
擺脫FM!推薦算法一次重要迭代,用戶時序模型
點擊上方藍字,關(guān)注并星標(biāo),和我一起學(xué)技術(shù)。
大家好,今天我們繼續(xù)來聊推薦系統(tǒng)。
之前我們介紹了推薦當(dāng)中應(yīng)用得非常廣泛的FM大家族,從FM這個模型衍生出了一系列的模型,從純FM,到AFM、FFM、DeepFM等等一系列的FM模型,最后的終極版本是xDeepFM。這個模型非常復(fù)雜,可以說是把FM魔改到了極致,今天這篇文章先不討論這個,等以后論文解析的時候好好介紹一下這個模型。
現(xiàn)在回過頭來看的話,會發(fā)現(xiàn)FM模型的各種魔改其實是一種探索,當(dāng)時還不知道未來的出路在哪里,也不知道深度學(xué)習(xí)在推薦領(lǐng)域能夠帶來什么變化。前人嘗試出來FM模型效果不錯,那么最簡單的辦法當(dāng)然是在FM上各種魔改。魔改多了之后,逐漸探索出了方法論,那么就有了下一次的迭代升級。
FM的下一個迭代版本是什么呢?其實不再是單純的某一個或者是某一種模型,而是一種思想和方法。我們之前的文章也提到過,也就是應(yīng)用Embedding向量的方法,基于Embedding向量的應(yīng)用,到這里有衍生出了許多個分支,有了更細(xì)維度的拆分。比如有的繼續(xù)研究傳統(tǒng)CTR的提升,有的研究模型的多任務(wù)學(xué)習(xí),可以讓模型同時優(yōu)化幾個指標(biāo),有的研究強化學(xué)習(xí),想要訓(xùn)練出更加智能的模型等等。
今天我們還是先來聊聊最傳統(tǒng)的CTR優(yōu)化的方向,給大家介紹幾個相對來說比較前沿的模型和方法。
用戶時序特征
之前在介紹FM模型的時候,曾經(jīng)提到過它有一個巨大的問題,就是模型的輸入的維度是固定的,也就是說我們生成的特征也是固定的。看起來這個沒什么問題,因為無論機器學(xué)習(xí)還是深度學(xué)習(xí),它們的模型基本上參數(shù)空間都是固定的,至少大小是固定的。
