
特征工程的這些基本功你都會(huì)了嗎
1引言
特征是什么?為什么需要工程設(shè)計(jì)?
基本上,所有機(jī)器學(xué)習(xí)算法都是將一些輸入數(shù)據(jù)轉(zhuǎn)化為輸出。這些輸入數(shù)據(jù)包括若干特征,通常是以由列組成的表格形式出現(xiàn)。
而算法往往要求輸入具有某些特性的特征才能正常工作。因此,出現(xiàn)了對(duì)特征工程的需求。
特征工程至少有兩個(gè)目標(biāo),
構(gòu)建適合機(jī)器學(xué)習(xí)算法要求的輸入數(shù)據(jù)。 改善機(jī)器學(xué)習(xí)模型的性能。
根據(jù)《福布斯》的一項(xiàng)調(diào)查,數(shù)據(jù)科學(xué)家把 80% 左右的時(shí)間花在數(shù)據(jù)收集、清晰以及預(yù)處理等數(shù)據(jù)準(zhǔn)備上。
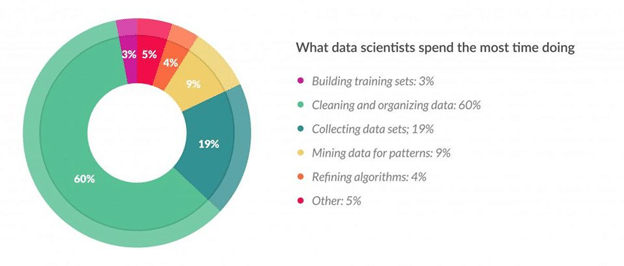
這點(diǎn)顯示了特征工程在數(shù)據(jù)科學(xué)中的重要性。因此有必要整理一下特征工程的主要技術(shù)。本篇通過(guò) Pandas 和 Numpy 等庫(kù)來(lái)實(shí)際操練。
import?pandas?as?pd
import?numpy?as?np
獲得特征工程專業(yè)知識(shí)的最佳方法是對(duì)各種數(shù)據(jù)集試驗(yàn)不同的技術(shù),并觀察其對(duì)模型性能的影響。
本文主要介紹以下幾個(gè)方面,
1、數(shù)據(jù)插補(bǔ) 2、處理異常值 3、分箱操作 4、對(duì)數(shù)轉(zhuǎn)換 5、獨(dú)熱編碼 6、分組操作 7、特征拆分 8、縮放操作 9、日期處理
2數(shù)據(jù)插補(bǔ)
缺失值是為機(jī)器學(xué)習(xí)準(zhǔn)備數(shù)據(jù)時(shí)可能遇到的最常見(jiàn)問(wèn)題之一。缺少值的原因可能是人為錯(cuò)誤、數(shù)據(jù)流中斷、隱私問(wèn)題等。無(wú)論是什么原因,缺少值都會(huì)影響機(jī)器學(xué)習(xí)模型的性能。
一般來(lái)說(shuō),機(jī)器學(xué)習(xí)算法不接受包含缺失值的輸入,而有一些機(jī)器學(xué)習(xí)平臺(tái)會(huì)自動(dòng)刪除包含缺失值的行,但這樣做往往會(huì)降低模型性能。
處理缺失值的最簡(jiǎn)單方案是刪除行或整個(gè)列。沒(méi)有最佳的刪除閾值,但是可以使用 70% 作為閾值,并嘗試刪除缺失值高于此閾值的行和列。
threshold?=?0.7
#?Dropping?columns?with?missing?value?rate?higher?than?threshold
data?=?data[data.columns[data.isnull().mean()?
