
從整體視角了解情感分析、文本分類!
文本分類是自然語言處理(NLP)最基礎(chǔ)核心的任務(wù),或者換句話說,幾乎所有NLP任務(wù)都是「分類」任務(wù),或者涉及到「分類」概念。比如分詞、詞性標(biāo)注、命名實(shí)體識(shí)別等序列標(biāo)注任務(wù)其實(shí)就是Token粒度的分類;再比如文本生成其實(shí)也可以理解為Token粒度在整個(gè)詞表上的分類任務(wù)。
本文側(cè)重于從宏觀角度(歷史演變和基本流程)對文本情感分類任務(wù)進(jìn)行介紹,目的是給讀者提供一個(gè)整體視角,從高遠(yuǎn)處審視情感分析、文本分類、甚至NLP,期望能拋磚引玉,引發(fā)讀者更多的思考。
本文同樣適合于非算法崗位的工程師,以及沒有技術(shù)背景但對NLP感興趣的伙伴。
本文篇幅較長,主要分為四個(gè)部分。
01 背景介紹
情感分析是根據(jù)輸入的文本、語音或視頻,自動(dòng)識(shí)別其中的觀點(diǎn)傾向、態(tài)度、情緒、評價(jià)等,廣泛應(yīng)用于消費(fèi)決策、輿情分析、個(gè)性化推薦等商業(yè)領(lǐng)域。包括篇章級、句子級和對象或?qū)傩约墶?梢苑譃橐韵氯悾?/span>

工業(yè)界最常見的往往是這種情況。比如大眾點(diǎn)評某家餐飲店下的評論:“服務(wù)非常贊,但味道很一般”,這句話其實(shí)表達(dá)了兩個(gè)意思,或者說兩個(gè)對象(屬性)的評價(jià),我們需要輸出類似:<服務(wù),正向>和<口味,負(fù)向>這樣的結(jié)果(<屬性-傾向>二元組),或者再細(xì)一點(diǎn)加入用戶的觀點(diǎn)信息(<屬性-觀點(diǎn)-傾向>三元組):<服務(wù),贊,正向>和<口味,一般,負(fù)向>。這樣的結(jié)果才更有實(shí)際意義。
從 NLP 處理的角度看,情感分析包括兩種基礎(chǔ)任務(wù):文本分類和實(shí)體對象或?qū)傩猿槿。@也正好涵蓋了 NLP 的兩類基本任務(wù):序列分類(Sequence Classification)和 Token 分類(Token Classification)。兩者的區(qū)別是,前者輸出一個(gè)標(biāo)簽,后者每個(gè) Token 輸出一個(gè)標(biāo)簽。
02 基本流程
一般來說,NLP 任務(wù)的基本流程主要包括以下五個(gè):
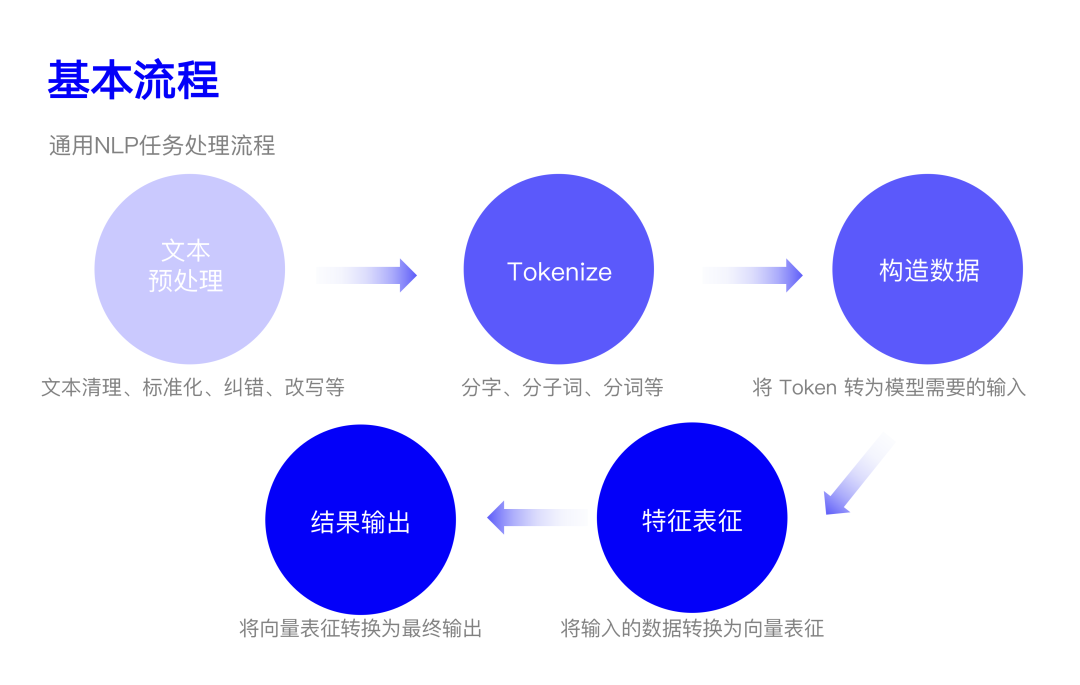
2.1 文本預(yù)處理
文本預(yù)處理主要是對輸入文本「根據(jù)任務(wù)需要」進(jìn)行的一系列處理。
文本清理:去除文本中無效的字符,比如網(wǎng)址、圖片地址,無效的字符、空白、亂碼等。
標(biāo)準(zhǔn)化:主要是將不同的「形式」統(tǒng)一化。比如英文大小寫標(biāo)準(zhǔn)化,數(shù)字標(biāo)準(zhǔn)化,英文縮寫標(biāo)準(zhǔn)化,日期格式標(biāo)準(zhǔn)化,時(shí)間格式標(biāo)準(zhǔn)化,計(jì)量單位標(biāo)準(zhǔn)化,標(biāo)點(diǎn)符號(hào)標(biāo)準(zhǔn)化等。
糾錯(cuò):識(shí)別文本中的錯(cuò)誤,包括拼寫錯(cuò)誤、詞法錯(cuò)誤、句法錯(cuò)誤、語義錯(cuò)誤等。
改寫:包括轉(zhuǎn)換和擴(kuò)展。轉(zhuǎn)換是將輸入的文本或 Query 轉(zhuǎn)換為同等語義的另一種形式,比如拼音(或簡拼)轉(zhuǎn)為對應(yīng)的中文。擴(kuò)展主要是講和輸入文本相關(guān)的內(nèi)容一并作為輸入。常用在搜索領(lǐng)域。
需要注意的是,這個(gè)處理過程并不一定是按照上面的順序從頭到尾執(zhí)行的,可以根據(jù)需要靈活調(diào)整,比如先糾錯(cuò)再標(biāo)準(zhǔn)化或?qū)?biāo)準(zhǔn)化放到改寫里面。咱們不能被這些眼花繚亂的操作迷惑,始終謹(jǐn)記,文本預(yù)處理的目的是將輸入的文本變?yōu)橐延邢到y(tǒng)「喜歡且接受」的形式。舉個(gè)例子,比如系統(tǒng)在訓(xùn)練時(shí)都使用「單車」作為自行車的稱呼,那預(yù)處理時(shí)就應(yīng)該把自行車、Bike、Bicycle 等都轉(zhuǎn)為單車。或者甚至系統(tǒng)用了某個(gè)錯(cuò)別字,那輸入也要變成對應(yīng)的錯(cuò)別字。
