
開(kāi)放目前最大人像摳圖數(shù)據(jù)集!助力隱私保護(hù)的人像摳圖研究
人像摳圖,是指從人物圖像中提取人物前景,是計(jì)算機(jī)視覺(jué)領(lǐng)域的基礎(chǔ)研究問(wèn)題之一[1,2,3,4,8],在下游任務(wù)上應(yīng)用非常廣泛,例如視頻會(huì)議,電影制作,直播軟件等等[7]。鑒于人物圖像中經(jīng)常包含人臉等個(gè)人核心隱私,如何防止該類(lèi)信息被濫用成為一個(gè)很重要的問(wèn)題。然而,之前所有的人像摳圖方法都忽略了對(duì)于人像隱私信息的保護(hù)。使得如何在保護(hù)隱私信息的同時(shí),取得高精度的人像摳圖結(jié)果,成為一個(gè)未被探索過(guò)的開(kāi)放問(wèn)題。
最近,探索研究院聯(lián)合悉尼大學(xué)、Adobe等機(jī)構(gòu),首次提出面向人像隱私保護(hù)的人像摳圖任務(wù),并構(gòu)建了一個(gè)目前為止最大型的人像摳圖數(shù)據(jù)集P3M-10k,涵蓋10,421張保護(hù)了人臉隱私的訓(xùn)練集和兩個(gè)沒(méi)有人像隱私問(wèn)題的測(cè)試集。此外,我們基于vision transformer設(shè)計(jì)了一種端到端的人像摳圖模型P3M-Net, 在只使用人像隱私保護(hù)的數(shù)據(jù)訓(xùn)練之后,在多個(gè)公開(kāi)的人像測(cè)試集都取得了最優(yōu)的結(jié)果。
模型訓(xùn)練均不涉及人像隱私數(shù)據(jù),解決了人像摳圖任務(wù)中的隱私保護(hù)問(wèn)題。

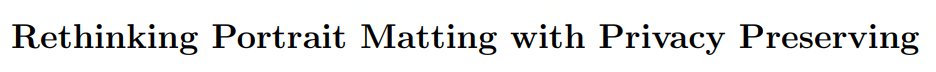
01
研究背景
近期,由于多媒體行業(yè)的興盛,全自動(dòng)化人像摳圖成為一個(gè)備受關(guān)注的方向[3,4]。然而,如何解決人像摳圖任務(wù)中涉及到的人臉信息的隱私問(wèn)題,成為一個(gè)未被關(guān)注和研究的領(lǐng)域。在本項(xiàng)研究中,我們提出了一個(gè)人像摳圖新任務(wù),探索如何在不涉及人臉隱私信息的同時(shí)能達(dá)到高精度人像摳圖結(jié)果。為了促進(jìn)該新任務(wù)的研究和評(píng)估,我們構(gòu)建了一個(gè)目前為止最大的隱私保護(hù)的人像摳圖數(shù)據(jù)集P3M-10k。
