
基礎(chǔ)積累 | 一文看懂深度學(xué)習(xí)模型壓縮和加速
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺(jué)”公眾號(hào)
視覺(jué)/圖像重磅干貨,第一時(shí)間送達(dá)
作者:知乎-揚(yáng)易(@xieyangyi) 簡(jiǎn)楓 千瞳
地址:https://zhuanlan.zhihu.com/p/138059904
整理:人工智能前沿講習(xí)
本文僅作學(xué)術(shù)交流,如有侵權(quán),請(qǐng)聯(lián)系刪文
一
前言
近年來(lái)深度學(xué)習(xí)模型在計(jì)算機(jī)視覺(jué)、自然語(yǔ)言處理、搜索推薦廣告等各種領(lǐng)域,不斷刷新傳統(tǒng)模型性能,并得到了廣泛應(yīng)用。隨著移動(dòng)端設(shè)備計(jì)算能力的不斷提升,移動(dòng)端AI落地也成為了可能。相比于服務(wù)端,移動(dòng)端模型的優(yōu)勢(shì)有:
減輕服務(wù)端計(jì)算壓力,并利用云端一體化實(shí)現(xiàn)負(fù)載均衡。特別是在雙11等大促場(chǎng)景,服務(wù)端需要部署很多高性能機(jī)器,才能應(yīng)對(duì)用戶流量洪峰。平時(shí)用戶訪問(wèn)又沒(méi)那么集中,存在巨大的流量不均衡問(wèn)題。直接將模型部署到移動(dòng)端,并在置信度較高情況下直接返回結(jié)果,而不需要請(qǐng)求服務(wù)端,可以大大節(jié)省服務(wù)端計(jì)算資源。同時(shí)在大促期間降低置信度閾值,平時(shí)又調(diào)高,可以充分實(shí)現(xiàn)云端一體負(fù)載均衡。 實(shí)時(shí)性好,響應(yīng)速度快。在feed流推薦和物體實(shí)時(shí)檢測(cè)等場(chǎng)景,需要根據(jù)用戶數(shù)據(jù)的變化,進(jìn)行實(shí)時(shí)計(jì)算推理。如果是采用服務(wù)端方案,則響應(yīng)速度得不到保障,且易造成請(qǐng)求過(guò)于密集的問(wèn)題。