三個Python爬蟲版本,各種方式爬取校花網(wǎng)美圖


爬蟲是什么?
如果我們把互聯(lián)網(wǎng)比作一張大的蜘蛛網(wǎng),數(shù)據(jù)便是存放于蜘蛛網(wǎng)的各個節(jié)點,而爬蟲就是一只小蜘蛛,
沿著網(wǎng)絡(luò)抓取自己的獵物(數(shù)據(jù))爬蟲指的是:向網(wǎng)站發(fā)起請求,獲取資源后分析并提取有用數(shù)據(jù)的程序;
從技術(shù)層面來說就是 通過程序模擬瀏覽器請求站點的行為,把站點返回的HTML代碼/JSON數(shù)據(jù)/二進制數(shù)據(jù)(圖片、視頻) 爬到本地,進而提取自己需要的數(shù)據(jù),存放起來使用;
基本環(huán)境配置
版本:Python3
系統(tǒng):Windows
IDE:Pycharm
爬蟲所需工具:
請求庫:requests,selenium(可以驅(qū)動瀏覽器解析渲染CSS和JS,但有性能劣勢(有用沒用的網(wǎng)頁都會加載);)
解析庫:正則,beautifulsoup,pyquery
存儲庫:文件,MySQL,Mongodb,Redis

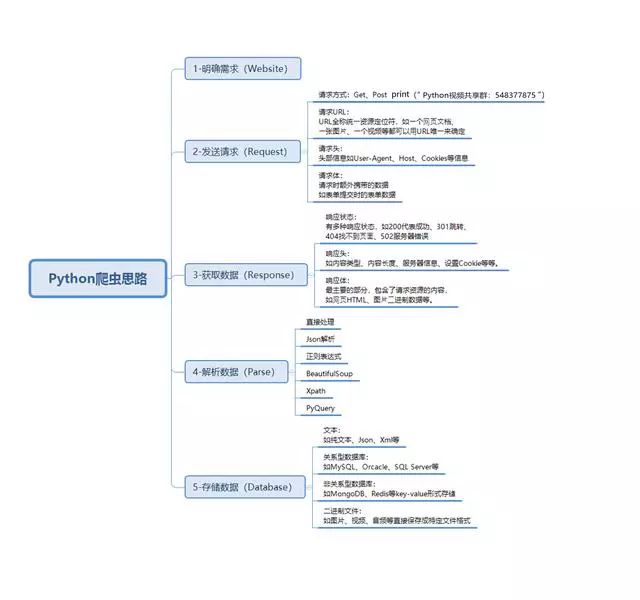
Python爬蟲基本流程
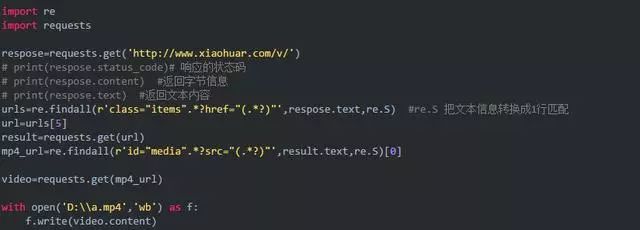
基礎(chǔ)版:
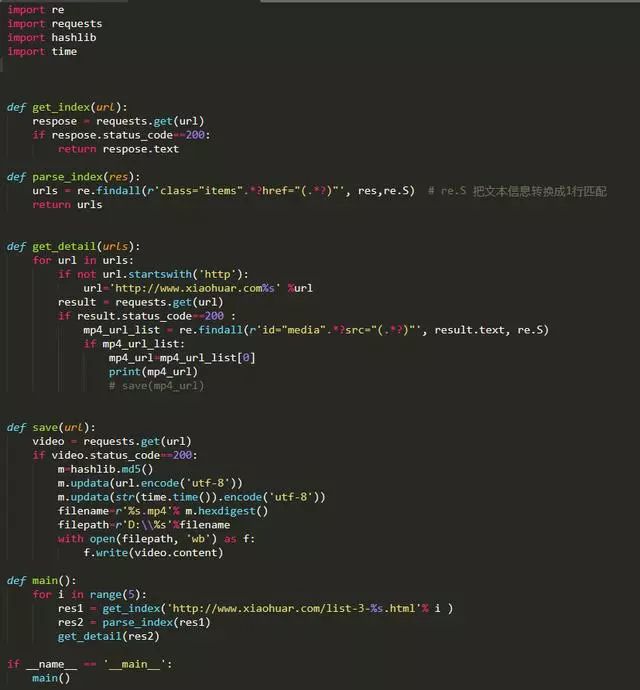
函數(shù)封裝版
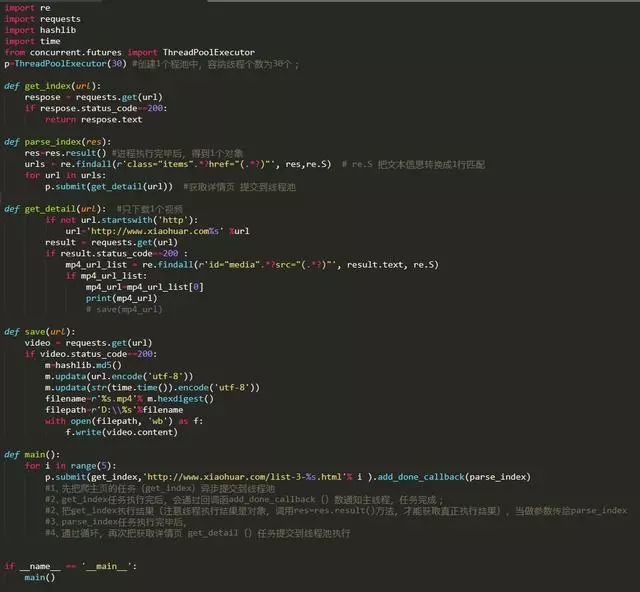
并發(fā)版
(如果一共需要爬30個視頻,開30個線程去做,花的時間就是 其中最慢那份的耗時時間)
明白了Python爬蟲的基本流程,然后對照代碼是不是覺得爬蟲特別的簡單呢?
搜索下方加老師微信
老師微信號:XTUOL1988【切記備注:學(xué)習(xí)Python】
領(lǐng)取Python web開發(fā),Python爬蟲,Python數(shù)據(jù)分析,人工智能等精品學(xué)習(xí)課程。帶你從零基礎(chǔ)系統(tǒng)性的學(xué)好Python!
*聲明:本文于網(wǎng)絡(luò)整理,版權(quán)歸原作者所有,如來源信息有誤或侵犯權(quán)益,請聯(lián)系我們刪除或授權(quán)