此外,以前的人像摳圖方法大多需要使用人為生成的輔助信息(三分圖,粗糙的分割圖,草圖等)來(lái)幫助完成摳圖。而僅有的幾種全自動(dòng)人像摳圖網(wǎng)絡(luò)也是基于CNN的單分支編碼-解碼網(wǎng)絡(luò)。不同于上述方法,我們?cè)O(shè)計(jì)了一種全新的基于vision transformer的多分支全自動(dòng)摳圖網(wǎng)絡(luò),在諸多公開(kāi)的人像數(shù)據(jù)測(cè)試集上達(dá)到了最優(yōu)的表現(xiàn)。
02
PPT 任務(wù) 和 P3M-10k數(shù)據(jù)集
為了探索如何在不涉及人臉隱私的同時(shí)達(dá)到高精度人像摳圖,我們提出了一個(gè)新的任務(wù),在人臉被保護(hù)的摳圖數(shù)據(jù)上進(jìn)行訓(xùn)練,讓模型能夠泛化到任意圖像上,包括人臉隱私被保護(hù)的圖像和普通完整人像。我們稱(chēng)之為Privacy Preserving Training (PPT) 任務(wù)。
為了探索PPT任務(wù),我們構(gòu)建了目前為止最大的具備隱私保護(hù)的人像摳圖數(shù)據(jù)集 P3M-10k。P3M-10k包括了10,421張人臉隱私被保護(hù)的圖片,和對(duì)應(yīng)的精細(xì)摳圖標(biāo)注。其中訓(xùn)練集有9,421張人臉被遮擋的高清人像圖片。測(cè)試集分為兩個(gè): (1) P3M-500-P提供了500張人臉隱私信息被遮擋的人像及高精度標(biāo)注,用以驗(yàn)證模型在隱私保護(hù)情況下的摳圖效果; (2) P3M-500-NP則提供了500張名人的人像圖像,其人臉信息是可公開(kāi)的,用以驗(yàn)證模型在普通完整人像上的泛化能力。下圖展示了數(shù)據(jù)集中的部分圖片和精細(xì)摳圖標(biāo)注。(a) 訓(xùn)練集樣張 (b) 測(cè)試集 P3M-500-P 樣張 (c) 測(cè)試集 P3M-500-NP樣張。左圖為人像,右圖為標(biāo)注信息。

我們?cè)赑3M-10k數(shù)據(jù)集上訓(xùn)練并測(cè)試了現(xiàn)有的摳圖算法,包括基于輔助信息的摳圖方法和全自動(dòng)摳圖方法,并且進(jìn)一步探討了因?yàn)殡[私保護(hù)(即PPT任務(wù))而產(chǎn)生的模型泛化能力的差異。具體實(shí)驗(yàn)結(jié)果可見(jiàn)論文[1,2]。實(shí)驗(yàn)結(jié)果表明,大部分的全自動(dòng)摳圖方法都因?yàn)椴捎昧巳四槺槐Wo(hù)的數(shù)據(jù)進(jìn)行訓(xùn)練,能夠在人臉被遮擋的圖片上表現(xiàn)良好,卻無(wú)法很好地泛化到普通完整的人像圖片上。