
一文看懂深度學(xué)習(xí)模型壓縮和加速
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

本文轉(zhuǎn)自:opencv學(xué)堂
近年來(lái)深度學(xué)習(xí)模型在計(jì)算機(jī)視覺(jué)、自然語(yǔ)言處理、搜索推薦廣告等各種領(lǐng)域,不斷刷新傳統(tǒng)模型性能,并得到了廣泛應(yīng)用。隨著移動(dòng)端設(shè)備計(jì)算能力的不斷提升,移動(dòng)端AI落地也成為了可能。相比于服務(wù)端,移動(dòng)端模型的優(yōu)勢(shì)有:
減輕服務(wù)端計(jì)算壓力,并利用云端一體化實(shí)現(xiàn)負(fù)載均衡。特別是在雙11等大促場(chǎng)景,服務(wù)端需要部署很多高性能機(jī)器,才能應(yīng)對(duì)用戶(hù)流量洪峰。平時(shí)用戶(hù)訪問(wèn)又沒(méi)那么集中,存在巨大的流量不均衡問(wèn)題。直接將模型部署到移動(dòng)端,并在置信度較高情況下直接返回結(jié)果,而不需要請(qǐng)求服務(wù)端,可以大大節(jié)省服務(wù)端計(jì)算資源。同時(shí)在大促期間降低置信度閾值,平時(shí)又調(diào)高,可以充分實(shí)現(xiàn)云端一體負(fù)載均衡。
實(shí)時(shí)性好,響應(yīng)速度快。在feed流推薦和物體實(shí)時(shí)檢測(cè)等場(chǎng)景,需要根據(jù)用戶(hù)數(shù)據(jù)的變化,進(jìn)行實(shí)時(shí)計(jì)算推理。如果是采用服務(wù)端方案,則響應(yīng)速度得不到保障,且易造成請(qǐng)求過(guò)于密集的問(wèn)題。利用端計(jì)算能力,則可以實(shí)現(xiàn)實(shí)時(shí)計(jì)算。
穩(wěn)定性高,可靠性好。在斷網(wǎng)或者弱網(wǎng)情況下,請(qǐng)求服務(wù)端會(huì)出現(xiàn)失敗。而采用端計(jì)算,則不會(huì)出現(xiàn)這種情況。在無(wú)人車(chē)和自動(dòng)駕駛等可靠性要求很高的場(chǎng)景下,這一點(diǎn)尤為關(guān)鍵,可以保證在隧道、山區(qū)等場(chǎng)景下仍能穩(wěn)定運(yùn)行。
安全性高,用戶(hù)隱私保護(hù)好。由于直接在端上做推理,不需要將用戶(hù)數(shù)據(jù)傳輸?shù)椒?wù)端,免去了網(wǎng)絡(luò)通信中用戶(hù)隱私泄露風(fēng)險(xiǎn),也規(guī)避了服務(wù)端隱私泄露問(wèn)題
移動(dòng)端部署深度學(xué)習(xí)模型也有很大的挑戰(zhàn)。主要表現(xiàn)在,移動(dòng)端等嵌入式設(shè)備,在計(jì)算能力、存儲(chǔ)資源、電池電量等方面均是受限的。故移動(dòng)端模型必須滿(mǎn)足模型尺寸小、計(jì)算復(fù)雜度低、電池耗電量低、下發(fā)更新部署靈活等條件。因此模型壓縮和加速就成為了目前移動(dòng)端AI的一個(gè)熱門(mén)話(huà)題。