#?Dropping?rows?with?missing?value?rate?higher?than?threshold
data?=?data.loc[data.isnull().mean(axis=1)?.數(shù)值插補(bǔ)
缺失值插補(bǔ)法,與缺失值刪除法比較起來(lái)是一個(gè)更好的選擇,至少它可以保持?jǐn)?shù)據(jù)的規(guī)模不變。但是,插補(bǔ)法需要考慮插補(bǔ)什么值。
首先,你可以考慮列中缺失的默認(rèn)值。例如,你有一列僅有 1 和 nan,行中的 nan 可能就是 0。另一個(gè)例子,你有一個(gè)列表示上個(gè)月客戶訪問(wèn)的次數(shù),缺失值可能也是 0。
產(chǎn)生缺失值的另一個(gè)原因是在連接大小不同的表時(shí)格引入的,此時(shí)插補(bǔ) 0 也可能是個(gè)合理的做法。
除了用默認(rèn)值插補(bǔ)缺失值外,還有一個(gè)比較有效的做法就是使用列的中位數(shù)插補(bǔ)缺失值,而不是平均值,因?yàn)橹形粩?shù)比均值更為穩(wěn)健。
#?Filling?all?missing?values?with?0
data?=?data.fillna(0)
#?Filling?missing?values?with?medians?of?the?columns
data?=?data.fillna(data.median())
.類別插補(bǔ)
用列中出現(xiàn)次數(shù)最多的值替換缺失值是處理類別型數(shù)據(jù)時(shí)的一個(gè)不錯(cuò)的選擇。但是,如果該列中的值是均勻分布的,則使用 Other 類別插補(bǔ)可能更加合理。
#?Max?fill?function?for?categorical?columns
data['column_name'].fillna(data['column_name'].value_counts().idxmax(),?inplace=True)
3處理異常值
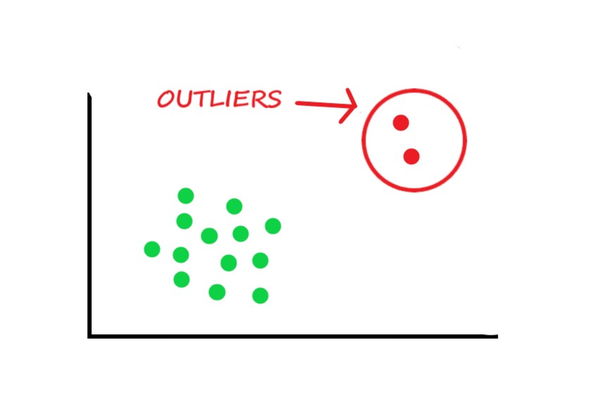
在提到如何處理異常值之前,檢測(cè)異常值的最佳方法是直觀地展示數(shù)據(jù)。所有其他統(tǒng)計(jì)方法都容易犯錯(cuò)誤,而將異常值可視化則有機(jī)會(huì)進(jìn)行高精度的決策。
正如我所提到的,統(tǒng)計(jì)方法不夠精確,但另一方面,它們卻具有優(yōu)勢(shì),而且速度很快。在這里,我將列出兩種處理異常值的不同方法。這些將使用標(biāo)準(zhǔn)差和百分位來(lái)檢測(cè)異常值。
.基于標(biāo)準(zhǔn)差的異常值檢測(cè)
如果某個(gè)值與平均值的距離大于
#?Dropping?the?outlier?rows?with?standard?deviation
factor?=?3
upper_lim?=?data['column'].mean?()?+?data['column'].std?()?*?factor
lower_lim?=?data['column'].mean?()?-?data['column'].std?()?*?factor
data?=?data[(data['column']?'column']?>?lower_lim)]
此外,可以使用
.基于百分位的異常值檢測(cè)
檢測(cè)異常值的另一種統(tǒng)計(jì)方法是使用百分位。你可以從頂部或底部劃分某些區(qū)間中的值作為異常值。這再次需要設(shè)置百分比這個(gè)閾值,這取決于數(shù)據(jù)分布。
此外,一個(gè)常見(jiàn)的錯(cuò)誤是根據(jù)數(shù)據(jù)范圍使用百分位。換句話說(shuō),如果你的數(shù)據(jù)范圍是 0 到 100,則前 5% 的值不是 96 到 100 之間的值。這里的前 5% 表示值不在數(shù)據(jù)量的第 95 個(gè)百分點(diǎn)之內(nèi)。
#?Dropping?the?outlier?rows?with?Percentiles
upper_lim?=?data['column'].quantile(.95)
lower_lim?=?data['column'].quantile(.05)
data?=?data[(data['column']?'column']?>?lower_lim)]
.設(shè)限與丟棄
處理異常值的另一種方法是將其設(shè)置為上限,而不是丟棄。這樣做可以保留數(shù)據(jù)規(guī)模,并且對(duì)于最終模型性能來(lái)說(shuō)可能會(huì)更好。
另一方面,設(shè)上限封頂可能會(huì)影響數(shù)據(jù)的分布,因此也不要過(guò)于吹捧它。
#?Capping?the?outlier?rows?with?Percentiles
upper_lim?=?data['column'].quantile(.95)
lower_lim?=?data['column'].quantile(.05)
data.loc[(df[column]?>?upper_lim),?column]?=?upper_lim
data.loc[(df[column]?4分箱
分箱可以應(yīng)用于類別型數(shù)據(jù)和數(shù)值型數(shù)據(jù)。
#?Numerical?Binning?Example
Value??????Bin???????