2.2 Tokenizing(分詞)
主要目的是將輸入的文本 Token 化,它涉及到后續(xù)將文本轉(zhuǎn)為向量。一般主要從三個(gè)粒度進(jìn)行切分:
字級別:英文就是字母級別,操作起來比較簡單。
詞級別:英文不需要,中文可能會(huì)需要。關(guān)于中文分詞,之前寫過一點(diǎn)思考,簡單來說,分詞主要是「分割語義」,降低不確定性,要不要分詞一般要看任務(wù)和模型。
子詞:包括BPE(Byte Pair Encoding),WordPieces,ULM(Unigram Language Model)等。在英文中很常見,當(dāng)然中文也可以做,是介于字級別和詞級別中間的一種粒度。主要目的是將一些「統(tǒng)一高頻」的形式單獨(dú)拎出來。比如英文中 de 開頭的前綴,或者最高級 est 等等。子詞一般是在大規(guī)模語料上通過統(tǒng)計(jì)「頻率」自動(dòng)學(xué)習(xí)到的。
我們需要知道的是,字和詞并非哪個(gè)一定比另一個(gè)好,都要需要根據(jù)具體情況具體分析的。它們的特點(diǎn)如下:
| 粒度 | 字 | 詞 |
|---|---|---|
| 詞表大小 | 固定 | 無法窮盡 |
| 未識(shí)別詞(OOV) | 沒有 | 典型問題,長尾、稀疏性 |
| 參數(shù)/計(jì)算量 | 多 | Token 變少,參數(shù)少,計(jì)算快 |
| 語義/建模復(fù)雜度 | 有不確定性 | 攜帶語義,能夠降低不確定性 |
注:OOV=Out Of Vocabulary
2.3 構(gòu)造數(shù)據(jù)
文本經(jīng)過上一步后會(huì)變成一個(gè)個(gè) Token,接下來就是根據(jù)后續(xù)需要將 Token 轉(zhuǎn)為一定形式的輸入,可能就是 Token 序列本身,也可能是將 Token 轉(zhuǎn)為數(shù)字,或者再加入新的信息(如特殊信息、Token 類型、位置等)。我們主要考慮后兩種情況。
Token 轉(zhuǎn)數(shù)字:就是將每個(gè)「文本」的 Token 轉(zhuǎn)為一個(gè)整數(shù),一般就是它在詞表中的位置。根據(jù)后續(xù)模型的不同,可能會(huì)有一些特殊的 Token 加入,主要用于「分割輸入」,其實(shí)就是個(gè)「標(biāo)記」。不過有兩個(gè)常用的特殊 Token 需要稍加說明:<UNK> 和 <PAD>,前者表示「未識(shí)別 Token」,UNK=Unknown,后者表示「填充 Token」。因?yàn)槲覀冊趯?shí)際使用時(shí)往往會(huì)批量輸入文本,而文本長度一般是不相等的,這就需要將它們都變成統(tǒng)一的長度,也就是把短的用 <PAD> 填充上。<PAD> 一般都放在詞表第一個(gè)位置,index 為 0,這樣有個(gè)好處就是我們在計(jì)算時(shí),0 的部分可以方便地處理掉(它們是「填充」上去的,本來就算不得數(shù))。
加入新的信息:又可以進(jìn)一步分為「在文本序列上加入新的信息」和「加入和文本序列平行的信息」。
序列上新增信息:輸入的文本序列有時(shí)候不一定『只』是一句話,還可能會(huì)加入其他信息,比如:「公司旁邊的螺螄粉真的太好吃了。<某種特殊分隔符>螺螄粉<可能又一個(gè)分隔符>好吃」。所以,準(zhǔn)確來說,應(yīng)該叫「輸入序列」。 新增平行信息:有時(shí)候除了輸入的文本序列,還需要其他信息,比如位置、Token 類型。這時(shí)候就會(huì)有和 Token 序列 Token 數(shù)一樣的其他序列加入,比如絕對位置信息,如果輸入的句子是「今天吃了螺螄粉很開心」,對應(yīng)的位置編碼是「1 2 3 4 5 6 7 8 9 10」。
需要再次強(qiáng)調(diào)的是,這一步和后續(xù)使用的模型直接相關(guān),要根據(jù)具體情況進(jìn)行相應(yīng)處理。
