
深度學(xué)習(xí)模型壓縮與加速綜述

極市導(dǎo)讀
?本文詳細(xì)介紹了4種主流的壓縮與加速技術(shù):結(jié)構(gòu)優(yōu)化、剪枝(Pruning)、量化(Quantization)、知識(shí)蒸餾(Knowledge Distillation),作者分別從每個(gè)技術(shù)結(jié)構(gòu)與性能表現(xiàn)進(jìn)行陳述。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
近年來,深度學(xué)習(xí)模型在CV、NLP等領(lǐng)域?qū)崿F(xiàn)了廣泛應(yīng)用。然而,龐大的參數(shù)規(guī)模帶來的計(jì)算開銷、內(nèi)存需求,使得其在計(jì)算能力受限平臺(tái)的部署中遇到了巨大的困難與挑戰(zhàn)。因此,如何在不影響深度學(xué)習(xí)模型性能的情況下進(jìn)行模型壓縮與加速,成為了學(xué)術(shù)界和工業(yè)界的研究熱點(diǎn)。
1、簡(jiǎn)介
深度學(xué)習(xí)模型壓縮與加速是指利用神經(jīng)網(wǎng)絡(luò)參數(shù)和結(jié)構(gòu)的冗余性精簡(jiǎn)模型,在不影響任務(wù)完成度的情況下,得到參數(shù)量更少、結(jié)構(gòu)更精簡(jiǎn)的模型。被壓縮后的模型對(duì)計(jì)算資源和內(nèi)存的需求更小,相比原始模型能滿足更廣泛的應(yīng)用需求。(事實(shí)上,壓縮和加速是有區(qū)別的,壓縮側(cè)重于減少網(wǎng)絡(luò)參數(shù)量,加速側(cè)重于降低計(jì)算復(fù)雜度、提升并行能力等,壓縮未必一定能加速,本文中我們把二者等同看待)
必要性:主流的模型,如VGG-16,參數(shù)量1億3千多萬,占用500多MB空間,需要進(jìn)行300多億次浮點(diǎn)運(yùn)算才能完成一次圖像識(shí)別任務(wù)。 可行性:并非所有的參數(shù)都在模型中發(fā)揮作用,部分參數(shù)作用有限、表達(dá)冗余,甚至?xí)档湍P偷男阅埽虼耍恍栌?xùn)練一小部分的權(quán)值參數(shù)就有可能達(dá)到和原來網(wǎng)絡(luò)相近的性能甚至超過原來網(wǎng)絡(luò)的性能(可以看做一種正則化)。
壓縮與加速,大體可以從三個(gè)層面來做:算法層、框架層、硬件層,本文僅討論算法層的壓縮與加速技術(shù)。
2、主流技術(shù)
主流的壓縮與加速技術(shù)有4種:結(jié)構(gòu)優(yōu)化、剪枝(Pruning)、量化(Quantization)、知識(shí)蒸餾(Knowledge Distillation)。
2.1、結(jié)構(gòu)優(yōu)化
通過優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)的設(shè)計(jì)去減少模型的冗余和計(jì)算量。常見方式如下:
矩陣分解:如ALBERT的embedding layer 參數(shù)共享:如CNN和ALBERT(只能壓縮參數(shù)不能加速推理) 分組卷積:主要應(yīng)用于CV領(lǐng)域,如shuffleNet,mobileNet等 分解卷積:使用兩個(gè)串聯(lián)小卷積核來代替一個(gè)大卷積核(Inception V2)、使用兩個(gè)并聯(lián)的非對(duì)稱卷積核來代替一個(gè)正常卷積核(Inception V3) 全局平均池化代替全連接層 使用1*1卷積核
