數(shù)據(jù)(Google交易和分類權(quán)重)
1. 機(jī)器學(xué)習(xí)——不平衡數(shù)據(jù)
處理類不平衡的兩種主要方法是上采樣/過(guò)采樣和下采樣/欠采樣。抽樣過(guò)程只應(yīng)用于訓(xùn)練集,對(duì)驗(yàn)證和測(cè)試數(shù)據(jù)不作任何更改。python中的Imblearn庫(kù)可以方便地實(shí)現(xiàn)數(shù)據(jù)重采樣。上采樣是將合成生成的數(shù)據(jù)點(diǎn)(對(duì)應(yīng)于少數(shù)類)注入數(shù)據(jù)集的過(guò)程,在這個(gè)過(guò)程之后,兩個(gè)標(biāo)簽的計(jì)數(shù)幾乎是相同的,這種均衡過(guò)程防止了模型向多數(shù)類傾斜,而且目標(biāo)類之間的交互(邊界)保持不變,同時(shí),上采樣機(jī)制由于附加信息的存在而給系統(tǒng)帶來(lái)偏差。我們可以通過(guò)分析Google Analytics的貸款預(yù)測(cè)問(wèn)題來(lái)解釋這些步驟。這里使用的訓(xùn)練數(shù)據(jù)集可以在以下鏈接中找到。- https://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii/
下面提到的所有代碼都可以在GitHub存儲(chǔ)庫(kù)中找到。- https://github.com/NandhiniN85/Class-Imbalancing
SMOTE(SyntheticMinorityOversamplingTechnique)——upsampling: 上采樣SMOTE基于knearestneighbors算法,綜合生成數(shù)據(jù)點(diǎn),這些數(shù)據(jù)點(diǎn)位于已經(jīng)存在的數(shù)量被超過(guò)的群體附近。應(yīng)用此方法時(shí),輸入記錄不應(yīng)包含任何空值。#import imblearn library
from imblearn.over_sampling import SMOTENC
oversample = SMOTENC(categorical_features=[0,1,2,3,4,9,10], random_state = 100)
X, y = oversample.fit_resample(X, y)
datduplicate—upsampling: 在這種方法中,已存在的數(shù)據(jù)點(diǎn)被隨機(jī)抽取并重復(fù)。from sklearn.utils import resample
maxcount = 332
train_nonnull_resampled = train_nonnull[0:0]
for grp in train_nonnull['Loan_Status'].unique():
GrpDF = train_nonnull[train_nonnull['Loan_Status'] == grp]
resampled = resample(GrpDF, replace=True, n_samples=int(maxcount), random_state=123)
train_nonnull_resampled = train_nonnull_resampled.append(resampled)
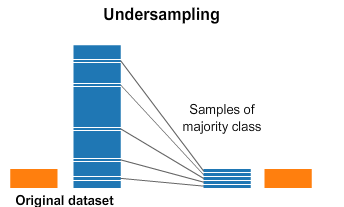
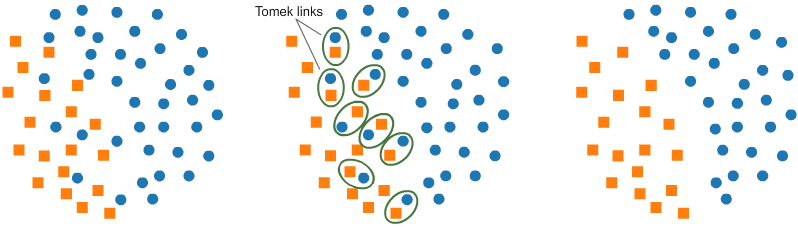
下采樣是一種減少訓(xùn)練樣本落在多數(shù)類下的機(jī)制。因?yàn)樗兄谄胶饽繕?biāo)類別的計(jì)數(shù),但刪除收集到的數(shù)據(jù),我們往往會(huì)丟失很多有價(jià)值的信息。T-Link基本上是來(lái)自不同類(最近的鄰居)的一對(duì)數(shù)據(jù)點(diǎn),其目標(biāo)是丟棄與多數(shù)類(數(shù)量較多的類)相對(duì)應(yīng)的樣本,從而減少占主導(dǎo)地位的標(biāo)簽的數(shù)量。這也增加了兩個(gè)標(biāo)簽之間的邊界空間,從而提高了性能準(zhǔn)確性。from imblearn.under_sampling import TomekLinks
undersample = TomekLinks()
X, y = undersample.fit_resample(X, y)
基于: 算法嘗試在多數(shù)類中尋找同質(zhì)聚類,只保留質(zhì)心,這將減少多數(shù)類的最大份額。它利用了KMeans集群中使用的邏輯,但是很多有用的信息會(huì)被浪費(fèi)。2. 計(jì)算機(jī)視覺(jué)——不平衡數(shù)據(jù)
對(duì)于非結(jié)構(gòu)化數(shù)據(jù),如圖像和文本輸入,上述平衡技術(shù)將不會(huì)有效。在計(jì)算機(jī)視覺(jué)中,模型的輸入是圖像中像素的張量表示,所以只是隨機(jī)改變像素值(為了添加更多的輸入記錄)就可以完全改變圖片本身的意義。有一種概念叫做數(shù)據(jù)增強(qiáng),即圖像經(jīng)過(guò)大量轉(zhuǎn)換后仍然保持其意義不變。各種圖像轉(zhuǎn)換包括縮放、剪切、翻轉(zhuǎn)、填充、旋轉(zhuǎn)、亮度、對(duì)比度和飽和度變化,通過(guò)這樣做,僅使用單個(gè)圖像,就可以創(chuàng)建一個(gè)龐大的圖像數(shù)據(jù)集。讓我們看看Analyticsvidhya中發(fā)布的計(jì)算機(jī)視覺(jué)hackathon,使用的數(shù)據(jù)集可以在這里找到。- https://datahack.analyticsvidhya.com/contest/janatahack-computer-vision-hackathon/#ProblemStatement
要求是將車輛分為緊急和非緊急兩類。為了便于說(shuō)明,我們使用“0.jpg”圖像。from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = load_img('images/0.jpg')
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
print(x.shape)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='vehichle', save_format='jpeg'):