2.4 文本特征
根據(jù)上面構(gòu)造的數(shù)據(jù),文本特征(也可以看作對文本的表征)從整體來看可以分為兩個(gè)方面:Token 直接作為特征和 Token(或其他信息)編碼成數(shù)字,然后轉(zhuǎn)成向量作為特征。這一小節(jié)咱們主要介紹一下從 Token 到特征形態(tài)發(fā)生了哪些變化,至于怎么去做這種轉(zhuǎn)換,為什么,下一節(jié)《模型發(fā)展》中會(huì)做進(jìn)一步分析。
a. OneHot
首先,要先明確下輸入的文本最終要變成什么樣子,也就是特征的外形長啥樣。注意,之前得到的整數(shù)并不能直接放到模型里去計(jì)算,因?yàn)閿?shù)字的大小并沒有語義信息。
那么,最簡單的表示方式就是某個(gè) Token 是否出現(xiàn)在給定的輸入中。我們假設(shè)實(shí)現(xiàn)已經(jīng)有一個(gè)做好的很大的詞表,里面有 10w 個(gè) Token。當(dāng)我們給定 Token 序列時(shí),詞表中的每個(gè) Token 是否出現(xiàn)在給定的序列中就可以構(gòu)造出一個(gè) 01 向量:
[0, 0, 1, 0, ..., 0, 1] # 10w 個(gè)
其中 1 表示那個(gè)位置的 Token 在出現(xiàn)在了給定的序列中,0 則表示未出現(xiàn)。可以想象,對于幾乎所有的輸入,對應(yīng)的 01 向量絕大多數(shù)的位置都是 0。假設(shè)有 m 個(gè)句子,那么會(huì)得到一個(gè)矩陣:
# m * 10w
[[0, 0, 1, 0, ..., 0, 1],
[0, 1, 0, 0, ..., 0, 0],
[0, 0, 1, 1, ..., 0, 1],
[0, 1, 1, 0, ..., 0, 0],
...
[1, 0, 0, 0, ..., 0, 1]]
其中的每一列就表示該位置 Token 的向量表示,換句話說,在表示句子的同時(shí),Token 也被成功地表示成了一個(gè)向量。
上面的這種編碼方式就叫 OneHot 編碼,也就是把 Token 編成一個(gè)只有一個(gè) 1 其余全是 0 的向量,然后通過在語料上計(jì)算(訓(xùn)練)得到最后的表示。
b. TF-IDF
聰明的您一定會(huì)想到,既然可以用「出現(xiàn)」或「不出現(xiàn)」來表示,那為啥不用頻率呢?沒錯(cuò),我們可以將上面的 1 都換成該詞在每個(gè)句子中出現(xiàn)的頻率,歸一化后就是概率。由于自然語言的「齊夫定律」,高頻詞會(huì)很自然地占據(jù)了主導(dǎo)地位,這對向量表示大有影響,想象一下,那些概率較高的詞幾乎在所有句子中出現(xiàn),它們的值也會(huì)更大,從而導(dǎo)致最終的向量表示向這些詞傾斜。
齊夫定律:在自然語言語料庫中,一個(gè)單詞出現(xiàn)的頻率與它在頻率表里的排名成反比。即第 n 個(gè)常見的頻率是最常見頻率的 1/n。舉個(gè)例子來說,中文的「的」是最常見的詞,排在第 1 位,比如第 10 位是「我」,那「我」的頻率就是「的」頻率的 1/10。
于是,很自然地就會(huì)想到使用某種方式去平和這種現(xiàn)象,讓真正的高頻詞凸顯出來,而降一些類似的、是這種常見詞的影響下降。咱們很自然就會(huì)想到,能不能把這些常見詞從詞表給剔除掉。哎,是的。這種類似的常見詞有個(gè)專業(yè)術(shù)語叫「停用詞」,一般呢,停用詞主要是虛詞居多,包括助詞、連詞、介詞、語氣詞等,但也可能會(huì)包括一些「沒用」的實(shí)詞,需要根據(jù)實(shí)際情況處理。
除了停用詞,還有另一種更巧妙的手段處理這個(gè)問題——TF-IDF,TF=Term Frequency,IDF=Inverse Document Frequency。TF 就是剛剛提到的詞頻,這不是有些常用詞嗎,這時(shí)候 IDF 來了,它表示「有多少個(gè)文檔包含那個(gè)詞」,具體等于文檔總數(shù)/包含該詞的文檔數(shù)。比如「的」在一句話(或一段文檔)中概率很高,但幾乎所有句子(或文檔)都有「的」,IDF 接近 1;相反如果一個(gè)詞在句子中概率高,但包含該詞的文檔比較少,IDF 就比較大,最后結(jié)果也大。而這是滿足我們預(yù)期的——詞在單個(gè)文檔或句子中是高概率的,但在所有文檔或句子中是低概率的,這不正說明這個(gè)詞對所在文檔或句子比較重要嗎。實(shí)際運(yùn)算時(shí),一般會(huì)取對數(shù),并且防止 0 除:
這時(shí)候的向量雖然看著不是 OneHot,但其實(shí)本質(zhì)還是,只是在原來是 1 的位置,變成了一個(gè)小數(shù)。
c. Embedding
剛剛的得到的矩陣最大的問題是維度太大,數(shù)據(jù)稀疏(就是絕大部分位置是 0),而且詞和詞之間是孤立的。最后這個(gè)問題不用多解釋,這樣構(gòu)建的特征肯定「不全面」。但是維度太大和數(shù)據(jù)稀疏又有什么影響呢?首先說前者,在《文獻(xiàn)資料:文本特征》第一篇文章提到了在超高維度下的反直覺現(xiàn)象——數(shù)據(jù)不會(huì)變的更均勻,反而會(huì)聚集在高維空間的角落,這會(huì)讓模型訓(xùn)練特別困難。再說后者,直觀來看,數(shù)據(jù)稀疏最大的問題是使得向量之間難以交互,比如「出差住酒店」和「出差住旅店」,酒店和旅店在這里意思差不多,但模型卻無法學(xué)習(xí)到。
既然如此,先輩們自然而然就想能不能用一個(gè)連續(xù)稠密、且維度固定的向量來表示。然后,大名鼎鼎的「詞向量」就登場了——它將一個(gè)詞表示為一個(gè)固定維度大小的稠密向量。具體來說,就是首先隨機(jī)初始化固定維度大小的稠密向量,然后用某種策略通過詞的上下文自動(dòng)學(xué)習(xí)到表征向量。也就是說,當(dāng)模型訓(xùn)練結(jié)束了,詞向量也同時(shí)到手了。具體的過程可參考《文獻(xiàn)資料:文本特征》第二篇文章。
「詞向量」是一個(gè)劃時(shí)代的成果,為啥這么說呢?因?yàn)樗嬲炎匀徽Z言詞匯表征成一個(gè)可計(jì)算、可訓(xùn)練的表示,帶來的直接效果就是自然語言一步跨入了深度學(xué)習(xí)時(shí)代——Embedding 后可以接各種各樣的模型架構(gòu),完成復(fù)雜的計(jì)算。
2.5 結(jié)果輸出
當(dāng)用戶的輸入是一句話(或一段文檔)時(shí),往往需要拿到整體的向量表示。在 Embedding 之前雖然也可以通過頻率統(tǒng)計(jì)得到,但難以進(jìn)行后續(xù)的計(jì)算。Embedding 出現(xiàn)之后,方法就很多了,其中最簡單的當(dāng)然是將每個(gè)詞的向量求和然后平均,復(fù)雜的話就是 Embedding 后接各種模型了。
那么在得到整個(gè)句子(或文檔)的向量表示后該如何得到最終的分類呢?很簡單,通過一個(gè)矩陣乘法,將向量轉(zhuǎn)為一個(gè)類別維度大小的向量。我們以二分類為例,就是將一個(gè)固定維度的句子或文檔向量變?yōu)橐粋€(gè)二維向量,然后將該二維向量通過一個(gè)非線性函數(shù)映射成概率分布。
舉個(gè)例子,假設(shè)最終的句子向量是一個(gè) 8 維的向量,w 是權(quán)重參數(shù),計(jì)算過程如下:
import numpy as np
rng = np.random.default_rng(seed=42)
embed = rng.normal(size=(1, 8)).round(2)
# array([[ 0.3 , -1.04, 0.75, 0.94, -1.95, -1.3 , 0.13, -0.32]]) 維度=1*8
w = rng.normal(size=(8, 2)).round(2)
""" 維度=8*2
array([[-0.02, -0.85],
[ 0.88, 0.78],
[ 0.07, 1.13],
[ 0.47, -0.86],
[ 0.37, -0.96],
[ 0.88, -0.05],
[-0.18, -0.68],
[ 1.22, -0.15]])
"""
z = embed @ b # 矩陣乘法
# array([[-2.7062, 0.8695]]) 維度=1*2
def softmax(x):
return np.exp(x) / np.sum(tf.exp(x), axis=1)
