
爬蟲案例:拉勾網(wǎng)工作職位爬取
本人非IT專業(yè),因?yàn)閷?duì)python爬蟲比較感興趣,因此正在自學(xué)python爬蟲,學(xué)習(xí)后就拿拉勾網(wǎng)練練手??,同時(shí)給zhenguo老師投稿,還能收獲50元。


本次我們的目標(biāo)是爬取拉勾網(wǎng)上成都的python崗位信息,包括職位名稱、地區(qū)、薪水、任職要求、工作內(nèi)容標(biāo)簽、公司名稱、公司的類別及規(guī)模和福利待遇等信息,并將這些信息保存在一個(gè)CSV文件當(dāng)中,廢話不多說,開干!
首先我們進(jìn)入拉勾網(wǎng),輸入Python關(guān)鍵信息,并選擇成都,首先分析一下當(dāng)前的url,url當(dāng)中的pn=為頁碼,因此我們想爬取第幾頁的信息,就將pn的值設(shè)置為第幾頁。
'https://www.lagou.com/wn/jobs?pn=2&fromSearch=true&kd=python&city=%E6%88%90%E9%83%BD'
'https://www.lagou.com/wn/jobs?pn=1&fromSearch=true&kd=python&city=%E6%88%90%E9%83%BD'
想要爬取所有頁面,只需要設(shè)置一個(gè)循環(huán),每個(gè)循環(huán)中調(diào)用爬取工作信息的函數(shù)即可,代碼如下:
if __name__ == '__main__':
# 爬取1-30頁的內(nèi)容
for page in range(1, 31):
url = f'https://www.lagou.com/wn/jobs?pn={page}&fromSearch=true&kd=python&city=%E6%88%90%E9%83%BD'
# 該函數(shù)的功能為爬取一頁信息內(nèi)容并寫入到CSV文件內(nèi)
get_info_job(url)
# 為了保證爬取速度過快導(dǎo)致IP被封,設(shè)置一下等待時(shí)間,爬取下一頁的時(shí)候等待2秒
sleep(2)
接下來就是定義爬取每一頁工作信息內(nèi)容并寫入到CSV文件內(nèi)保存的函數(shù),該函數(shù)的實(shí)現(xiàn)方式如下:def get_info_job(job_url):