模型壓縮和加速不僅僅可以提升移動(dòng)端模型性能,在服務(wù)端也可以大大加快推理響應(yīng)速度,并減少服務(wù)器資源消耗,大大降低成本。結(jié)合移動(dòng)端AI模型和服務(wù)端模型,實(shí)現(xiàn)云端一體化,是目前越來(lái)越廣泛采用的方案。
模型壓縮和加速是兩個(gè)不同的話(huà)題,有時(shí)候壓縮并不一定能帶來(lái)加速的效果,有時(shí)候又是相輔相成的。壓縮重點(diǎn)在于減少網(wǎng)絡(luò)參數(shù)量,加速則側(cè)重在降低計(jì)算復(fù)雜度、提升并行能力等。模型壓縮和加速可以從多個(gè)角度來(lái)優(yōu)化。總體來(lái)看,個(gè)人認(rèn)為主要分為三個(gè)層次:
算法層壓縮加速。這個(gè)維度主要在算法應(yīng)用層,也是大多數(shù)算法工程師的工作范疇。主要包括結(jié)構(gòu)優(yōu)化(如矩陣分解、分組卷積、小卷積核等)、量化與定點(diǎn)化、模型剪枝、模型蒸餾等。
框架層加速。這個(gè)維度主要在算法框架層,比如tf-lite、NCNN、MNN等。主要包括編譯優(yōu)化、緩存優(yōu)化、稀疏存儲(chǔ)和計(jì)算、NEON指令應(yīng)用、算子優(yōu)化等
硬件層加速。這個(gè)維度主要在AI硬件芯片層,目前有GPU、FPGA、ASIC等多種方案,各種TPU、NPU就是ASIC這種方案,通過(guò)專(zhuān)門(mén)為深度學(xué)習(xí)進(jìn)行芯片定制,大大加速模型運(yùn)行速度。
下面也會(huì)分算法層、框架層和硬件層三個(gè)方面進(jìn)行介紹。
2.1 結(jié)構(gòu)優(yōu)化
2.1.1 矩陣分解
舉個(gè)例子,將M*N的矩陣分解為M*K + K*N,只要讓K<<M 且 K << N,就可以大大降低模型體積。比如在ALBERT的embedding層,就做了矩陣分解的優(yōu)化。如下圖所示
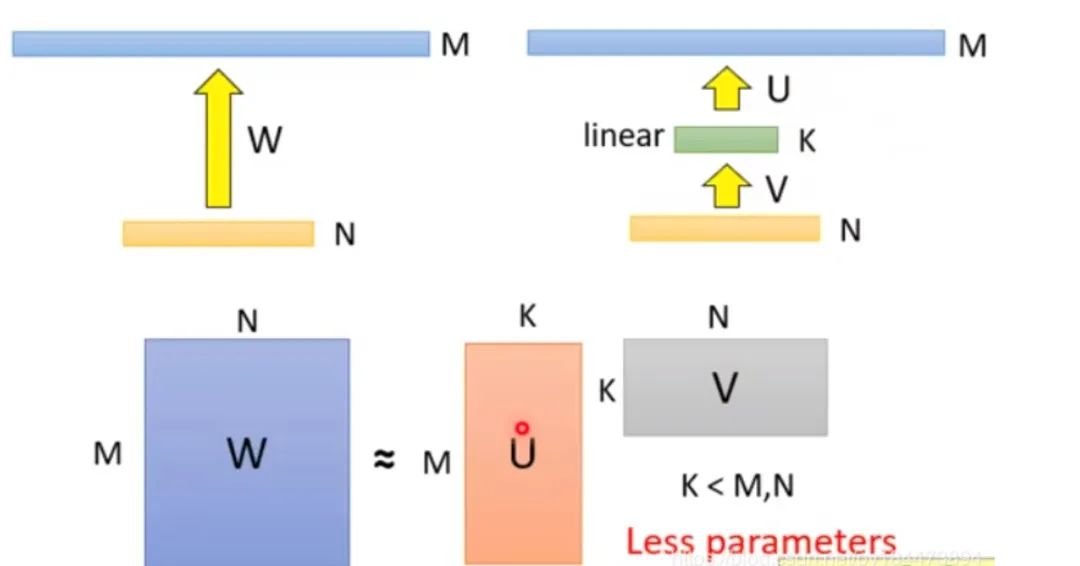
其中M為詞表長(zhǎng)度,也就是vocab_size,典型值為21128。N為隱層大小,典型值為1024,也就是hidden_size。K為我們?cè)O(shè)置的低維詞嵌入空間,可以設(shè)置為128。
分解前:矩陣參數(shù)量為 (M * N)
分解后:參數(shù)量為 (M*K + K*N)
壓縮量:(M * N) / (M*K + K*N), 由于M遠(yuǎn)大于N,故可近似為 N / k,當(dāng)N=2014,k=128時(shí),可以壓縮8倍
2.1.2 權(quán)值共享
相對(duì)于DNN全連接參數(shù)量過(guò)大的問(wèn)題,CNN提出了局部感受野和權(quán)值共享的概念。在NLP中同樣也有類(lèi)似應(yīng)用的場(chǎng)景。比如ALBert中,12層共用同一套參數(shù),包括multi-head self attention和feed-forward,從而使得參數(shù)量降低到原來(lái)的1/12。這個(gè)方案對(duì)于模型壓縮作用很大,但對(duì)于推理加速則收效甚微。因?yàn)楣蚕頇?quán)值并沒(méi)有帶來(lái)計(jì)算量的減少。
