生產(chǎn)實踐 | 基于 Flink 的短視頻生產(chǎn)消費監(jiān)控
短視頻生產(chǎn)消費監(jiān)控
短視頻帶來了全新的傳播場域和節(jié)目形態(tài),小屏幕、快節(jié)奏成為行業(yè)潮流的同時,也催生了新的用戶消費習慣,為創(chuàng)作者和商戶帶來收益。而多元化的短視頻也可以為品牌方提供營銷機遇。
其中對于垂類生態(tài)短視頻的生產(chǎn)消費熱點的監(jiān)控分析目前成為了實時數(shù)據(jù)處理很常見的一個應用場景,比如對某個圈定的垂類生態(tài)下的視頻生產(chǎn)或者視頻消費進行監(jiān)控,對熱點視頻生成對應的優(yōu)化推薦策略,促進熱點視頻的生產(chǎn)或者消費,構建整個生產(chǎn)消費數(shù)據(jù)鏈路的閉環(huán),從而提高創(chuàng)作者收益以及消費者留存。
本文將完整分析垂類生態(tài)短視頻生產(chǎn)消費數(shù)據(jù)的整條鏈路流轉方式,并基于 Flink 提供幾種對于垂類視頻生產(chǎn)消費監(jiān)控的方案設計。通過本文,你可以了解到:
垂類生態(tài)短視頻生產(chǎn)消費數(shù)據(jù)鏈路閉環(huán)
實時監(jiān)控短視頻生產(chǎn)消費的方案設計
不同監(jiān)控量級場景下的代碼實現(xiàn)
flink 學習資料
項目簡介
垂類生態(tài)短視頻生產(chǎn)消費數(shù)據(jù)鏈路流轉架構圖如下,此數(shù)據(jù)流轉圖也適用于其他場景:
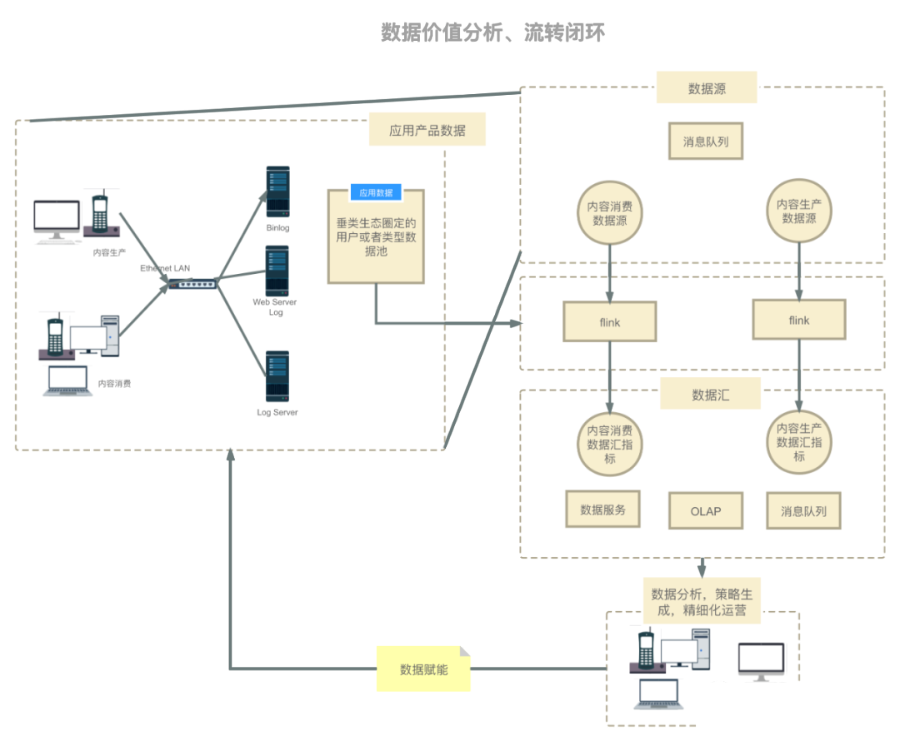
在上述場景中,用戶生產(chǎn)和消費短視頻,從而客戶端、服務端以及數(shù)據(jù)庫會產(chǎn)生相應的行為操作日志,這些日志會通過日志抽取中間件抽取到消息隊列中,我們目前的場景中是使用 Kafka 作為消息隊列;然后使用 flink 對垂類生態(tài)中的視頻進行生產(chǎn)或消費監(jiān)控(內容生產(chǎn)通常是圈定垂類作者 id 池,內容消費通常是圈定垂類視頻 id 池),最后將實時聚合數(shù)據(jù)產(chǎn)出到下游;下游可以以數(shù)據(jù)服務,實時看板的方式展現(xiàn),運營同學或者自動化工具最終會幫助我們分析當前垂類下的生產(chǎn)或者消費熱點,從而生成推薦策略。
