
從零實(shí)現(xiàn)爬蟲(chóng)和情感分類(lèi)模型(一)

文 | Giant
編 | NLP情報(bào)局
大家好,我是Giant,這是我的第3篇文章。
日常生活中,我們?nèi)コ燥垺⒂^影會(huì)提前上網(wǎng)刷評(píng)論,然后再選擇好評(píng)高的餐廳或電影。
看新聞時(shí),我們也會(huì)點(diǎn)擊感興趣的新聞?lì)悇e(體育、財(cái)經(jīng)等),再結(jié)合標(biāo)題有選擇地閱讀。

情感分析、新聞歸類(lèi)都是自然語(yǔ)言處理—文本分類(lèi)任務(wù)的經(jīng)典應(yīng)用。本文我們將從0實(shí)現(xiàn)一個(gè)餐廳評(píng)論評(píng)分系統(tǒng)。具體分4個(gè)模塊介紹:
python怎么裝最方便? 如何用python實(shí)現(xiàn)爬蟲(chóng)? 數(shù)據(jù)處理三劍客使用技巧 如何實(shí)現(xiàn)情感分類(lèi)模型?
開(kāi)源代碼:
https://github.com/yechens/RestaurantCrawler
python怎么裝最方便?
python是一種非常流行的編程語(yǔ)言,語(yǔ)法簡(jiǎn)潔卻功能強(qiáng)大,安裝方式很多。Mac和Ubuntu等系統(tǒng)已經(jīng)預(yù)裝好了最新版本的python。
但我還是強(qiáng)烈推薦你安裝Anaconda套裝。它是一個(gè)開(kāi)源的python發(fā)行版本,包含180多個(gè)工具包,其中很多工具包對(duì)于機(jī)器學(xué)習(xí)研究非常重要。一次安裝可以“一勞永逸”。
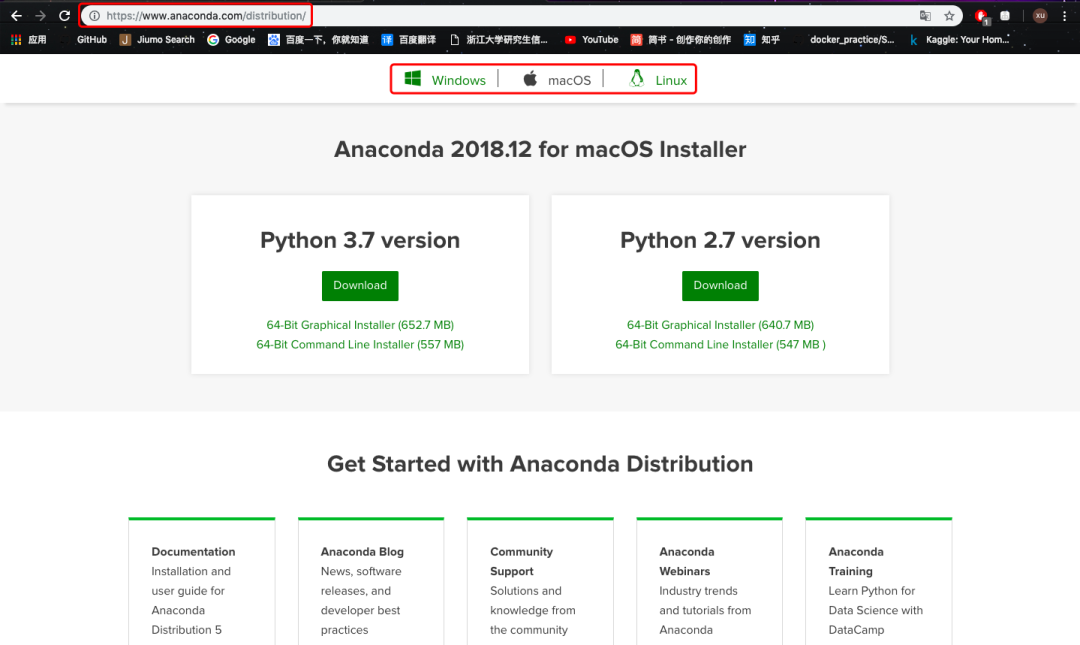
進(jìn)入Anaconda官網(wǎng)的下載頁(yè)面,可以根據(jù)你的系統(tǒng)下載最新版本的conda。如果想下載歷史版本,可以參考[1]。
之后根據(jù)中文提示一步步安裝即可,非常方便。
安裝完成后,進(jìn)入系統(tǒng)終端(Windows下稱(chēng)“命令提示符”),用conda創(chuàng)建一個(gè)虛擬環(huán)境,這樣可以和系統(tǒng)中原有的python環(huán)境相隔離。
conda create -n py36 python=3.6 # 創(chuàng)建指定py版本的虛擬環(huán)境conda env list # 查看虛擬環(huán)境source activate py36 # 激活
這里我們創(chuàng)建了一個(gè)python3.6版本的虛擬環(huán)境,然后激活進(jìn)入:

python最基礎(chǔ)的環(huán)境搭建到這兒全部完成啦。
如何用python實(shí)現(xiàn)爬蟲(chóng)
我們的目標(biāo)是實(shí)現(xiàn)一個(gè)餐廳評(píng)分系統(tǒng),核心數(shù)據(jù)是各大餐廳的評(píng)論語(yǔ)料。如何獲得呢?