2.1.3 分組卷積
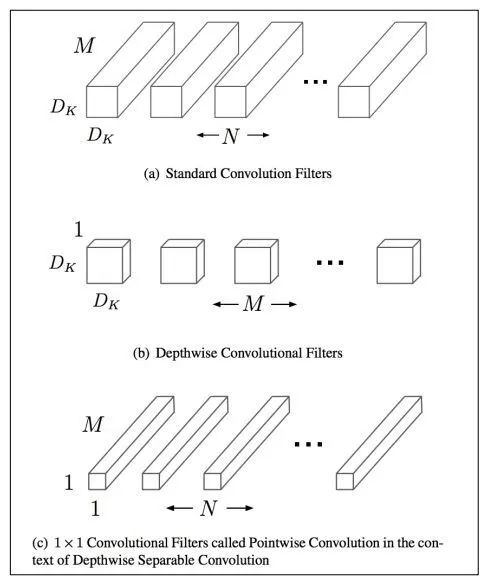
在視覺(jué)模型中應(yīng)用較為廣泛,比如shuffleNet,mobileNet等。我們以mobileNet為例。對(duì)于常規(guī)的M輸入通道,N輸出通道,dk*dk的kernel size的卷積,需要參數(shù)量為 M*N*dk*dk。這是因?yàn)槊總€(gè)輸入通道,都會(huì)抽取N種特征(對(duì)應(yīng)輸出通道數(shù)),不同的輸入通道需要不同的kernel來(lái)做抽取,然后疊加起來(lái)。故M個(gè)輸入通道,N個(gè)輸出通道,就需要M*N個(gè)kernel了。
mobileNet對(duì)常規(guī)卷積做了優(yōu)化,每個(gè)輸入通道,僅需要一個(gè)kernel做特征提取,這叫做depth wise。如此M個(gè)通道可得到M個(gè)feature map。但我們想要的是N通道輸出,怎么辦呢?mobileNet采用一個(gè)常規(guī)1*1卷積來(lái)處理這個(gè)連接,從而轉(zhuǎn)化到N個(gè)輸出通道上。總結(jié)下來(lái),mobileNet利用一個(gè)dk*dk的depth wise卷積和一個(gè)1*1的point wise卷積來(lái)實(shí)現(xiàn)一個(gè)常規(guī)卷積。
分組前:參數(shù)量 (M*N*dk*dk)
分組后:參數(shù)量 (M*dk*dk + M*N*1*1)
壓縮量:(M*dk*dk + M*N*1*1) / (M*N*dk*dk),近似為 1/(dk*dk)。dk的常見(jiàn)值為3,也就是3*3卷積,故可縮小約9倍
如下圖所示:
2.1.4 分解卷積
使用兩個(gè)串聯(lián)小卷積核來(lái)代替一個(gè)大卷積核。InceptionV2中創(chuàng)造性的提出了兩個(gè)3x3的卷積核代替一個(gè)5x5的卷積核。在效果相同的情況下,參數(shù)量?jī)H為原先的 3x3x2 / 5x5 = 18/25
使用兩個(gè)并聯(lián)的非對(duì)稱(chēng)卷積核來(lái)代替一個(gè)正常卷積核。InceptionV3中將一個(gè)7x7的卷積拆分成了一個(gè)1x7和一個(gè)7x1, 卷積效果相同的情況下,大大減少了參數(shù)量,同時(shí)還提高了卷積的多樣性。
2.1.5 其他
全局平均池化代替全連接層。這個(gè)才是大殺器!AlexNet和VGGNet中,全連接層幾乎占據(jù)了90%的參數(shù)量。inceptionV1創(chuàng)造性的使用全局平均池化來(lái)代替最后的全連接層,使得其在網(wǎng)絡(luò)結(jié)構(gòu)更深的情況下(22層,AlexNet僅8層),參數(shù)量只有500萬(wàn),僅為AlexNet的1/12