利用端計(jì)算能力,則可以實(shí)現(xiàn)實(shí)時(shí)計(jì)算。 穩(wěn)定性高,可靠性好。在斷網(wǎng)或者弱網(wǎng)情況下,請(qǐng)求服務(wù)端會(huì)出現(xiàn)失敗。而采用端計(jì)算,則不會(huì)出現(xiàn)這種情況。在無(wú)人車和自動(dòng)駕駛等可靠性要求很高的場(chǎng)景下,這一點(diǎn)尤為關(guān)鍵,可以保證在隧道、山區(qū)等場(chǎng)景下仍能穩(wěn)定運(yùn)行。 安全性高,用戶隱私保護(hù)好。由于直接在端上做推理,不需要將用戶數(shù)據(jù)傳輸?shù)椒?wù)端,免去了網(wǎng)絡(luò)通信中用戶隱私泄露風(fēng)險(xiǎn),也規(guī)避了服務(wù)端隱私泄露問(wèn)題
算法層壓縮加速。這個(gè)維度主要在算法應(yīng)用層,也是大多數(shù)算法工程師的工作范疇。主要包括結(jié)構(gòu)優(yōu)化(如矩陣分解、分組卷積、小卷積核等)、量化與定點(diǎn)化、模型剪枝、模型蒸餾等。 框架層加速。這個(gè)維度主要在算法框架層,比如tf-lite、NCNN、MNN等。主要包括編譯優(yōu)化、緩存優(yōu)化、稀疏存儲(chǔ)和計(jì)算、NEON指令應(yīng)用、算子優(yōu)化等 硬件層加速。這個(gè)維度主要在AI硬件芯片層,目前有GPU、FPGA、ASIC等多種方案,各種TPU、NPU就是ASIC這種方案,通過(guò)專門為深度學(xué)習(xí)進(jìn)行芯片定制,大大加速模型運(yùn)行速度。
二
算法層壓縮加速
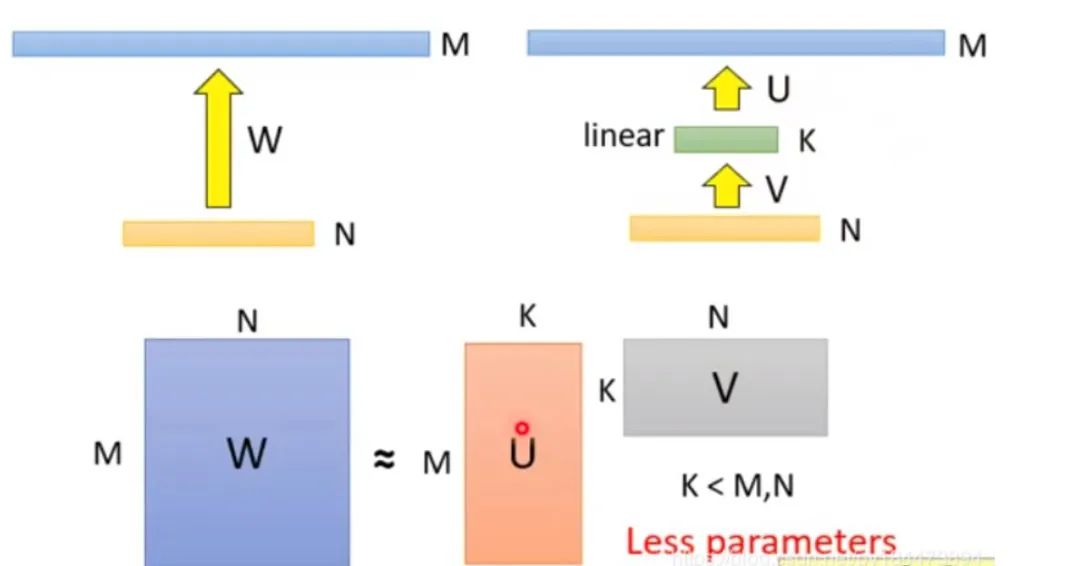
分解前:矩陣參數(shù)量為?(M * N) 分解后:參數(shù)量為?(M*K + K*N) 壓縮量:(M * N) / (M*K + K*N), 由于M遠(yuǎn)大于N,故可近似為?N / k,當(dāng)N=2014,k=128時(shí),可以壓縮8倍
