來自 | 知乎 作者 | luoxd
鏈接 | https://zhuanlan.zhihu.com/p/257109614
準(zhǔn)確、魯棒地從醫(yī)學(xué)圖像中分割出器官或病變在許多臨床應(yīng)用中起著至關(guān)重要的作用,如診斷和治療計劃。隨著標(biāo)注數(shù)據(jù)的大量增加,深度學(xué)習(xí)在圖像分割方面獲得了巨大地成功。然而,對于醫(yī)學(xué)圖像來說,標(biāo)注數(shù)據(jù)的獲取通常是昂貴的,因為生成準(zhǔn)確的注釋需要專業(yè)知識和時間,特別是在三維圖像中。為了降低標(biāo)記成本,近年來人們提出了許多方法來開發(fā)一種高性能的醫(yī)學(xué)圖像分割模型,以減少標(biāo)記數(shù)據(jù)。例如,將用戶交互與深度神經(jīng)網(wǎng)絡(luò)相結(jié)合,交互式地進行圖像分割,可以減少標(biāo)記的工作量。自監(jiān)督學(xué)習(xí)方法是利用無標(biāo)簽數(shù)據(jù),以監(jiān)督的方式訓(xùn)練模型,學(xué)習(xí)基礎(chǔ)知識然后進行知識遷移。半監(jiān)督學(xué)習(xí)框架直接從有限地帶標(biāo)簽數(shù)據(jù)和大量的未帶標(biāo)簽數(shù)據(jù)中學(xué)習(xí),得到高質(zhì)量的分割結(jié)果。弱監(jiān)督學(xué)習(xí)方法從邊框、涂鴉或圖像級標(biāo)簽中學(xué)習(xí)圖像分割,而不是使用像素級標(biāo)注,這減少了標(biāo)注的負(fù)擔(dān)。但是,弱監(jiān)督學(xué)習(xí)和自監(jiān)督學(xué)習(xí)在醫(yī)學(xué)圖像分割任務(wù)上性能依舊受限,尤其是在三維醫(yī)學(xué)圖像的分割上。除此之外,少量標(biāo)注數(shù)據(jù)和大量未標(biāo)注數(shù)據(jù)更加符合實際臨床場景。本文總結(jié)了近些年出現(xiàn)的用于醫(yī)學(xué)影像的半監(jiān)督學(xué)習(xí)方法,這些方法大致可以分為:
(1)基于數(shù)據(jù)擾動或模型擾動或數(shù)據(jù)模型同時擾動正則化;為了方便更多的人研究和使用半監(jiān)督學(xué)習(xí)算法來充分利用未標(biāo)注數(shù)據(jù),我們開始了一個半監(jiān)督分割學(xué)習(xí)的總結(jié)小項目,包含了最新論文總結(jié)、經(jīng)典算法實現(xiàn)、和搭建了開箱即用的半監(jiān)督醫(yī)學(xué)圖像分割示例,具體內(nèi)容可參見https://github.com/HiLab-git/SSL4MIS1. TCSM-V1: Semi-supervised Skin Lesion Segmentation via Transformation Consistent Self-ensembling Model. (BMVC2018)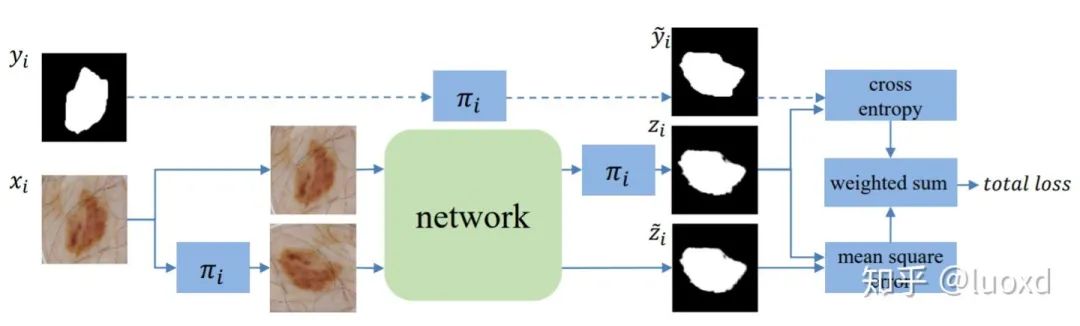 總結(jié):這篇文章的方法類似于Temporal ensembling for semi-supervised learning(ICLR2017)通過給輸入數(shù)據(jù)加擾動(transformation)來正則化模型 (一次迭代模型需要前向傳播兩次,輸入分別是未變化的圖像和變化后的圖像,然后變化后圖像得到的結(jié)果進行反變換然后構(gòu)建這兩個預(yù)測結(jié)果的一致性損失),直接將未標(biāo)注數(shù)據(jù)利用起來,想法很簡潔但效果很不錯。2. TCSM-V2: Transformation-Consistent Self-Ensembling Model for Semisupervised Medical Image Segmentation. (TNNLS2020)
總結(jié):這篇文章的方法類似于Temporal ensembling for semi-supervised learning(ICLR2017)通過給輸入數(shù)據(jù)加擾動(transformation)來正則化模型 (一次迭代模型需要前向傳播兩次,輸入分別是未變化的圖像和變化后的圖像,然后變化后圖像得到的結(jié)果進行反變換然后構(gòu)建這兩個預(yù)測結(jié)果的一致性損失),直接將未標(biāo)注數(shù)據(jù)利用起來,想法很簡潔但效果很不錯。2. TCSM-V2: Transformation-Consistent Self-Ensembling Model for Semisupervised Medical Image Segmentation. (TNNLS2020)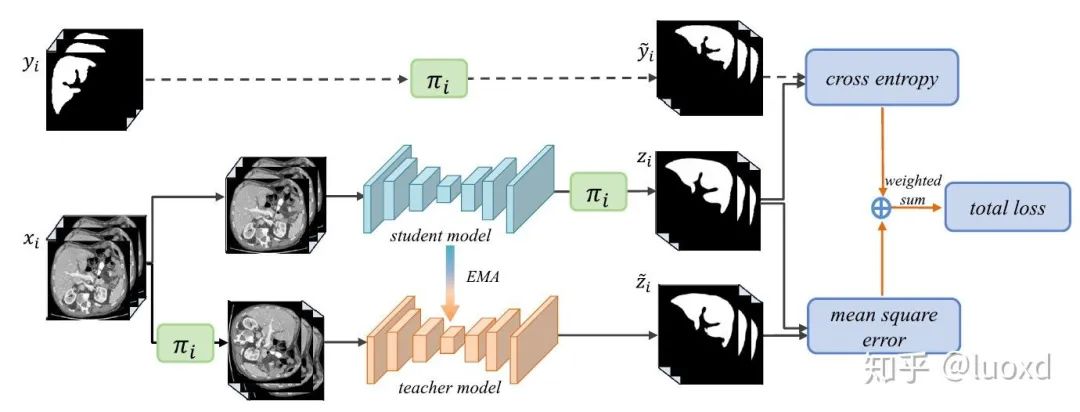 總結(jié):這篇在Mean Teacher (NIPS2017) 的基礎(chǔ)上引入了更多的數(shù)據(jù)擾動(flip, rotate, rescale,noise等等)和模型擾動(dropout)來構(gòu)建同一輸入在不同擾動下的一致性。然后取得了很不錯的效果。https://github.com/xmengli999/TCSM3. Uncertainty-aware Self-ensembling Model for Semi-supervised 3D Left Atrium Segmentation (MICCAI2019)