softmax(z)
# array([[0.0272334, 0.9727666]])
這個(gè)最后的概率分布是啥意思呢?它分別表示結(jié)果為 0 和 1 的概率,兩者的和為 1.0。
您可能會(huì)有疑問或好奇:參數(shù)都是隨機(jī)的,最后輸出的分類不對怎么辦?這個(gè)其實(shí)就是模型的訓(xùn)練過程了。簡單來說,最后輸出的概率分布會(huì)和實(shí)際的標(biāo)簽做一個(gè)比對,然后這個(gè)差的部分會(huì)通過「反向傳播算法」不斷沿著模型網(wǎng)絡(luò)往回傳,從而可以更新隨機(jī)初始化的參數(shù),直到最終的輸出和標(biāo)簽相同或非常接近為止。此時(shí),我們再用訓(xùn)練好的網(wǎng)絡(luò)參數(shù)計(jì)算,就會(huì)得到正確的標(biāo)簽。
03 模型簡史
這部分我們主要簡單回顧一下 NLP 處理情感分類任務(wù)模型發(fā)展的歷史,探討使用了什么方法,為什么使用該方法,有什么問題等。雖然您看到的是情感分類,其實(shí)也適用于其他類似的任務(wù)。
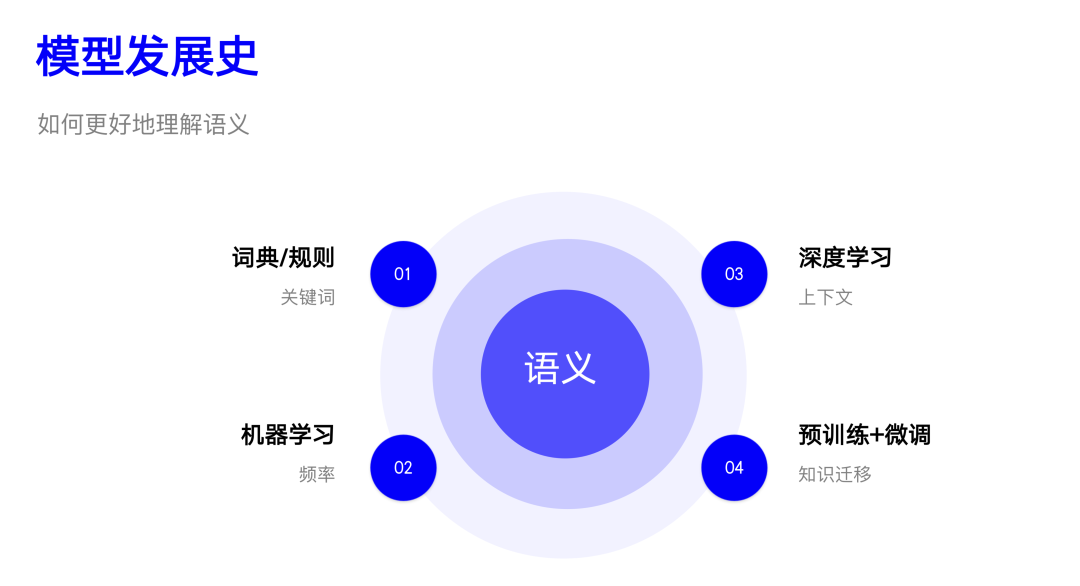
3.1 詞典/規(guī)則
在 NLP 發(fā)展的初級階段,詞典和規(guī)則的方法是主流。算法步驟也非常簡單:
事先收集好分別代表正向和負(fù)向的詞表。比如正向的「開心、努力、積極」,負(fù)向的「難過、垃圾、郁悶」 對給定的文本分詞 分別判斷包含正向和負(fù)向詞的數(shù)量 包含哪類詞多,結(jié)果就是哪一類
可以看出這個(gè)非常簡單粗暴,模型就是這兩個(gè)詞表,整個(gè)算法的核心就是「基于匹配」,實(shí)際匹配時(shí),考慮到性能一般會(huì)使用 Trie 或自動(dòng)機(jī)進(jìn)行匹配。這種方法的主要特點(diǎn)包括:
簡單:意味著成本低廉,非常容易實(shí)施。
歧義:因?yàn)橐粋€(gè)個(gè)詞是獨(dú)立的,沒有考慮上下文,導(dǎo)致在否定、多重否定、反問等情況下會(huì)失敗,比如「不開心、不得不努力、他很難過?不!」
無法泛化:詞表是固定的,沒有出現(xiàn)在詞表中的詞,或稍微有些變化(比如單個(gè)字變了)就會(huì)導(dǎo)致識(shí)別失敗。
雖然有不少問題,但詞典/規(guī)則方法直到現(xiàn)在依然是常用的方法之一,這背后根本的原因就在于我們在自然語言理解時(shí)往往會(huì)特別關(guān)注到其中的「關(guān)鍵詞」,而語序、助詞等往往沒啥別特影響^_^
3.2 機(jī)器學(xué)習(xí)
隨著統(tǒng)計(jì)在 NLP 領(lǐng)域的使用,「基于頻率」的方法開始風(fēng)靡,最簡單常用的模型就是 Ngram,以及基于 Ngram 構(gòu)建特征并將之運(yùn)用在機(jī)器學(xué)習(xí)模型上。這一階段的主要特點(diǎn)是對數(shù)據(jù)進(jìn)行「有監(jiān)督」地訓(xùn)練,效果自然比上一種方法要好上很多。
Ngram 其實(shí)很簡單。比如給定一句話「人世間的成見就像一座大山」,如果以字為粒度,Bigram 結(jié)果是「人世 世間 間的……」,Trigram 自然就是「人世間 世間的 間的成……」,4-Gram,5-Gram 以此類推。不過實(shí)際一般使用 Bigram 和 Trigram 就夠了。
Ngram 本質(zhì)是對句子進(jìn)行語義分割(回想前面提到的「分詞的意義」),也可以看成是一種「分詞」。所以之前構(gòu)建文本特征的 Token 也都可以換成 Ngram。現(xiàn)在從概率角度考慮情感分類問題,其實(shí)就是解決下面這個(gè)式子:
這里給定的 Token 可以是字、詞或任意的 Ngram,甚至是彼此的結(jié)合。由于分母在不同類型下是一樣的,所以可以不考慮,主要考慮分子部分。又由于類別的概率一般是先驗(yàn)的,因此最終就成了解決給定情感傾向得到給定 Token 序列的概率。上面的式子也叫貝葉斯公式,如果不考慮給定 Token 之間的相關(guān)性,就得到了樸素貝葉斯(Naive Bayes):