最簡(jiǎn)單的方法,是去各大點(diǎn)評(píng)網(wǎng)站上查看餐廳的評(píng)論信息,然后手工復(fù)制、粘貼到Excel。但這樣費(fèi)時(shí)費(fèi)力,效率極低。能不能讓計(jì)算機(jī)幫助我們自動(dòng)搜集各個(gè)店鋪的評(píng)論數(shù)據(jù)呢?
當(dāng)然可以!這就是網(wǎng)絡(luò)爬蟲(chóng)。

整個(gè)互聯(lián)網(wǎng)相當(dāng)于一張大圖,各個(gè)網(wǎng)站是圖中的節(jié)點(diǎn)。爬蟲(chóng)正是模擬人的行為,利用計(jì)算機(jī)自動(dòng)遍歷各個(gè)節(jié)點(diǎn),訪問(wèn)頁(yè)面并抓取信息。這里的信息包括圖片、文字、視頻、腳本等等。此外,我們要記載哪個(gè)網(wǎng)頁(yè)下載過(guò)了,以免重復(fù)。
相比真實(shí)用戶(hù)訪問(wèn),爬蟲(chóng)有2個(gè)明顯優(yōu)勢(shì):
自動(dòng)進(jìn)行,無(wú)需人工干預(yù) 并發(fā)量大,訪問(wèn)效率高
而讀者之所以經(jīng)常聽(tīng)到爬蟲(chóng)和python掛鉤,是因?yàn)槟_本語(yǔ)言python非常適合寫(xiě)爬蟲(chóng)代碼。
有多簡(jiǎn)單呢?核心只有三行代碼:
import requestsr = requests.get(url="http://www.baidu.com")content = r.content
requests庫(kù)會(huì)自動(dòng)向我們指定的網(wǎng)頁(yè)鏈接(百度)發(fā)起http請(qǐng)求,并將爬取結(jié)果返回到變量content中。
爬蟲(chóng)背后涉及了瀏覽器的工作原理。對(duì)此感興趣的讀者,可以閱讀參考文獻(xiàn)[2]。
