
從零實(shí)現(xiàn)爬蟲(chóng)和情感分類(lèi)模型(二)

大家好,我是Giant,這是我的第5篇文章。
上一篇文章中我們完成了python環(huán)境搭建和百萬(wàn)級(jí)評(píng)論爬蟲(chóng),本文將利用爬取的數(shù)據(jù)訓(xùn)練評(píng)論分類(lèi)模型。
開(kāi)源代碼:
https://github.com/yechens/RestaurantCrawler/blob/main/demo_01.ipynb
01 數(shù)據(jù)處理三劍客
pandas、numpy、matplotlib功能強(qiáng)大使用方便,被譽(yù)為python數(shù)據(jù)處理三劍客。
之前爬取的數(shù)據(jù)保留在mongodb中,可以用mogoexport或數(shù)據(jù)庫(kù)可視化軟件將其導(dǎo)出到csv文件。
數(shù)據(jù)清洗
簡(jiǎn)單起見(jiàn),這里分別導(dǎo)出評(píng)分5星和1星的評(píng)論各6800條。后續(xù)處理中,每類(lèi)情感取6000條用于模型訓(xùn)練和校驗(yàn),剩余800條作為測(cè)試。
將導(dǎo)出的數(shù)據(jù)分別命名為10_star.csv、50_star.csv,借助pandas庫(kù)導(dǎo)入。

接下來(lái)遍歷評(píng)論列的每一行,過(guò)濾其中的非中文字符和長(zhǎng)度小于10的無(wú)效評(píng)論。
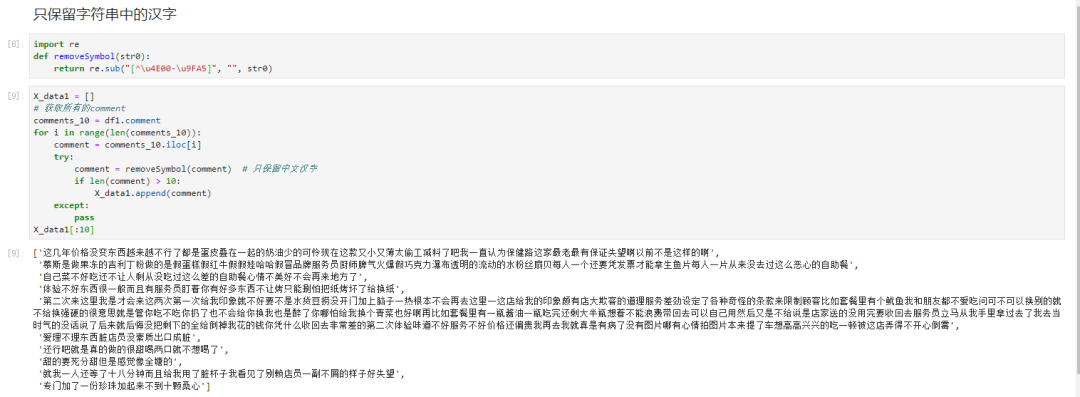
得到訓(xùn)練數(shù)據(jù)后,我們手工創(chuàng)建一個(gè)labels數(shù)組存放標(biāo)簽,將其轉(zhuǎn)換為numpy對(duì)象,便于后期輸入到神經(jīng)網(wǎng)絡(luò)中。
import?numpy?as?np
y_data?=?[0?for?i?in?range(6000)]?+?[1?for?i?in?range(6000)]
y_data?=?np.asarray(y_data,?dtype=np.float32)
y_test_data?=?[0?for?i?in?range(800)]?+?[1?for?i?in?range(800)]
y_test_data?=?np.asarray(y_data,?dtype=np.float32)
亂序處理
聰明的讀者可能發(fā)現(xiàn)了一個(gè)問(wèn)題:這份數(shù)據(jù)太有規(guī)律啦,正負(fù)情感剛好前后各占一半。假如前3000條評(píng)論機(jī)器全判斷為負(fù)面,能證明準(zhǔn)確率有100%嗎?