1x1卷積核的使用。1x1的卷積核可以說(shuō)是性?xún)r(jià)比最高的卷積了,沒(méi)有之一。它在參數(shù)量為1的情況下,同樣能夠提供線(xiàn)性變換,relu激活,輸入輸出channel變換等功能。VGGNet創(chuàng)造性的提出了1x1的卷積核
使用小卷積核來(lái)代替大卷積核。VGGNet全部使用3x3的小卷積核,來(lái)代替AlexNet中11x11和5x5等大卷積核。小卷積核雖然參數(shù)量較少,但也會(huì)帶來(lái)特征面積捕獲過(guò)小的問(wèn)題。inception net認(rèn)為越往后的卷積層,應(yīng)該捕獲更多更高階的抽象特征。因此它在靠后的卷積層中使用的5x5等大面積的卷積核的比率較高,而在前面幾層卷積中,更多使用的是1x1和3x3的卷積核。
2.2 量化
2.2.1 偽量化
深度學(xué)習(xí)模型參數(shù)通常是32bit浮點(diǎn)型,我們能否使用16bit,8bit,甚至1bit來(lái)存儲(chǔ)呢?答案是肯定的。常見(jiàn)的做法是保存模型每一層時(shí),利用低精度來(lái)保存每一個(gè)網(wǎng)絡(luò)參數(shù),同時(shí)保存拉伸比例scale和零值對(duì)應(yīng)的浮點(diǎn)數(shù)zero_point。推理階段,利用如下公式來(lái)網(wǎng)絡(luò)參數(shù)還原為32bit浮點(diǎn):
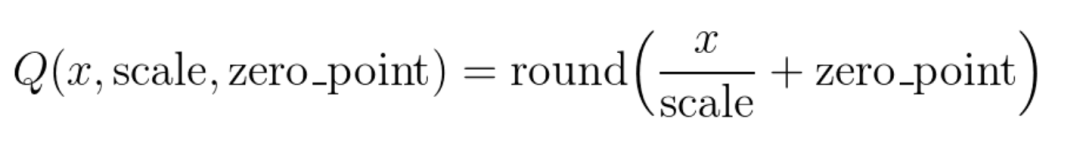
這個(gè)過(guò)程被稱(chēng)為偽量化。
偽量化之所以得名,是因?yàn)榇鎯?chǔ)時(shí)使用了低精度進(jìn)行量化,但推理時(shí)會(huì)還原為正常高精度。為什么推理時(shí)不仍然使用低精度呢?這是因?yàn)橐环矫婵蚣軐佑行┧阕又恢С指↑c(diǎn)運(yùn)算,需要專(zhuān)門(mén)實(shí)現(xiàn)算子定點(diǎn)化才行。另一方面,高精度推理準(zhǔn)確率相對(duì)高一些。偽量化可以實(shí)現(xiàn)模型壓縮,但對(duì)模型加速?zèng)]有多大效果。
2.2.2 聚類(lèi)與偽量化
一種實(shí)現(xiàn)偽量化的方案是,利用k-means等聚類(lèi)算法,步驟如下:
將大小相近的參數(shù)聚在一起,分為一類(lèi)。
每一類(lèi)計(jì)算參數(shù)的平均值,作為它們量化后對(duì)應(yīng)的值。
每一類(lèi)參數(shù)存儲(chǔ)時(shí),只存儲(chǔ)它們的聚類(lèi)索引。索引和真實(shí)值(也就是類(lèi)內(nèi)平均值)保存在另外一張表中
推理時(shí),利用索引和映射表,恢復(fù)為真實(shí)值。
過(guò)程如下圖所示,
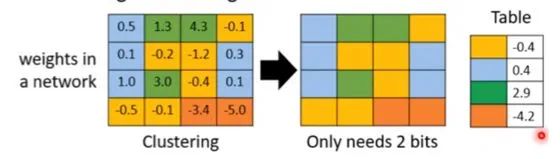