問題不在于模型,而在于應(yīng)用的時候,我們還是以電商場景舉例,大家都知道在電商場景當(dāng)中,有的用戶活躍,行為多,有的用戶相對不那么活躍,比較冷淡,偶爾來買點東西。對于這兩種不同的用戶來說,顯然前者的行為更多,傳遞的信息也就更多。這個也很好理解,用戶行為越多,喜好越明顯,相反如果用戶缺什么來買什么就很難猜測喜好。
但由于模型的輸入是固定的,過去買過100件商品和沒買過商品的用戶,他們的特征加工完了之后是同樣的維度,顯然這會導(dǎo)致前者丟失大量的信息。另外一個問題是FM模型本身沒有時序處理的部分,它肯定就學(xué)不到時序的一些信息。比如張三一周之前想買襪子,于是點擊了很多襪子,前兩天又對一款游戲感興趣,點擊了幾次游戲。可能總體上來說游戲點擊的次數(shù)不如襪子多,但顯然由于游戲點擊的行為發(fā)生地距離現(xiàn)在更近,他之后會點擊游戲的概率要大于襪子。如果只是單純的制作一個用戶過去最經(jīng)常點擊的類別,那么對于張三來說這個類別顯然是襪子,但是這個信息肯定是不準(zhǔn)確的。
早年的算法工程師們也不傻,也都知道要把用戶行為的特征著重研究,應(yīng)用進模型。但這里有兩個問題,第一個問題是用戶的行為數(shù)量是不同的,有的用戶行為多有的行為少,但模型的參數(shù)往往是固定的。第二個問題是FM模型沒有時序的處理邏輯,它不能處理時間上的先后關(guān)系以及這個關(guān)系帶來的影響。
由于這兩個問題的存在,導(dǎo)致了我們僅僅制作特征是不夠的,包含的信息往往比較片面,我們還需要模型層面的改進。
怎么改進呢,其實很簡單,不是說了FM本身沒有時序處理的部分,導(dǎo)致它學(xué)不到先后邏輯上的關(guān)聯(lián)么。那什么領(lǐng)域的模型主要研究時序?NLP,因為語句是有先后順序的,無論是文本分析還是機器翻譯都需要考慮上下文,所以NLP是最早使用RNN、LSTM等時序模型的領(lǐng)域。
NLP先行一步,推薦也緊跟而上,嘗試著將NLP的一些技術(shù)和思想應(yīng)用到推薦模型當(dāng)中來,由此誕生了許許多多的模型。在這里承志著重挑選了這兩年效果不俗得到廣泛認(rèn)可的模型給大家簡單介紹一下。
DIN
關(guān)于DIN模型的論文解析上周已經(jīng)寫過了,大家想看的話可以點擊下方的傳送門進行訪問。
