
超分辨率在移動實時音視頻的應用實踐
共 2421字,需瀏覽 5分鐘
·
2022-02-09 17:35
在 RTC 2019實時互聯(lián)網(wǎng)大會上,聲網(wǎng)Agora AI 算法工程師周世付,分享了超分辨率應用于移動端實時音視頻場景下,遇到的難點、通用解決方法,以及解決思路。

近年來,超分辨率(簡稱超分)在圖像增強、去噪、細節(jié)恢復、圖像放大方面展現(xiàn)出廣闊的應用前景,成為計算機視覺領域的研究熱點,受到學術界和工業(yè)界的關注和重視,業(yè)界也紛紛舉辦超分競賽,比如優(yōu)酷的視頻超分競賽、聲網(wǎng)的圖像超分競賽和深圳市政府舉辦的AI+4K HDR競賽,旨在吸引更多的人參與超分算法的研究和促進超分算法的落地。因為超分算法的大規(guī)模應用落地還存在一些亟需解決的問題。
移動端實時超分的難點
目前,移動端實時音視頻應用目前存在的一個痛點問題是傳輸?shù)囊曨l分辨偏低,而終端顯示屏的分辨率高,存在分辨率不匹配的問題。實時傳輸?shù)囊曨l分辨率普遍偏低,是由于受到傳輸帶寬的限制和實時性的要求。低分辨率視頻不能有效的展現(xiàn)圖像細節(jié),因而帶來的用戶體驗有限。為了解決傳輸視頻與終端顯示屏分辨率不匹配的問題,通常的做法是將低分辨率視頻進行放大。
傳統(tǒng)最常用的放大方法是插值法,如bicubic、nearest、bilinear等,優(yōu)點是速度快,但缺點也很明顯,即圖像放大后,圖像存在模糊、細節(jié)丟失的現(xiàn)象。

而隨著深度學習的出現(xiàn),基于深度學習的超分已經(jīng)成為了新的解決方案,也是學術界與工業(yè)界都在研究的方法。它能有效地恢復圖像的細節(jié),并保持圖像清晰度。但基于深度學習的超分算法在落地應用的過程中,也面臨著挑戰(zhàn),主要表包括:(1)超分模型過大;(2)超分算法運算復雜。