這“兩行代碼”是最簡(jiǎn)單的一種情況,爬取到的內(nèi)容也只是百度首頁(yè)的源碼;但實(shí)際開(kāi)發(fā)爬蟲(chóng)的核心內(nèi)容,已經(jīng)呈現(xiàn)在這兩行代碼里了。
Scrapy簡(jiǎn)介
在本項(xiàng)目中,我使用了一個(gè)比requests庫(kù)稍復(fù)雜的工具Scrapy,它是python最火的爬蟲(chóng)框架,結(jié)構(gòu)化的設(shè)計(jì)可以讓開(kāi)發(fā)人員方便的自定義項(xiàng)目需求。
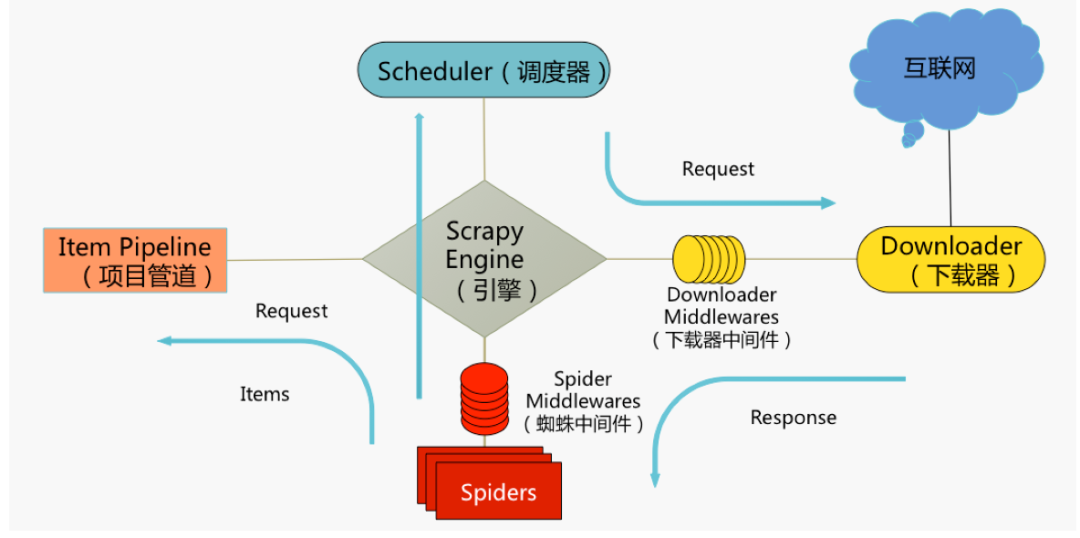
框架核心內(nèi)容可以用這張圖來(lái)概述,圖中包括Scrapy5大組件:
Scrapy Engine(引擎)
爬蟲(chóng)的“大腦”,是整個(gè)爬蟲(chóng)的調(diào)度中心Scheduler(調(diào)度器)
初始的爬取URL和后續(xù)在頁(yè)面中獲取的待爬取的URL將放入調(diào)度器中,等待爬取。同時(shí)調(diào)度器會(huì)自動(dòng)去除已經(jīng)下載過(guò)的URL。
Downloader(下載器)
獲取指定頁(yè)面的數(shù)據(jù)并提供給引擎和spiderSpiders(爬蟲(chóng)類(lèi))
用戶(hù)編寫(xiě)的分析爬取結(jié)果(response)并從中提取內(nèi)容的類(lèi)Items(實(shí)體類(lèi))
處理Spiders提取出來(lái)的內(nèi)容(items)典型處理包括:清洗、驗(yàn)證、持久化(存入數(shù)據(jù)庫(kù))
Scrapy主體內(nèi)容先介紹到這,參考文獻(xiàn)[3]、[4]、[5]為讀者準(zhǔn)備了學(xué)習(xí)這個(gè)框架的更多資料。
爬取餐廳評(píng)論
接下來(lái)進(jìn)入實(shí)戰(zhàn)環(huán)節(jié):利用python、Scrapy實(shí)現(xiàn)各大城市餐廳評(píng)論信息的自動(dòng)爬取。