2.2、剪枝
剪枝是指在預(yù)訓(xùn)練好的大型模型的基礎(chǔ)上,設(shè)計(jì)對(duì)網(wǎng)絡(luò)參數(shù)的評(píng)價(jià)準(zhǔn)則,以此為根據(jù)刪除“冗余”參數(shù)。根據(jù)剪枝粒度粗細(xì),參數(shù)剪枝可分為非結(jié)構(gòu)化剪枝和結(jié)構(gòu)化剪枝。非結(jié)構(gòu)化剪枝的粒度比較細(xì),可以無限制去掉網(wǎng)絡(luò)中期望比例的任何“冗余”參數(shù),但會(huì)帶來裁剪后網(wǎng)絡(luò)結(jié)構(gòu)不規(guī)整難以有效加速的問題。結(jié)構(gòu)化剪枝的粒度比較粗,剪枝的最小單位是filter內(nèi)參數(shù)的組合,通過對(duì)filter或者feature map設(shè)置評(píng)價(jià)因子,甚至可以刪除整個(gè)filter或者某幾個(gè)channel,使網(wǎng)絡(luò)“變窄”,可以直接在現(xiàn)有軟硬件上獲得有效加速,但可能帶來預(yù)測(cè)精度的下降,需要通過對(duì)模型微調(diào)恢復(fù)性能。
2.3、量化
量化是指用較低位寬表示典型的32bit浮點(diǎn)型網(wǎng)絡(luò)參數(shù)。網(wǎng)絡(luò)參數(shù)包括權(quán)重、激活值、梯度和誤差等等, 可以使用統(tǒng)一的位寬(如16bit,8bit,2bit和1bit等),也可以根據(jù)經(jīng)驗(yàn)或一定策略自由組合不同的位寬。量化的優(yōu)點(diǎn)在于:1).能夠顯著減少參數(shù)存儲(chǔ)空間與內(nèi)存占用空間,如,將參數(shù)從32bit浮點(diǎn)型量化到8bit整型能夠減少75%的存儲(chǔ)空間,這對(duì)于計(jì)算資源有限的邊緣設(shè)備和嵌入式設(shè)備進(jìn)行深度學(xué)習(xí)模型的部署和使用都有很大幫助;2).能夠加快運(yùn)算速度,減少設(shè)備能耗,讀取32bit浮點(diǎn)數(shù)所需的帶寬可以同時(shí)讀入4個(gè)8bit整數(shù),并且整型運(yùn)算相比浮點(diǎn)型運(yùn)算更快,自然能降低設(shè)備功耗。但其仍存在一定的局限性,網(wǎng)絡(luò)參數(shù)的位寬減少損失一部分信息量,造成推理精度下降,雖然能通過微調(diào)恢復(fù)部分精確度,但帶來時(shí)間成本;量化到特殊位寬時(shí),很多現(xiàn)有的訓(xùn)練方法和硬件平臺(tái)不再適用,需要設(shè)計(jì)專用的系統(tǒng)架構(gòu),靈活性不高。
2.4、知識(shí)蒸餾
知識(shí)蒸餾在Hinton于2015年發(fā)表的《Distilling the Knowledge in a Neural Network》(https://arxiv.org/pdf/1503.02531.pdf)中被提出。
同其它壓縮與加速技術(shù)不同,知識(shí)蒸餾需要兩種類型的網(wǎng)絡(luò):Teacher Model和Student Model。前者參數(shù)量大、結(jié)構(gòu)復(fù)雜,后者參數(shù)量較小、結(jié)構(gòu)相對(duì)簡(jiǎn)單。二者可以是不同的網(wǎng)絡(luò)結(jié)構(gòu),但是采用相似的網(wǎng)絡(luò)結(jié)構(gòu),蒸餾效果會(huì)更好。訓(xùn)練流程如下圖所示:
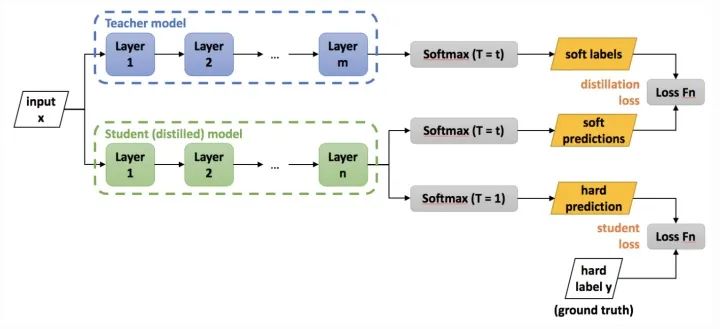
首先訓(xùn)練Teacher Model,然后用其指導(dǎo)Student Model的訓(xùn)練(訓(xùn)練集可以保持一致)。具體指導(dǎo)方案,將Teacher Model在Softmax層的輸出作為數(shù)據(jù)的soft label(熵更高,信息量更大),Student Model的loss function將是對(duì)soft label預(yù)測(cè)和hard label預(yù)測(cè)的loss的線性加權(quán)和(具體可以參考https://zhuanlan.zhihu.com/p/102038521)。Student Model訓(xùn)練好后,按照常規(guī)模型使用即可。
對(duì)soft label預(yù)測(cè)的loss,可以計(jì)算兩個(gè)Model在Softmax層的輸出的Cross Entropy,也可以計(jì)算兩個(gè)Model在Softmax層的輸入的MSE。
知識(shí)蒸餾通過將Teacher Model的知識(shí)遷移到Student Model中,使Student Model達(dá)到與Teacher Model相當(dāng)?shù)男阅埽瑫r(shí)又能起到模型壓縮的目的。其局限性在于,由于使用Softmax層的輸出作為知識(shí),所以一般多用于具有Softmax層面的分類任務(wù),在其它任務(wù)上的表現(xiàn)不好。
3、應(yīng)用實(shí)例
以下列舉幾個(gè)知識(shí)蒸餾的應(yīng)用實(shí)例。
3.1、DistillBERT
DistillBERT在Hugging Face于2019年發(fā)表的《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》(https://arxiv.org/pdf/1910.01108.pdf)中被提出。
DistillBERT的細(xì)節(jié)如下:
Student架構(gòu):總體和BERT一致,移除了token-type embeddings和pooler,層數(shù)減半(每?jī)蓪尤サ粢粚樱?2層減到6層) Student初始化:直接采用Teacher(BERT-base)中對(duì)應(yīng)的參數(shù)進(jìn)行初始化 Training loss:?  ?,其中,?
?,其中,? ?是soft label之間的KL散度(非交叉熵),?
?是soft label之間的KL散度(非交叉熵),? ?同BERT,?
?同BERT,? ?是隱層向量之間的cosine值
?是隱層向量之間的cosine值Student訓(xùn)練:采用了RoBERTa的方式,如,更大的batch_size、dynamic masking、去NSP 數(shù)據(jù)集:Student采用了和原始BERT一致的數(shù)據(jù)集
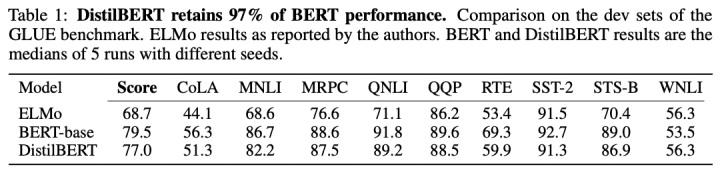
DistillBERT在GLUE數(shù)據(jù)集上的性能表現(xiàn):