總結(jié):這篇在Mean Teacher (NIPS2017) 的基礎(chǔ)上引入了更多的數(shù)據(jù)擾動(flip, rotate, rescale,noise等等)和模型擾動(dropout)來構(gòu)建同一輸入在不同擾動下的一致性。然后取得了很不錯的效果。https://github.com/xmengli999/TCSM3. Uncertainty-aware Self-ensembling Model for Semi-supervised 3D Left Atrium Segmentation (MICCAI2019)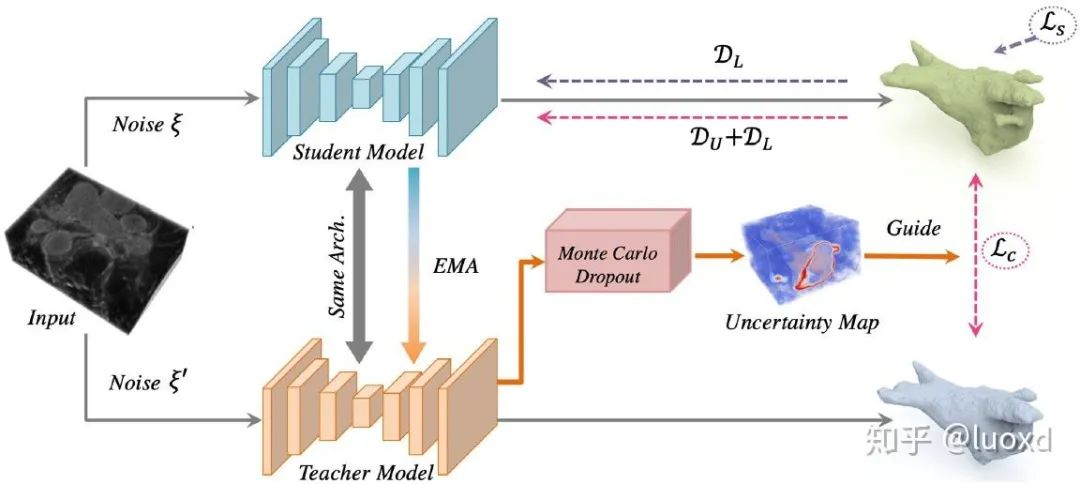 總結(jié):這篇文章整合了Mean Teacher (NIPS2017) 和不確定性估計來進行半監(jiān)督學(xué)習(xí),通過不確定性圖來指導(dǎo)(加權(quán))Mean Teacher模型從未標(biāo)注的數(shù)據(jù)上逐步學(xué)習(xí)。不確定性圖的計算采用了經(jīng)典的蒙特卡洛 Dropout多次推理來獲得,這樣會帶來一些額外的計算開銷,但帶來了性能的提升,可以得到不錯的效果,而且現(xiàn)在利用不確定性估計來提高網(wǎng)絡(luò)性能也是一個熱門的研究方向。https://github.com/yulequan/UA-MT值得一提的是,Dr. Lequan的代碼寫得非常簡潔易學(xué),后續(xù)也有很多在此基礎(chǔ)上改進的算法。4. 3D Semi-Supervised Learning with Uncertainty-Aware Multi-View Co-Training (WACV2020,MedIA2020)
總結(jié):這篇文章整合了Mean Teacher (NIPS2017) 和不確定性估計來進行半監(jiān)督學(xué)習(xí),通過不確定性圖來指導(dǎo)(加權(quán))Mean Teacher模型從未標(biāo)注的數(shù)據(jù)上逐步學(xué)習(xí)。不確定性圖的計算采用了經(jīng)典的蒙特卡洛 Dropout多次推理來獲得,這樣會帶來一些額外的計算開銷,但帶來了性能的提升,可以得到不錯的效果,而且現(xiàn)在利用不確定性估計來提高網(wǎng)絡(luò)性能也是一個熱門的研究方向。https://github.com/yulequan/UA-MT值得一提的是,Dr. Lequan的代碼寫得非常簡潔易學(xué),后續(xù)也有很多在此基礎(chǔ)上改進的算法。4. 