借助之前下載的conda工具,進(jìn)入虛擬環(huán)境后我們用一行代碼完成scrapy安裝:
conda install scrapy為了方便演示,這兒只爬取杭州、北京等5大城市各1000家餐館的200條評(píng)論,一共約100w條數(shù)據(jù)。想爬取更多內(nèi)容,讀者略微修改開(kāi)源代碼中的內(nèi)容即可。
創(chuàng)建項(xiàng)目
我們先創(chuàng)建一個(gè)新的Scrapy項(xiàng)目:
scrapy?startproject?MeiTuanRestaurant該命令將會(huì)創(chuàng)建包含以下內(nèi)容的MeiTuanRestaurant目錄:
scrapy.cfg:?項(xiàng)目的配置文件MeiTuanRestaurant/:?項(xiàng)目的python模塊。之后您將在此加入代碼MeiTuanRestaurant/items.py:?項(xiàng)目中的item文件MeiTuanRestaurant/pipelines.py:?項(xiàng)目中的pipelines文件MeiTuanRestaurant/settings.py:?項(xiàng)目的設(shè)置文件MeiTuanRestaurant/spiders/:?放置spider代碼的目錄
cd進(jìn)入MeiTuanRestaurant目錄,隨后我們?cè)趕piders目錄下創(chuàng)建一個(gè)存放“爬蟲(chóng)類(lèi)”的py文件:
scrapy genspider meituan meituan.commeituan.py中生成了爬蟲(chóng)類(lèi)MeituanSpider,我們?cè)谄渲兄付ㄐ枰廊〉捻?yè)面入口、解析爬取結(jié)果并存放到數(shù)據(jù)庫(kù)中等操作。
我在meituan.py做了簡(jiǎn)單的修改,并定義了一些新函數(shù)。
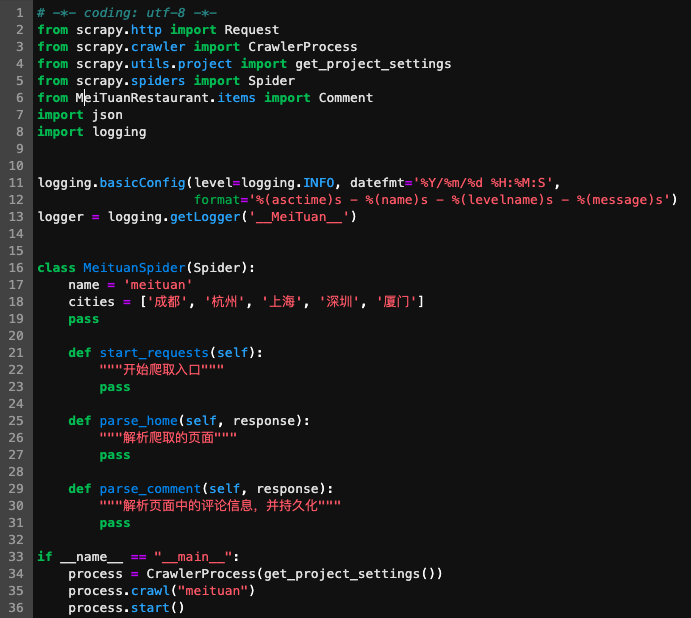
