
Flink生產(chǎn)實(shí)時(shí)監(jiān)控和預(yù)警配置解析

Hi,我是王知無,一個(gè)大數(shù)據(jù)領(lǐng)域的原創(chuàng)作者。
放心關(guān)注我,獲取更多行業(yè)的一手消息。
在實(shí)際的Flink 項(xiàng)目中,如何觀察Flink的性能,如何監(jiān)控Flink的運(yùn)行狀態(tài),如何設(shè)置報(bào)警策略?下面簡(jiǎn)單講下我的經(jīng)驗(yàn)吧。
一、Flink webUI
首先聊下Flink webUI。如下圖所示:
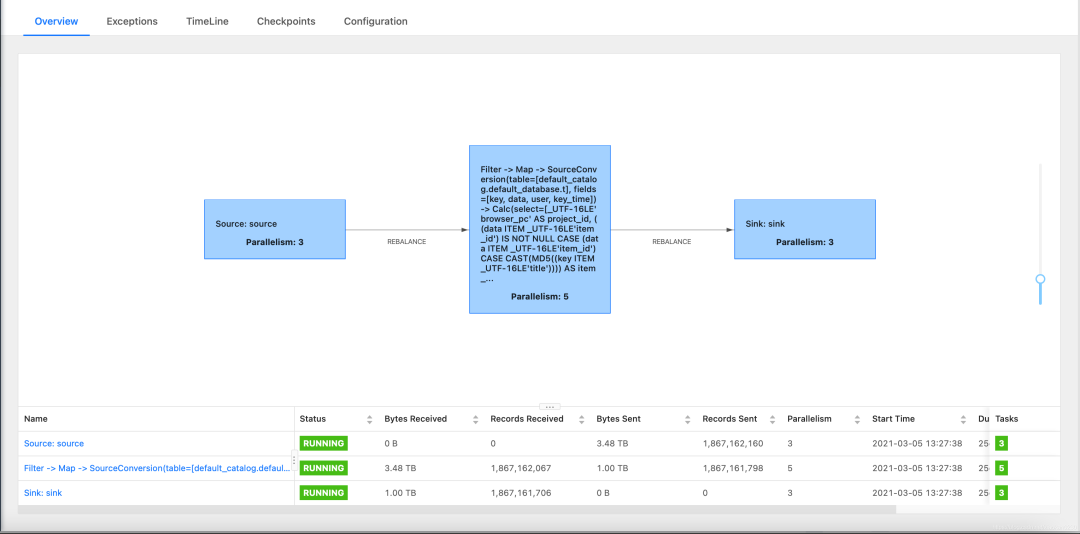
如果是本地調(diào)試模式,默認(rèn)是不開啟webui的。
StreamExecutionEnvironment?env?=?StreamExecutionEnvironment.getExecutionEnvironment();
上面的初始化方式,本地調(diào)試默認(rèn)不開啟webui。
StreamExecutionEnvironment?env?=?StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new?Configuration());
需要使用上面這種方式才能在本地調(diào)試的時(shí)候打開webui。當(dāng)然了,也需要在pom文件中添加依賴
????????????org.apache.flink
????????????flink-runtime-web_2.11
????????????${flink.version}
????????