從上可見(jiàn),當(dāng)只需要4個(gè)類(lèi)時(shí),我們僅需要2bit就可以實(shí)現(xiàn)每個(gè)參數(shù)的存儲(chǔ)了,壓縮量達(dá)到16倍。推理時(shí)通過(guò)查找表恢復(fù)為浮點(diǎn)值,精度損失可控。結(jié)合霍夫曼編碼,可進(jìn)一步優(yōu)化存儲(chǔ)空間。一般來(lái)說(shuō),當(dāng)聚類(lèi)數(shù)為N時(shí),我們壓縮量為 log(N) / 32。
2.2.3 定點(diǎn)化
與偽量化不同的是,定點(diǎn)化在推理時(shí),不需要還原為浮點(diǎn)數(shù)。這需要框架實(shí)現(xiàn)算子的定點(diǎn)化運(yùn)算支持。目前MNN、XNN等移動(dòng)端AI框架中,均加入了定點(diǎn)化支持。
2.3 剪枝
2.3.1 剪枝流程
剪枝歸納起來(lái)就是取其精華去其糟粕。按照剪枝粒度可分為突觸剪枝、神經(jīng)元剪枝、權(quán)重矩陣剪枝等。總體思想是,將權(quán)重矩陣中不重要的參數(shù)設(shè)置為0,結(jié)合稀疏矩陣來(lái)進(jìn)行存儲(chǔ)和計(jì)算。通常為了保證performance,需要一小步一小步地進(jìn)行迭代剪枝。步子大了,容易那個(gè)啥的,大家都懂的哈。
常見(jiàn)迭代剪枝流程如下圖所示
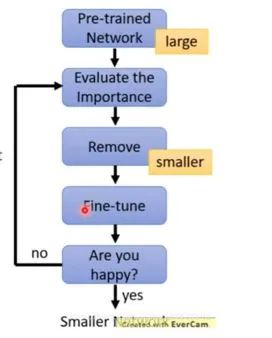
訓(xùn)練一個(gè)performance較好的大模型。
評(píng)估模型中參數(shù)的重要性。常用的評(píng)估方法是,越接近0的參數(shù)越不重要。當(dāng)然還有其他一些評(píng)估方法,這一塊也是目前剪枝研究的熱點(diǎn)。
將不重要的參數(shù)去掉,或者說(shuō)是設(shè)置為0。之后可以通過(guò)稀疏矩陣進(jìn)行存儲(chǔ)。比如只存儲(chǔ)非零元素的index和value。
訓(xùn)練集上微調(diào),從而使得由于去掉了部分參數(shù)導(dǎo)致的performance下降能夠盡量調(diào)整回來(lái)。
驗(yàn)證模型大小和performance是否達(dá)到了預(yù)期,如果沒(méi)有,則繼續(xù)迭代進(jìn)行。
2.3.2 突觸剪枝
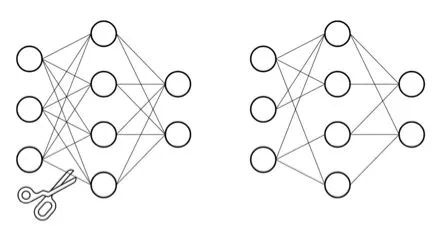
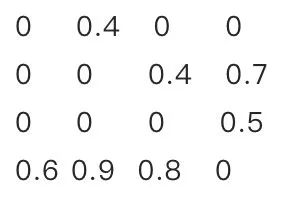
突觸剪枝剪掉神經(jīng)元之間的不重要的連接。對(duì)應(yīng)到權(quán)重矩陣中,相當(dāng)于將某個(gè)參數(shù)設(shè)置為0。常見(jiàn)的做法是,按照數(shù)值大小對(duì)參數(shù)進(jìn)行排序,將大小排名最后的k%置零即可,k%為壓縮率。具體流程可以參考下面的圖例:


2.3.3 神經(jīng)元剪枝
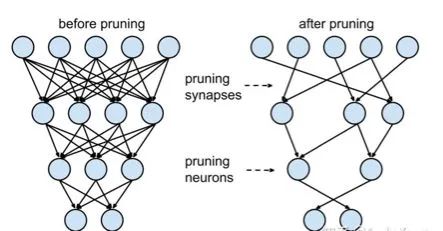