為了避免數(shù)據(jù)分布不規(guī)律的現(xiàn)象,我們需要為數(shù)據(jù)“洗牌”。
X_train,?y_train?=?[],?[]
nums?=?np.arange(12000)
#?隨機(jī)打亂12000個(gè)訓(xùn)練數(shù)據(jù)
np.random.shuffle(nums)
for?i?in?nums:
????X_train.append(X_data[i])
????y_train.append(y_data[i])
簡(jiǎn)單的數(shù)據(jù)預(yù)處理完成后,還有一個(gè)問(wèn)題。
這兒的數(shù)據(jù)全都是中文,即便是英文字母,計(jì)算機(jī)也一概不認(rèn)識(shí)。所以需要一個(gè)額外的“翻譯”步驟。
02?快速獲得中文詞向量
在自然語(yǔ)言處理任務(wù)中,需要考慮詞如何在計(jì)算機(jī)中表示。常見(jiàn)的表示方法有兩種:
one-hot representation (獨(dú)熱編碼) distribution representation
第一種是離散表示方法,得到高維度的稀疏矩陣;第二種方法是將詞表示成固定長(zhǎng)度的密集型向量,即詞向量。
從頭訓(xùn)練一個(gè)有效的語(yǔ)言模型耗時(shí)又耗能。本例中,我們借助騰訊AI實(shí)驗(yàn)室發(fā)布的bert-as-service接口,通過(guò)兩行代碼,即可使用預(yù)訓(xùn)練的Bert模型生成句向量和詞向量。
這兩行代碼怎么用呢?
from?bert_serving.client?import?BertClient
bc?=?BertClient
#?將待訓(xùn)練的中文數(shù)據(jù)轉(zhuǎn)換為(,768)維的句向量
input_train?=?bc.encode(X_train)
bert-as-service服務(wù)將一個(gè)句子統(tǒng)一轉(zhuǎn)換成768維的句向量,最終我們得到了[12000 * 768]維度的特征矩陣,也就是神經(jīng)網(wǎng)絡(luò)的真正輸入。
03?情感分類(lèi)模型實(shí)現(xiàn)
有了輸入特征,模型訓(xùn)練部分就比較簡(jiǎn)單了,尤其是有Keras這樣的工具。
Keras是一個(gè)高層神經(jīng)網(wǎng)絡(luò)API,純python編寫(xiě)并使用Tensorflow等框架作為后端,特點(diǎn)是簡(jiǎn)潔、快速。
直接使用pip或conda指令即可安裝Keras和Tensorflow。
#?使用國(guó)內(nèi)鏡像加速安裝
$?pip?install?keras?-i?https://pypi.douban.com/simple
$?pip?install?tensorflow?-i?https://pypi.douban.com/simple
使用Keras實(shí)現(xiàn)一個(gè)神經(jīng)網(wǎng)絡(luò)模型大致分四步:
定義訓(xùn)練數(shù)據(jù):輸入張量和目標(biāo)張量 逐層定義網(wǎng)絡(luò),將輸入映射到目標(biāo) 配置學(xué)習(xí)過(guò)程:選擇損失函數(shù)、優(yōu)化器和監(jiān)控指標(biāo) 調(diào)用模型的 fit 方法在訓(xùn)練數(shù)據(jù)上多次迭代
我們直接使用使用Sequential類(lèi)來(lái)定義模型(僅用于層的線性堆疊,是最常見(jiàn)的網(wǎng)絡(luò)架構(gòu))。
from?keras.models?import?Sequential
from?keras.layers?import?Dense,?Dropout
import?tensorflow?as?tf
model?=?Sequential()
#?搭建模型
model.add(Dense(32,?activation='relu',?input_shape=(768,)))
model.add(Dropout(0.3))
model.add(Dense(32,?activation='relu'))
model.add(Dense(1,?activation='sigmoid'))
對(duì)于簡(jiǎn)單的二分類(lèi)問(wèn)題,使用Dense全連接層已經(jīng)足夠,最后的輸出是0~1之間的小數(shù),代表了正面/負(fù)面情感的概率。為了防止過(guò)擬合,在模型中加入了Dropout層,
接下來(lái),我們指定模型使用的優(yōu)化器和損失函數(shù),以及訓(xùn)練過(guò)程中想要監(jiān)控的指標(biāo)。
model.compile(
????loss='binary_crossentropy',
????optimizer=tf.train.AdamOptimizer(),
????metrics=['acc']
)
最后,通過(guò)fit方法將輸入數(shù)據(jù)傳入模型。我們留出20%的數(shù)據(jù)作為驗(yàn)證集:
history?=?model.fit(
????X_train,?y_train,
????epochs=30,
????batch_size=128,
????validation_split=0.2,
????verbose=1
)
模型開(kāi)始迭代訓(xùn)練了!