如何緩解全自動(dòng)摳圖方法泛化性能差的問(wèn)題,是本項(xiàng)研究的目標(biāo)之一。另外,我們也發(fā)現(xiàn)由一個(gè)共享編碼器,和兩個(gè)不同任務(wù)的解碼器組成的結(jié)構(gòu)能夠有效緩解因隱私保護(hù)而產(chǎn)生的摳圖模型泛化能力差的問(wèn)題。基于此,我們?cè)O(shè)計(jì)了全新的單編碼器-雙解碼器的人像摳圖模型P3M-Net。
03
全新端到端摳圖網(wǎng)絡(luò) P3M-NET
首先,我們將全自動(dòng)化人像摳圖任務(wù)分解成人像語(yǔ)義信息獲取和人像細(xì)節(jié)信息提取兩個(gè)子任務(wù)。基于此,我們?cè)O(shè)計(jì)的P3M-Net由一個(gè)共享的編碼器和兩個(gè)分開(kāi)的解碼器組成,分別進(jìn)行共同特征提取和完成上述兩個(gè)子任務(wù)。我們還設(shè)計(jì)了一個(gè)三方特征融合模塊,為了促進(jìn)兩個(gè)子任務(wù)之間的信息交互,使得預(yù)測(cè)錯(cuò)誤可以在深層網(wǎng)絡(luò)里被逐步糾正。此外,我們還額外設(shè)計(jì)了一個(gè)深層雙向特征融合模塊和淺層雙向特征融合模塊來(lái)確保每個(gè)子任務(wù)與其對(duì)應(yīng)的不同層次的編碼進(jìn)行充分的融合。后續(xù)的實(shí)驗(yàn)驗(yàn)證了我們所提出的三個(gè)模塊的作用。
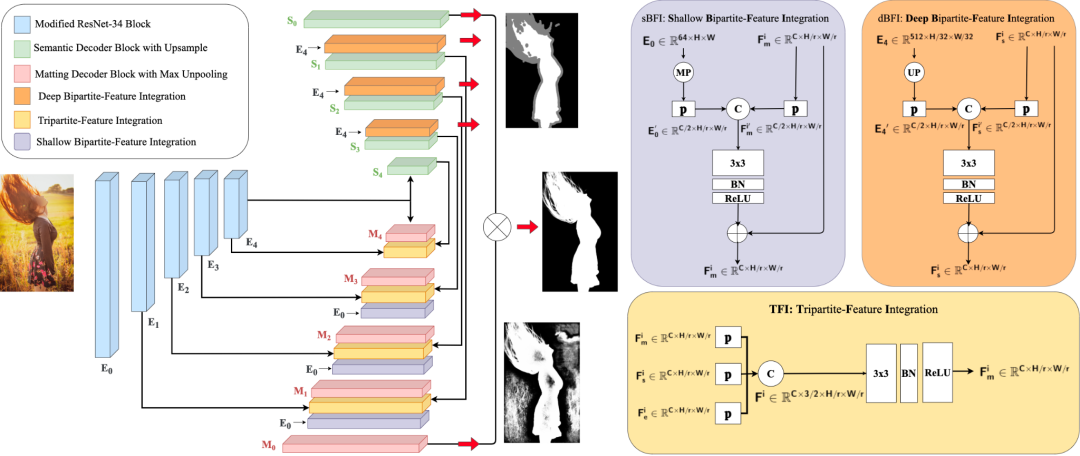
另外,我們也探究了使用CNN和vision transformer作為編碼模塊的性能差異。具體的,我們使用了ResNet-34[9], Swin Transformer[10]和ViTAE Transformer[5,6]作為我們的基礎(chǔ)模塊。我們觀察到,Swin相比于ResNet, 鑒于它具有更好的長(zhǎng)距關(guān)系建模能力,使得它對(duì)于語(yǔ)義層面的提取能力更強(qiáng)。相比于CNN和Swin,ViTAE在具有長(zhǎng)距關(guān)系建模能力的同時(shí),還保有CNN的局部性和不變性建模能力,使其具有很強(qiáng)的語(yǔ)義提取能力,同時(shí)對(duì)于人物圖像中細(xì)節(jié)的感知能力也更勝一籌。我們?cè)诤竺娴闹饔^和客觀結(jié)果中都說(shuō)明了這一點(diǎn)。
