文末贈書福利
張量核心、顯存帶寬、16位能力……各種紛繁復雜的GPU參數(shù)讓人眼花繚亂,到底怎么選?從不到1000元1050 Ti到近30000元的Titan V,GPU價格的跨度這么大,該從何價位下手?誰才是性價比之王?讓GPU執(zhí)行不同的任務,最佳選擇也隨之變化,用于計算機視覺和做NLP就不太一樣。而且,用云端TPU、GPU行不行?和本地GPU在處理任務時應該如何分配,才能更省錢?現(xiàn)在,為了幫你找到最適合的裝備,華盛頓大學的博士生Tim Dettmers將對比凝練成實用攻略,最新的模型和硬件也考慮在內(nèi)。文末還附有一份特別精簡的GPU選購建議,歡迎對號入座。
???最重要的參數(shù)
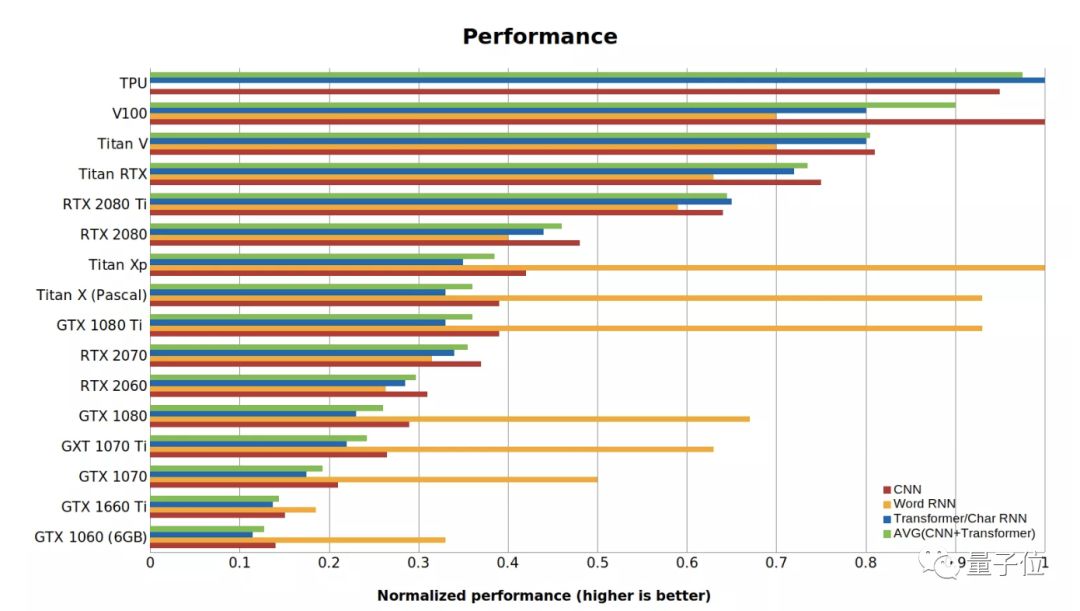
針對不同深度學習架構(gòu),GPU參數(shù)的選擇優(yōu)先級是不一樣的,總體來說分兩條路線:卷積網(wǎng)絡和Transformer:張量核心>FLOPs(每秒浮點運算次數(shù))>顯存帶寬>16位浮點計算能力循環(huán)神經(jīng)網(wǎng)絡:顯存帶寬>16位浮點計算能力>張量核心>FLOPs在說清楚哪個GPU參數(shù)對速度尤為重要之前,先看看兩個最重要的張量運算:矩陣乘法和卷積。舉個栗子?,以運算矩陣乘法A×B=C為例,將A、B復制到顯存上比直接計算A×B更耗費資源。也就是說,如果你想用LSTM等處理大量小型矩陣乘法的循環(huán)神經(jīng)網(wǎng)絡,顯存帶寬是GPU最重要的屬性。相反,卷積運算受計算速度的約束比較大。因此,要衡量GPU運行ResNets等卷積架構(gòu)的性能,最佳指標就是FLOPs。張量核心可以明顯增加FLOPs。Transformer中用到的大型矩陣乘法介于卷積運算和RNN的小型矩陣乘法之間,16位存儲、張量核心和TFLOPs都對大型矩陣乘法有好處,但它仍需要較大的顯存帶寬。需要特別注意,如果想借助張量核心的優(yōu)勢,一定要用16位的數(shù)據(jù)和權(quán)重,避免使用RTX顯卡進行32位運算!下面Tim總結(jié)了一張GPU和TPU的標準性能數(shù)據(jù),值越高代表性能越好。RTX系列假定用了16位計算,Word RNN數(shù)值是指長度<100的段序列的biLSTM性能。這項基準測試是用PyTorch 1.0.1和CUDA 10完成的。△?GPU和TPU的性能數(shù)據(jù)