神經(jīng)元剪枝則直接將某個(gè)節(jié)點(diǎn)直接去掉。對(duì)應(yīng)到權(quán)重矩陣中,相當(dāng)于某一行和某一列置零。常見(jiàn)做法是,計(jì)算神經(jīng)元對(duì)應(yīng)的一行和一列參數(shù)的平方和的根,對(duì)神經(jīng)元進(jìn)行重要性排序,將大小排名最后的k%置零。具體流程可以參考下面的圖例:
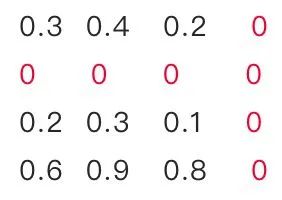
2.3.4 權(quán)重矩陣剪枝
除了將權(quán)重矩陣中某些零散的參數(shù),或者整行整列去掉外,我們能否將整個(gè)權(quán)重矩陣去掉呢?答案是肯定的,目前也有很多這方面的研究。NeurIPS 2019有篇文章,Are Sixteen Heads Really Better than One?,深入分析了BERT多頭機(jī)制中每個(gè)頭到底有多大用,結(jié)果發(fā)現(xiàn)很多頭其實(shí)沒(méi)啥卵用。他在要去掉的head上,加入mask,來(lái)做每個(gè)頭的重要性分析。
作者先分析了單獨(dú)去掉每層每個(gè)頭,WMT任務(wù)上BLEU的改變。發(fā)現(xiàn),大多數(shù)head去掉后,對(duì)整體影響不大。如下圖所示

然后作者分析了,每層只保留一個(gè)最重要的head后,ACC的變化。可見(jiàn)很多層只保留一個(gè)head,performance影響不大。如下圖所示

由此可見(jiàn),直接進(jìn)行權(quán)重矩陣剪枝,也是可行的方案。相比突觸剪枝和神經(jīng)元剪枝,壓縮率要大很多。
2.4 蒸餾
2.4.1 蒸餾流程
蒸餾本質(zhì)是student對(duì)teacher的擬合,從teacher中汲取養(yǎng)分,學(xué)到知識(shí),不僅僅可以用到模型壓縮和加速中。蒸餾常見(jiàn)流程如下圖所示
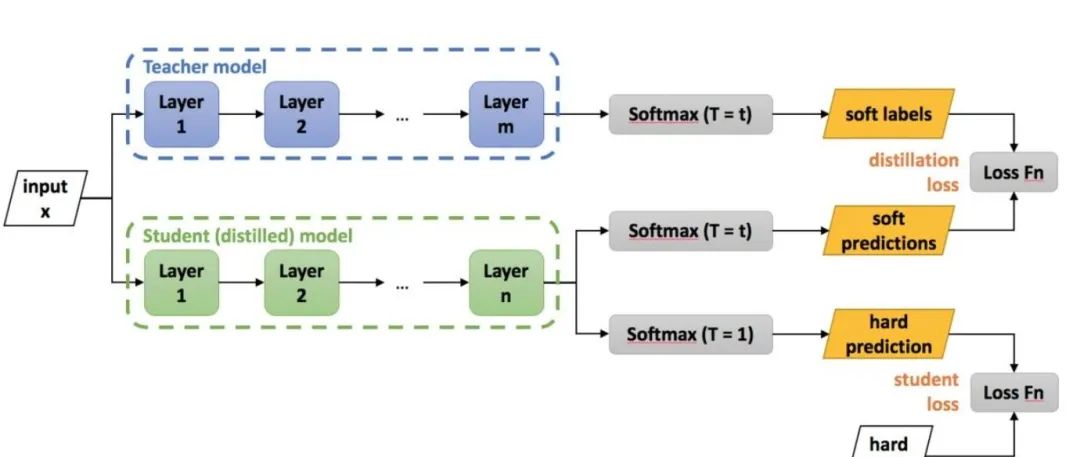
老師和學(xué)生可以是不同的網(wǎng)絡(luò)結(jié)構(gòu),比如BERT蒸餾到BiLSTM網(wǎng)絡(luò)。但一般相似網(wǎng)絡(luò)結(jié)構(gòu),蒸餾效果會(huì)更好。
總體loss為 soft_label_loss + hard_label_loss。soft_label_loss可以用KL散度或MSE擬合
soft label為teacher模型的要擬合的對(duì)象。可以是模型預(yù)測(cè)輸出,也可以是embeddings, 或者h(yuǎn)idden layer和attention分布。
針對(duì)軟標(biāo)簽的定義,蒸餾的方案也是百花齊放,下面分享兩篇個(gè)人認(rèn)為非常經(jīng)典的文章。
2.4.2 distillBERT
DistillBERT: A distilled version of BERT: smaller, faster, cheaper and lighter
DistillBERT由大名鼎鼎的HuggingFace出品。主要?jiǎng)?chuàng)新點(diǎn)為:
Teacher 12層,student 6層,每?jī)蓪尤サ粢粚印1热鐂tudent第二層對(duì)應(yīng)teacher第三層
Loss= 5.0 * Lce+2.0 * Lmlm+1.0 * Lcos
Lce: soft_label 的KL散度
Lmlm: mask LM hard_label 的交叉熵
Lcos:hidden state 的余弦相似度
DistilBERT 比 BERT 快 60%,體積比 BERT 小 60%。在glue任務(wù)上,保留了 95% 以上的性能。在performance損失很小的情況下,帶來(lái)了較大的模型壓縮和加速效果。

2.4.3 TinyBERT
TinyBERT: Distilling BERT for Natural Language Understanding
總體結(jié)構(gòu)
重點(diǎn)來(lái)看下 TinyBERT,它是由華為出品,非常值得深入研究。TinyBERT 對(duì) embedding 層,transformer層(包括hidden layer和attention)和 prediction 層均進(jìn)行了擬合。如下圖所示。
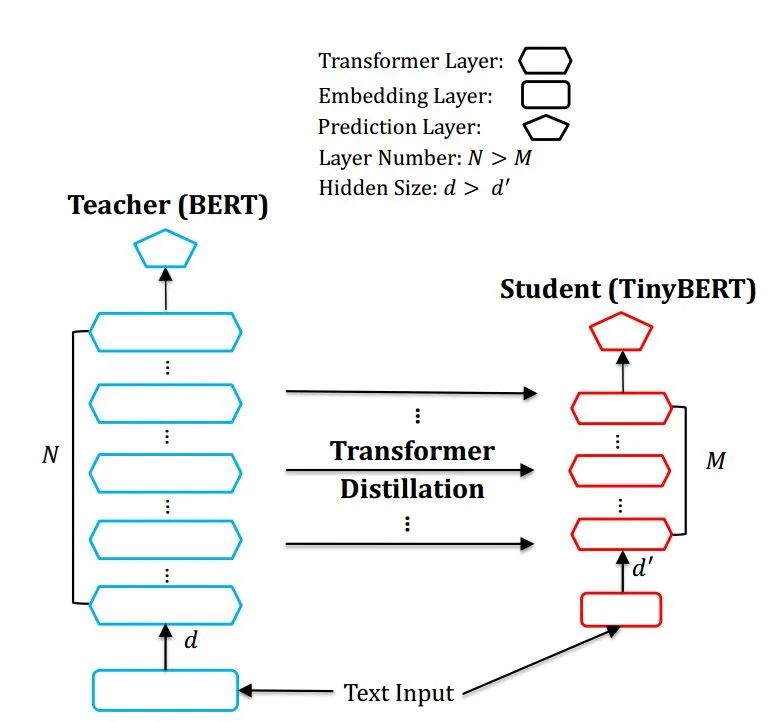
其中Embeddings采用MSE, Prediction采用KL散度, Transformer層的hidden layer和attention,均采用MSE。loss如下
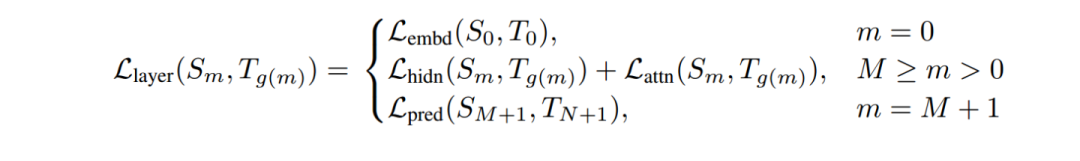
其中m為層數(shù)。
效果分析
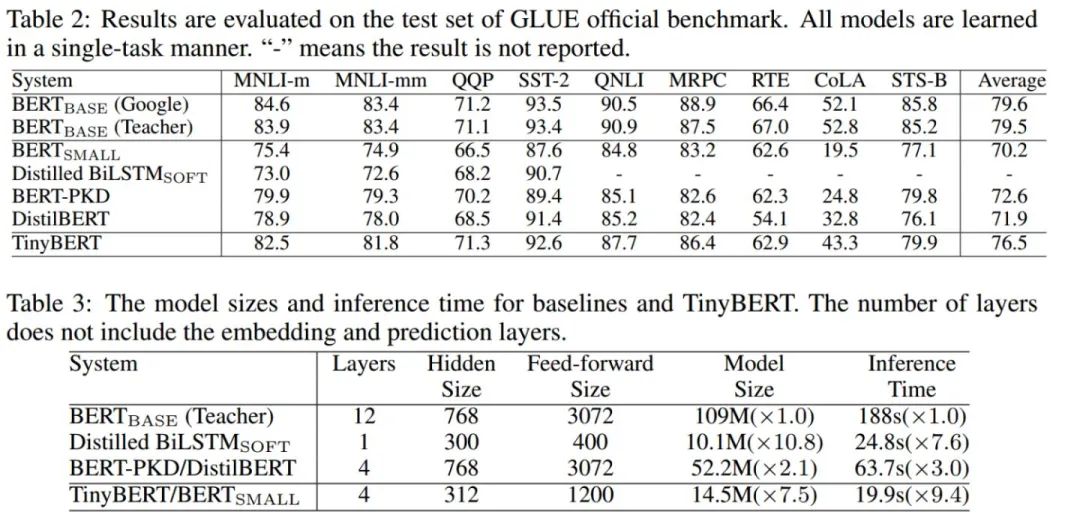
消融分析

3.1 手機(jī)端AI能力
目前移動(dòng)端AI框架也比較多,包括谷歌的tf-lite,騰訊的NCNN,阿里的MNN,百度的PaddleLite, 小米的MACE等。他們都不同程度的進(jìn)行了模型壓縮和加速的支持。特別是端上推理的加速。這個(gè)可以參考“手機(jī)端AI性能排名“。
3.2 端側(cè)AI框架加速優(yōu)化方法
個(gè)人總結(jié)的主要方法如下,可能有遺漏哈,各位看官請(qǐng)輕拍:
基于基本的C++編譯器優(yōu)化。
打開(kāi)編譯器的優(yōu)化選項(xiàng),選擇O2等加速選項(xiàng)。
小函數(shù)內(nèi)聯(lián),概率大分支優(yōu)先,避免除法,查表空間換時(shí)間,函數(shù)參數(shù)不超過(guò)4個(gè)等。
利用C,而不是C++,C++有不少冗余的東西。
緩存優(yōu)化
小塊內(nèi)存反復(fù)使用,提升cache命中率,盡量減少內(nèi)存申請(qǐng)。比如上一層計(jì)算完后,接著用作下一層計(jì)算。
連續(xù)訪問(wèn),內(nèi)存連續(xù)訪問(wèn)有利于一次同時(shí)取數(shù),相近位置cache命中概率更高。比如縱向訪問(wèn)數(shù)組時(shí),可以考慮轉(zhuǎn)置后變?yōu)闄M向訪問(wèn)。
