
基于深度學(xué)習(xí)的自然圖像和醫(yī)學(xué)圖像分割:網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)

極市導(dǎo)讀
?在利用CNNs進(jìn)行圖像語義分割時(shí),有一些針對(duì)網(wǎng)絡(luò)結(jié)構(gòu)的創(chuàng)新點(diǎn),主要包括了新神經(jīng)架構(gòu)和新組件或?qū)拥脑O(shè)計(jì)。文章的后半部分則對(duì)醫(yī)學(xué)圖像分割領(lǐng)域中網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)的應(yīng)用進(jìn)行了梳理。>>>極市七夕粉絲福利活動(dòng):煉丹師們,七夕這道算法題,你會(huì)解嗎?
1. 圖像語義分割網(wǎng)絡(luò)結(jié)構(gòu)創(chuàng)新
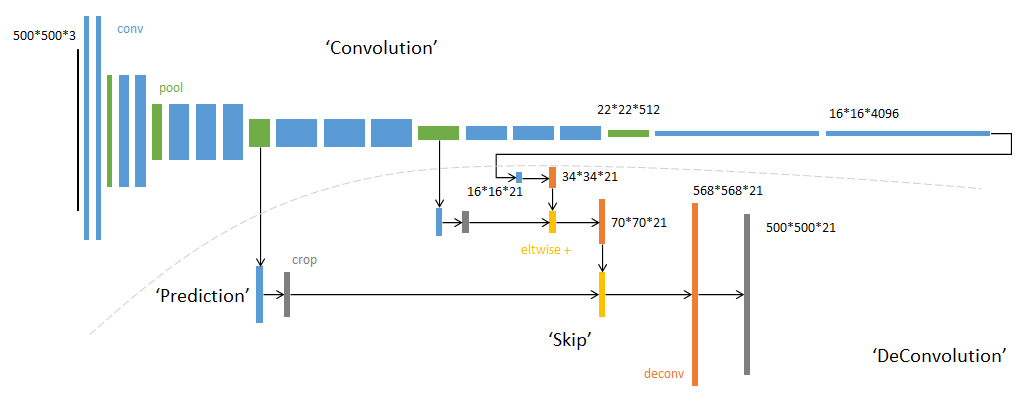
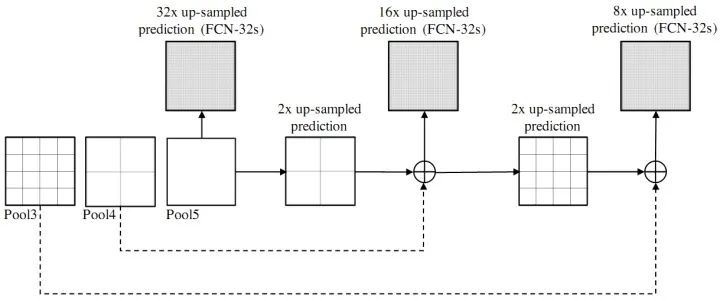
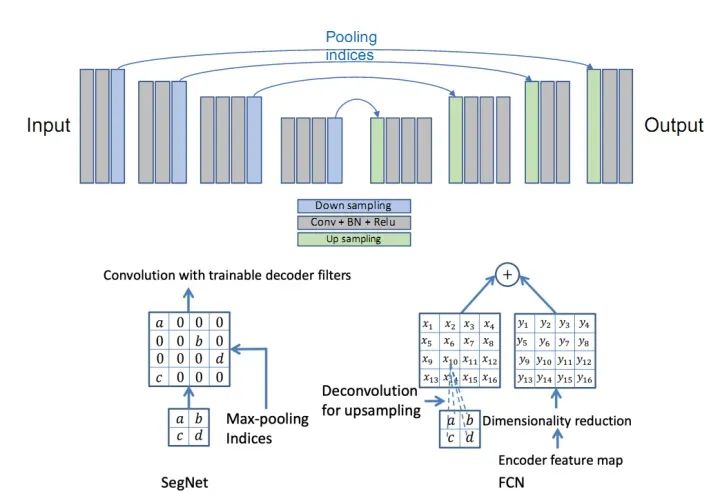
SegNet和FCN網(wǎng)絡(luò)的思路基本一致。編碼器部分使用VGG16的前13層卷積,不同點(diǎn)在于Decoder部分Upsampling的方式。FCN通過將特征圖deconv得到的結(jié)果與編碼器對(duì)應(yīng)大小的特征圖相加得到上采樣結(jié)果;而SegNet用Encoder部分maxpool的索引進(jìn)行Decoder部分的上采樣(原文描述:the decoder upsamples the lower resolution input feature maps. Speci?cally, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling.)。

