
識別速度3.6ms/幀!人像摳圖、工業(yè)質檢、遙感識別,用這一個分割模型就夠了
支撐影視人像摳圖、醫(yī)療影像分析、自動駕駛感知等萬億級市場背后的核心技術是什么?那就要說到頂頂重要的圖像分割技術。相比目標檢測、圖像分類等技術,圖像分割需要將每個像素點進行分類,在精細的圖像識別任務中不可替代,也是智能視覺算法工程師擁有關鍵核心競爭力的關鍵!

圖1 圖像分割應用
正因如此,DeepLabv3、OCRNet、BiseNetv2、Fast-SCNN等優(yōu)秀算法層出不窮,然而在實際產業(yè)落地過程中往往需要綜合考慮硬件性能、精度等多方面因素,對算法的需求也是苛刻的。往往業(yè)界算法在保障高識別精度的情況下,就會犧牲算法運行速度;反之追求速度,則會帶來精度的大幅度損失。
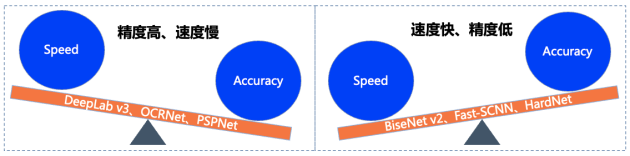
圖2 各算法速度與精度平衡情況示意
如何能同時實現速度和精度的均衡,在當前云、邊、端多場景協(xié)同的產業(yè)大趨勢下高標準滿足產業(yè)需求,是各屆研究人員致力投入的方向。
PP-LiteSeg就是這樣一個同時兼顧精度與速度的SOTA(業(yè)界最佳)語義分割模型。它基于Cityscapes數據集,在1080ti上精度為mIoU 72.0時,速度高達273.6 FPS?, (mIoU 77.5 時,FPS為102.6),超越現有CVPR SOTA模型STDC,真正實現了精度和速度的SOTA均衡。
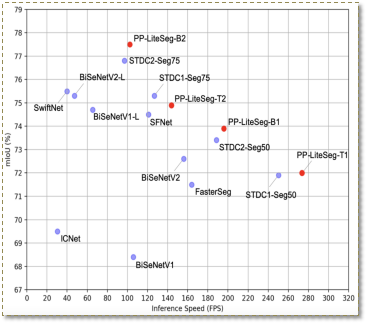
圖3?PP-LiteSeg精度/速度說明
空口無憑,歡迎優(yōu)秀的你直接試用!?(記得Star收藏跟進最新狀態(tài))
傳送門:
https://github.com/PaddlePaddle/PaddleSeg

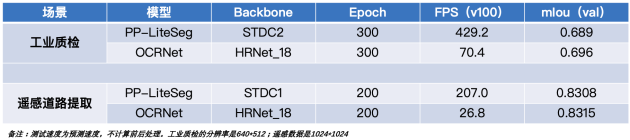

圖4 PP-LiteSeg和OCRNet在某工業(yè)質檢數據集識別情況對比

圖4 PP-LiteSeg和OCRNet在deepglobe數據集識別情況對比
那PP-LiteSeg為何可以擁有這么優(yōu)秀的效果呢?
PP-LiteSeg提出三個創(chuàng)新模塊:靈活的解碼模塊(FLD)、注意力融合模塊(UAFM)、簡易金字塔池化模塊(SPPM)。FLD靈活調整解碼模塊中通道數,平衡編碼模塊和解碼模塊的計算量,使得整個模型更加高效;UAFM模塊效地加強特征表示,更好地提升了模型的精度;SPPM模塊減小了中間特征圖的通道數、移除了跳躍連接,使得模型性能進一步提升。
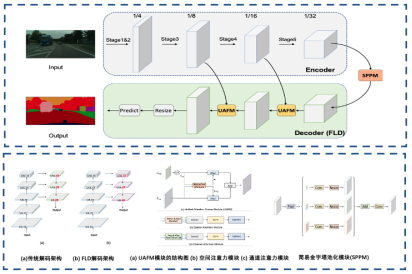
圖5 PP-LiteSeg 模型結構和優(yōu)化點
正是基于這些模塊的設計與改進,最終PP-LiteSeg超越其他方法,在1080ti上精度為mIoU 72.0時,速度高達273.6 FPS , (mIoU 77.5 時,FPS為102.6),實現了精度和速度的SOTA平衡。更多關于PP-LiteSeg的內容,請參考:
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.5/configs/pp_liteseg
直播預告
為了讓開發(fā)者們更深入的了解PP-LiteSeg這個SOTA模型,解決落地應用難點,掌握產業(yè)實踐的核心能力,飛槳團隊精心準備了精品直播課!

掃碼報名直播課
進入技術交流群
4月26日20:30,百度資深高工將為我們詳細介紹精度和速度平衡的PP-LiteSeg,對其原理及使用方式進行拆解,更有汽車金屬墊片缺陷分割實戰(zhàn),加上直播現場互動答疑,還在等什么!抓緊掃碼上車吧!

圖1
圖4:合作伙伴提供質檢數據樣例
圖5:源于deepglobe數據集
END