此時(shí),我們只需要在正向和負(fù)向語料上分別計(jì)算 Token 的概率即可,這個(gè)過程也叫訓(xùn)練,得到的模型其實(shí)是兩個(gè) Token 概率表。有了這個(gè)模型,再有新的句子過來時(shí),Token 化后,利用(2)式分別計(jì)算正向和負(fù)向的概率,哪個(gè)高,這個(gè)句子就是哪種類別。深度學(xué)習(xí)之前,Google 的垃圾郵件分類器就是用該算法實(shí)現(xiàn)的。
可以發(fā)現(xiàn),這種方法其實(shí)是考慮了兩種不同類型下,可能的 Token 序列概率,相比上一種方法容錯(cuò)率得到了提高,泛化能力增加。需要注意的是,歧義本質(zhì)是使用 Ngram 解決的,這也同樣適用于上一種方法。由于類似于直接查表,所以這種方法本質(zhì)上是 OneHot 特征,只不過是直接用了 Token 本身(和它的概率)作為特征。另外,無論是哪種「文本特征」,都是可以直接運(yùn)用在機(jī)器學(xué)習(xí)模型上進(jìn)行計(jì)算訓(xùn)練的。
這里的核心其實(shí)是「基于頻率」建模,實(shí)際會(huì)使用 Ngram,通過 OneHot、TF-IDF 等來構(gòu)建特征。這種方法的主要問題是:維度災(zāi)難、數(shù)據(jù)稀疏、詞孤立等,在『文本特征』一節(jié)已做相應(yīng)介紹,這里不再贅述。
3.3 深度學(xué)習(xí)
深度學(xué)習(xí)時(shí)代最大的不同是使用了稠密的 Embedding,以及后面可接各式各樣的神經(jīng)網(wǎng)絡(luò),實(shí)際上是一種「基于上下文」的建模方式。我們以 NLP 領(lǐng)域經(jīng)典的 TextCNN 架構(gòu)來進(jìn)行說明。
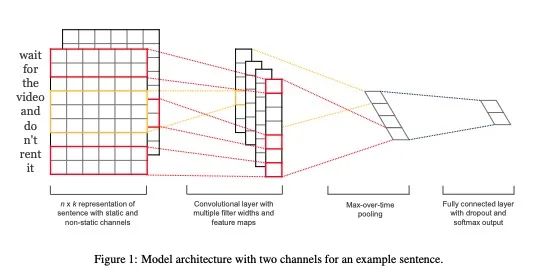
假設(shè)每個(gè)詞是 6 維的(如圖所示),每個(gè)詞旁邊的格子里都對應(yīng)著該詞的 Embedding,整個(gè)那一片可以叫輸入句子的 Embedding 矩陣。我們現(xiàn)在假設(shè)有一個(gè) 3×6 的矩陣,里面的值是要學(xué)習(xí)的參數(shù),一開始是隨機(jī)初始化的。這個(gè) 3×6 的矩陣叫 Kernel,它會(huì)沿著句子 Embedding 矩陣從上往下移動(dòng),圖例中的步幅是 1,每移動(dòng)一步,Kernel 和 3 個(gè)詞的 Embedding 點(diǎn)乘后求和后得到一個(gè)值,最后就會(huì)得到一個(gè)一維向量(卷積層 Convolutional layer),然后取最大值或平均值(池化層 Pooling),就會(huì)得到一個(gè)值。如果我們每次使用一個(gè)值不一樣的 Kernel,就會(huì)得到一組不同的值,這個(gè)就構(gòu)成了輸入句子的表征,通過類似前面『結(jié)果輸出』中的計(jì)算,就會(huì)得到最終的概率分布。
這里有幾點(diǎn)需要說明一下:
第一,我們可以使用多個(gè)不同大小的 Kernel,剛剛用了 3,還可以用 2、4 或 5,最后得到的向量會(huì)拼接在一起,共同作為句子的標(biāo)準(zhǔn)。
第二,Embedding 矩陣也是可以作為參數(shù)在訓(xùn)練時(shí)初始化的,這樣模型訓(xùn)練完了,Embedding 順便也就有了(此時(shí)因?yàn)樽罱K結(jié)果都已經(jīng)有了,往往該矩陣也沒啥意義,不需要單獨(dú)拿出來考慮),或者也可以直接使用已經(jīng)訓(xùn)練好的 Embedding 矩陣。
第三,除了 TextCNN 還有其他很多模型也可以做類似的事,大同小異。
Embedding 有效地解決了上一種方法的問題,但它本身也是有一些問題的,比如沒考慮外部知識(shí),這就進(jìn)入了我們下一個(gè)時(shí)代——預(yù)訓(xùn)練模型。
3.4 預(yù)訓(xùn)練+微調(diào)
預(yù)訓(xùn)練模型「基于大規(guī)模語料訓(xùn)練」,其本質(zhì)是一種遷移學(xué)習(xí)——將大規(guī)模語料中的知識(shí)學(xué)習(xí)到模型中,然后用在各個(gè)實(shí)際的任務(wù)中,是對上一種方法的改進(jìn)。我們以百度的 ERNIE 為例說明。