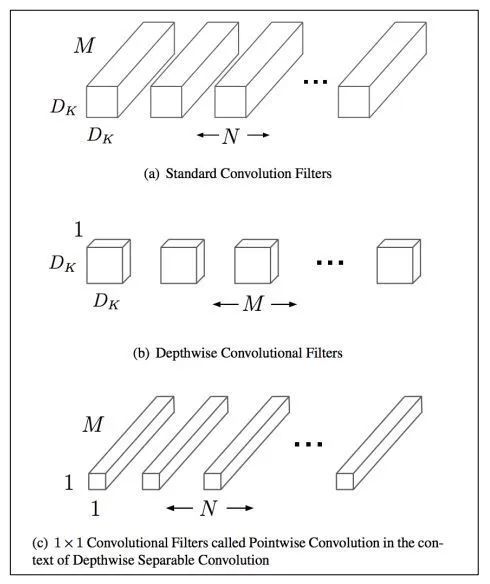
分組前:參數(shù)量?(M*N*dk*dk) 分組后:參數(shù)量?(M*dk*dk + M*N*1*1) 壓縮量:(M*dk*dk + M*N*1*1) / (M*N*dk*dk),近似為?1/(dk*dk)。dk的常見(jiàn)值為3,也就是3*3卷積,故可縮小約9倍
使用兩個(gè)串聯(lián)小卷積核來(lái)代替一個(gè)大卷積核。InceptionV2中創(chuàng)造性的提出了兩個(gè)3x3的卷積核代替一個(gè)5x5的卷積核。在效果相同的情況下,參數(shù)量?jī)H為原先的 3x3x2 / 5x5 = 18/25 使用兩個(gè)并聯(lián)的非對(duì)稱卷積核來(lái)代替一個(gè)正常卷積核。InceptionV3中將一個(gè)7x7的卷積拆分成了一個(gè)1x7和一個(gè)7x1, 卷積效果相同的情況下,大大減少了參數(shù)量,同時(shí)還提高了卷積的多樣性。
2.1.5 其他
全局平均池化代替全連接層。這個(gè)才是大殺器!AlexNet和VGGNet中,全連接層幾乎占據(jù)了90%的參數(shù)量。inceptionV1創(chuàng)造性的使用全局平均池化來(lái)代替最后的全連接層,使得其在網(wǎng)絡(luò)結(jié)構(gòu)更深的情況下(22層,AlexNet僅8層),參數(shù)量只有500萬(wàn),僅為AlexNet的1/12 1x1卷積核的使用。1x1的卷積核可以說(shuō)是性價(jià)比最高的卷積了,沒(méi)有之一。它在參數(shù)量為1的情況下,同樣能夠提供線性變換,relu激活,輸入輸出channel變換等功能。VGGNet創(chuàng)造性的提出了1x1的卷積核 使用小卷積核來(lái)代替大卷積核。VGGNet全部使用3x3的小卷積核,來(lái)代替AlexNet中11x11和5x5等大卷積核。小卷積核雖然參數(shù)量較少,但也會(huì)帶來(lái)特征面積捕獲過(guò)小的問(wèn)題。inception net認(rèn)為越往后的卷積層,應(yīng)該捕獲更多更高階的抽象特征。因此它在靠后的卷積層中使用的5x5等大面積的卷積核的比率較高,而在前面幾層卷積中,更多使用的是1x1和3x3的卷積核。