0-30???->??Low???????
31-70??->??Mid???????
71-100?->??High
#?Categorical?Binning?Example
Value??????Bin???????
Spain??->??Europe??????
Italy??->??Europe???????
Chile??->??South?America
Brazil?->??South?America
分箱的主要?jiǎng)訖C(jī)是使模型更加健壯并防止過(guò)擬合,但同時(shí)也會(huì)降低性能。每次分箱不僅會(huì)犧牲信息,也會(huì)使得數(shù)據(jù)更加規(guī)范化。
性能與過(guò)擬合之間的權(quán)衡是分箱過(guò)程的關(guān)鍵。
對(duì)于數(shù)值型特征,除了一些明顯的過(guò)擬合的情況外,分箱對(duì)于某種算法可能是多余的,因?yàn)樗鼘?duì)模型性能有影響。 然而,對(duì)于類別型特征,低頻標(biāo)簽可能會(huì)對(duì)統(tǒng)計(jì)模型的魯棒性產(chǎn)生負(fù)面影響。因此,為這些不太頻繁的值分配一般類別有助于保持模型的魯棒性。例如,數(shù)據(jù)大小為 100,000 行,則將計(jì)數(shù)少于 100 的標(biāo)簽合并到 Other之類的新類別可能是一個(gè)不錯(cuò)的選擇。
#?Numerical?Binning?Example
data['bin']?=?pd.cut(data['value'],?bins=[0,30,70,100],?labels=["Low",?"Mid",?"High"])
???value???bin
0??????2???Low
1?????45???Mid
2??????7???Low
3?????85??High
4?????28???Low
#?Categorical?Binning?Example
?????Country
0??????Spain
1??????Chile
2??Australia
3??????Italy
4?????Brazil
conditions?=?[
????data['Country'].str.contains('Spain'),
????data['Country'].str.contains('Italy'),
????data['Country'].str.contains('Chile'),
????data['Country'].str.contains('Brazil')]
choices?=?['Europe',?'Europe',?'South?America',?'South?America']
data['Continent']?=?np.select(conditions,?choices,?default='Other')
?????Country??????Continent
0??????Spain?????????Europe
1??????Chile??South?America
2??Australia??????????Other
3??????Italy?????????Europe
4?????Brazil??South?America
