
關聯(lián)規(guī)則也能有監(jiān)督?
大家好,我是小伍哥,今天繼續(xù)跟大家探討關聯(lián)規(guī)則策略自動化的話題,這次的數(shù)據(jù)更接近真實場景,這個系列已經(jīng)寫了兩篇文章了,第一篇簡介基本原理,第二篇講解策略自動化挖掘,上一篇文章中,我們用關聯(lián)規(guī)則算法進行了風控策略的自動化挖掘,但是需要兩步走,先挖掘的策略再進行準確率的評估,稍微有點麻煩,那有沒有辦法一次性的挖掘就得出策略的準確率呢,把這個算法當然有監(jiān)督的方法,實際上是可以的,只是相對麻煩點,我們現(xiàn)在開始。
風控策略自動化生成-利用關聯(lián)規(guī)則分分鐘生成千萬條策略!
開始前,我們簡單的回顧下關聯(lián)規(guī)則的兩個概念,這對理解我們的挖掘思路十分重要:
支持度(support):交易記錄中某項集出現(xiàn)的概率
項集X的支持度:
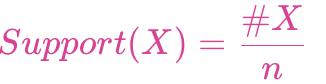
項集{X,Y}支持度:
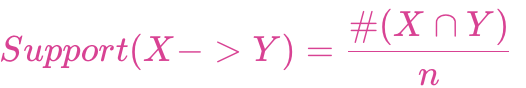
如果支持度太低,說明{X,Y}這條規(guī)則在全集中出現(xiàn)的概率小,支持度一般按照項集k值的增加而減少,也就是一元組合的要多于二元組合規(guī)則。
置信度(confidence):買了X的人又買了Y,置信度是條件概率P(Y|X)。
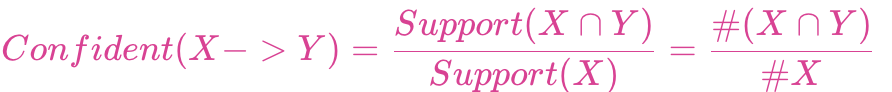
1、數(shù)據(jù)集介紹
我們利用的是一個對直播間彈幕數(shù)據(jù)集,里面大量涉黃涉暴的文本,挖掘看看哪些是高風險的詞匯,可以當成違禁詞庫,直接進行屏蔽了。該數(shù)據(jù)集包含19670條明細數(shù)據(jù),每一行都用 1(垃圾文本)和 0(正常文本)進行了標記。需要數(shù)據(jù)集的關注:小伍哥聊風控,回復【彈幕】
正常彈幕示例
新人主播,各位老板多多關注??? 050077你賣我 0看看五雷咒的威力 0
垃圾彈幕示例
網(wǎng)站++沜買的私聊我 1安 KMD555 買-P-微 1摳逼加薇2928046748摳逼加薇2928046748摳逼。1
部分數(shù)據(jù)如下

2、文本讀取
import osimport pandas as pdpath = '/Users/wuzhengxiang/Documents/DataSets/TextCnn'os.chdir(path)data = pd.read_csv('text_all.csv')#對數(shù)據(jù)進行隨機打亂data = data.sample(frac=1, random_state=42)print(data.shape)2)#查看0-1的比例,可以看出來,數(shù)據(jù)集基本上平衡data['label'].value_counts()1 98820 9788#查看前10行的數(shù)據(jù)data.head(10)text label17036 鄭 29526 Q 77544 15426 葩葩葩l 014173 網(wǎng)站盤需要買的私聊我. 114582 買家秀和賣家秀?01730 1776看v 01444 我又沒送你謝我干啥? 010439 7645 55562筘 02448 伽韋 sx111505 珂視頻箹 Ku 110423 影薇 w2753636 111782 ?????胸還沒有寒磊的?大???還奶子疼!0
3、文本預處理
把文本處理成算法需要的格式
# 安裝結巴分詞 有的話就不用管了# pip install jieba#加載結巴分詞import jieba#使用默認的模式分詞即可 測試下分詞效果print(list(jieba.cut('佳喂:sx111505可越qw')))['佳', '喂', ':', 'sx111505', '可越', 'qw']#進行分詞處理data['text'] = text_all['text'].apply(lambda x: ' '.join(jieba.cut(x)))data.head()#進行替換 并與原來的文本進行合并'''label = 1 替換成 Risklabel = 0 替換成 Norm'''text_all['label'] = text_all['label'].apply(lambda x: 'Risk' if x>0 