方案設計
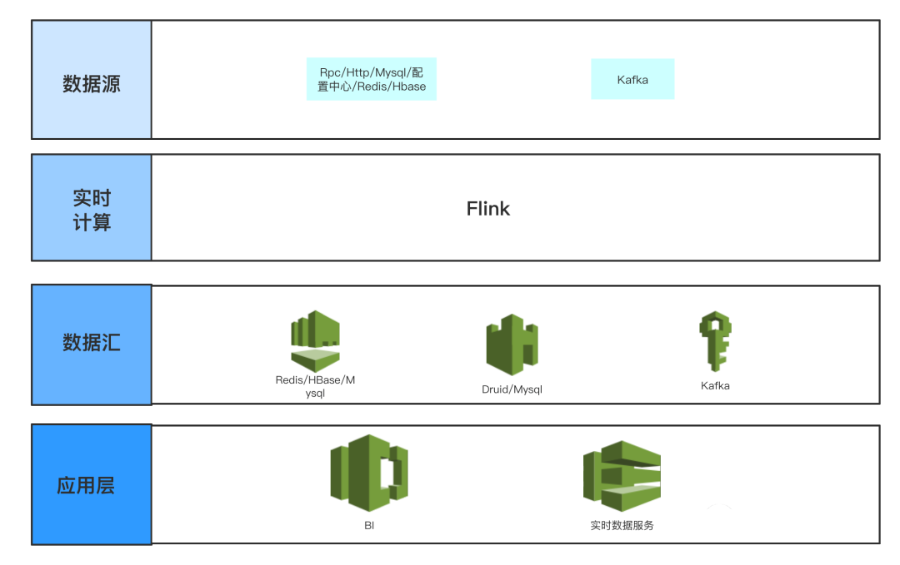
其中數(shù)據(jù)源如下:
Kafka為全量內容生產(chǎn)和內容消費的日志。 Rpc/Http/Mysql/配置中心/Redis/HBase為需要監(jiān)控的垂類生態(tài)內容 id 池(內容生產(chǎn)則為作者 id 池,內容消費則為視頻 id 池),其主要是提供給運營同學動態(tài)配置需要監(jiān)控的 id 范圍,其可以在 flink 中進行實時查詢,解析運營同學想要的監(jiān)控指標范圍,以及監(jiān)控的指標和計算方式,然后加工數(shù)據(jù)產(chǎn)出,可以支持隨時配置,實時數(shù)據(jù)隨時計算產(chǎn)出。
其中數(shù)據(jù)匯為聚類好的內容生產(chǎn)或者消費熱點話題或者事件指標:
Redis/HBase主要是以低延遲(Redis 5ms p99,HBase 100ms p99,不同公司的服務能力不同)并且高 QPS 提供數(shù)據(jù)服務,給 Server 端或者線上用戶提供低延遲的數(shù)據(jù)查詢。 Druid/Mysql可以做為 OLAP 引擎為 BI 分析提供靈活的上卷下鉆聚合分析能力,供運營同學配置可視化圖表使用。 Kafka可以以流式數(shù)據(jù)產(chǎn)出,從而提供給下游繼續(xù)消費或者進行特征提取。
廢話不多說,我們直接上方案和代碼,下述幾種方案按照監(jiān)控 id 范圍量級區(qū)分,不同的量級對應著不同的方案,其中的代碼示例為 ProcessWindowFunction,也可以使用 AggregateFunction 代替,其中主要監(jiān)控邏輯都相同。
方案 1
適合監(jiān)控 id 數(shù)據(jù)量小的場景(幾千 id),其實現(xiàn)方式是在 flink 任務初始化時將需要監(jiān)控的 id 池或動態(tài)配置中心的 id 池加載到內存當中,之后只需要在內存中判斷內容生產(chǎn)或者消費數(shù)據(jù)是否在這個監(jiān)控池當中。
ProcessWindowFunction?p?=?new?ProcessWindowFunction()?{
????