5Log 對(duì)數(shù)變換
對(duì)數(shù)變換是特征工程中最常用的數(shù)學(xué)變換之一,它的好處有,
它有助于處理偏度不為 0 的數(shù)據(jù),并且在轉(zhuǎn)換后,分布變得更接近正態(tài)分布。 在大多數(shù)情況下,數(shù)據(jù)的數(shù)量級(jí)在不同范圍內(nèi)是不同的。例如,年齡 15 和 20 之間的數(shù)量差異并不等于年齡 65 和 70 之間的數(shù)量差異。就年份而言,是的,它們是相同的,但是對(duì)于其他方面,年輕年齡的 5 年差異意味著更高的數(shù)量差異。這種類型的數(shù)據(jù)來(lái)自乘性過(guò)程,對(duì)數(shù)變換將起到規(guī)范化(normalize)數(shù)量差異的作用。
由于數(shù)量差異的歸一化,模型變得更加健壯,因此它也減少了異常值的影響。
需要注意的是,你要應(yīng)用對(duì)數(shù)變換的數(shù)據(jù)必須是正值,否則會(huì)出現(xiàn)錯(cuò)誤。另外,可以在轉(zhuǎn)換數(shù)據(jù)之前將 1 加到數(shù)據(jù)中,用于確保變換后的輸出值也是正的。
Log(x+1)
#?Log?Transform?Example
data?=?pd.DataFrame({'value':[2,45,?-23,?85,?28,?2,?35,?-12]})
data['log+1']?=?(data['value']+1).transform(np.log)
#?Negative?Values?Handling
#?Note?that?the?values?are?different
data['log']?=?(data['value']-data['value'].min()+1)?.transform(np.log)
???value??log(x+1)??log(x-min(x)+1)
0??????2???1.09861??????????3.25810
1?????45???3.82864??????????4.23411
2????-23???????nan??????????0.00000
3?????85???4.45435??????????4.69135
4?????28???3.36730??????????3.95124
5??????2???1.09861??????????3.25810
6?????35???3.58352??????????4.07754
7????-12???????nan??????????2.48491
6獨(dú)熱編碼
獨(dú)熱編碼是機(jī)器學(xué)習(xí)中最常見(jiàn)的編碼方法之一。此方法將一列中的值分布到多個(gè)標(biāo)記列,并為其分配 0 或 1。這些二進(jìn)制值表示類別和編碼之間的關(guān)系。
該方法將算法難以正確理解的分類型數(shù)據(jù)更改為數(shù)值格式,并使你可以在不丟失任何信息的情況下對(duì)類別數(shù)據(jù)進(jìn)行分組。
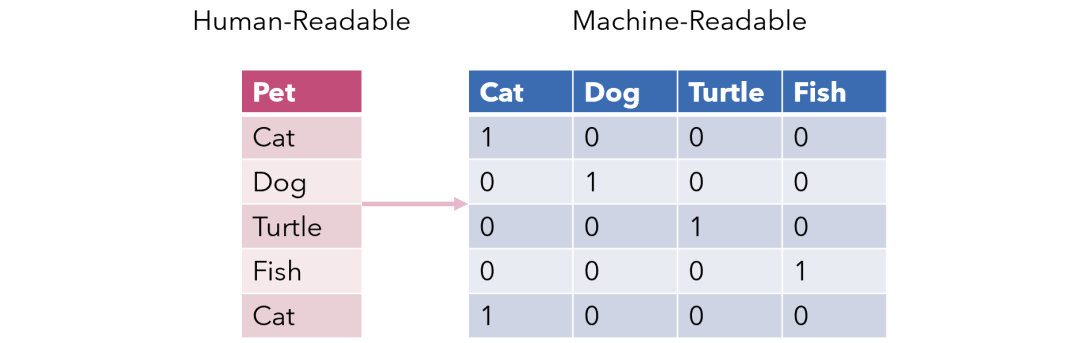
.Why 獨(dú)熱編碼?