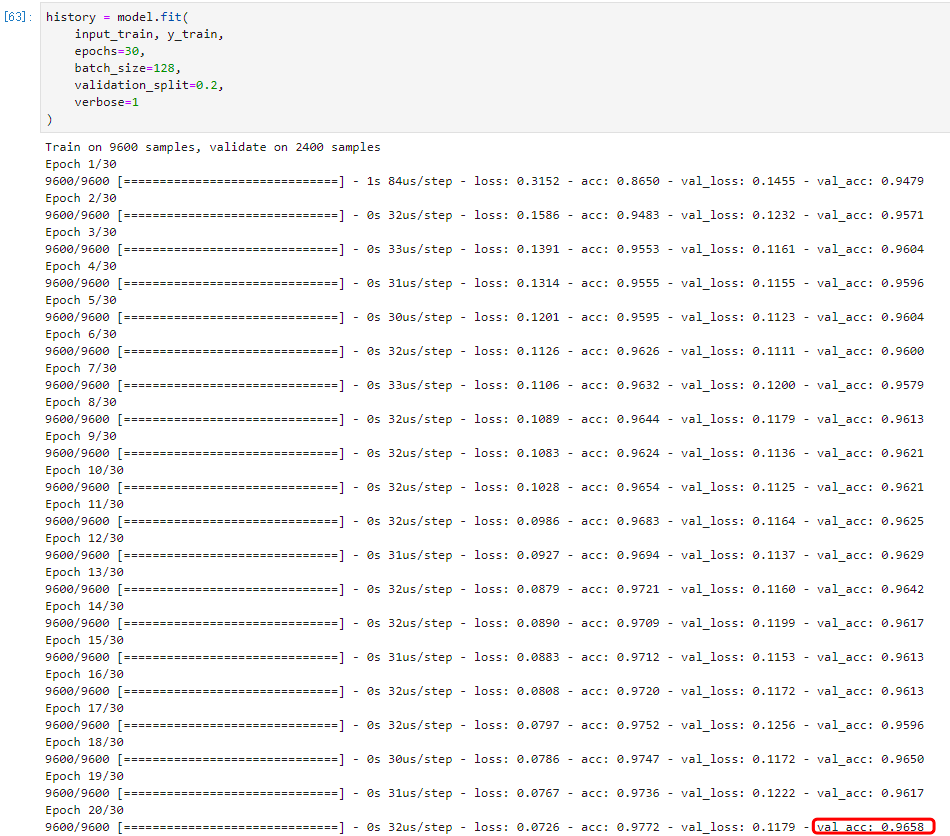
觀察發(fā)現(xiàn),隨著迭代次數(shù)的增加,模型損失逐漸下降,準(zhǔn)確度逐漸上升,直到趨于穩(wěn)定。
運(yùn)行結(jié)束后,使用matplotlib庫(kù)將結(jié)果可視化呈現(xiàn)。
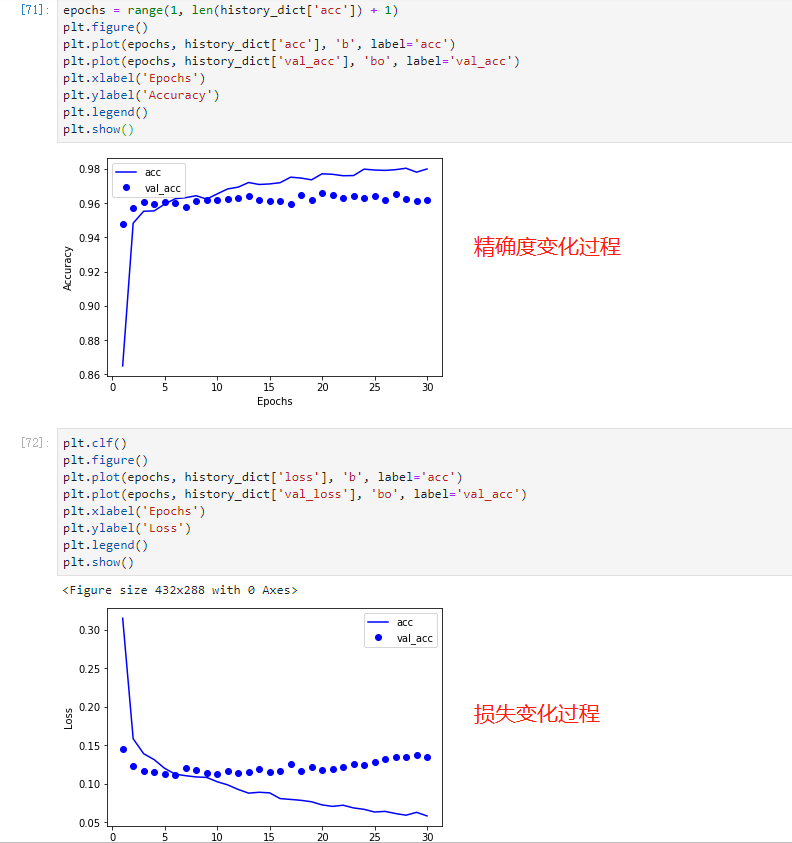
因?yàn)槿蝿?wù)比較簡(jiǎn)單,加上Bert的特征抽取能力,模型對(duì)于判別好評(píng)還是差評(píng)有96%的準(zhǔn)確率!
另外還有1600條數(shù)據(jù)當(dāng)作測(cè)試集沒(méi)有使用,調(diào)用evaluate方法測(cè)試:
test_loss?=?model.evaluate(
????X_test,
????y_test,
????batch_size=64,
????verbose=1
)
print(test_loss)
得到結(jié)果:[0.079560, 0.973125],表示測(cè)試集損失和準(zhǔn)確率分別為0.07和97%。
04?小結(jié)
本文是NLP情感分類(lèi)任務(wù)的入門(mén)和實(shí)現(xiàn),可以讓讀者利用簡(jiǎn)單的數(shù)據(jù)和工具實(shí)現(xiàn)一個(gè)分類(lèi)模型。整個(gè)過(guò)程涉及了數(shù)據(jù)處理、特征編碼、模型訓(xùn)練和結(jié)果分析。