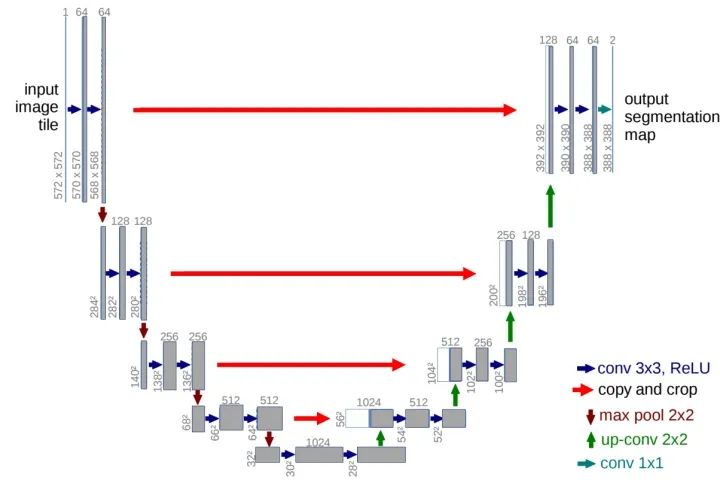
U-Net網(wǎng)絡(luò)最初是針對(duì)生物醫(yī)學(xué)圖像設(shè)計(jì)的,但由于其初四的性能,現(xiàn)如今UNet及其變體已經(jīng)廣泛應(yīng)用到CV各個(gè)子領(lǐng)域。UNet網(wǎng)絡(luò)由U通道和短接通道(skip-connection)組成,U通道類似于SegNet的編解碼結(jié)構(gòu),其中編碼部分(contracting path)進(jìn)行特征提取和捕獲上下文信息,解碼部分(expanding path)用解碼特征圖來預(yù)測像素標(biāo)簽。短接通道提高了模型精度并解決了梯度消失問題,特別要注意的是短接通道特征圖與上采用特征圖是拼接而不是相加(不同于FCN)。
V-Net網(wǎng)絡(luò)結(jié)構(gòu)與U-Net類似,不同在于該架構(gòu)增加了跳躍連接,并用3D操作物替換了2D操作以處理3D圖像(volumetric image)。并且針對(duì)廣泛使用的細(xì)分指標(biāo)(如Dice)進(jìn)行優(yōu)化。

FC-DenseNet (百層提拉米蘇網(wǎng)絡(luò))(paper title: The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation)該網(wǎng)絡(luò)結(jié)構(gòu)是由用密集連接塊(Dense Block)和UNet架構(gòu)組建的。該網(wǎng)絡(luò)最簡單的版本是由向下過渡的兩個(gè)下采樣路徑和向上過渡的兩個(gè)上采樣路徑組成。且同樣包含兩個(gè)水平跳躍連接,將來自下采樣路徑的特征圖與上采樣路徑中的相應(yīng)特征圖拼接在一起。上采樣路徑和下采樣路徑中的連接模式不完全同:下采樣路徑中,每個(gè)密集塊外有一條跳躍拼接通路,從而導(dǎo)致特征圖數(shù)量的線性增長,而在上采樣路徑中沒有此操作。(多說一句,這個(gè)網(wǎng)絡(luò)的簡稱可以是Dense Unet,但是有一篇論文叫Fully Dense UNet for 2D Sparse Photoacoustic Tomography Artifact Removal, 是一個(gè)光聲成像去偽影的論文,我看到過好多博客引用這篇論文里面的插圖來談?wù)Z義分割,根本就不是一碼事好么 =_=||,自己能分清即可。)

Deeplab系列網(wǎng)絡(luò)是在編解碼結(jié)構(gòu)的基礎(chǔ)上提出的改進(jìn)版本,2018年DeeplabV3+網(wǎng)絡(luò)在VOC2012和Cityscapes數(shù)據(jù)集上的表現(xiàn)優(yōu)異,達(dá)到SOTA水平。DeepLab系列共有V1、V2、V3和V3+共四篇論文。簡要總結(jié)一些各篇論文的核心內(nèi)容:

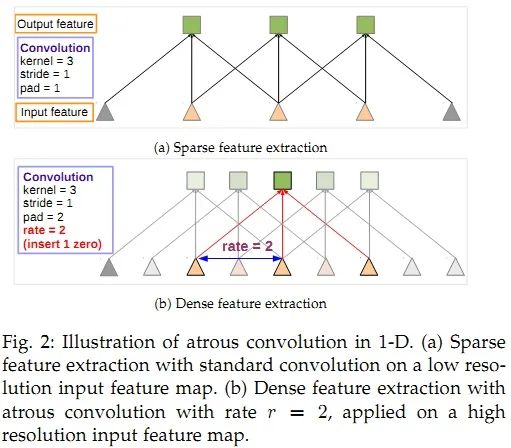




PSPNet(pyramid scene parsing network)通過對(duì)不同區(qū)域的上下文信息進(jìn)行聚合,提升了網(wǎng)絡(luò)利用全局上下文信息的能力。在SPPNet,金字塔池化生成的不同層次的特征圖最終被flatten并concate起來,再送入全連接層以進(jìn)行分類,消除了CNN要求圖像分類輸入大小固定的限制。而在PSPNet中,使用的策略是:poolling-conv-upsample,然后拼接得到特征圖,然后進(jìn)行標(biāo)簽預(yù)測。
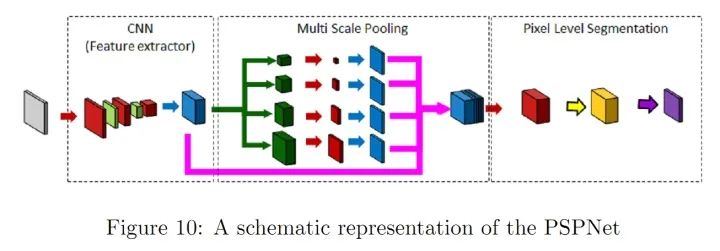
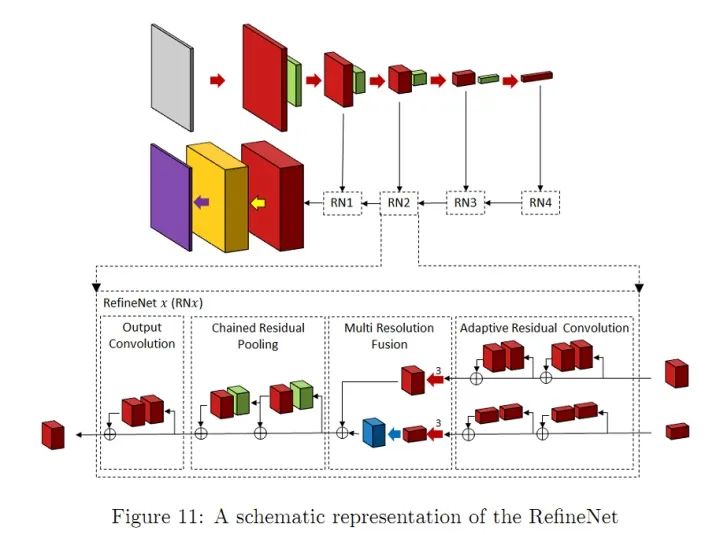
RefineNet通過細(xì)化中間激活映射并分層地將其連接到結(jié)合多尺度激活,同時(shí)防止銳度損失。網(wǎng)絡(luò)由獨(dú)立的Refine模塊組成,每個(gè)Refine模塊由三個(gè)主要模塊組成,即:剩余卷積單元(RCU),多分辨率融合(MRF)和鏈?zhǔn)S喑?CRP)。整體結(jié)構(gòu)有點(diǎn)類似U-Net,但在跳躍連接處設(shè)計(jì)了新的組合方式(不是簡單的concat)。個(gè)人認(rèn)為,這種結(jié)構(gòu)其實(shí)非常適合作為自己網(wǎng)絡(luò)設(shè)計(jì)的思路,可以加入許多其他CV問題中使用的CNN module,而且以U-Net為整體框架,效果不會(huì)太差。
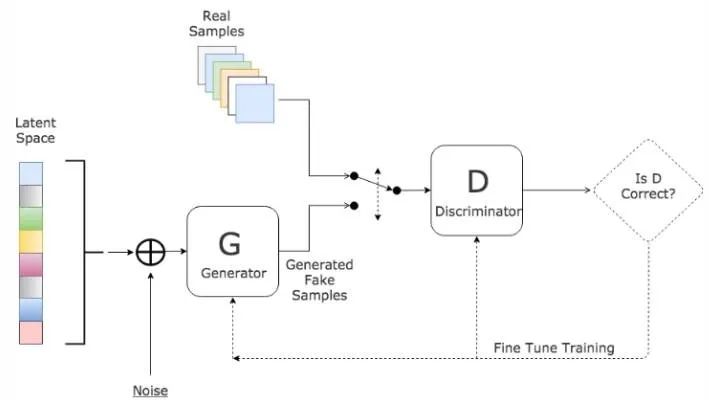

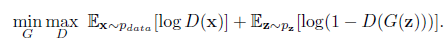
2. 網(wǎng)絡(luò)結(jié)構(gòu)創(chuàng)新在醫(yī)學(xué)圖像分割中的應(yīng)用
推薦閱讀

評(píng)論
圖片
表情