推薦領(lǐng)域開創(chuàng)性論文,詳解阿里巴巴DIN模型
整體上來說DIN模型的原理并不復(fù)雜,相反還很簡單。它的本身其實就是一個Embedding + MLP的結(jié)構(gòu),只不過在其中加上了DIN模塊。也就是下圖紅框當(dāng)中的部分。
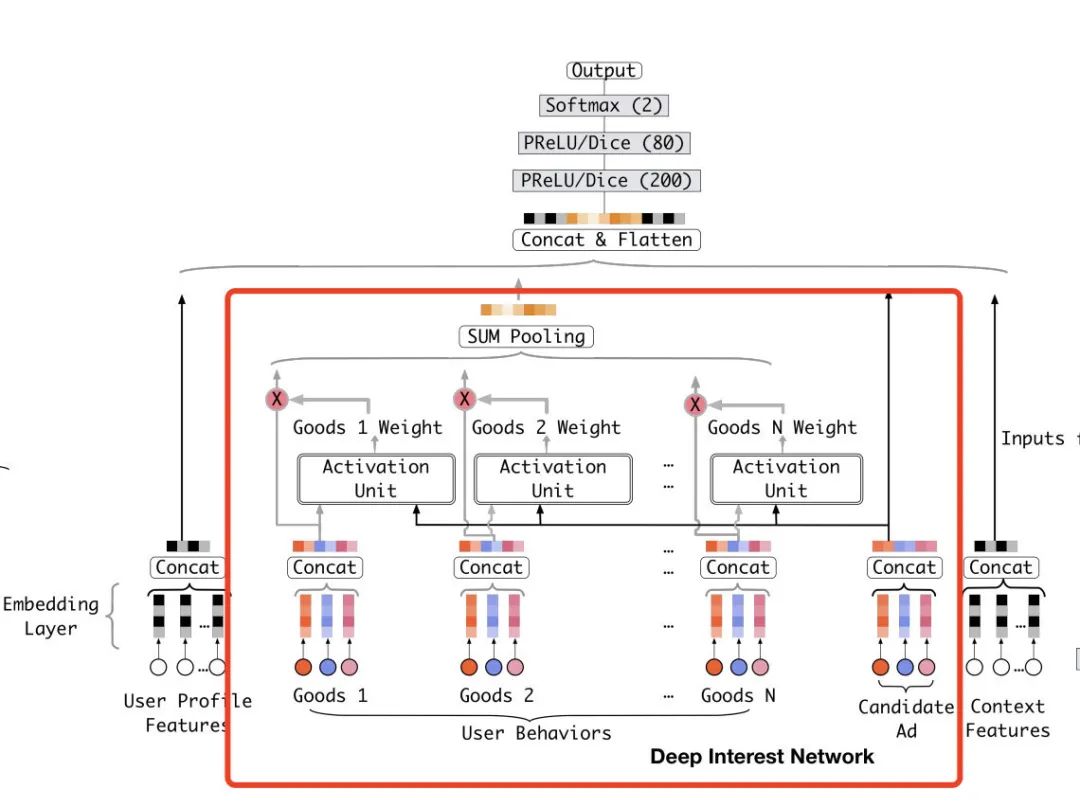
紅框當(dāng)中的Goods1到Goods N表示的用戶歷史的行為數(shù)據(jù),也就是用戶和哪些商品有過交互。對于用戶交互過的每一個商品,我們都通過Activation Unit計算它和當(dāng)前將要預(yù)測的候選商品的權(quán)重。這個權(quán)重也可以理解成相似度,也就是用戶交互的商品和候選的商品的相似度。然后我們把序列里所有商品都通過這個方式得到權(quán)重,并且對它們的Embedding表示通過sum pooling進行加權(quán)求和,最后我們把這么一個加權(quán)求和得到的向量輸入DNN。
這里的精髓有兩個,一個是sum pooling可以解決有的用戶行為多有的行為少的問題,因為sum到一起了之后長度就固定了。第二個是這里的權(quán)重要經(jīng)過一次softmax運算,這樣可以保證所有權(quán)重之和為1。
Transformer
第二個要介紹的模型叫做transformer,如果說DIN只是借鑒了NLP當(dāng)中時序模型的一些處理邏輯和思想的話,那么transformer幾乎就是實打?qū)嵉闹苯影徇\了。
transformer原本是NLP領(lǐng)域的模型,尤其在機器翻譯上獲得了非常好的效果。它本質(zhì)上是一個encoder和decoder的結(jié)合,也就是一個編碼器和解碼器的結(jié)合。也就是說通過編碼和解碼的過程,讓模型學(xué)到兩個序列之間的映射或者是內(nèi)在關(guān)系。
它的整個模型結(jié)構(gòu)圖如下所示:
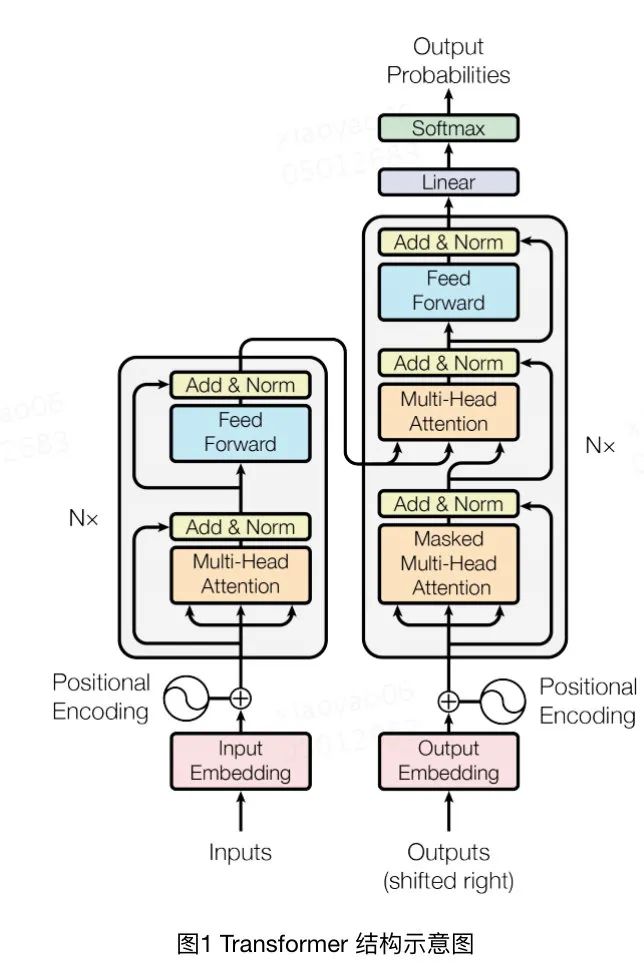