實(shí)際開(kāi)發(fā)中,使用的模型和特征抽取方法會(huì)更加復(fù)雜,涉及更嚴(yán)格的測(cè)試和部署環(huán)節(jié)。今后的文章中我們將為讀者繼續(xù)呈現(xiàn)!
推? 薦? 閱? 讀
天池NLP賽道top指南 萬(wàn)萬(wàn)沒(méi)想到,BERT學(xué)會(huì)寫(xiě)SQL了 騰訊、百度、滴滴最新NLP算法面經(jīng) 從零實(shí)現(xiàn)爬蟲(chóng)和情感分類(lèi)(一) 文本匹配利器:從孿生網(wǎng)絡(luò)到Sentence-BERT綜述
參考資料
由于微信平臺(tái)算法改版,訂閱號(hào)內(nèi)容將不再以時(shí)間排序展示,如果大家想第一時(shí)間看到我們的推送,強(qiáng)烈建議星標(biāo)我們幫我們點(diǎn)【在看】。星標(biāo)具體步驟:
(1)點(diǎn)擊頁(yè)面最上方“NLP情報(bào)局”,進(jìn)入主頁(yè)
(2)點(diǎn)擊右上角的小點(diǎn)點(diǎn),在彈出頁(yè)面點(diǎn)擊“設(shè)為星標(biāo)”,就可以啦
感謝支持??
原創(chuàng)不易,有收獲的話請(qǐng)幫忙點(diǎn)擊分享、點(diǎn)贊、在看??