函數(shù)參數(shù)“response”中存儲(chǔ)了頁(yè)面解析后的結(jié)果,我們可以從中提取出想要的內(nèi)容,例如當(dāng)前頁(yè)面(page)、評(píng)論信息等。
完善爬蟲(chóng)
隨后,我們指定好爬取的頁(yè)面url,并填寫(xiě)函數(shù)內(nèi)容。本項(xiàng)目中,我們通過(guò)構(gòu)造api接口,提取json格式的數(shù)據(jù)。
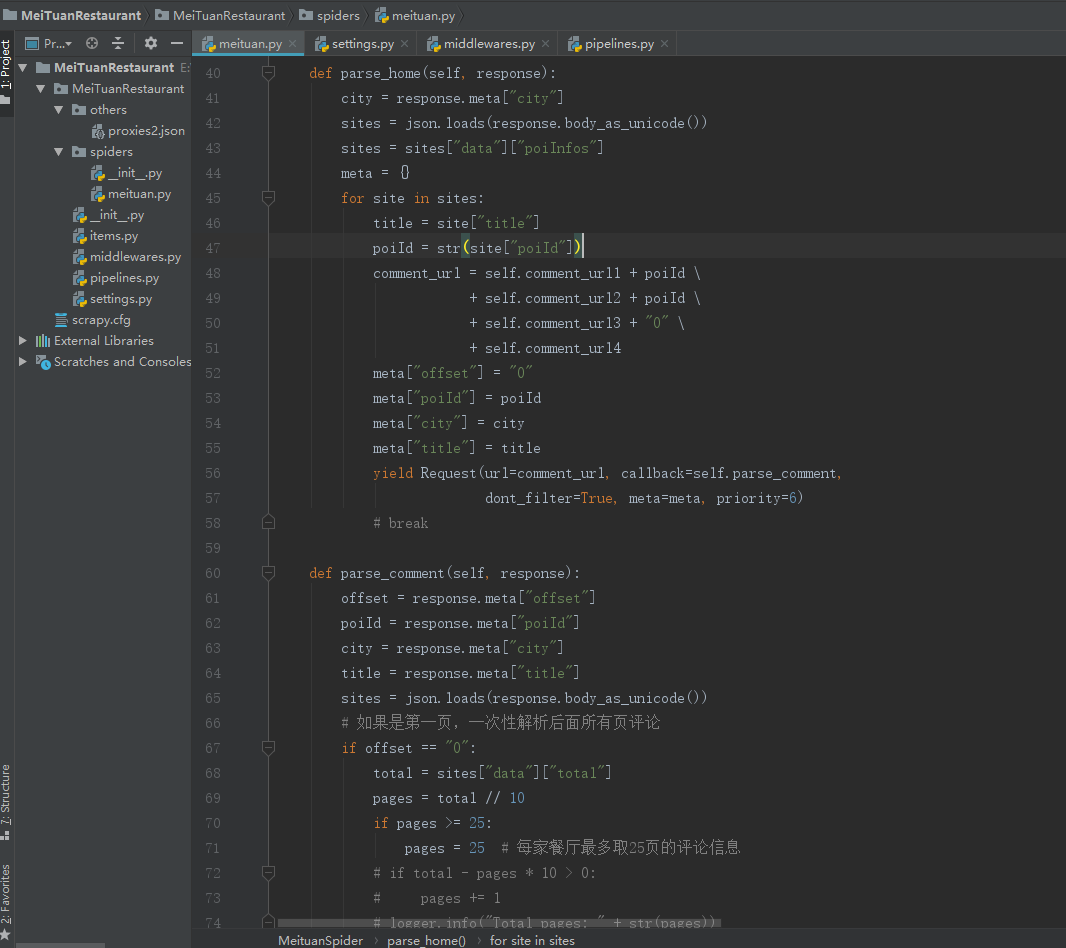
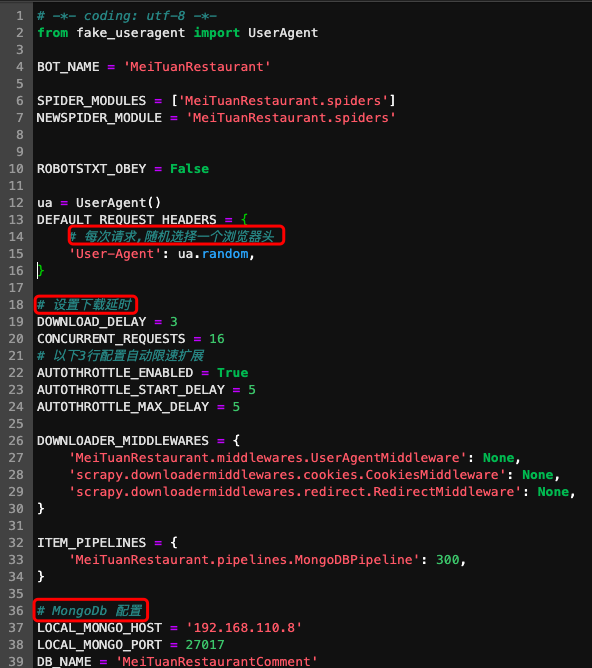
此外,我們需要在settings.py中進(jìn)行相關(guān)配置,常見(jiàn)操作有將爬蟲(chóng)偽裝成瀏覽器、設(shè)置下載延時(shí)、配置數(shù)據(jù)庫(kù)等等。
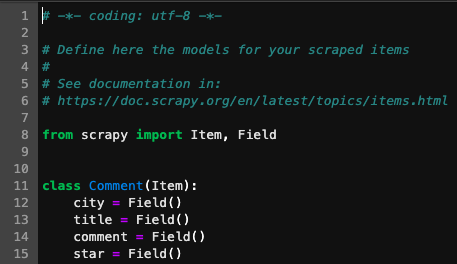
item.py中建立了評(píng)論的對(duì)象類(lèi),包含了樣本的所有屬性。例如一條評(píng)論可以有城市、標(biāo)題、內(nèi)容、星級(jí)4個(gè)特征。
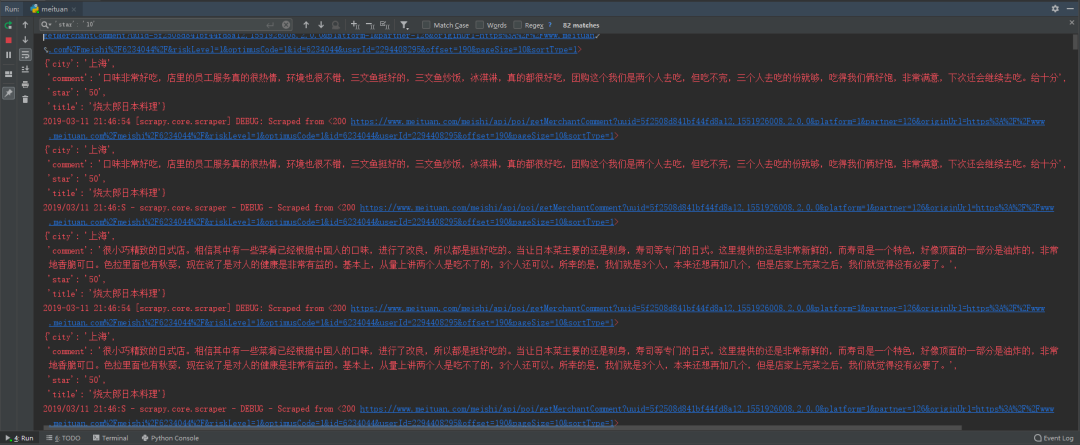
啟動(dòng)爬蟲(chóng)
打開(kāi)終端進(jìn)入項(xiàng)目所在路徑(MeiTuanRestaurant路徑下),運(yùn)行以下命令:
scrapy crawl meituan啟動(dòng)后可以看到爬蟲(chóng)開(kāi)始賣(mài)力爬取各個(gè)餐廳的評(píng)論信息啦。
數(shù)據(jù)持久化
為了將爬取到的內(nèi)容及時(shí)保存,我把評(píng)論數(shù)據(jù)存儲(chǔ)到非結(jié)構(gòu)化數(shù)據(jù)庫(kù)mongodb中。

如果覺(jué)得速度太慢,還可以嘗試分布式架構(gòu)(如scrapy-redis),加快爬蟲(chóng)爬取速度。