DistillBERT在參數(shù)量和推理速度上的表現(xiàn):

3.2、TinyBERT
TinyBERT在華科+華為于2019年發(fā)表的《TinyBERT: Distilling BERT for Natural Language Understanding》(https://arxiv.org/pdf/1909.10351.pdf)中被提出。
TinyBERT的訓(xùn)練流程如下:
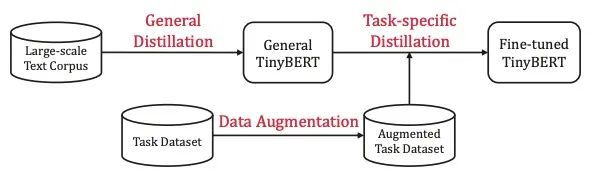
整體是個(gè)兩階段的蒸餾過程:
General Distillation:以未經(jīng)fine-tuning的BERT作為Teacher,蒸餾得到General TinyBERT Task-specific Distillation:以fine-tuning后的BERT作為Teacher,General TinyBERT作為Student的初始化,在經(jīng)過數(shù)據(jù)增強(qiáng)后的Task Dataset上繼續(xù)蒸餾,得到Fine-tuned TinyBERT
TinyBERT的結(jié)構(gòu)如下:
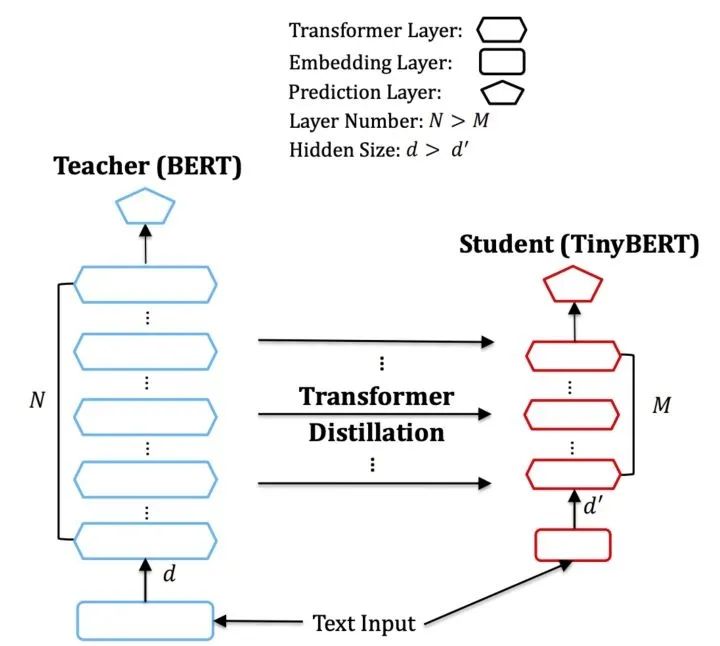
TinyBERT的loss如下:

其中,? ?表示embedding layer,?
?表示embedding layer,? ?表示prediction layer,?
?表示prediction layer,? ?有三種形式,代表三種不同的loss:
?有三種形式,代表三種不同的loss:

 ?都是MSE loss,?
?都是MSE loss,? ?是Cross Entropy loss,具體計(jì)算公式可參考論文。
?是Cross Entropy loss,具體計(jì)算公式可參考論文。
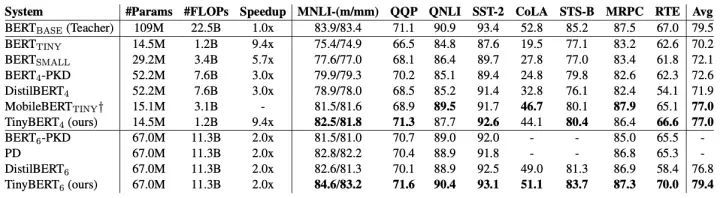
TinyBERT的性能表現(xiàn)如下:
3.3、FastBERT
FastBERT在北大+騰訊于2020年發(fā)表的《FastBERT: a Self-distilling BERT with Adaptive Inference Time》(https://arxiv.org/pdf/2004.02178.pdf)中被提出。
FastBERT的結(jié)構(gòu)如下:
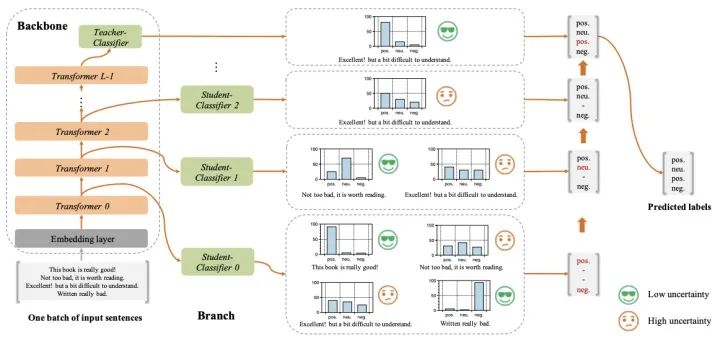
它的創(chuàng)新點(diǎn)在于self-distillation mechanism和sample-wise adaptive mechanism:
self-distillation mechanism:Teacher(backbone)和Student(branch)統(tǒng)一在一個(gè)模型中,在原始BERT的每層Transformer后接Student Classifier,擬合原始BERT的Teacher Classifier;backbone和branch的參數(shù)訓(xùn)練是獨(dú)立的,其中一個(gè)模塊參數(shù)在訓(xùn)練時(shí),另一個(gè)模塊參數(shù)會(huì)frozen sample-wise adaptive mechanism:基于LUHA(the Lower the Uncertainty,the Higher the Accuracy)假設(shè),在底層Transformer對(duì)應(yīng)的Student Classifier中,如果已經(jīng)做出了置信的分類決策,則不再繼續(xù)頂層的預(yù)測(cè)