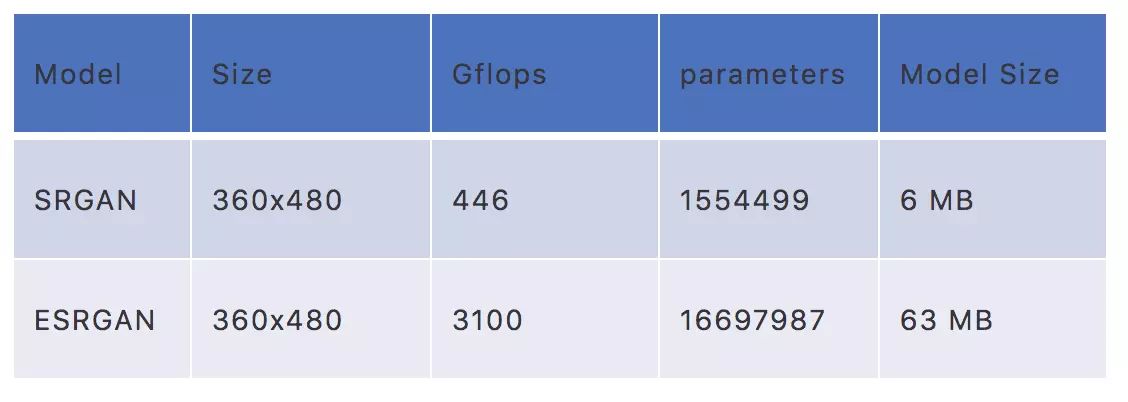
超分與Bicubic對比 目前學術界有兩個經(jīng)典超分模型SRGAN和ESRGAN,如下表 1 所示,我們列出了兩個模型的參數(shù)量和算法復雜度。SRGAN和ESRGAN的參數(shù)量分別達到150萬和1600萬,所需要的存儲空間分別是6MB和63MB。對于移動設備來說,模型太大,會占用過多存儲。
再看運算復雜度方面。以360x480大小的圖像作為輸入,進行4倍的放大,SRGAN和ESRGAN的運算復雜度分別可以達到446GFLOPs和3100GFLOPs。而目前主流的手機iphone XR的gpu的運算能力大約為500GFLOPs。由此可見,目前的移動設備的運算能力,還無法實時運行現(xiàn)有的超分模型,需要降低模型的算法復雜度和減小模型的體積,才能可能讓實時超分模型在移動設備實時運行。
如何降低算法復雜度與模型體積?
降低模型的算法復雜度和減小模型的體積的方法,通常是模型壓縮和模型加速。模型壓縮的目的,是通過減小模型中冗余的權重,去掉對模型性能貢獻小的分支,從而達到減小模型的參數(shù)量,降低模型的運算量。而模型加速,則是側(cè)重降低卷積運算的開銷,提高卷積運算的效率,從而提高模型的運行速度。模型壓縮和模型加速,是相輔相成的,通過合理的模型壓縮算法和模型加速算法的結(jié)合,能夠有效地減小模型體積和提高模型的運算速度。
模型壓縮方法,可以分為權重優(yōu)化和模型結(jié)構(gòu)設計。權重優(yōu)化也可分為剪枝和量化。 剪枝,是將模型中冗余的權重去掉,以達到模型瘦身的目的。比如,Deep compression[1],通過權值剪枝、權值量化和權值編碼,能夠?qū)⒛P偷捏w積減小49倍。 權重量化,則將權值以低碼率進行存儲,從而減小模型的體積,比如,XNornet[2]模型,對輸入的featuremaps和權值均進行二進制量化,實現(xiàn)58x的模型壓縮和32倍的加速。
經(jīng)典的輕量級模型有suqeezenet[3]、mobilenet[4]和shufflenet[5]。他們從模型結(jié)構(gòu)設計角度來講,通常會采用小卷積核替代大卷積核,如用3x3替代5x5、7x7, 或者1x1替代3x3。在同等條件下,3x3的運算是5x5、7x7的9/25、9/49,而且1x1是3x3的1/9。
模型加速方法,在convolution的基礎上,衍生出了depth-wise convolution、group convolution,point-wise convolution。在mobilenett模型中,大量使用了depth-wise convolution和point-wise convolution。而在shufflenet模型中,則采用了group convolution和point-wise convolution。
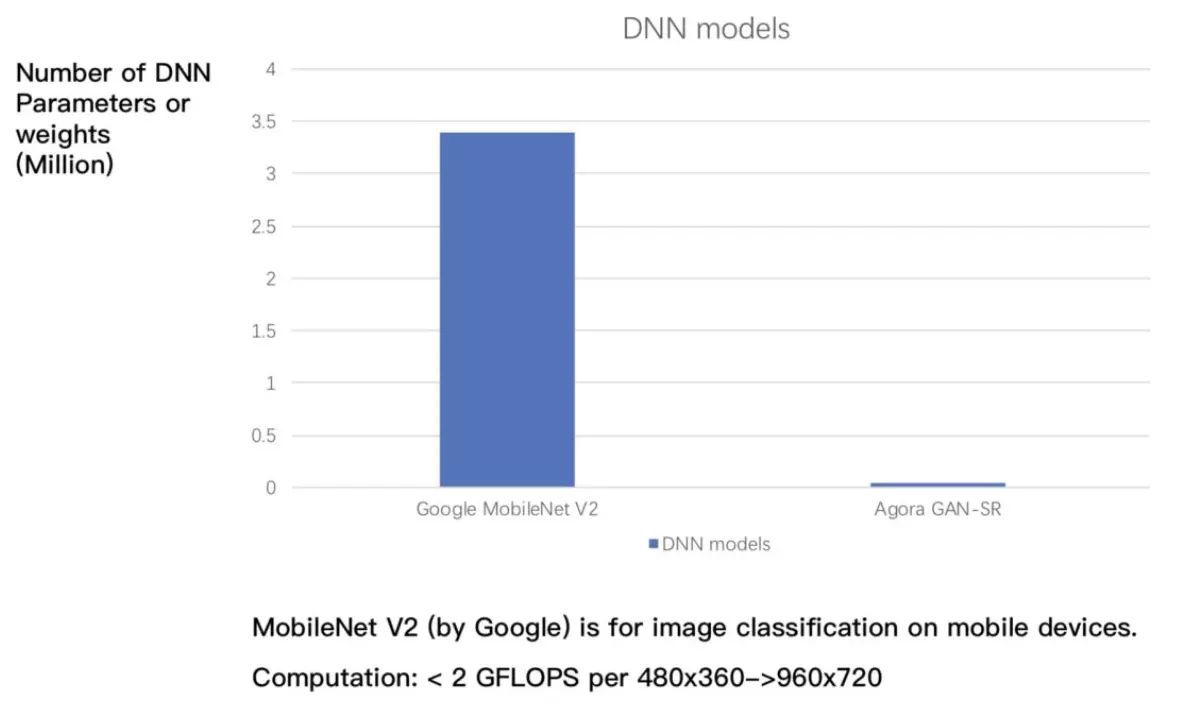
在以上的研究基礎之上,聲網(wǎng)也自研了超分算法。聲網(wǎng)的超分模型的體積,比mobilenet v2還要小。對360p的圖像進行2倍的放大時,其運算復雜度小于2GFLOPs,可實現(xiàn)在移動設備上的實時運行。在運算速度和超分效果實現(xiàn)較好的前提下,有效地提高移動實時音視頻的用戶體驗。
參考文獻
- Han S, Mao H, Dally W J, et al.Deep Compression: Compressing Deep Neural Networks with Pruning, TrainedQuantization and Huffman Coding[J]. arXiv: Computer Vision and PatternRecognition, 2015.
- Rastegari M, Ordonez V, RedmonJ, et al. XNOR-Net: ImageNet Classification Using Binary Convolutional NeuralNetworks[C]. european conference on computer vision, 2016: 525-542.
- Iandola F, Han S, Moskewicz MW, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and<0.5MB model size[J]. arXiv: Computer Vision and Pattern Recognition, 2017.
- Howard A G, Zhu M, Chen B, etal. MobileNets: Efficient Convolutional Neural Networks for Mobile VisionApplications[J]. arXiv: Computer Vision and Pattern Recognition, 2017.
- Zhang X, Zhou X, Lin M, et al.ShuffleNet: An Extremely Efficient Convolutional Neural Network for MobileDevices[J]. arXiv: Computer Vision and Pattern Recognition, 2017.