else 'Norm')# 分詞處理 并把標簽加到序列后面df_arr = [list(i[0])+([i[1]]) for i in zip(text_all['text'],text_all['label'])]# 看看處理后前10條數(shù)據(jù)長啥樣print(df_arr[0:10])[['颙', ' ', '29526', ' ', 'Q', ' ', '77544', 'Risk'],['\ufeff', '染', '-', '黃色', ' ', 'K', ' ', 'U', ' ', 'C', ' ', '5', ' ', '3', ' ', '4', 'Risk'],['91', '網(wǎng)址', '求', '大哥', 'Risk'],['塞', ' ', 'CC', '-', '名字', '-', '看', '拼', '?', 'Risk'],['QQ', '網(wǎng)名', '!', '微信', 'Norm'],['佳維', ':', 'sx111505', ' ', '可', '曰', 'Yy', 'Risk'],['我區(qū)', '才', '250', '-', '350w', '買到', 'Norm'],['君', '-', '偉心', ' ', 'K', 'U', '€', '5', '3', '7', 'Risk'],['不是', ',', '問', '一些', '愚蠢', '的', '問題', ',', '說', '怎么', '獲得', '英雄', ',', '臥槽', '??', 'Norm'],['我', '找到', '了', '免費', '網(wǎng)址', 'Risk']]
4、關聯(lián)規(guī)則挖掘
這次我使用FP-growth算法,因為規(guī)模比較大,使用的Python包為mlxtend,大家有啥其他好用的可以推薦給我,目前這個用下來還是挺好用的。
# 安裝包,如果有 則忽略pip install mlxtend#加載包from mlxtend.preprocessing import TransactionEncoderfrom mlxtend.frequent_patterns import apriorifrom mlxtend.frequent_patterns import fpgrowthfrom mlxtend.frequent_patterns import association_rulesimport pandas as pd#轉換為算法可接受模型(布爾值)te = TransactionEncoder()df_tf = te.fit_transform(df_arr)df = pd.DataFrame(df_tf,columns=te.columns_)#設置支持度求頻繁項集,最小支持度設置為0.005frequent_itemsets = fpgrowth(df,min_support=0.005,use_colnames= True)#求關聯(lián)規(guī)則,設置最小置信度為0.3rules = association_rules(frequent_itemsets,metric = 'confidence',min_threshold = 0.3)# 查看下輸出結果長啥樣rules.columns['antecedents', 'consequents', 'antecedent support','consequent support', 'support', 'confidence', 'lift', 'leverage','conviction']# 看前5行數(shù)據(jù)rules.head()antecedents consequents antecedent support ... lift leverage conviction0 ( ) (Risk) 0.354042 ... 1.559177 0.099459 2.2964611 (Risk) ( ) 0.502389 ... 1.559177 0.099459 1.4419162 (Q) (Risk) 0.021352 ... 1.876746 0.009405 8.7081853 (Q) ( ) 0.021352 ... 2.347047 0.010183 3.8211624 ( , Q) (Risk) 0.017743 ... 