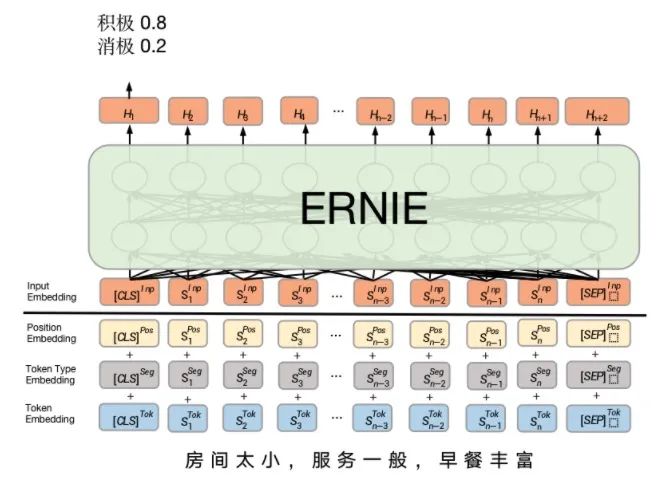
首先是它的輸入比上一種方法多了新的信息,但最終每個(gè) Token 依然會(huì)得到一個(gè) Embedding,然后經(jīng)過一個(gè)復(fù)雜的預(yù)訓(xùn)練模型 ERNIE 就會(huì)得到最終的輸出向量(類似上個(gè)方法的中間步驟),進(jìn)而就可以得到標(biāo)簽的概率分布。預(yù)訓(xùn)練模型已經(jīng)在很多 NLP 任務(wù)上達(dá)到了最好的效果。
當(dāng)然,要說預(yù)訓(xùn)練模型有什么不好,那就是太大太貴了,大是指模型大以及參數(shù)規(guī)模大(起碼上億),貴則是訓(xùn)練過程需要消耗的資源很多。不過大多數(shù)情況下,我們并不需要自己訓(xùn)練一個(gè),只要使用開源的即可,因?yàn)轭A(yù)訓(xùn)練的語料足夠大,幾乎涵蓋了所有領(lǐng)域,大部分時(shí)候會(huì)包含您任務(wù)所需要的信息。
以上涉及的代碼可以參考:http://nbviewer.org/github/hscspring/All4NLP/blob/master/Senta/senta.ipynb
04 探討展望
4.1 實(shí)際應(yīng)用
上面介紹了那么多的方法和模型,這里主要探討一下在實(shí)際應(yīng)用過程中的一些取舍和選擇。
規(guī)則 VS 模型:純規(guī)則、純模型和兩者結(jié)合的方法都有。規(guī)則可控,但維護(hù)起來不容易,尤其當(dāng)規(guī)模變大時(shí),規(guī)則重復(fù)、規(guī)則沖突等問題就會(huì)冒出來;模型維護(hù)簡單,有 bad case 重新訓(xùn)練一下就行,但可能需要增加語料,另外過程也不能干預(yù)。實(shí)際中,簡單任務(wù)可以使用純模型,復(fù)雜可控任務(wù)可以使用模型+規(guī)則組合,模型負(fù)責(zé)通用大多數(shù),規(guī)則覆蓋長尾個(gè)案。
深度 VS 傳統(tǒng):這個(gè)選擇其實(shí)比較簡單,當(dāng)業(yè)務(wù)需要可解釋時(shí),可以選擇傳統(tǒng)的機(jī)器學(xué)習(xí)模型,沒有這個(gè)限制時(shí),應(yīng)優(yōu)先考慮深度學(xué)習(xí)。
簡單 VS 復(fù)雜:當(dāng)任務(wù)簡單,數(shù)據(jù)量不大時(shí),可以用簡單模型(如 TextCNN),此時(shí)用復(fù)雜模型未必效果更好;但是當(dāng)任務(wù)復(fù)雜,數(shù)據(jù)量比較多時(shí),復(fù)雜模型基本上是碾壓簡單模型的。
總而言之,使用什么方案要綜合考慮具體的任務(wù)、數(shù)據(jù)、業(yè)務(wù)需要、產(chǎn)品規(guī)劃、資源等多種因素后確定。
4.2 情感的未來
主要簡單暢想一下未來,首先可以肯定的是未來一定是圍繞著更深刻的語義理解發(fā)展的。從目前的發(fā)展看,主要有以下幾個(gè)方向。
1、多模態(tài):多種不同形態(tài)的輸入結(jié)合。包括:文本、圖像、聲音等,或者文本、視頻。這個(gè)也是目前比較前沿的研究方向,其實(shí)也是很容易理解的。因?yàn)槲覀內(nèi)祟愅紩?huì)察言觀色,聽話聽音,其實(shí)就是從多個(gè)渠道接收到「信息」。換成機(jī)器,自然也可以做類似的事情,預(yù)期來看,效果必然是有提升的。舉個(gè)例子,比如就是簡單的「哈哈哈哈」幾個(gè)字,如果單純從文本看就是「大笑」,但如果配上圖像和聲音,那可能就變成「狂暴」、「淫邪」、「假笑」等可能了。
2、深度語義:綜合考慮率多種影響因素。包括:環(huán)境、上下文、背景知識(shí)。這點(diǎn)和第一點(diǎn)類似,也是盡量將場景「真實(shí)化」。
