
AI繪圖Stable Diffusion中關(guān)鍵技術(shù):U-Net的應(yīng)用
你好,我是郭震
引言
在人工智能和深度學(xué)習(xí)的迅猛發(fā)展下,圖像生成技術(shù)已經(jīng)取得了令人矚目的進(jìn)展。特別是,Stable Diffusion模型以其文本到圖像的生成能力吸引了廣泛關(guān)注。本文將深入探討Stable Diffusion中一個(gè)關(guān)鍵技術(shù)——U-Net架構(gòu)的應(yīng)用,揭示它如何在生成細(xì)節(jié)豐富且與文本描述緊密相連的圖像中發(fā)揮核心作用。
U-Net架構(gòu)概述
U-Net最初設(shè)計(jì)用于醫(yī)學(xué)圖像分割,其特點(diǎn)是一種對(duì)稱的編碼器-解碼器結(jié)構(gòu),中間通過(guò)跳躍連接直接傳遞特征圖。這種結(jié)構(gòu)能夠在圖像的不同層次中保留豐富的細(xì)節(jié)信息,是U-Net在圖像處理任務(wù)中表現(xiàn)出色的關(guān)鍵。
Unet提出的初衷是為了解決醫(yī)學(xué)圖像分割的問(wèn)題; 一種U型的網(wǎng)絡(luò)結(jié)構(gòu)來(lái)獲取上下文的信息和位置信息; 在2015年的ISBI cell tracking比賽中獲得了多個(gè)第一 ,一開(kāi)始這是為了解決細(xì)胞層面的分割的任務(wù)的。
這個(gè)結(jié)構(gòu)的巧妙之處,通過(guò)下面例子我們看下:
說(shuō)一開(kāi)始的圖片是224x224的,那么就會(huì)變成112x112,56x56, 28x28 ,14x14四個(gè)不同尺寸的特征。 然后我們對(duì)14x14的特征圖做上采樣或者反卷積,得到28x28的特征圖, 這個(gè)28x28的特征圖與之前的28x28的特征圖進(jìn)行通道上的拼接concat,
然后再對(duì)拼接之后的特征圖做卷積和上采樣,得到56x56的特征圖,
再與之前的56x56的特征拼接,卷積,再 上采樣,經(jīng) 過(guò)四次上采樣可以得到一個(gè)與輸入圖像尺寸相同的224x224的預(yù)測(cè)結(jié)果。
歸納下U-Net:
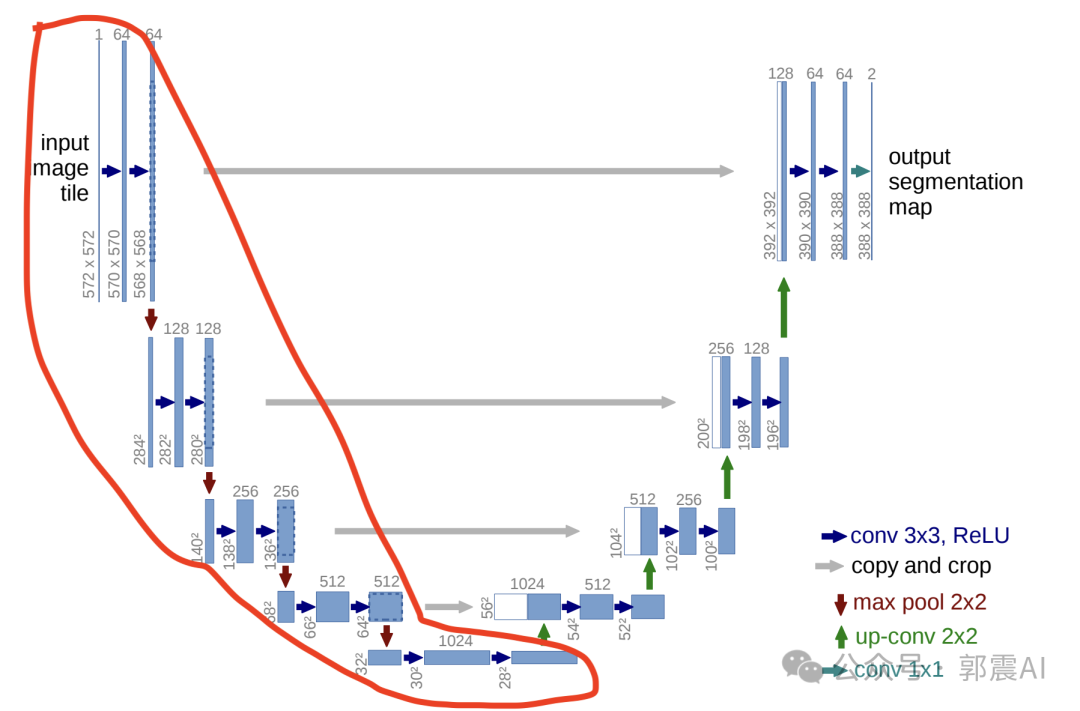
特征提取與降采樣 : 在U-Net架構(gòu)的編碼器部分,輸入圖像首先經(jīng)過(guò)一系列卷積層和池化層進(jìn)行處理,目的是提取圖像的特征并逐漸降低圖像的空間維度(尺寸)。這一過(guò)程中,圖像的尺寸會(huì)經(jīng)過(guò)幾個(gè)階段的縮減。例如,一個(gè)224x224的圖像首先降采樣為112x112,然后變?yōu)?6x56,接著是28x28,最后達(dá)到14x14。每一步降采樣都旨在捕獲圖像的高級(jí)特征,同時(shí)減少計(jì)算量。