對(duì)齊訪問(wèn),比如224*224的尺寸,補(bǔ)齊為256*224,從而提高緩存命中率。
緩存預(yù)取,CPU計(jì)算的時(shí)候,preload后面的數(shù)據(jù)到cache中。
多線(xiàn)程。
為循環(huán)分配線(xiàn)程。
動(dòng)態(tài)調(diào)度,某個(gè)子循環(huán)過(guò)慢的時(shí)候,調(diào)度一部分循環(huán)到其他線(xiàn)程中。
稀疏化
稀疏索引和存儲(chǔ)方案,采用eigen的sparseMatrix方案。
內(nèi)存復(fù)用和提前申請(qǐng)
掃描整個(gè)網(wǎng)絡(luò),計(jì)算每層網(wǎng)絡(luò)內(nèi)存復(fù)用的情況下,最低的內(nèi)存消耗。推理剛開(kāi)始的時(shí)候就提前申請(qǐng)好。避免推理過(guò)程中反復(fù)申請(qǐng)和釋放內(nèi)存,避免推理過(guò)程中因?yàn)閮?nèi)存不足而失敗,復(fù)用提升內(nèi)存訪問(wèn)效率和cache命中率。
ARM NEON指令的使用,和ARM的深度融合。NEON可以單指令多取值(SIMD),感興趣可針對(duì)學(xué)習(xí),這一塊水也很深。
手工匯編,畢竟機(jī)器編譯出來(lái)的代碼還是有不少冗余的。可以針對(duì)運(yùn)行頻次特別高的代碼進(jìn)行手工匯編優(yōu)化。當(dāng)然如果你匯編功底驚天地泣鬼神的強(qiáng),也可以全方位手工匯編。
算子支持:比如支持GPU加速,支持定點(diǎn)化等。有時(shí)候需要重新開(kāi)發(fā)端側(cè)的算子。
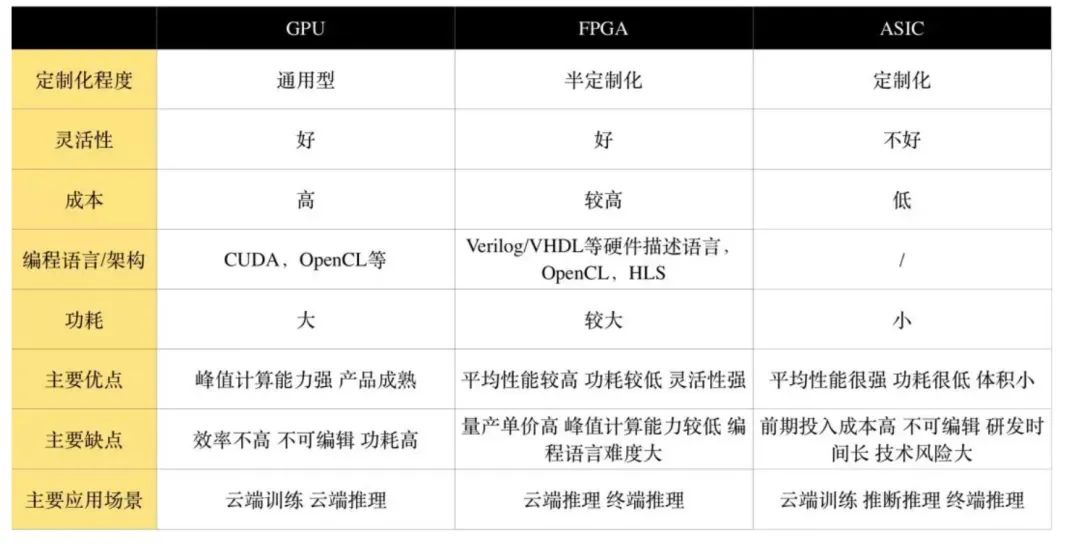
硬件層加速比較硬核,小編就連半瓢水都達(dá)不到了,為了保證整個(gè)方案的全面性,還是硬著頭皮東施效顰下。目前AI芯片廠家也是百花齊放,誰(shuí)都想插一腳,不少互聯(lián)網(wǎng)公司也來(lái)趕集,如下圖所示。

AI 芯片目前三種方案。GPU目前被英偉達(dá)和AMD牢牢把控。ASIC目前最火,TPU、NPU等屬于ASIC范疇。
這篇文章我們對(duì)深度學(xué)習(xí)模型壓縮和加速的幾類(lèi)常用的方法進(jìn)行了介紹,如果有讀者對(duì)模型壓縮加速也感覺(jué)興趣的話(huà),歡迎一起來(lái)討論。
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Are Sixteen Heads Really Better than One?
DistillBERT: A distilled version of BERT: smaller, faster, cheaper and lighter
TinyBERT: Distilling BERT for Natural Language Understanding
手機(jī)端AI性能排名
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~