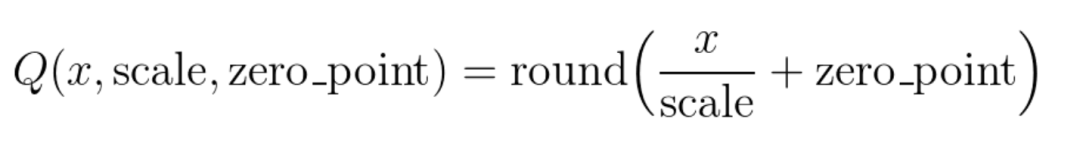
將大小相近的參數(shù)聚在一起,分為一類。 每一類計(jì)算參數(shù)的平均值,作為它們量化后對(duì)應(yīng)的值。 每一類參數(shù)存儲(chǔ)時(shí),只存儲(chǔ)它們的聚類索引。索引和真實(shí)值(也就是類內(nèi)平均值)保存在另外一張表中 推理時(shí),利用索引和映射表,恢復(fù)為真實(shí)值。
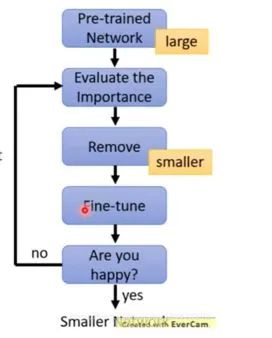
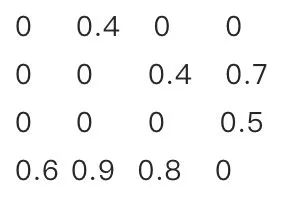
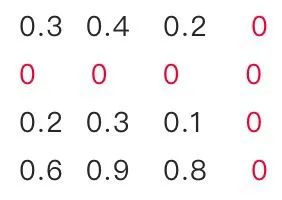
訓(xùn)練一個(gè)performance較好的大模型。 評(píng)估模型中參數(shù)的重要性。常用的評(píng)估方法是,越接近0的參數(shù)越不重要。當(dāng)然還有其他一些評(píng)估方法,這一塊也是目前剪枝研究的熱點(diǎn)。 將不重要的參數(shù)去掉,或者說(shuō)是設(shè)置為0。之后可以通過(guò)稀疏矩陣進(jìn)行存儲(chǔ)。比如只存儲(chǔ)非零元素的index和value。 訓(xùn)練集上微調(diào),從而使得由于去掉了部分參數(shù)導(dǎo)致的performance下降能夠盡量調(diào)整回來(lái)。 驗(yàn)證模型大小和performance是否達(dá)到了預(yù)期,如果沒(méi)有,則繼續(xù)迭代進(jìn)行。
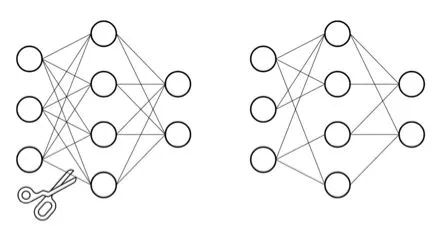


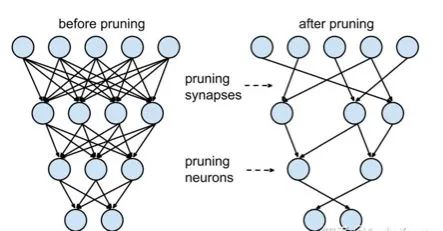
2.3.3 神經(jīng)元剪枝


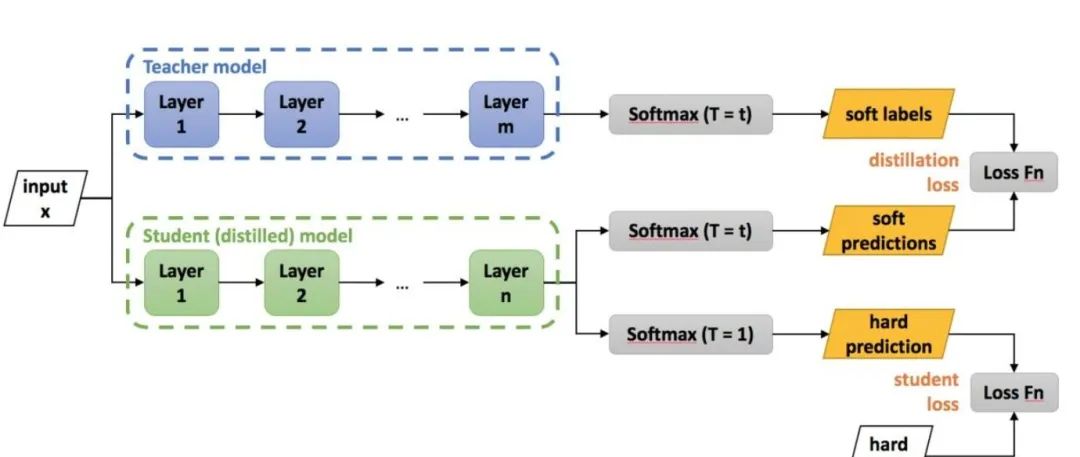