如果你是on yarn 模式,則必須使用第一種初始化方式,on yarn 默認(rèn)可以查看webui。
下面是一個(gè)讀取kafka數(shù)據(jù),通過Flink 處理后,再寫入目標(biāo)kafka的任務(wù)。
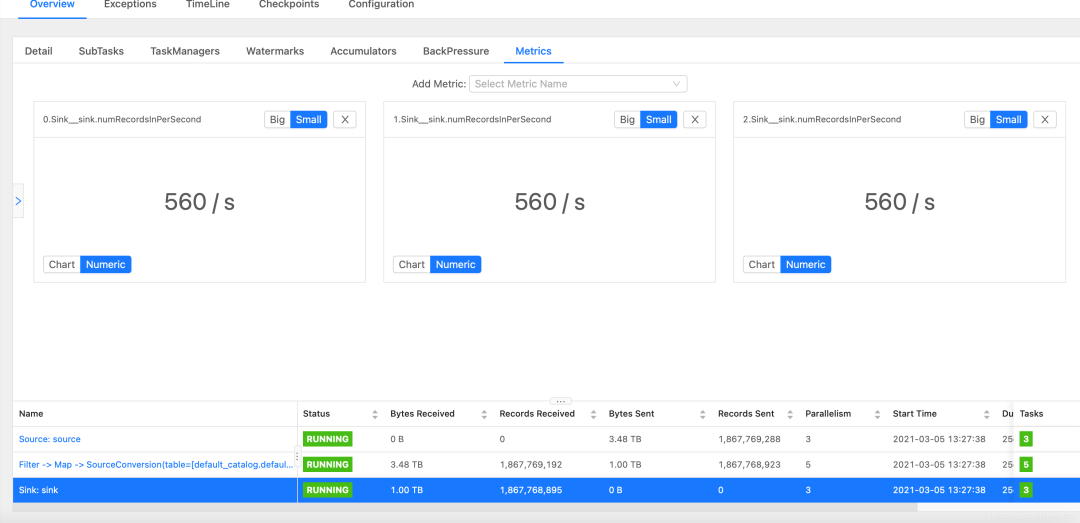
如上圖所示,點(diǎn)擊sink,在metrics中選擇Sink__sink.numRecordsInPerSecond。這里有幾個(gè)并行度,就需要全部選出來,如果你設(shè)置了50個(gè)并行度,那么就要選50次。
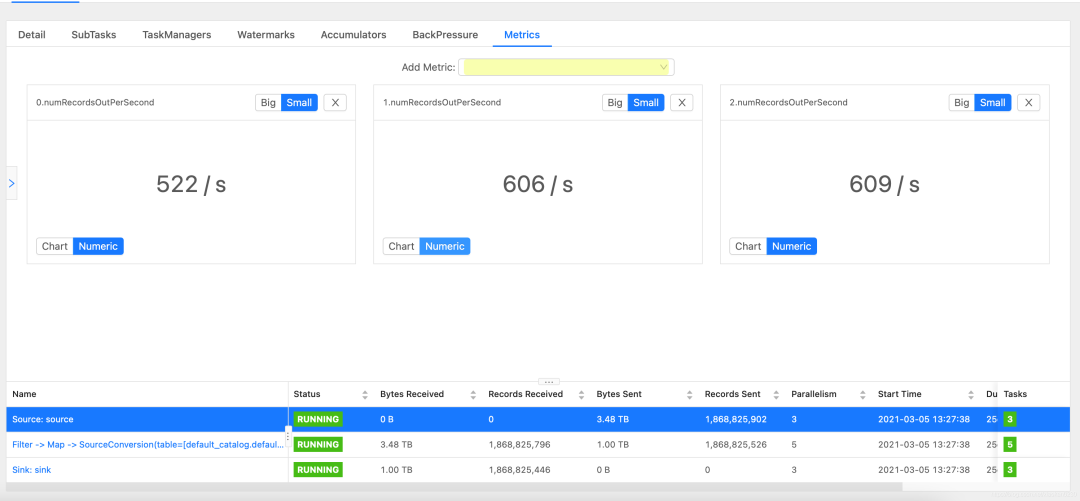
source也是同樣操作
那么,從上圖可知,該任務(wù)sink總速度為560*3=1680 條/s,source總速度為1737 條/s。基本相等
那么接下來,我們?cè)趺磁卸ㄋ俣仁欠裾D兀?/p>
我們可以借助kafka-eagle查看kafka topic的寫入速度。
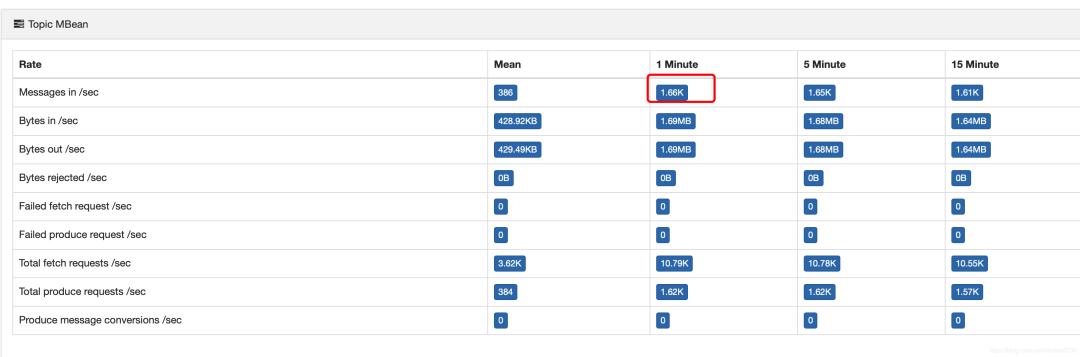
可以看到kafka的寫入速度是1.66k/s,而我們的業(yè)務(wù)邏輯,輸入和輸出是1:1,所以,flink的寫入速度和kafka的生產(chǎn)速度保持一直.