上圖當(dāng)中左邊一列是編碼器,也就是將input通過Multi-Head Attention、Add & Norm等操作最后輸入到解碼器decoder當(dāng)中。解碼器會對output做同樣的編碼操作,然后再學(xué)習(xí)兩個編碼之間的交叉信息。至于Multi-Head Attention、Add & Norm這些子模塊當(dāng)中究竟進行了什么樣的操作,這里就不多做贅述了,有很多復(fù)雜的實現(xiàn)細(xì)節(jié),大家感興趣的話可以去閱讀論文原文。
正是因為它開創(chuàng)性地對輸入和輸出都做了編碼和解碼的操作,使得它在機器翻譯的領(lǐng)域大放異彩,獲得了非常好的效果。對于推薦領(lǐng)域來說,它不需要預(yù)測一個序列,只需要預(yù)測當(dāng)前item的CTR。所以它主要被用來處理用戶行為序列這個特征,利用transformer結(jié)構(gòu)對用戶行為序列當(dāng)中的item以及目標(biāo)item進行encoding和decoding運算,得到一個定長的向量。
這里我們可以看下transformer在美團推薦場景下的應(yīng)用,我找來了博客里的圖。
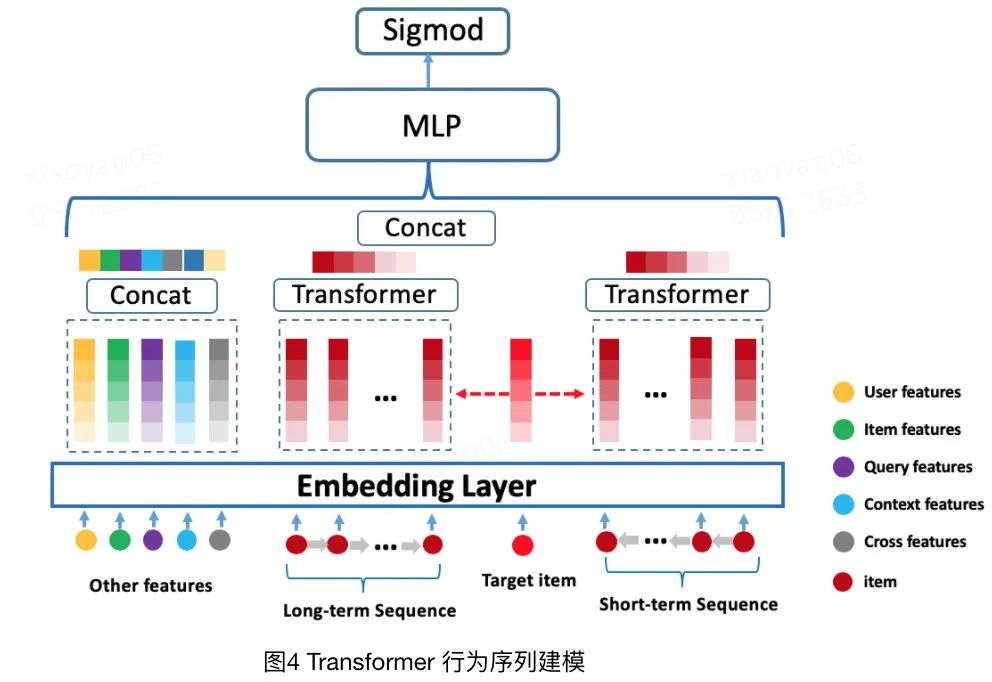
從圖中可以看得出來,它的結(jié)構(gòu)和DIN沒有什么本質(zhì)上的區(qū)別,無非是把用戶行為序列按照時間長短分成了兩個部分。然后多個Embedding歸并的方法不再是sum pooling而是transformer而已。
總結(jié)
在推薦場景,尤其是電商場景下,用戶的歷史行為數(shù)據(jù)至關(guān)重要,它能直接反應(yīng)用戶的興趣以及偏好。尤其是當(dāng)用戶行為序列很長的時候,還能反應(yīng)出用戶歷史行為以及消費能力的變化,使得模型的預(yù)測能夠更加精準(zhǔn)。淘寶的首頁推薦能做得這么好,總能推出很吸引人耳目一新的商品,和用戶行為序列特征的深度挖掘和使用脫不開干系。
DIN和BST(Transformer)這兩篇論文分別發(fā)表于18和19年,它的作者都是阿里巴巴,應(yīng)該算是推薦領(lǐng)域比較前沿尖端的論文了。非常推薦給想要從事推薦算法領(lǐng)域的小伙伴。
好了,今天的文章就到這里,感謝閱讀,喜歡的話不要忘了三連。