總結(jié)
本文實(shí)現(xiàn)了“從零實(shí)現(xiàn)爬蟲(chóng)和情感分類(lèi)模型”的第一部分:搭建環(huán)境、實(shí)現(xiàn)爬蟲(chóng)。單機(jī)約2-3天可以完成百萬(wàn)級(jí)的評(píng)論信息自動(dòng)爬取(如果遇到ip被封,需要設(shè)置代理池繼續(xù)偽裝爬蟲(chóng))。
在下一篇文章中,我們將分析數(shù)據(jù)處理和模型訓(xùn)練的實(shí)用技巧!
推 薦 閱 讀

[1] Anaconda歷史版本: https://repo.continuum.io/archive/
[2]?圖解瀏覽器的基本工作原理:?https://zhuanlan.zhihu.com/p/47407398
[3] Scrapy官方文檔: https://scrapy.org/
[4]?《Python爬蟲(chóng)開(kāi)發(fā)與項(xiàng)目實(shí)戰(zhàn)》: https://www.jqhtml.com/down/716.html
[5]?構(gòu)建單機(jī)千萬(wàn)級(jí)別的微博爬蟲(chóng)系統(tǒng): https://github.com/LiuXingMing/SinaSpider
由于微信平臺(tái)算法改版,訂閱號(hào)內(nèi)容將不再以時(shí)間排序展示,如果大家想第一時(shí)間看到我們的推送,強(qiáng)烈建議星標(biāo)我們幫我們點(diǎn)【在看】。星標(biāo)具體步驟:
(1)點(diǎn)擊頁(yè)面最上方“NLP情報(bào)局”,進(jìn)入主頁(yè)
(2)點(diǎn)擊右上角的小點(diǎn)點(diǎn),在彈出頁(yè)面點(diǎn)擊“設(shè)為星標(biāo)”,就可以啦
感謝支持??
原創(chuàng)不易,有收獲的話(huà)請(qǐng)分享、點(diǎn)贊、在看三選一吧??