04
隱私數(shù)據(jù)訓(xùn)練的影響與研究
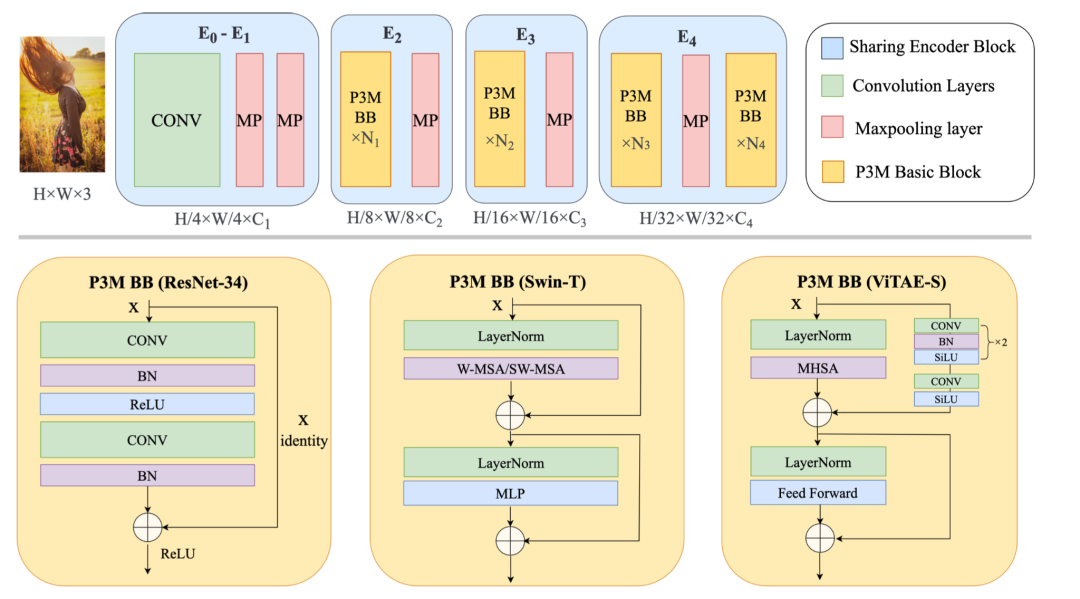
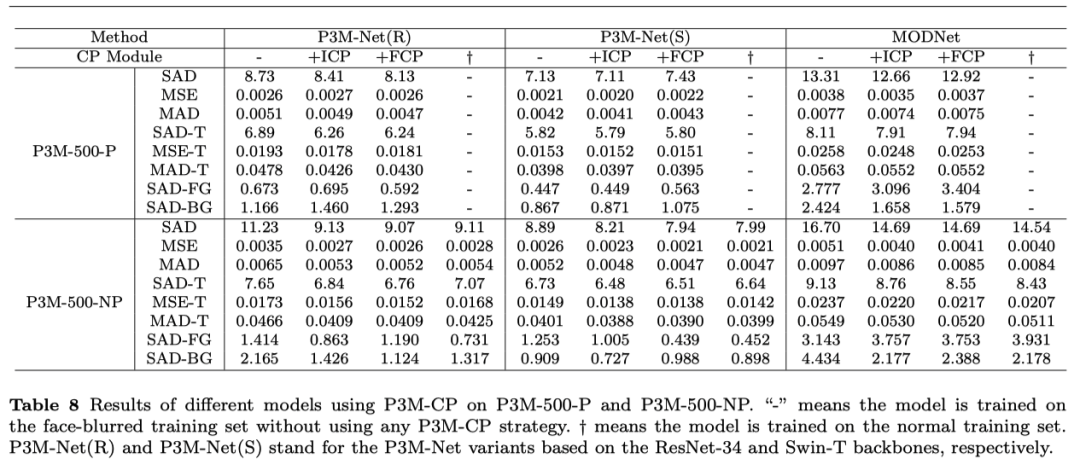
盡管P3M-Net模型緩解了PPT任務(wù)下對(duì)于普通人像上的泛化性能降低的問(wèn)題,但依然存在人臉部分虛化,前后景語(yǔ)義錯(cuò)誤的情況。為了進(jìn)一步解決這個(gè)問(wèn)題,我們提出了Copy and Paste (P3M-CP) 模塊。這是一個(gè)即插即用的模塊,能夠?qū)⒖晒_(kāi)的人臉信息注入到任意摳圖模型中,有效緩解PPT設(shè)置帶來(lái)的泛化性能下降的問(wèn)題。
P3M-CP 模塊能夠在數(shù)據(jù)和特征兩個(gè)層面提取公開(kāi)的名人人像中的人臉信息,用 “copy and paste” 的模式注入到模型中,補(bǔ)充訓(xùn)練階段的缺乏的人臉信息,因此提升模型在完整人像上的泛化能力。下圖中展示了P3M-CP如何從source domain(名人數(shù)據(jù))向target domain(隱私保護(hù)下的訓(xùn)練數(shù)據(jù))注入信息的過(guò)程。具體的,P3M-CP可以在數(shù)據(jù)層面(P3M-ICP)和特征層面(P3M-FCP)上分別進(jìn)行。
05
實(shí)驗(yàn)結(jié)果
為了驗(yàn)證P3M-Net 模型在人像摳圖下的效果,我們?cè)赑3M-10k 的訓(xùn)練集上進(jìn)行訓(xùn)練,在兩個(gè)測(cè)試集上進(jìn)行驗(yàn)證。其中P3M-500-P測(cè)試集能夠驗(yàn)證模型在隱私保護(hù)下的摳圖效果,而P3M-500-NP測(cè)試集則可以檢驗(yàn)?zāi)P驮谌四槺荒:那闆r下訓(xùn)練后在完整人像上的泛化能力。我們采用了MSE, SAD, GRAD, CONN等評(píng)價(jià)指標(biāo)。客觀結(jié)果如下表所示。主觀效果如下圖所示。可以看出,我們所有的P3M-Net變種都超越了目前所有的前沿?fù)笀D模型,優(yōu)勢(shì)明顯。
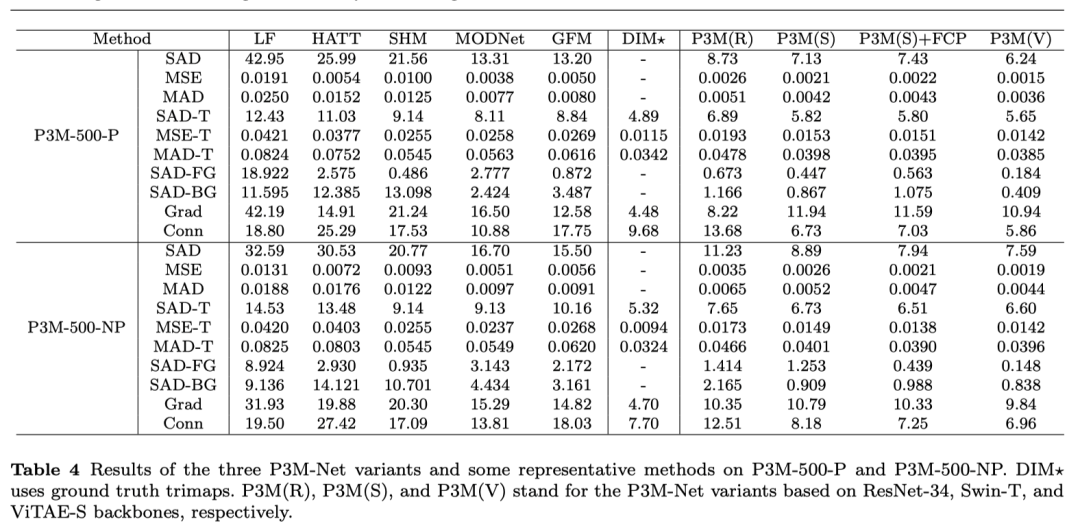