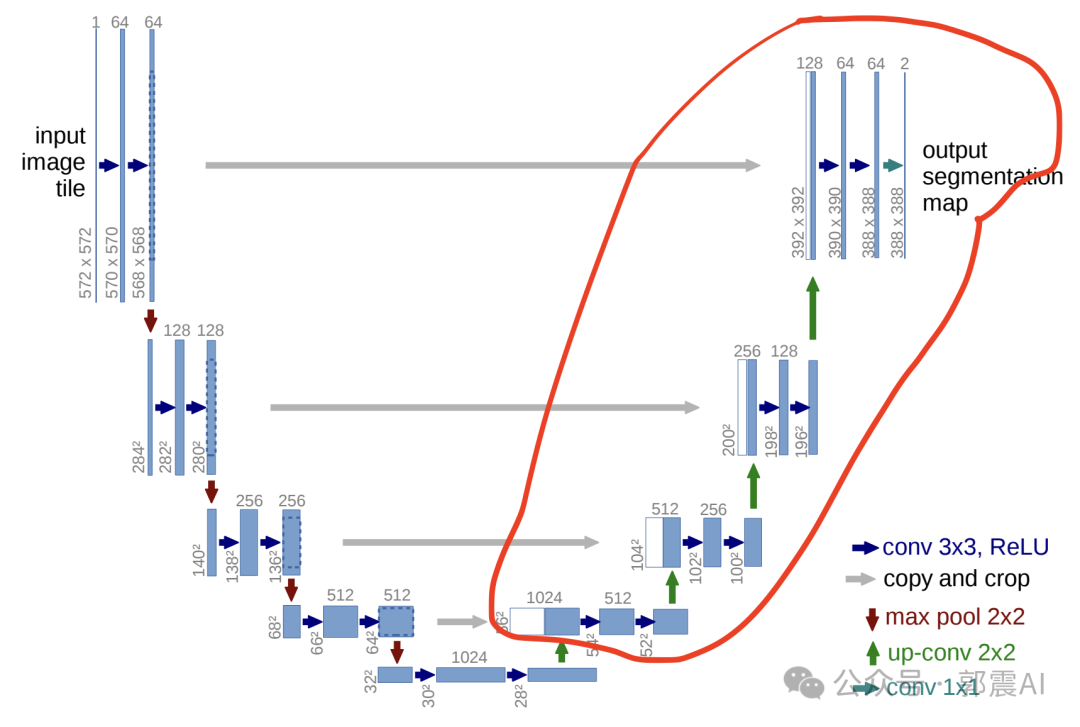
上采樣和特征融合 : 在U-Net的解碼器部分,通過(guò)上采樣(或反卷積)操作逐步恢復(fù)圖像的尺寸。這一過(guò)程不僅僅是簡(jiǎn)單地增加圖像的尺寸, 更重要的是恢復(fù)圖像的細(xì)節(jié)信息 。以14x14的特征圖為例,我們首先通過(guò)上采樣或反卷積得到28x28的特征圖。然后, 這個(gè)新生成的28x28特征圖會(huì)與編碼器階段對(duì)應(yīng)尺寸(28x28)的特征圖進(jìn)行通道上的拼接(concatenation)。這一步是U-Net架構(gòu)的關(guān)鍵,稱為“跳躍連接”(Skip Connection) 。
以下是一個(gè)簡(jiǎn)化的PyTorch代碼示例,展示如何將解碼器階段的新生成的28x28特征圖與編碼器階段相對(duì)應(yīng)尺寸的28x28特征圖進(jìn)行通道上的拼接。
import torch
import torch.nn as nn
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
# 編碼器部分
self.encoder_conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)
# 假設(shè)有更多的卷積層和池化層...
# 解碼器部分
self.decoder_conv1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, padding=1) # 注意輸入通道數(shù)是由于拼接而翻倍
# 假設(shè)有更多的卷積層...
# 上采樣
self.up_sample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def forward(self, x):
# 編碼器路徑
enc1 = F.relu(self.encoder_conv1(x))
# 假設(shè)有更多編碼器操作...
# 以下代碼跳過(guò)了中間的操作,直接到上采樣和拼接的部分
# 假設(shè)enc1是我們需要拼接的編碼器階段的28x28特征圖
# 解碼器路徑 - 上采樣
upsampled = self.up_sample(enc1) # 假設(shè)從14x14上采樣到28x28
# 解碼器卷積操作...
dec1 = F.relu(self.decoder_conv1(upsampled))
# 特征圖拼接
# 假設(shè)dec1是解碼器階段新生成的28x28特征圖
# enc1是與之拼接的編碼器階段的28x28特征圖
concat_features = torch.cat((enc1, dec1), 1) # 1表示在通道維度上拼接