3D Semi-Supervised Learning with Uncertainty-Aware Multi-View Co-Training (WACV2020,MedIA2020)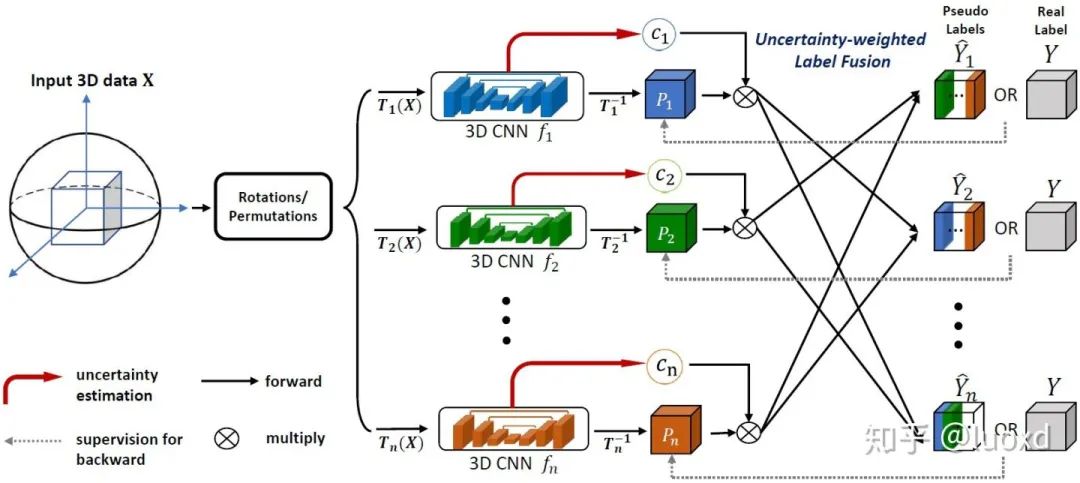 總結(jié):這篇文章結(jié)合了前面提到的幾篇的所有特點(沒有采用Mean Teacher Model),并將多視角的聯(lián)合訓(xùn)練引入到醫(yī)學(xué)圖像的半監(jiān)督和域適應(yīng)的問題中,想法很新穎,實現(xiàn)也不難,而且效果很不錯,只是隨著視角的不斷增加計算開銷會越來越大。5. Shape-aware Semi-supervised 3D Semantic Segmentation for Medical Images (MICCAI2020)
總結(jié):這篇文章結(jié)合了前面提到的幾篇的所有特點(沒有采用Mean Teacher Model),并將多視角的聯(lián)合訓(xùn)練引入到醫(yī)學(xué)圖像的半監(jiān)督和域適應(yīng)的問題中,想法很新穎,實現(xiàn)也不難,而且效果很不錯,只是隨著視角的不斷增加計算開銷會越來越大。5. Shape-aware Semi-supervised 3D Semantic Segmentation for Medical Images (MICCAI2020)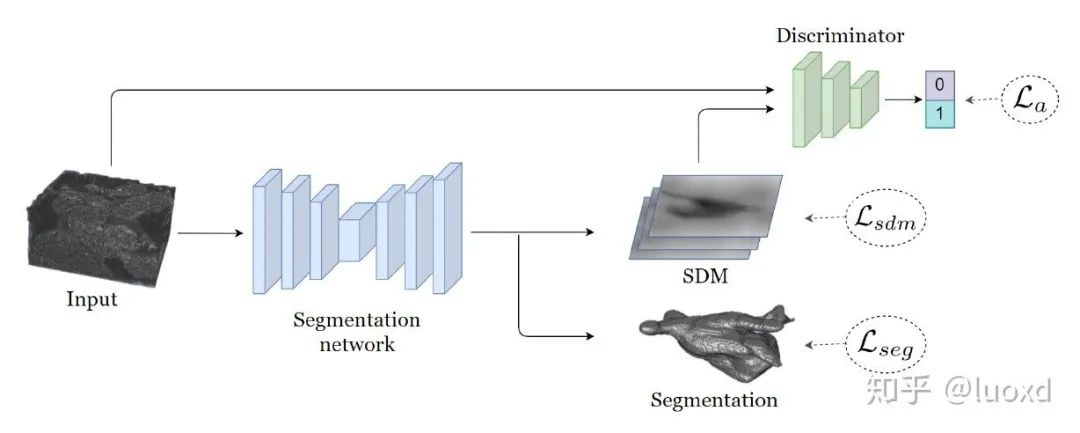 總結(jié): 這篇文章采用了一個常用的多任務(wù)網(wǎng)絡(luò)結(jié)構(gòu),同時進行圖像分割和帶符號的距離圖回歸(引入了形狀和位置先驗),并用判別器來作為正則化項,與以前常見用判別器做正則化項方法不同的是,本文的判別器輸入時帶符號的距離圖和原圖,而不是分割結(jié)果和原圖。這樣設(shè)計可以使整個未標(biāo)記數(shù)據(jù)集的預(yù)測分布平滑,并引入了很強的形狀和位置先驗信息,保證分割結(jié)果的穩(wěn)定性和魯棒性。https://github.com/kleinzcy/SASSnet6. Semi-supervised Medical Image Segmentation through Dual-task Consistency (Arxiv)
總結(jié): 這篇文章采用了一個常用的多任務(wù)網(wǎng)絡(luò)結(jié)構(gòu),同時進行圖像分割和帶符號的距離圖回歸(引入了形狀和位置先驗),并用判別器來作為正則化項,與以前常見用判別器做正則化項方法不同的是,本文的判別器輸入時帶符號的距離圖和原圖,而不是分割結(jié)果和原圖。這樣設(shè)計可以使整個未標(biāo)記數(shù)據(jù)集的預(yù)測分布平滑,并引入了很強的形狀和位置先驗信息,保證分割結(jié)果的穩(wěn)定性和魯棒性。