環(huán)境指的是對話雙方當(dāng)前所處的環(huán)境,比如現(xiàn)在是冬天,但用戶說「房間怎么這么熱」,其實(shí)可能是因?yàn)榉块g空調(diào)或暖氣開太高。如果不考慮環(huán)境,可能就會(huì)難以理解(這對人來說也是一樣的)。
上下文指的是對話中的歷史信息,比如開始對話時(shí)用戶說「今天有點(diǎn)感冒」,后面如果再說「感覺有點(diǎn)冷」,那可能是生病導(dǎo)致的。如果沒有這樣的上下文記憶,對話可能看起來就有點(diǎn)傻,對情感的理解和判斷也會(huì)不準(zhǔn)確。其實(shí)上下文在多輪對話中已有部分應(yīng)用,但還遠(yuǎn)遠(yuǎn)不夠,主要是難以將和用戶所有的歷史對話都結(jié)構(gòu)化地「連接」在一起。目前常用的也是根據(jù)用戶的「行為」數(shù)據(jù)對其「畫像」。
背景知識(shí)是指關(guān)于世界認(rèn)知的知識(shí)。比如用戶說「年輕人,耗子尾汁」,如果機(jī)器人沒有關(guān)于馬保國相關(guān)的背景知識(shí)就很難理解這句話是啥意思。這塊目前在實(shí)踐的是知識(shí)圖譜,其實(shí)就是在做出判斷時(shí),多考慮一部分背景知識(shí)的信息。
3、多方法:綜合使用多種方法。包括:知識(shí)圖譜、強(qiáng)化學(xué)習(xí)和深度學(xué)習(xí)。這是從方法論的角度進(jìn)行思考,知識(shí)圖譜主要是世界萬物及其基本關(guān)系進(jìn)行建模;強(qiáng)化學(xué)習(xí)則是對事物運(yùn)行的規(guī)則建模;而深度學(xué)習(xí)主要考慮實(shí)例的表征。多種方法組合成一個(gè)立體完整的系統(tǒng),這里有篇不成熟的胡思亂想對此進(jìn)行了比較詳細(xì)的闡述。
文獻(xiàn)資料
這部分作為擴(kuò)展補(bǔ)充,對相應(yīng)領(lǐng)域有興趣的伙伴可以順著鏈接了解一下:
業(yè)界應(yīng)用
情感分析技術(shù)在美團(tuán)的探索與應(yīng)用:https://mp.weixin.qq.com/s/gXyH4JrhZI2HHd5CsNSvTQ
情感計(jì)算在UGC應(yīng)用進(jìn)展:https://mp.weixin.qq.com/s/FYjOlksOxb255CvNLqFjAg
預(yù)處理
NLP 中的預(yù)處理:使用 Python 進(jìn)行文本歸一化:https://cloud.tencent.com/developer/article/1625962)
當(dāng)你搜索時(shí),發(fā)生了什么?(中) | 人人都是產(chǎn)品經(jīng)理:http://www.woshipm.com/pd/4680562.html
全面理解搜索 Query:當(dāng)你在搜索引擎中敲下回車后,發(fā)生了什么?:https://zhuanlan.zhihu.com/p/112719984
Tokenize
深入理解NLP Subword算法:BPE、WordPiece、ULM:https://zhuanlan.zhihu.com/p/86965595
Byte Pair Encoding — The Dark Horse of Modern NLP:https://towardsdatascience.com/byte-pair-encoding-the-dark-horse-of-modern-nlp-eb36c7df4f10
文本特征
The Curse of Dimensionality in Classification:https://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/
word2vec 前世今生:https://www.cnblogs.com/iloveai/p/word2vec.html
情感未來
多模態(tài)情感分析簡述:https://www.jiqizhixin.com/articles/2019-12-16-7
千言數(shù)據(jù)集:情感分析:https://aistudio.baidu.com/aistudio/competition/detail/50/0/task-definition

太子長琴
算法工程師
個(gè)人博客:https://yam.gift/