# 繼續(xù)解碼器操作...
return concat_features
# 假設(shè)的輸入
input_image = torch.randn(1, 3, 224, 224) # Batch size 1, 3 channels, 224x224 pixels
model = UNet()
output_features = model(input_image)
print(output_features.shape) # 輸出拼接后的特征圖的尺寸
在PyTorch中,torch.cat函數(shù)用于沿指定維度拼接給定的張量序列。在您提到的操作 torch.cat((enc1, dec1), 1) 中,enc1 和 dec1 是兩個(gè)張量,它們將會(huì)在維度1(即通道維度)上進(jìn)行拼接。這種操作在圖像處理任務(wù)中特別常見(jiàn),尤其是在需要合并來(lái)自不同網(wǎng)絡(luò)層的特征信息時(shí)。
具體來(lái)說(shuō),這里的步驟解釋如下:
- 參數(shù)解釋:
-
(enc1, dec1):這是一個(gè)元組,包含了兩個(gè)要拼接的張量。在U-Net結(jié)構(gòu)中,enc1通常是從編碼器路徑中得到的特征圖,而dec1是解碼器路徑(可能經(jīng)過(guò)上采樣)中得到的特征圖。 -
1:這個(gè)數(shù)字指定了拼接的維度。對(duì)于一個(gè)形狀為(N, C, H, W)的張量(其中N是批量大小,C是通道數(shù),H是高度,W是寬度),維度0對(duì)應(yīng)于批量大小,維度1對(duì)應(yīng)于通道數(shù)。因此,1表明拼接發(fā)生在通道維度上,這意味著這兩個(gè)張量的高度和寬度必須相匹配,但它們的通道數(shù)可以不同。
-
- 操作結(jié)果:
- 拼接后的張量將具有相同的批量大小
N和相同的空間維度H和W,但其通道數(shù)C是兩個(gè)輸入張量通道數(shù)的和。如果enc1的形狀是(N, C1, H, W),而dec1的形狀是(N, C2, H, W),那么拼接后的張量形狀將是(N, C1+C2, H, W)。
- 拼接后的張量將具有相同的批量大小
在這個(gè)示例中,torch.cat函數(shù)用于在通道維度(dim=1)上拼接特征圖。這里的enc1和dec1代表要拼接的兩個(gè)特征圖,分別來(lái)自于U-Net的編碼器和解碼器部分。注意,在實(shí)際的U-Net實(shí)現(xiàn)中,會(huì)有多個(gè)這樣的拼接操作,對(duì)應(yīng)于不同層級(jí)的特征圖。此外,模型的其他部分,如更多的卷積層、池化層、激活函數(shù)等,在這里為了簡(jiǎn)化被省略了。