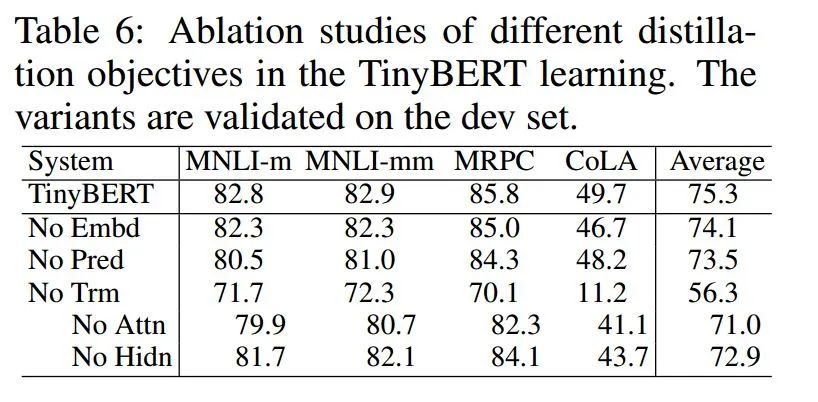
老師和學(xué)生可以是不同的網(wǎng)絡(luò)結(jié)構(gòu),比如BERT蒸餾到BiLSTM網(wǎng)絡(luò)。但一般相似網(wǎng)絡(luò)結(jié)構(gòu),蒸餾效果會(huì)更好。 總體loss為 soft_label_loss + hard_label_loss。soft_label_loss可以用KL散度或MSE擬合 soft label為teacher模型的要擬合的對(duì)象。可以是模型預(yù)測(cè)輸出,也可以是embeddings, 或者h(yuǎn)idden layer和attention分布。
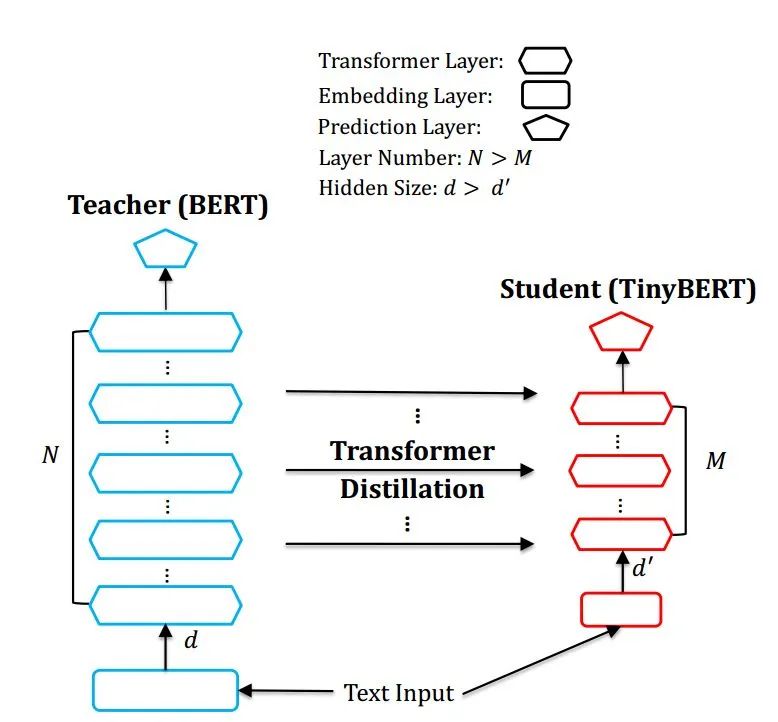
Teacher 12層,student 6層,每?jī)蓪尤サ粢粚印1热鐂tudent第二層對(duì)應(yīng)teacher第三層 Loss= 5.0 * Lce+2.0 * Lmlm+1.0 * Lcos
Lce:?soft_label 的KL散度 Lmlm:?mask LM hard_label 的交叉熵 Lcos:hidden state 的余弦相似度

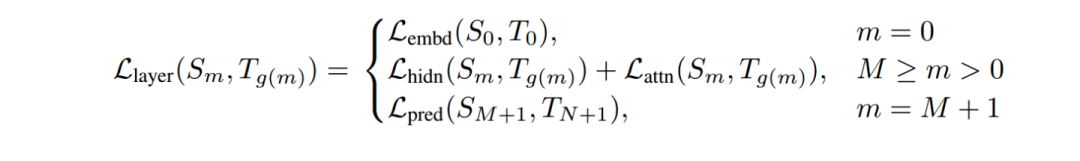
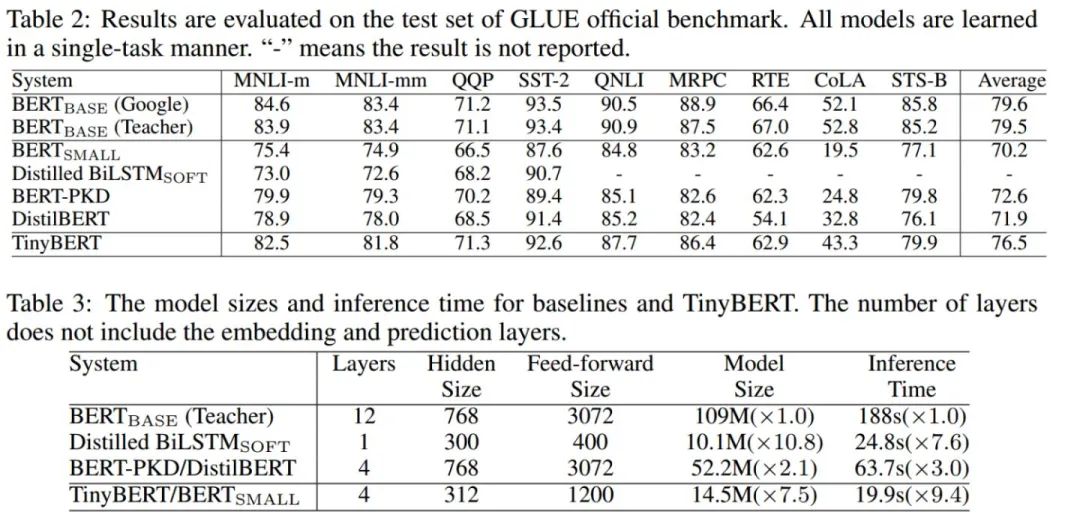

三
框架層加速
基于基本的C++編譯器優(yōu)化。 打開編譯器的優(yōu)化選項(xiàng),選擇O2等加速選項(xiàng)。 小函數(shù)內(nèi)聯(lián),概率大分支優(yōu)先,避免除法,查表空間換時(shí)間,函數(shù)參數(shù)不超過(guò)4個(gè)等。 利用C,而不是C++,C++有不少冗余的東西。 緩存優(yōu)化 小塊內(nèi)存反復(fù)使用,提升cache命中率,盡量減少內(nèi)存申請(qǐng)。比如上一層計(jì)算完后,接著用作下一層計(jì)算。 連續(xù)訪問(wèn),內(nèi)存連續(xù)訪問(wèn)有利于一次同時(shí)取數(shù),相近位置cache命中概率更高。