FastBERT的訓(xùn)練流程如下:
Pre-training:對(duì)除Teacher Classifier外的backbone進(jìn)行預(yù)訓(xùn)練,這部分和BERT系列模型沒有區(qū)別(甚至可以直接使用開源的訓(xùn)練好的模型) Fine-tuning forbackbone:根據(jù)下游任務(wù),采用對(duì)應(yīng)的數(shù)據(jù)集,訓(xùn)練含Teacher Classifier在內(nèi)的backbone Self-distillation for branch:可以采用無標(biāo)簽的數(shù)據(jù)(因?yàn)椴恍枰猯abel,只需要Teacher Classifier的輸出),Teacher Classifier的輸出?  ?作為soft label,計(jì)算Student Classifier的輸出?
?作為soft label,計(jì)算Student Classifier的輸出? ?和??之間的KL散度,將所有層的KL散度之和作為total loss:
?和??之間的KL散度,將所有層的KL散度之和作為total loss:
為了實(shí)現(xiàn)Adaptive inference,F(xiàn)astBERT采用了歸一化的熵作為Student Classifier決策結(jié)果的置信度指標(biāo):

其中,??是Student Classifier輸出的概率分布,? ?是類目數(shù)量。論文中,給Uncertainty設(shè)定的閾值是Speed,二者取值均介于0、1之間。
?是類目數(shù)量。論文中,給Uncertainty設(shè)定的閾值是Speed,二者取值均介于0、1之間。
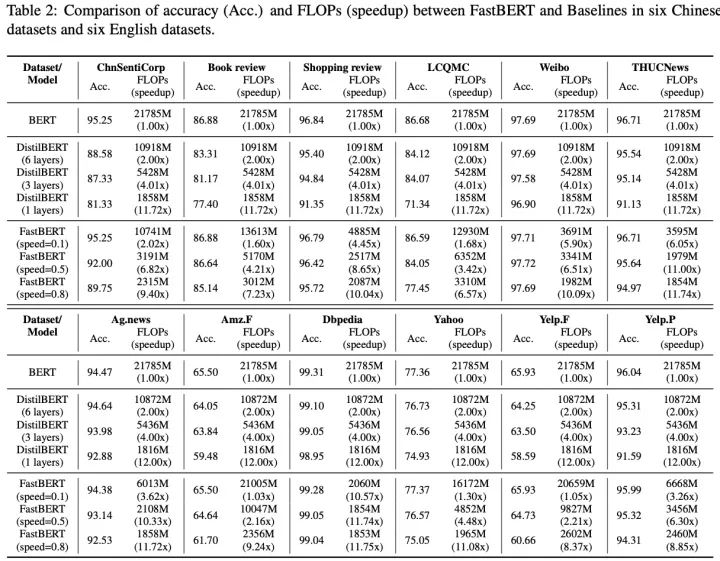
FastBERT的性能表現(xiàn)如下(當(dāng)前僅應(yīng)用于分類任務(wù)):
參考文獻(xiàn)
[1] SIGAI:深度學(xué)習(xí)模型壓縮與加速綜述(https://zhuanlan.zhihu.com/p/67871864)
[2] 簡(jiǎn)楓:一文看懂深度學(xué)習(xí)模型壓縮和加速(https://zhuanlan.zhihu.com/p/138059904)
[3] 深度學(xué)習(xí)模型壓縮方法的特點(diǎn)總結(jié)和對(duì)比_deephub-CSDN博客(https://blog.csdn.net/deephub/article/details/107424974)
[4] 深度學(xué)習(xí)網(wǎng)絡(luò)模型壓縮剪枝詳細(xì)分析 - 吳建明wujianming - 博客園(https://www.cnblogs.com/wujianming-110117/p/12702802.html)
[5] http://www.jos.org.cn/ch/reader/download_pdf_file.aspx?journal_id=jos&file_name=88D0BB702E5C1707DA216DE97314F1CF19E0198366EB5D137A9BF999F723A888FEB366E50279546F&open_type=self&file_no=6096