跳躍連接的作用: 跳躍連接的主要作用是將編碼器階段捕獲的高級(jí)別、全局特征與解碼器階段的局部、細(xì)節(jié)特征結(jié)合起來(lái)。 這種結(jié)合幫助模型在恢復(fù)圖像尺寸的同時(shí),也能夠精確地恢復(fù)圖像的細(xì)節(jié)和結(jié)構(gòu),這對(duì)于圖像分割和生成任務(wù)至關(guān)重要 。
通過(guò)這種方式,U-Net能夠有效地處理和生成高質(zhì)量的圖像, 不僅保留了圖像的全局信息,也精確地恢復(fù)了局部細(xì)節(jié) ,從而在許多圖像處理任務(wù)中實(shí)現(xiàn)了優(yōu)異的性能。
Stable Diffusion是一種先進(jìn)的文本到圖像生成模型,它能夠根據(jù)簡(jiǎn)短的文本提示生成復(fù)雜、高質(zhì)量的圖像。其核心在于理解文本的含義,并轉(zhuǎn)化為視覺(jué)內(nèi)容,這一過(guò)程中U-Net的架構(gòu)扮演了至關(guān)重要的角色。
U-Net在Stable Diffusion中的應(yīng)用
- 細(xì)節(jié)的捕捉與增強(qiáng):Stable Diffusion利用U-Net的跳躍連接來(lái)維持和增強(qiáng)圖像的細(xì)節(jié)。這些連接允許在生成過(guò)程中直接使用來(lái)自編碼器的高分辨率特征,從而在解碼器階段細(xì)化圖像的細(xì)節(jié)。
- 多尺度特征融合:通過(guò)U-Net的編碼器-解碼器結(jié)構(gòu),Stable Diffusion能夠融合不同尺度的特征,這對(duì)于生成與文本描述相匹配的復(fù)雜圖像至關(guān)重要。這種結(jié)構(gòu)使模型能夠在保持全局一致性的同時(shí),精確控制圖像的局部細(xì)節(jié)。
- 迭代細(xì)化:Stable Diffusion在圖像生成過(guò)程中采用迭代細(xì)化的策略,每一步都利用U-Net架構(gòu)對(duì)圖像進(jìn)行進(jìn)一步的優(yōu)化和細(xì)化。這種方式使得最終生成的圖像不僅細(xì)節(jié)豐富,而且與輸入的文本描述高度一致。
結(jié)語(yǔ)
U-Net在Stable Diffusion中的應(yīng)用不僅展示了其在圖像分割之外的廣泛適用性,也體現(xiàn)了在復(fù)雜的圖像生成任務(wù)中對(duì)細(xì)節(jié)和質(zhì)量的極致追求。通過(guò)深入分析U-Net架構(gòu)如何在Stable Diffusion中發(fā)揮作用,我們不僅能夠更好地理解這一先進(jìn)模型的內(nèi)部機(jī)制,還能夠激發(fā)出更多創(chuàng)新的應(yīng)用思路,推動(dòng)人工智能技術(shù)在圖像生成領(lǐng)域的發(fā)展。閱讀更多:https://zglg.work