比如縱向訪問(wèn)數(shù)組時(shí),可以考慮轉(zhuǎn)置后變?yōu)闄M向訪問(wèn)。 對(duì)齊訪問(wèn),比如224*224的尺寸,補(bǔ)齊為256*224,從而提高緩存命中率。 緩存預(yù)取,CPU計(jì)算的時(shí)候,preload后面的數(shù)據(jù)到cache中。 多線程 為循環(huán)分配線程。 動(dòng)態(tài)調(diào)度,某個(gè)子循環(huán)過(guò)慢的時(shí)候,調(diào)度一部分循環(huán)到其他線程中。 稀疏化 稀疏索引和存儲(chǔ)方案,采用eigen的sparseMatrix方案。 內(nèi)存復(fù)用和提前申請(qǐng) 掃描整個(gè)網(wǎng)絡(luò),計(jì)算每層網(wǎng)絡(luò)內(nèi)存復(fù)用的情況下,最低的內(nèi)存消耗。推理剛開始的時(shí)候就提前申請(qǐng)好。避免推理過(guò)程中反復(fù)申請(qǐng)和釋放內(nèi)存,避免推理過(guò)程中因?yàn)閮?nèi)存不足而失敗,復(fù)用提升內(nèi)存訪問(wèn)效率和cache命中率。 ARM NEON指令的使用,和ARM的深度融合。NEON可以單指令多取值(SIMD),感興趣可針對(duì)學(xué)習(xí),這一塊水也很深。 手工匯編,畢竟機(jī)器編譯出來(lái)的代碼還是有不少冗余的。可以針對(duì)運(yùn)行頻次特別高的代碼進(jìn)行手工匯編優(yōu)化。當(dāng)然如果你匯編功底驚天地泣鬼神的強(qiáng),也可以全方位手工匯編。 算子支持:比如支持GPU加速,支持定點(diǎn)化等。有時(shí)候需要重新開發(fā)端側(cè)的算子。
四
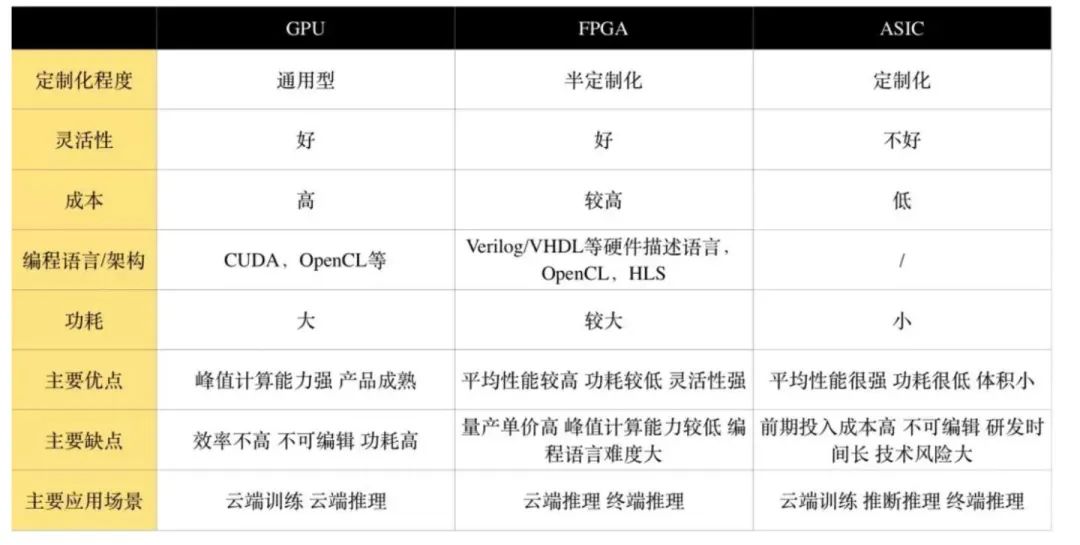
硬件層加速

五
總結(jié)
本文僅做學(xué)術(shù)分享,如有侵權(quán),請(qǐng)聯(lián)系刪文。
評(píng)論
圖片
表情