https://github.com/kleinzcy/SASSnet6. Semi-supervised Medical Image Segmentation through Dual-task Consistency (Arxiv)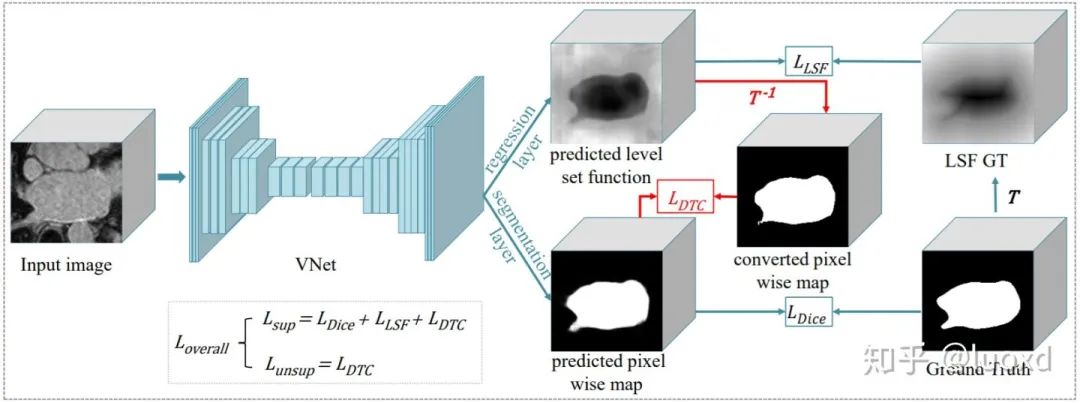 總結(jié): 前面五篇文章主要還是基于數(shù)據(jù)層面和模型層面的擾動來構(gòu)建一致性來進行半監(jiān)督學(xué)習(xí)。本文(DTC)從任務(wù)層面來構(gòu)建了一致性進行半監(jiān)督學(xué)習(xí),與SASSNet一樣本文采用了一個多任務(wù)網(wǎng)絡(luò)結(jié)構(gòu),同時進行分割和水平集函數(shù)回歸,不同的是SASSNet用判別器來進行正則化(data-level),而本文利用兩個任務(wù)之間的表示差異來構(gòu)建一致性(task-level)。與Mean Teacher等模型需要多次前向傳播相比,DTC模型簡單,計算開銷也不大,除此之外,還有可以構(gòu)建許多跨任務(wù)的一致性進行全監(jiān)督,半監(jiān)督或者是跨域(DA)學(xué)習(xí)。https://github.com/Luoxd1996/DTC以上論文更多細(xì)節(jié)和實驗結(jié)果可以參考這些論文原文,此處只是個人的近期總結(jié),更多內(nèi)容也歡迎大家補充,也希望大家能設(shè)計出更好的半監(jiān)督學(xué)習(xí)算法來降低對標(biāo)注數(shù)據(jù)的依賴。
總結(jié): 前面五篇文章主要還是基于數(shù)據(jù)層面和模型層面的擾動來構(gòu)建一致性來進行半監(jiān)督學(xué)習(xí)。本文(DTC)從任務(wù)層面來構(gòu)建了一致性進行半監(jiān)督學(xué)習(xí),與SASSNet一樣本文采用了一個多任務(wù)網(wǎng)絡(luò)結(jié)構(gòu),同時進行分割和水平集函數(shù)回歸,不同的是SASSNet用判別器來進行正則化(data-level),而本文利用兩個任務(wù)之間的表示差異來構(gòu)建一致性(task-level)。與Mean Teacher等模型需要多次前向傳播相比,DTC模型簡單,計算開銷也不大,除此之外,還有可以構(gòu)建許多跨任務(wù)的一致性進行全監(jiān)督,半監(jiān)督或者是跨域(DA)學(xué)習(xí)。https://github.com/Luoxd1996/DTC以上論文更多細(xì)節(jié)和實驗結(jié)果可以參考這些論文原文,此處只是個人的近期總結(jié),更多內(nèi)容也歡迎大家補充,也希望大家能設(shè)計出更好的半監(jiān)督學(xué)習(xí)算法來降低對標(biāo)注數(shù)據(jù)的依賴。

戳我,查看GAN的系列專輯~!