????//?配置中心動態(tài)?id?池
????private?Config>?needMonitoredIdsConfig;
????@Override
????public?void?open(Configuration?parameters)?throws?Exception?{
????????this.needMonitoredIdsConfig?=?ConfigBuilder
????????????????.buildSet("needMonitoredIds",?Long.class);
????}
????@Override
????public?void?process(Long?bucket,?Context?context,?Iterable?iterable,?Collector?collector) ?throws?Exception?{
????????Set?needMonitoredIds?=?needMonitoredIdsConfig.get();
????????/**
?????????*?判斷?commonModel?中的?id?是否在?needMonitoredIds?池中
?????????*/
????}
}
監(jiān)控的 id 池可以按照固定或者可配置從而分出兩種獲取方式:第一種是在 flink 任務開始時就全部加載進內存中,這種方式適合監(jiān)控 id 池不變的情況;第二種是使用動態(tài)配置中心,每次都從配置中心訪問到最新的監(jiān)控 id 池,其可以滿足動態(tài)配置或者更改 id 池的需求,并且這種實現(xiàn)方式通常可以實時感知到配置更改,幾乎無延遲。
方案 2
適合監(jiān)控 id 數(shù)據(jù)量適中(幾十萬 id),監(jiān)控數(shù)據(jù)范圍會不定時發(fā)生變動的場景。其實現(xiàn)方式是在 flink 算子中定時訪問接口獲取最新的監(jiān)控 id 池,以獲取最新監(jiān)控數(shù)據(jù)范圍。
ProcessWindowFunction?p?=?new?ProcessWindowFunction()?{
????private?long?lastRefreshTimest
????private?Set?needMonitoredIds;
????@Override
????public?void?open(Configuration?parameters)?throws?Exception?{
????????super.open(parameters);
????????this.refreshNeedMonitoredIds(System.currentTimeMillis());
????}
????@Override
????public?void?process(Long?bucket,?Context?context,?Iterable?iterable,?Collector?collector) ?throws?Exception?{
????????long?windowStart?=?context.window().getStart();
????????this.refreshNeedMonitoredIds(windowStart);
????????/**
?????????*?判斷?commonModel?中的?id?是否在?needMonitoredIds?池中
?????????*/
????}
????public?void?refreshNeedMonitoredIds(long?windowStart)?{
????????//?每隔?10?秒訪問一次
????????if?(windowStart?-?this.lastRefreshTimestamp?>=?10000L)?{
????????????this.lastRefreshTimestamp?=?windowStart;
????????????this.needMonitoredIds?=?Rpc.get(...)