1.910640 0.008117 12.404721#設置最小提升度#rules = rules.drop(rules[rules.lift <1.0].index)#設置標題索引并打印結果rules.rename(columns = {'antecedents':'from','consequents':'to','support':'sup','confidence':'conf'},inplace = True)rules = rules[['from','to','sup','conf','lift']]print(rules)Output from spyder call 'get_namespace_view':antecedents consequents ... leverage conviction0 ( ) (Risk) ... 0.099459 2.2964611 (Risk) ( ) ... 0.099459 1.4419162 (Q) (Risk) ... 0.009405 8.7081853 (Q) ( ) ... 0.010183 3.8211624 ( , Q) (Risk) ... 0.008117 12.404721... ... ... ... ...285560 ( , 5176) (157, 4994, Risk) ... 0.005410 54.203533285561 (5176, Risk) ( , 157, 4994) ... 0.005410 inf285562 (4994) ( , 157, Risk, 5176) ... 0.005410 54.203533285563 (157) ( , 5176, 4994, Risk) ... 0.005410 54.203533285564 (5176) ( , 157, 4994, Risk) ... 0.005410 54.203533#rules為Dataframe格式,可根據(jù)自身需求存入文件 結果為frozenset,轉換成dict更好看rules = rules[rules['to']==frozenset({'Risk'})]rules['from'] = rules['from'].apply(lambda x:set(x))rules['to'] = rules['to'].apply(lambda x:set(x))rules.to_csv('rules.csv',header=True,index=False)
最后的結果如下,其實有很多亂碼的字,我們在實際應用的時候,可以做更精細化的特征。
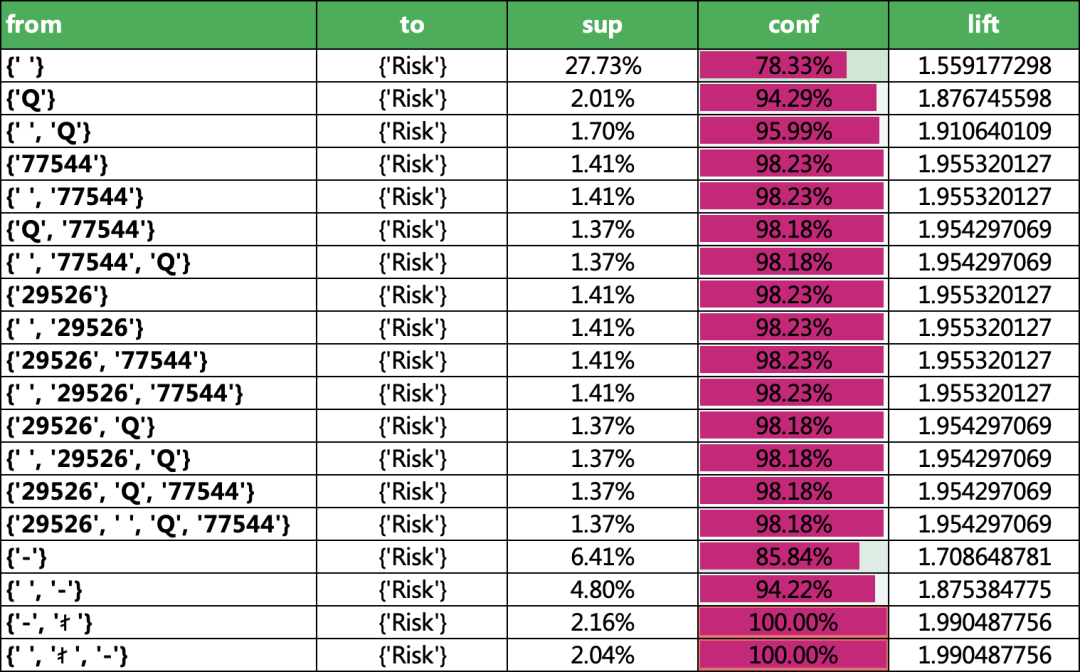
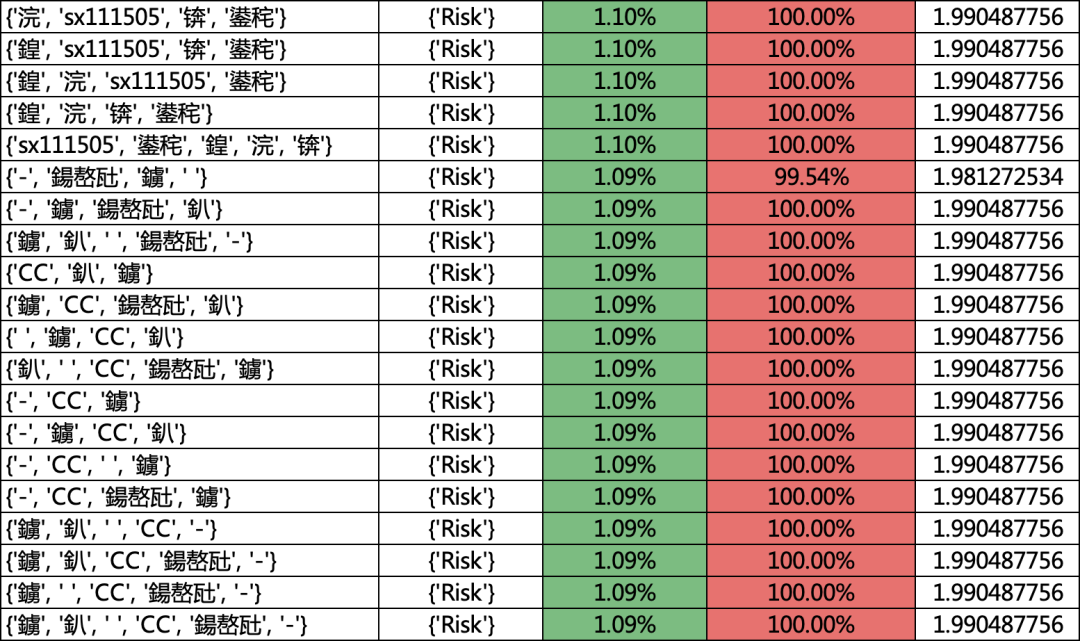
sup:支持度,其實就是這個策略的覆蓋程度
conf:置信度,就是這個策略在訓練集上的準確率。不用單獨計算準確率,非常快捷方便。
5、結 ? 論
這種方法挖掘的策略相對比較少點,但是比較簡單,一次性就可以得出準確率。
如果數(shù)據(jù)需要進一步清洗,可以用下面這個函數(shù)試試,數(shù)字和字母都會連續(xù)的在一起
def TokenClean(s):'''字符清洗處理'''lasts = [] #文本序列is_dn = [] #儲存單詞is_en = [] #儲存字母for i in s:if i.encode('UTF-8').isalnum():#字母is_en.append(i)elif not i.encode('UTF-8').isalnum() and len(is_en)>0 :#非字母is_dn.append(''.join(is_en))lasts.append(is_dn.pop())lasts.append(i)is_en = []else:lasts.append(i)if len(is_en)>0:is_dn.append(''.join(is_en))lasts.append(is_dn.pop())return lastsTokenClean('然-美-絲-薇 KUC539')['然', '-', '美', '-', '絲', '-', '薇', ' ', 'KUC539']df_arr = [TokenClean(i[0])+([i[1]]) for i in zip(text_all['text'],text_all['label'])]
今天就寫到這里,要進群的,文末加我的。