???性價比分析
性價比可能是選擇一張GPU最重要的考慮指標。在攻略中,小哥進行了如下運算測試各顯卡的性能:用語言模型Transformer-XL和BERT進行Transformer性能的基準測試。
用最先進的biLSTM進行了單詞和字符級RNN的基準測試。
上述兩種測試是針對Titan Xp、Titan RTX和RTX 2080 Ti進行的,對于其他GPU則線性縮放了性能差異。
借用了現(xiàn)有的CNN基準測試。
用了亞馬遜和eBay上顯卡的平均售價作為GPU的參考成本。
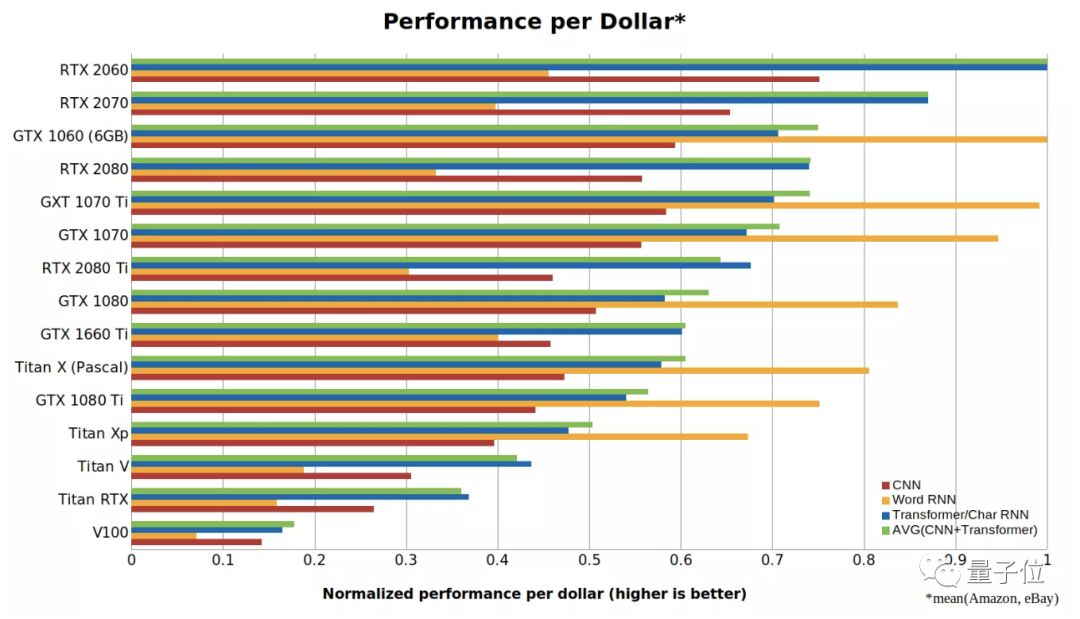
最后,可以得出CNN、RNN和Transformer的歸一化性能/成本比值,如下所示:△?CNN、RNN和Transformer的每美元性能
在上面這張圖中,數(shù)字越大代表每一美元能買到的性能越強。可以看出, RTX 2060比RTX 2070,RTX 2080或RTX 2080 Ti更具成本效益,甚至是Tesla V100性價比的5倍以上。所以此輪的性價比之王已經(jīng)確定,是RTX 2060無疑了。不過,這種考量方式更偏向于小型GPU,且因為游戲玩家不喜歡RTX系列顯卡,導致GTX 10xx系列的顯卡售價虛高。此外,還存在一定的單GPU偏差,一臺有4個RTX 2080 Ti的計算機比兩臺帶8個RTX 2060的計算機性價比更高。???所需顯存與16位訓練
GPU的顯存對某些應用至關(guān)重要,比如常見的計算機視覺、機器翻譯和一部分NLP應用。可能你認為RTX 2070具有成本效益,但需要注意其顯存很小,只有8 GB。通過16位訓練,你可以擁有幾乎16位的顯存,相當于將顯存翻了一倍,這個方法對RTX 2080和RTX 2080 Ti同樣適用。也就是說,16位計算可以節(jié)省50%的內(nèi)存,16位 8GB顯存大小與12GB 32位顯存大小相當。???云端or本地?TPU or GPU?