????????}
????}
}
根據(jù)上述代碼實現(xiàn)方式,按照時間間隔的方式刷新 id 池,其缺點在于不能實時感知監(jiān)控 id 池的變化,所以刷新時間可能會和需求場景強耦合(如果 id 池會頻繁更新,那么就需要縮小刷新時間間隔)。也可根據(jù)需求場景在每個窗口開始前刷新 id 池,這樣可保證每個窗口中的 id 池中的數(shù)據(jù)一直保持更新。
方案 3
方案 3 對方案 2 的一個優(yōu)化(幾十萬 id,我們生產(chǎn)環(huán)境中最常用的)。其實現(xiàn)方式是在 flink 中使用 broadcast 算子定時訪問監(jiān)控 id 池,并將 id 池以廣播的形式下發(fā)給下游參與計算的各個算子。其優(yōu)化點在于:比如任務的并行度為 500,每 1s 訪問一次,采用方案 2 則訪問監(jiān)控 id 池接口的 QPS 為 500,在使用 broadcast 算子之后,其訪問 QPS 可以減少到 1,可以大大減少對接口的訪問量,減輕接口壓力。
public?class?Example?{
????@Slf4j
????static?class?NeedMonitorIdsSource?implements?SourceFunction<Map<Long,?Set<Long>>>?{
????????private?volatile?boolean?isCancel;
????????@Override
????????public?void?run(SourceContext>>?sourceContext) ?throws?Exception?{
????????????while?(!this.isCancel)?{
????????????????try?{
????????????????????TimeUnit.SECONDS.sleep(1);
????????????????????Set?needMonitorIds?=?Rpc.get(...);
????????????????????//?可以和上一次訪問的數(shù)據(jù)做比較查看是否有變化,如果有變化,才發(fā)送出去
????????????????????if?(CollectionUtils.isNotEmpty(needMonitorIds))?{
????????????????????????sourceContext.collect(new?HashMap>()?{{
????????????????????????????put(0L,?needMonitorIds);
????????????????????????}});
????????????????????}
????????????????}?catch?(Throwable?e)?{
????????????????????//?防止接口訪問失敗導致的錯誤導致?flink?job?掛掉
????????????????????log.error("need?monitor?ids?error",?e);
????????????????}
????????????}
????????}
????????@Override
????????public?void?cancel()?{
????????????this.isCancel?=?true;
????????}
????}
????public?static?void?main(String[]?args)?{
????????ParameterTool?parameterTool?=?ParameterTool.fromArgs(args);
????????InputParams?inputParams?=?new?InputParams(parameterTool);
????????StreamExecutionEnvironment?env?=?StreamExecutionEnvironment.createLocalEnvironment();
????????final?MapStateDescriptor>?broadcastMapStateDescriptor?=?new?MapStateDescriptor<>(
????????????????"config-keywords",
????????????????BasicTypeInfo.LONG_TYPE_INFO,
????????????????TypeInformation.of(new?TypeHint>()?{
????????????????}));
????????/*********************?kafka?source?*********************/
????????BroadcastStream>>?broadcastStream?=?env
????????????????.addSource(new?NeedMonitorIdsSource())?//?redis?photoId?數(shù)據(jù)廣播
????????????????.setParallelism(1)
????????????????.broadcast(broadcastMapStateDescriptor);
????????DataStream?logSourceDataStream?=?SourceFactory.getSourceDataStream(...);
????????/*********************?dag?*********************/
????????DataStream?resultDataStream?=?logSourceDataStream
????????????????.keyBy(KeySelectorFactory.getStringKeySelector(CommonModel::getKeyField))
????????????????.connect(broadcastStream)
????????????????.process(new?KeyedBroadcastProcessFunction>,?CommonModel>()?{
????????????????????private?Set?needMonitoredIds;
????????????????????@Override
????????????????????public?void?open(Configuration?parameters)?throws?Exception?{
????????????????????????super.open(parameters);
????????????????????????this.needMonitoredIds?=?Rpc.get(...)
????????????????????}
????????????????????@Override
????????????????????public?void?processElement(CommonModel?commonModel,?ReadOnlyContext?readOnlyContext,?Collector?collector) ?throws?Exception?{
????????????????????????//?判斷?commonModel?中的?id?是否在?needMonitoredIds?池中
????????????????????}
????????????????????@Override
????????????????????public?void?processBroadcastElement(Map>?longSetMap,?Context?context,?Collector?collector) ?throws?Exception?{
????????????????????????//?需要監(jiān)控的字段
????????????????????????Set?needMonitorIds?=?longSetMap.get(0L);
????????????????????????if?(CollectionUtils.isNotEmpty(needMonitorIds))?{
????????????????????????????this.needMonitoredIds?=?needMonitorIds;
????????????????????????}
????????????????????}
????????????????});
????????/*********************?kafka?sink?*********************/
????????SinkFactory.setSinkDataStream(...);
????????