i += 1
if i > 19:
break # otherwise the generator would loop indefinitely
在GitHub存儲(chǔ)庫(kù)中可以找到整個(gè)代碼和一個(gè)預(yù)訓(xùn)練過(guò)的模型。- https://github.com/NandhiniN85/Class-Imbalancing/blob/main/Computer%20Vision%20-%20Data%20Imbalanced.ipynb
可以參考這個(gè)鏈接了解ImageDataGenerator的詳細(xì)用法。- https://keras.io/api/preprocessing/image/
3. NLP——不平衡數(shù)據(jù)
自然語(yǔ)言處理模型處理序列數(shù)據(jù),如文本、移動(dòng)圖像,其中當(dāng)前數(shù)據(jù)與之前的數(shù)據(jù)有時(shí)間依賴性。由于文本輸入屬于非結(jié)構(gòu)化數(shù)據(jù),所以我們要以不同的方式處理這些場(chǎng)景。例如,以票據(jù)分類語(yǔ)言模型為例,其中IT票據(jù)必須根據(jù)輸入文本中出現(xiàn)的單詞順序分配給不同的組。谷歌翻譯(google trans python包): 這是擴(kuò)展少數(shù)群體數(shù)量的有用技術(shù)之一。在這里,我們把給定的句子翻譯成“非英語(yǔ)”語(yǔ)言,然后再翻譯成“英語(yǔ)”,通過(guò)這種方式,可以維護(hù)輸入消息的重要細(xì)節(jié),但是單詞的順序/有時(shí)具有相似意義的新詞作為新記錄引入,從而可以對(duì)不足類進(jìn)行計(jì)數(shù)。輸入文字- "warning for using windows disk space"數(shù)據(jù)補(bǔ)充文字-“Warning about using Windows storage space”即使上面的句子的意思是一樣的,它也引入了新單詞,從而通過(guò)擴(kuò)大輸入樣本的數(shù)量來(lái)提高語(yǔ)言模型的學(xué)習(xí)能力。下面執(zhí)行的代碼可以在GitHub存儲(chǔ)庫(kù)中找到。- https://github.com/NandhiniN85/Class-Imbalancing/blob/main/NLP%20-%20Class%20Imbalanced.ipynb
這個(gè)例子只包含了一個(gè)非英語(yǔ)代碼。在google trans 中使用的語(yǔ)言代碼的完整列表可以在以下鏈接找到:https://py-googletrans.readthedocs.io/en/latest/from googletrans import Translatortranslator = Translator()
def German_translation(x): print(x) german_translation = translator.translate(x, dest='de') return german_translation.text
def English_translation(x): print(x)
english_translation = translator.translate(x, dest='en') return english_translation.text
x = German_translation("warning for using windows disk space")
English_translation(x)
類權(quán)重: 該方法是在擬合模型過(guò)程中利用類權(quán)重參數(shù)。對(duì)于目標(biāo)中的每個(gè)類別,都分配一個(gè)權(quán)重,與多數(shù)類相比,少數(shù)類將獲得更多的權(quán)重,因此,在反向傳播過(guò)程中,與少數(shù)類相關(guān)聯(lián)的損失值越大,模型會(huì)對(duì)輸出中的所有類一視同仁。import numpy as np
from tensorflow import keras
from sklearn.utils.class_weight import compute_class_weight
y_integers = np.argmax(raw_y_train, axis=1)
class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
d_class_weights = dict(enumerate(class_weights))
history = model.fit(input_final, raw_y_train, batch_size=32, class_weight = d_class_weights, epochs=8,callbacks=[checkpoint,reduceLoss],validation_data =(val_final, raw_y_val), verbose=1)
這個(gè)選項(xiàng)在機(jī)器學(xué)習(xí)分類器中也可用,如我們給class_weight = ' balanced '的' SVM '。# fit the training dataset on the classifier
SVM = svm.SVC(C=1.0, kernel='linear', degree=3, gamma='auto', class_weight='balanced', random_state=100)
使用類權(quán)重的整個(gè)python代碼可以在GitHub鏈接中找到。- https://github.com/NandhiniN85/Class-Imbalancing/blob/main/English_raw200_model_execution.ipynb
結(jié)論
到目前為止,我們已經(jīng)討論了不同領(lǐng)域處理不平衡數(shù)據(jù)的各種方法,如機(jī)器學(xué)習(xí)、計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理。盡管這些方法只是解決多數(shù)Vs少數(shù)目標(biāo)群體問(wèn)題的開(kāi)始,還有其他先進(jìn)的技術(shù)可以進(jìn)一步探索。
?------------------------------------------------
感謝對(duì)我們的支持!