另外,我們?cè)贏dobe發(fā)布的 RWP test set上也進(jìn)行了測(cè)試,進(jìn)一步驗(yàn)證模型的性能。我們的模型均由P3M-10k訓(xùn)練集進(jìn)行訓(xùn)練,在RWP test set上直接測(cè)試。測(cè)試結(jié)果如下。可見(jiàn),P3M-Net依然表現(xiàn)最優(yōu),證明了其具有很強(qiáng)的跨數(shù)據(jù)集泛化能力。
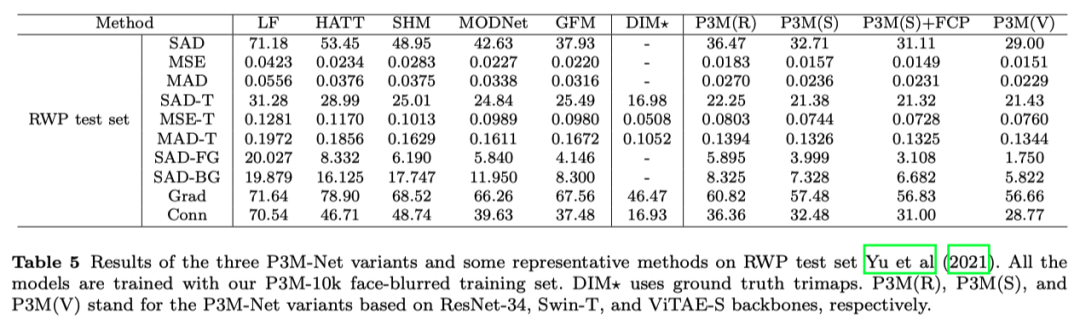
另外我們對(duì)P3M-CP 模型進(jìn)行了消融實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果證明P3M-CP在大部分模型上都能夠顯著提升對(duì)普通圖像的泛化能力,甚至達(dá)到了和在普通圖像上訓(xùn)練一致的效果。值得注意的是,P3M-Net ViTAE 模型由于自身已經(jīng)具有了優(yōu)異的泛化能力,在不加任何模塊的情況下,也能夠取得非常滿意的泛化效果。
未來(lái)我們將在模型設(shè)計(jì)和訓(xùn)練方法層面,進(jìn)一步研究隱私保護(hù)下的人像摳圖問(wèn)題。針對(duì)視頻數(shù)據(jù),研究輕量化人像摳圖模型,降低模型復(fù)雜度,提升推理速度。我們希望本項(xiàng)研究能促進(jìn)社區(qū)關(guān)注人像摳圖任務(wù)中的隱私保護(hù)問(wèn)題,并進(jìn)一步激發(fā)相關(guān)問(wèn)題的深入研究。
論文鏈接:
https://dl.acm.org/doi/10.1145/3474085.3475512
https://arxiv.org/abs/2203.16828
Github鏈接
https://github.com/JizhiziLi/P3M
https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting
參考文獻(xiàn)
THE END
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有美顏、三維視覺(jué)、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群
個(gè)人微信(如果沒(méi)有備注不拉群!) 請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱(chēng)
下載1:何愷明頂會(huì)分享
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