搞清楚了參數(shù),還有更眼花繚亂的選項擺在面前:谷歌云、亞馬遜AWS、微軟的云計算平臺都能搞機器學習,是不是可以不用自己買GPU?英偉達、AMD、英特爾、各種創(chuàng)業(yè)公司……AI加速芯片也有不少品牌可選。面對整個行業(yè)的圍攻,Tim分析了各家平臺的優(yōu)缺點。英偉達
英偉達無疑是深度學習硬件領(lǐng)域的領(lǐng)導者,大多數(shù)深度學習庫都對英偉達GPU提供最佳支持。而AMD的OpenCL沒有這樣強大的標準庫。軟件是英偉達GPU非常強大的一部分。在過去的幾個月里,NVIDIA還在為軟件注入更多資源。例如,Apex庫對PyTorch中的16位梯度提供支持,還包括像FusedAdam這樣的融合快速優(yōu)化器。但是英偉達現(xiàn)在有一項非常坑爹的政策,如果在數(shù)據(jù)中心使用CUDA,那么只允許使用Tesla GPU而不能用GTX或RTX GPU。由于擔心法律問題,研究機構(gòu)和大學經(jīng)常被迫購買低性價比的Tesla GPU。然而,Tesla與GTX和RTX相比并沒有真正的優(yōu)勢,價格卻高出10倍。AMD
AMD GPU性能強大但是軟件太弱。雖然有ROCm可以讓CUDA轉(zhuǎn)換成可移植的C++代碼,但是問題在于,移植TensorFlow和PyTorch代碼庫很難,這大大限制了AMD GPU的應用。TensorFlow和PyTorch對AMD GPU有一定的支持,所有主要的網(wǎng)絡都可以在AMD GPU上運行,但如果想開發(fā)新的網(wǎng)絡,可能有些細節(jié)會不支持。對于那些只希望GPU能夠順利運行的普通用戶,Tim并不推薦AMD。但是支持AMD GPU和ROCm開發(fā)人員,會有助于打擊英偉達的壟斷地位,將使每個人長期受益。英特爾
Tim曾經(jīng)嘗試過至強融核(Xeon Phi)處理器,但體驗讓人失望。英特爾目前還不是英偉達或AMD GPU真正的競爭對手。至強融核對深度學習的支持比較差,不支持一些GPU的設計特性,編寫優(yōu)化代碼困難,不完全支持C++ 11的特性,與NumPy和SciPy的兼容性差。英特爾曾計劃在今年下半年推出神經(jīng)網(wǎng)絡處理器(NNP),希望與GPU和TPU競爭,但是該項目已經(jīng)跳票。谷歌
谷歌TPU已經(jīng)發(fā)展成為一種非常成熟的云端產(chǎn)品。你可以這樣簡單理解TPU:把它看做打包在一起的多個專用GPU,它只有一個目的——進行快速矩陣乘法。如果看一下具有張量核心的V100 GPU與TPUv2的性能指標,可以發(fā)現(xiàn)兩個系統(tǒng)的性能幾乎相同。TPU本身支持TensorFlow,對PyTorch的支持也在試驗中。TPU在訓練大型Transformer GPT-2上取得了巨大的成功,BERT和機器翻譯模型也可以在TPU上高效地進行訓練,速度相比GPU大約快56%。但是TPU也并非沒有問題,有些文獻指出在TPUv2上使用LSTM沒有收斂。TPU長時間使用時還面臨著累積成本的問題。TPU具有高性能,最適合在訓練階段使用。在原型設計和推理階段,應該依靠GPU來降低成本。總而言之,目前TPU最適合用于訓練CNN或大型Transformer,并且應該補充其他計算資源而不是主要的深度學習資源。亞馬遜和微軟云GPU
亞馬遜AWS和Microsoft Azure的云GPU非常有吸引力,人們可以根據(jù)需要輕松地擴大和縮小使用規(guī)模,對于論文截稿或大型項目結(jié)束前趕出結(jié)果非常有用。然而,與TPU類似,云GPU的成本會隨著時間快速增長。目前,云GPU過于昂貴,且無法單獨使用,Tim建議在云GPU上進行最后的訓練之前,先使用一些廉價GPU進行原型開發(fā)。初創(chuàng)公司的AI硬件
有一系列初創(chuàng)公司在生產(chǎn)下一代深度學習硬件。但問題在于,這些硬件需要開發(fā)一個完整的軟件套件才能具有競爭力。英偉達和AMD的對比就是鮮明的例子。小結(jié)
總的來說,本地運算首選英偉達GPU,它在深度學習上的支持度比AMD好很多;云計算首選谷歌TPU,它的性價比超過亞馬遜AWS和微軟Azure。訓練階段使用TPU,原型設計和推理階段使用本地GPU,可以幫你節(jié)約成本。如果對項目deadline或者靈活性有要求,請選擇成本更高的云GPU。
???最終建議
1、使用GTX 1070或更好的GPU;
2、購買帶有張量核心的RTX GPU;
3、在GPU上進行原型設計,然后在TPU或云GPU上訓練模型。針對不同研究目的、不同預算,Tim給出了如下的建議:避免的坑:所有Tesla、Quadro、創(chuàng)始人版(Founders Edition)的顯卡,還有Titan RTX、Titan V、Titan XP高性價比:RTX 2070(高端),RTX 2060或GTX 1060 (6GB)(中低端)破產(chǎn)之選:GTX 1050 Ti(4GB),或者CPU(原型)+ AWS / TPU(訓練),或者Colab計算機視覺或機器翻譯研究人員:采用鼓風設計的GTX 2080 Ti,如果訓練非常大的網(wǎng)絡,請選擇RTX Titans已經(jīng)開始研究深度學習:RTX 2070起步,以后按需添置更多RTX 2070嘗試入門深度學習:GTX 1050 Ti(2GB或4GB顯存)
感謝北京大學出版社贊助,共2本
贈書方式:后臺回復999參與抽獎
加老胡微信,圍觀朋友圈
推薦閱讀
pip 的高階玩法
我愛線代,線代使我快樂
Python數(shù)據(jù)可視化,被Altair圈粉了
機器學習深度研究:特征選擇中幾個重要的統(tǒng)計學概念