如果該列中有 N 個(gè)不同的值,則將它們映射到 N-1 個(gè)二進(jìn)制列就足夠了,因?yàn)榭梢詮钠渌兄锌鄢撊笔е怠H绻覀兪种械乃辛卸嫉扔?0,則缺失值必須等于 1。這就是為什么將其稱為獨(dú)熱編碼的原因。但是,我將使用 Pandas 的 get_dummies 函數(shù)給出一個(gè)示例,此函數(shù)將一列映射到多個(gè)列。
encoded_columns?=?pd.get_dummies(data['column'])
data?=?data.join(encoded_columns).drop('column',?axis=1)
7分組操作
在大多數(shù)機(jī)器學(xué)習(xí)算法中,每個(gè)實(shí)例對(duì)應(yīng)訓(xùn)練數(shù)據(jù)集中的一行,而不同列對(duì)應(yīng)不同特征。這種形式的數(shù)據(jù)稱為整齊(tidy)數(shù)據(jù)。
整齊數(shù)據(jù)集易于操作、建模和可視化,并具有特定的結(jié)構(gòu): 每個(gè)變量是一列,每個(gè)觀察值是一行,每種類型的觀察單位是表格。
諸如涉及事務(wù)處理之類的數(shù)據(jù)集由于一個(gè)實(shí)例對(duì)應(yīng)多行數(shù)據(jù)而很少適合整齊數(shù)據(jù)的定義。在這種情況下,我們按實(shí)例對(duì)數(shù)據(jù)進(jìn)行分組,然后每個(gè)實(shí)例僅由一行代表。
按操作分組的關(guān)鍵是確定特征的聚合函數(shù)。對(duì)于數(shù)值型特征,平均值和求和函數(shù)通常是不錯(cuò)的選擇,而對(duì)于分類型特征,則較為復(fù)雜。
.分類特征分組
建議使用三種不同的方式來(lái)聚合分類特征:
第一種是選擇頻率最高的標(biāo)簽。換句話說(shuō),這是分類特征的 max 操作,但是普通的 max 函數(shù)通常不返回此值,因此你需要自己定義,例如使用 lambda 函數(shù)。
data.groupby('id').agg(lambda?x:?x.value_counts().index[0])
第二種選擇是制作數(shù)據(jù)透視表(pivot table)。這種方法與上一步驟中的編碼方法類似,略有不同。代替二值符號(hào),可以將其定義為分組列和編碼列之間的值的聚合函數(shù)。如果你打算超越二值標(biāo)記列并將多重特征合并為更有用的聚合特征,那么這將是一個(gè)不錯(cuò)的選擇。(該方法與 Pandas 中另一個(gè)函數(shù) groupby 作用類似,可以結(jié)合下圖例子來(lái)理解這一點(diǎn)。)
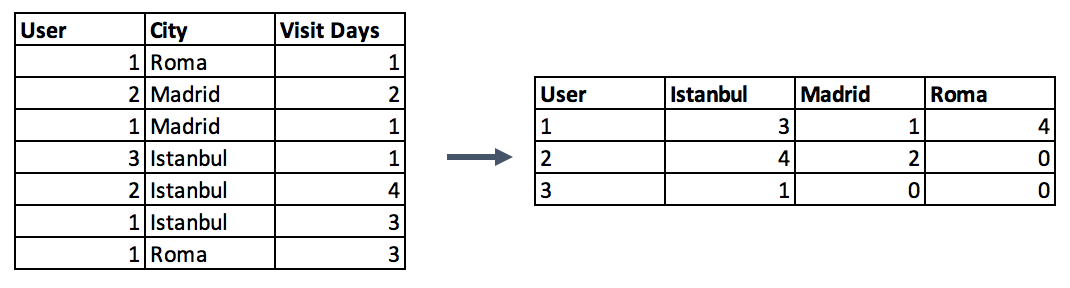
#?Pivot?table?Pandas?Example
data.pivot_table(index='column_to_group',?columns='column_to_encode',?values='aggregation_column',?aggfunc=np.sum,?fill_value?=?0)
最后一種分類特征分組方案是在應(yīng)用獨(dú)熱編碼后應(yīng)用分組函數(shù) group by。此方法將保留所有數(shù)據(jù)(在上面第一種方案中,會(huì)丟失一些數(shù)據(jù))。與此同時(shí),還將編碼列從分類轉(zhuǎn)換為數(shù)值。可以閱讀下一部分以了解數(shù)值特征分組的說(shuō)明。
.數(shù)值特征分組
在大多數(shù)情況下,數(shù)值特征使用求和以及均值函數(shù)分組。根據(jù)特征的含義,兩者都是可取的。例如,如果要獲取比率列,則可以取二值列的平均值。在同一示例中,sum 函數(shù)可用于獲得總數(shù)。
#?sum_cols:?List?of?columns?to?sum