這里如果看到kafka的生產(chǎn)速度明顯高于flink的source和sink速度,則基本可以斷定,F(xiàn)link已經(jīng)產(chǎn)生反壓,并且性能不符合線上要求。
那么是否kafka寫入速度和Flink的消費(fèi)速度一致,就表示萬事大吉了呢?也不一定,我們需要通過FlinkWebui直接觀察反壓的情況。

如果和上圖一樣Ratio是0,并且status是ok,那么說明一切正常。
如果此時(shí)出現(xiàn)反壓,說明Flink的消費(fèi)速度,只能勉強(qiáng)等于日常的生產(chǎn)速度,并且此時(shí)有積壓的數(shù)據(jù)。這種情況會(huì)在補(bǔ)數(shù)據(jù)的時(shí)候會(huì)比較明顯,如果一個(gè)任務(wù)的極限性能僅僅等于或略大于生產(chǎn)日常的性能,則出現(xiàn)這種情況的概率會(huì)很高,
所以,一般來說,在Flink任務(wù)上線前,我們需要測(cè)試極限性能,一般要求至少3倍的日常速度,做到10倍以上,是最好的。
下面是一個(gè)讀取kakfa 數(shù)據(jù),處理后寫mysql的任務(wù)。
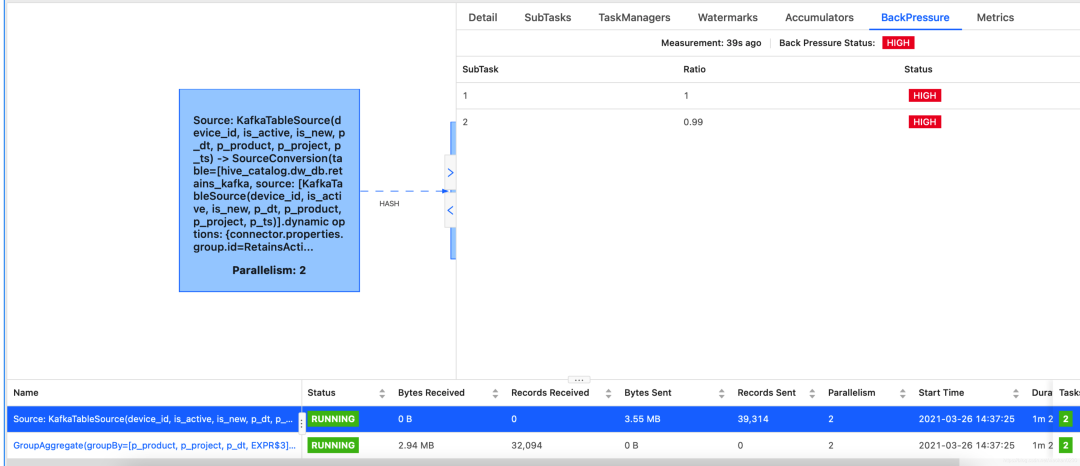
上圖說明下游產(chǎn)生了反壓,但是由于下游有g(shù)roup by 等一系列操作,我們無法確定瓶頸出在了哪里。如果需要查看具體哪一步產(chǎn)生了反壓,我們可以通過如下設(shè)置來禁止合并。
env.disableOperatorChaining();

如上圖所示,將所有子任務(wù)全部采集反壓信息。從最上的子任務(wù)往下數(shù),第一個(gè)反壓為綠色的就是罪魁禍?zhǔn)住H缟蠄D所示,F(xiàn)latMap,是紅色,sink為綠色,說明反壓在了sink,也就是說mysql的寫入速度,不能滿足我們的需求,導(dǎo)致上游Flink處理全部被限制了速度。
當(dāng)然,罪魁禍?zhǔn)撞灰欢ㄖ挥幸粋€(gè),mysql的寫入性能解決后,還有可能反壓在其他階段,但是我們通過這種方式,可以一步步定位問題,解決問題,有針對(duì)性的優(yōu)化問題,而不是像某些領(lǐng)導(dǎo)賞識(shí)的同事一樣,只知道增加并行度,最終極大增加了集群壓力,一個(gè)任務(wù)動(dòng)輒幾百G,成為集群不穩(wěn)定的因素之一,完了還甩鍋給其他人,那就沒意思了。
二、Kafka 消費(fèi) 監(jiān)控
我們知道,F(xiàn)link在 打checkpoint時(shí)才向kafka集群提交offset消費(fèi)信息的,所以如果僅僅站在kafka lag 的角度,我們看到的消費(fèi)延遲是鋸齒狀的圖形,大致長(zhǎng)這樣

上圖是一個(gè)checkpoint為3min,并且flink沒有反壓的kafka lag監(jiān)控圖。
在腳本中我們可以通過如下命令獲取kafka總lag
lag=`kafka/kafka_2.11-2.0.1/bin/kafka-consumer-groups.sh?--bootstrap-server?*.*.*.*:6667?--describe?--group?"$2"?|grep?"$3"??2>/dev/null?|grep?-v?LAG|awk?'{sum+=$5}END