????????env.execute(inputParams.jobName);
????}
}
方案 4
適合于超大監(jiān)控范圍的數(shù)據(jù)(幾百萬,我們自己的生產(chǎn)實踐中使用擴量到 500 萬)。其原理是將監(jiān)控范圍接口按照 id 按照一定規(guī)則分桶。flink 消費到日志數(shù)據(jù)后將 id 按照 監(jiān)控范圍接口 id 相同的分桶方法進行分桶 keyBy,這樣在下游算子中每個算子中就可以按照桶變量值,從接口中拿到對應桶的監(jiān)控 id 數(shù)據(jù),這樣 flink 中并行的每個算子只需要獲取到自己對應的桶的數(shù)據(jù),可以大大減少請求的壓力。
public?class?Example?{
????public?static?void?main(String[]?args)?{
????????ParameterTool?parameterTool?=?ParameterTool.fromArgs(args);
????????InputParams?inputParams?=?new?InputParams(parameterTool);
????????StreamExecutionEnvironment?env?=?StreamExecutionEnvironment.createLocalEnvironment();
????????final?MapStateDescriptor>?broadcastMapStateDescriptor?=?new?MapStateDescriptor<>(
????????????????"config-keywords",
????????????????BasicTypeInfo.LONG_TYPE_INFO,
????????????????TypeInformation.of(new?TypeHint>()?{
????????????????}));
????????/*********************?kafka?source?*********************/
????????DataStream?logSourceDataStream?=?SourceFactory.getSourceDataStream(...);
????????/*********************?dag?*********************/
????????DataStream?resultDataStream?=?logSourceDataStream
????????????????.keyBy(KeySelectorFactory.getLongKeySelector(CommonModel::getKeyField))
????????????????.timeWindow(Time.seconds(inputParams.accTimeWindowSeconds))
????????????????.process(new?ProcessWindowFunction()?{
????????????????????private?long?lastRefreshTimest
????????????????????private?Set?oneBucketNeedMonitoredIds;
????????????????????@Override
????????????????????public?void?open(Configuration?parameters)?throws?Exception?{
????????????????????????super.open(parameters);
????????????????????}
????????????????????@Override
????????????????????public?void?process(Long?bucket,?Context?context,?Iterable?iterable,?Collector?collector) ?throws?Exception?{
????????????????????????long?windowStart?=?context.window().getStart();
????????????????????????this.refreshNeedMonitoredIds(windowStart,?bucket);
????????????????????????/**
?????????????????????????*?判斷?commonModel?中的?id?是否在?needMonitoredIds?池中
?????????????????????????*/
????????????????????}
????????????????????public?void?refreshNeedMonitoredIds(long?windowStart,?long?bucket)?{
????????????????????????//?每隔?10?秒訪問一次
????????????????????????if?(windowStart?-?this.lastRefreshTimestamp?>=?10000L)?{
????????????????????????????this.lastRefreshTimestamp?=?windowStart;
????????????????????????????this.oneBucketNeedMonitoredIds?=?Rpc.get(bucket,?...)
????????????????????????}
????????????????????}
????????????????});
????????/*********************?kafka?sink?*********************/
????????SinkFactory.setSinkDataStream(...);
????????env.execute(inputParams.jobName);
????}
}
總結
本文首先介紹了,在短視頻領域中,短視頻生產(chǎn)消費數(shù)據(jù)鏈路的整個閉環(huán),并且其數(shù)據(jù)鏈路閉環(huán)一般情況下也適用于其他場景;以及對應的實時監(jiān)控方案的設計和不同場景下的代碼實現(xiàn),包括:
垂類生態(tài)短視頻生產(chǎn)消費數(shù)據(jù)鏈路閉環(huán):用戶操作行為日志的流轉,日志上傳,實時計算,以及流轉到 BI,數(shù)據(jù)服務,最后數(shù)據(jù)賦能的整個流程
實時監(jiān)控方案設計:監(jiān)控類實時計算流程中各類數(shù)據(jù)源,數(shù)據(jù)匯的選型
監(jiān)控 id 池在不同量級場景下具體代碼