#?mean_cols:?List?of?columns?to?average
grouped?=?data.groupby('column_to_group')
sums?=?grouped[sum_cols].sum().add_suffix('_sum')
avgs?=?grouped[mean_cols].mean().add_suffix('_avg')
new_df?=?pd.concat([sums,?avgs],?axis=1)
8特征拆分
拆分特征是使它們?cè)跈C(jī)器學(xué)習(xí)中發(fā)揮作用的好辦法。很多時(shí)候,數(shù)據(jù)集包含一些字符串列,這就違反了整齊數(shù)據(jù)的原則。通過(guò)將列的可用部分提取成新特征,有利于
讓機(jī)器學(xué)習(xí)算法能夠理解它們。 可以將它們分箱和分組。
通過(guò)發(fā)掘潛在信息來(lái)提高模型性能。
split 函數(shù)是一個(gè)不錯(cuò)的選擇,但是,沒(méi)有一種適用于拆分所有特征的通用方法。它取決于列的特性以及如何拆分它。讓我們通過(guò)兩個(gè)示例對(duì)其進(jìn)行介紹。
首先,一個(gè)可用于拆分普通名字列的簡(jiǎn)單 split 函數(shù),
data.name
0??Luther?N.?Gonzalez
1????Charles?M.?Young
2????????Terry?Lawson
3???????Kristen?White
4??????Thomas?Logsdon
#?Extracting?first?names
data.name.str.split("?").map(lambda?x:?x[0])
0?????Luther
1????Charles
2??????Terry
3????Kristen
4?????Thomas
#?Extracting?last?names
data.name.str.split("?").map(lambda?x:?x[-1])
0????Gonzalez
1???????Young
2??????Lawson
3???????White
4?????Logsdon
上面的示例通過(guò)僅使用第一個(gè)和最后一個(gè)詞來(lái)處理長(zhǎng)度超過(guò)兩個(gè)單詞的名字,這使該函數(shù)在遇到極端情況時(shí)具有魯棒性,在處理此類字符串時(shí)應(yīng)考慮到這一方法。
split 函數(shù)的另一個(gè)使用場(chǎng)景是提取兩個(gè)字符之間的字符串部分。以下示例顯示了通過(guò)在一行代碼中連續(xù)使用兩個(gè) split 函數(shù)來(lái)實(shí)現(xiàn)此情況的方法。
#?String?extraction?example
data.title.head()
0??????????????????????Toy?Story?(1995)
1????????????????????????Jumanji?(1995)
2???????????????Grumpier?Old?Men?(1995)
3??????????????Waiting?to?Exhale?(1995)
4????Father?of?the?Bride?Part?II?(1995)
data.title.str.split("(",?n=1,?expand=True)[1].str.split(")",?n=1,?expand=True)[0]
0????1995
1????1995
2????1995
3????1995
4????1995
9縮放
在大多數(shù)情況下,數(shù)據(jù)集的數(shù)值特征沒(méi)有特定范圍,并且彼此不同。在實(shí)際中,如果要求年齡列和收入列具有相同的數(shù)值范圍肯定會(huì)讓人覺(jué)得沒(méi)道理。但是如果站在機(jī)器學(xué)習(xí)的角度來(lái)看的話,該如何比較這兩個(gè)數(shù)值特征呢?