response = requests.get(url=job_url, headers=headers).text
selector = html.etree.HTML(response)
lis = selector.xpath('//*[@id="jobList"]/div[1]/div')
for li in lis:
name_area = li.xpath('.//div[1]/div[1]/div[1]/a/text()')
# 獲取職位名稱
title = name_area[0]
# 獲取地區(qū)
area = name_area[1].replace('[', '').replace(']', '')
# 獲取薪水
salary = li.xpath('.//div[1]/div[1]/div[2]/span/text()')[0]
# 獲取經(jīng)驗(yàn)和學(xué)歷要求,有時(shí)候沒有要求時(shí),xpath匹配結(jié)果是一個(gè)空列表,程序會(huì)報(bào)錯(cuò),因此這里需要捕獲異常,一旦捕獲異常,代表該工作無要求
try:
exp_degree = li.xpath('.//div[1]/div[1]/div[2]/text()')[0]
except IndexError:
exp_degree = '無要求'
# 獲取工作標(biāo)簽,有時(shí)候沒有工作標(biāo)簽,沒有的話就用“/”代替
tags = li.xpath('.//div[2]/div[1]/span/text()')
if not tags:
tags = '/'
# 獲取公司名稱
company_name = li.xpath('.//div[1]/div[2]/div[1]/a/text()')[0]
# 獲取公司類別和規(guī)模,有些公司沒有這些信息,xpath匹配結(jié)果是一個(gè)空列表,程序會(huì)報(bào)錯(cuò),因此捕獲異常,一旦捕獲到異常,代表沒有公司類別和規(guī)模信心,用“/”代替
try:
company_Type_Size = li.xpath('.//div[1]/div[2]/div[2]/text()')[0]
except IndexError:
company_Type_Size = '/'
# 獲取福利待遇,同樣有些公司不公布福利待遇,xpath匹配結(jié)果也是一個(gè)空列表,程序會(huì)報(bào)錯(cuò),因此需捕獲異常,一旦捕獲到異常,代表公司沒有公布福利待遇等信息,用“/”替代
try:
benefits = li.xpath('.//div[2]/div[2]/text()')[-1].replace('“', '').replace('”', '')
except IndexError:
benefits = '/'
job_datas = {
'職位名稱': title,
'地區(qū)': area,
'薪水': salary,
'經(jīng)驗(yàn)和學(xué)歷要求': exp_degree,
'工作標(biāo)簽': tags,
'公司名稱': company_name,
'公司類別和規(guī)模': company_Type_Size,
'福利待遇': benefits
}
# print(job_datas)
writer.writerow([
title,
area,
salary,
exp_degree,
tags,
company_name,
company_Type_Size,
benefits
])
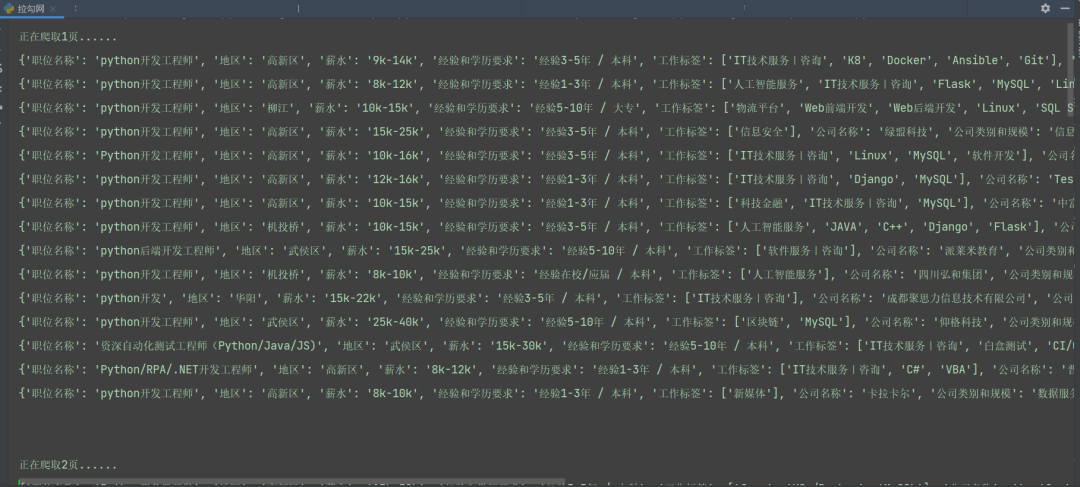
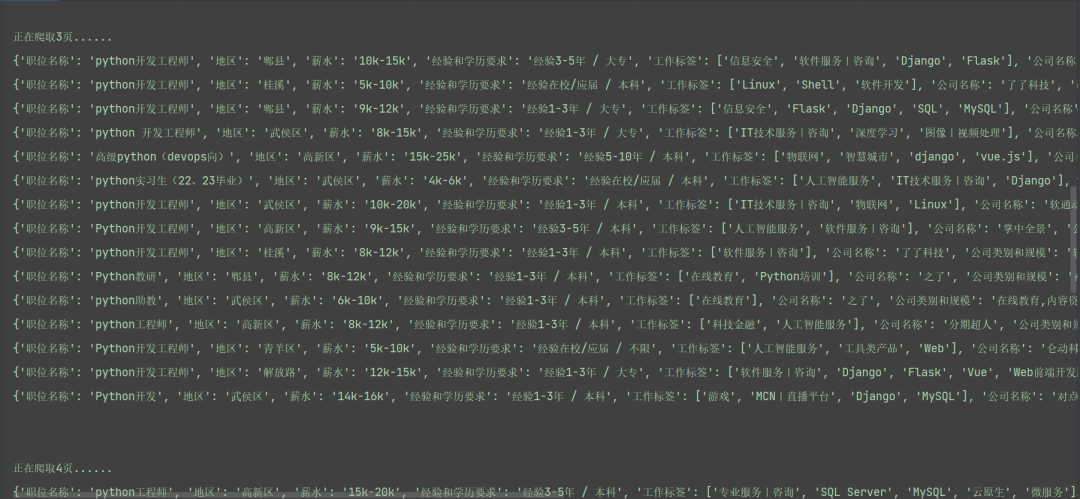
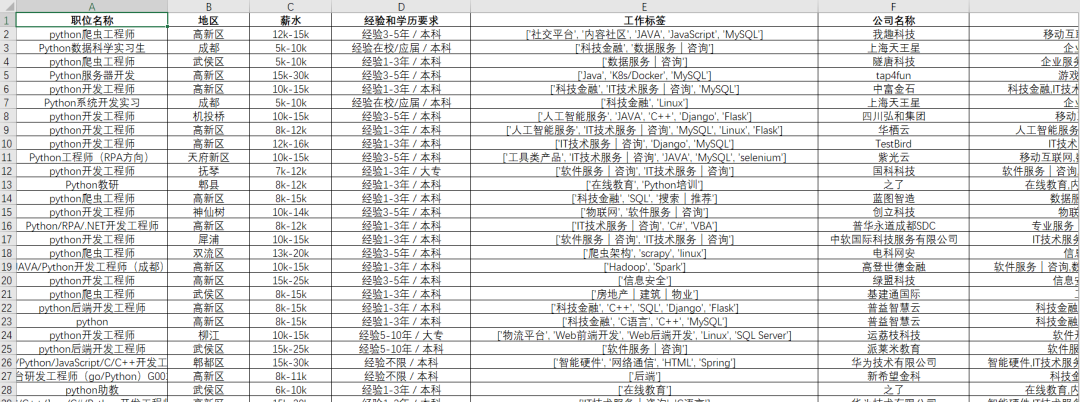
這里具體的爬取和保存的函數(shù)就定義完畢了,每次循環(huán)的時(shí)候直接調(diào)用該函數(shù)就行了,并且該程序能夠適配所有地區(qū)和所有工作崗位的信息爬取,只需要更換具體的url就行了。該程序爬取成都崗位的信息效果圖如下:
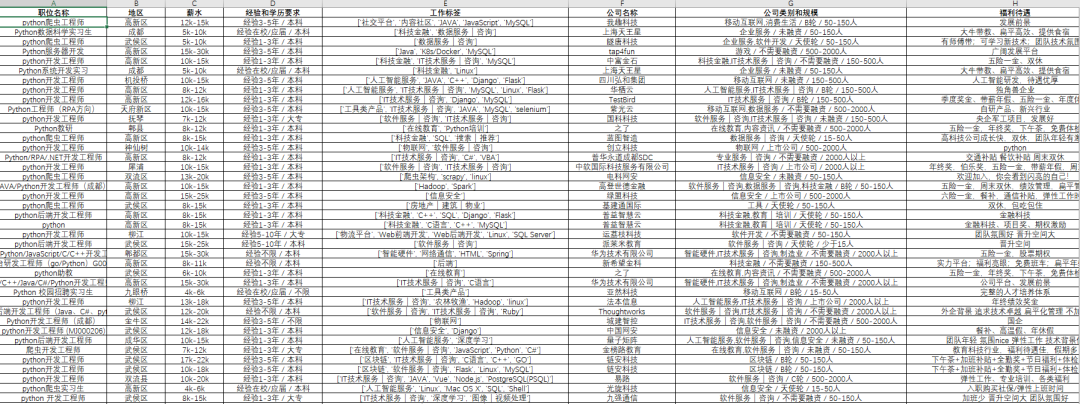
我們可以看到,我們爬取的信息有職位名稱、地區(qū)、薪水、經(jīng)驗(yàn)和學(xué)歷要求、工作標(biāo)簽、公司名稱、公司類別和規(guī)模、福利待遇等信息。
完整源碼下載,請(qǐng)關(guān)注我的公眾號(hào),后臺(tái)回復(fù):拉勾
評(píng)論
圖片
表情