[6]?https://github.com/scutan90/DeepLearning-500-questions/blob/master/ch17_%E6%A8%A1%E5%9E%8B%E5%8E%8B%E7%BC%A9%E3%80%81%E5%8A%A0%E9%80%9F%E5%8F%8A%E7%A7%BB%E5%8A%A8%E7%AB%AF%E9%83%A8%E7%BD%B2/%E7%AC%AC%E5%8D%81%E4%B8%83%E7%AB%A0_%E6%A8%A1%E5%9E%8B%E5%8E%8B%E7%BC%A9%E3%80%81%E5%8A%A0%E9%80%9F%E5%8F%8A%E7%A7%BB%E5%8A%A8%E7%AB%AF%E9%83%A8%E7%BD%B2.md
[7] 潘小小:【經(jīng)典簡(jiǎn)讀】知識(shí)蒸餾(Knowledge Distillation) 經(jīng)典之作(https://zhuanlan.zhihu.com/p/102038521)
[8] 船長(zhǎng):知識(shí)蒸餾Knowledge Distillation(https://zhuanlan.zhihu.com/p/83456418)
[9] https://arxiv.org/pdf/1503.02531.pdf
[10] 【Knowledge Distillation】知識(shí)蒸餾總結(jié)https://www.jianshu.com/p/afed593a4088
[11] 章魚小丸子:語義表示模型新方向《DistillBert》https://zhuanlan.zhihu.com/p/89522799
[12] NLP中的預(yù)訓(xùn)練語言模型(四)-- 小型化bert(DistillBert, ALBERT, TINYBERT)https://www.icode9.com/content-4-513644.html
[13] https://arxiv.org/pdf/1910.01108.pdf
[14] 騰訊技術(shù)工程:比 Bert 體積更小速度更快的 TinyBERT(https://zhuanlan.zhihu.com/p/94359189)
[15] TinyBERT:模型小7倍,速度快8倍,華中科大、華為出品(https://www.jiqizhixin.com/articles/2019-09-30-5)
[16] BERT 模型蒸餾 TinyBERT(https://www.jianshu.com/p/015d23216ab3)
[17] https://arxiv.org/pdf/1909.10351.pdf
[18] https://arxiv.org/pdf/2004.02178.pdf
[19] rumor:FastBERT:又快又穩(wěn)的推理提速方法(https://zhuanlan.zhihu.com/p/127869267)
[20] 推理怎么又快又穩(wěn)?且看我FastBERT(https://www.jiqizhixin.com/articles/2020-07-23-7)
[21] 解讀FastBERT《a Self-distilling BERT with Adaptive Inference Time》(https://www.codenong.com/cs105364183/)
以上為本文的全部參考文獻(xiàn),對(duì)原作者表示感謝。
推薦閱讀