縮放解決了這個(gè)問(wèn)題。經(jīng)過(guò)縮放過(guò)程后,連續(xù)特征的范圍變得相同。對(duì)于許多算法來(lái)說(shuō),此過(guò)程不是強(qiáng)制性的,但應(yīng)用起來(lái)效果可能很好。但是,基于距離計(jì)算的算法(例如 k-NN 或 k-Means)需要具有可縮放的連續(xù)特征作為模型輸入。
有兩種基本的數(shù)據(jù)縮放方式。
.歸一化
歸一化(或 min-max 歸一化)在 0 到 1 之間的固定范圍內(nèi)縮放所有值。
此變換不會(huì)更改特征的分布,并且由于標(biāo)準(zhǔn)差降低,異常值的影響會(huì)增加。因此,建議在該歸一化之前處理異常值。
data?=?pd.DataFrame({'value':[2,45,?-23,?85,?28,?2,?35,?-12]})
data['normalized']?=?(data['value']?-?data['value'].min())?/?(data['value'].max()?-?data['value'].min())
???value??normalized
0??????2????????0.23
1?????45????????0.63
2????-23????????0.00
3?????85????????1.00
4?????28????????0.47
5??????2????????0.23
6?????35????????0.54
7????-12????????0.10
.標(biāo)準(zhǔn)化
標(biāo)準(zhǔn)化(或 z-分?jǐn)?shù)規(guī)范化)在考慮標(biāo)準(zhǔn)差的同時(shí)縮放特征值。如果特征的標(biāo)準(zhǔn)差不同,則它們的范圍也將彼此不同。這減少了特征中異常值的影響。
在以下標(biāo)準(zhǔn)化公式中,
data?=?pd.DataFrame({'value':[2,45,?-23,?85,?28,?2,?35,?-12]})
data['standardized']?=?(data['value']?-?data['value'].mean())?/?data['value'].std()
???value??standardized
0??????2?????????-0.52
1?????45??????????0.70
2????-23?????????-1.23
3?????85??????????1.84
4?????28??????????0.22
5??????2?????????-0.52
6?????35??????????0.42
7????-12?????????-0.92
10提取日期
盡管日期列通常給有關(guān)模型目標(biāo)值提供了很多有用信息,但它們?cè)跈C(jī)器學(xué)習(xí)學(xué)習(xí)中往往被忽略。日期可以以多種格式顯示,這使得算法很難理解,即使將日期簡(jiǎn)化為 01-01-2017 之類的格式也是如此。
如果不處理日期列,那么在這些值之間建立序數(shù)關(guān)系對(duì)于機(jī)器學(xué)習(xí)算法來(lái)說(shuō)是非常具有挑戰(zhàn)性的。在這里,建議對(duì)日期進(jìn)行三種預(yù)處理,
將日期部分提取到不同的列中: 年、月、日等。 根據(jù)年、月、日等提取當(dāng)前日期和這些列之間的時(shí)間差。
從日期中提取一些特定特征: 工作日的名稱,是否周末、是否休假等。
如果將日期列按上述方法提取出新的列,則它們的信息將會(huì)被更合理地表達(dá)出來(lái),并且機(jī)器學(xué)習(xí)算法可以輕松地理解它們。
from?datetime?import?date
data?=?pd.DataFrame({'date':
['01-01-2017',
'04-12-2008',
'23-06-1988',
'25-08-1999',
'20-02-1993',
]})
#?Transform?string?to?date
data['date']?=?pd.to_datetime(data.date,?format="%d-%m-%Y")
#?Extracting?Year
data['year']?=?data['date'].dt.year
#?Extracting?Month
data['month']?=?data['date'].dt.month
#?Extracting?passed?years?since?the?date
data['passed_years']?=?date.today().year?-?data['date'].dt.year
#?Extracting?passed?months?since?the?date
data['passed_months']?=?(date.today().year?-?data['date'].dt.year)?*?12?+?date.today().month?-?data['date'].dt.month
#?Extracting?the?weekday?name?of?the?date
data['day_name']?=?data['date'].dt.day_name()
????????date??year??month??passed_years??passed_months???day_name
0?2017-01-01??2017??????1?????????????2?????????????26?????Sunday
1?2008-12-04??2008?????12????????????11????????????123???Thursday
2?1988-06-23??1988??????6????????????31????????????369???Thursday
3?1999-08-25??1999??????8????????????20????????????235??Wednesday
4?1993-02-20??1993??????2????????????26????????????313???Saturday

?英文鏈接?
Emre Ren?bero?lu: https://towardsdatascience.com/feature-engineering-for-machine-learning-3a5e293a5114