這時(shí)候我們需要引入一個(gè)概念,F(xiàn)link消費(fèi)虛擬速度F0。設(shè)flink checkpoint間隔為t
F0=lag/t
例如,最高峰時(shí),kafka 的lag 為30000 ,
F0=30000/60/3=167
Flink虛擬消費(fèi)速度在最高峰時(shí)約等于167條/s。
設(shè)Flink 真實(shí)消費(fèi)速度為F1.(通過webui 直接獲得),預(yù)警倍數(shù)為m
再設(shè)預(yù)警消費(fèi)速度為F2,F(xiàn)2=F1*m
例如Flink 任務(wù)日常的消費(fèi)速度為167/s,峰值為250/s,我們?cè)O(shè)置預(yù)警倍數(shù)為2.那么當(dāng)F0>F2時(shí),我們觸發(fā)報(bào)警。
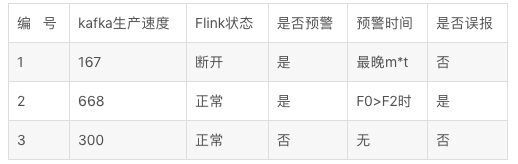
可以看到,僅僅通過Kafka lan監(jiān)控Flink任務(wù)狀態(tài) ,在出現(xiàn)高峰時(shí),可能存在誤報(bào)的情況,但是如果將預(yù)警倍數(shù)設(shè)置太高,又可能降低Flink預(yù)警的及時(shí)性。實(shí)際情況中,我們需要根據(jù)業(yè)務(wù)情況,設(shè)置合理的m和t,在允許極少誤報(bào)的情況下,做到實(shí)時(shí)任務(wù)的故障對(duì)用戶無感知,當(dāng)然,前提是筆記本隨身攜帶。。。
三、yarn 監(jiān)控
由于我們都是per job 模式,所以在yarn上都會(huì)有唯一名字,在腳本中可以通過如下方式獲得num。
??num=`yarn?application?-list?|?grep?"FlinkJobName"?|?wc?-l`
如果num小于1,那么就說明Flink任務(wù)掛了,簡(jiǎn)單直接。
但是也有一種情況,那就是集群yarn掛了。由于我們公司的集群建設(shè)做的很差,經(jīng)常出現(xiàn)這種情況,所以在監(jiān)控腳本中,不能監(jiān)控到num=0就直接啟動(dòng)Flink,這樣可能會(huì)導(dǎo)致下游數(shù)據(jù)翻倍,而是應(yīng)該電話通知,人工確認(rèn)狀態(tài)后,再手動(dòng)啟動(dòng)Flink任務(wù)。
例如,可以和kafka lag 監(jiān)控綜合來看,如果kafka lag一切正常,yarn 查不到任務(wù)信息,那大概率是說明yarn 掛了,但是Flink任務(wù)還在正常運(yùn)行。
總結(jié):
通過yarn,kafka,flink web ui 綜合判斷Flink任務(wù)健康狀態(tài)。
通過設(shè)置合理的m和t做到最少的誤報(bào)率和最高的SLA
Flink 程序質(zhì)量是第一位,極限性能至少在高峰性能2倍以上,監(jiān)控只是輔助,F(xiàn)link 優(yōu)化不到位,再多的監(jiān)控也沒法保證高SLA。
如果這個(gè)文章對(duì)你有幫助,不要忘記?「在看」?「點(diǎn)贊」?「收藏」?三連啊喂!

2022年全網(wǎng)首發(fā)|大數(shù)據(jù)專家級(jí)技能模型與學(xué)習(xí)指南(勝天半子篇)