
【機器學習】圖解機器學習中的 12 種交叉驗證技術
今天我給大家盤點下機器學習中所使用的交叉驗證器都有哪些,用最直觀的圖解方式來幫助大家理解他們是如何工作的。
數(shù)據(jù)集說明
數(shù)據(jù)集來源于kaggle M5 Forecasting - Accuracy[1]
該任務是盡可能精確地預測沃爾瑪在美國銷售的各種產品的單位銷售額(demand)。本文將使用其中的一部分數(shù)據(jù)。
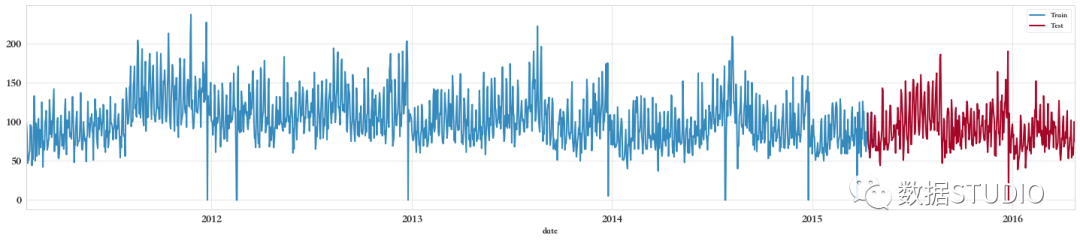
該數(shù)據(jù)樣例如下。

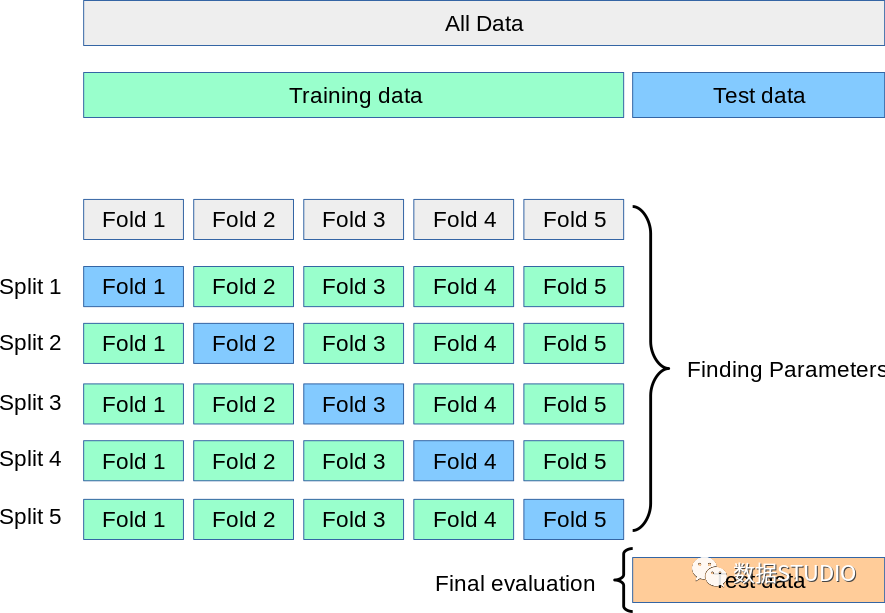
數(shù)據(jù)集的劃分需要根據(jù)交叉驗證基本原理來操作。首先需要將所有數(shù)據(jù)集劃分為訓練集和測試集,再再訓練集中利用交叉驗證劃分訓練集和驗證集,如下圖所示。
首先按照日期date劃分測試集和訓練集,如下圖所示。
為本次演示需求,創(chuàng)造了一些新的特征,最終篩選并使用了如下幾個變量。
Training columns:
['sell_price', 'year', 'month', 'dayofweek', 'lag_7',
'rmean_7_7', 'demand_month_mean', 'demand_month_max',
'demandmonth_max_to_min_diff', 'demand_dayofweek_mean',
'demand_dayofweek_median', 'demand_dayofweek_max']
設置如下兩個全局變量,以及用來存儲每種交叉驗證得分結果的DataFrame
SEED = 888 # 為了再現(xiàn)
NFOLDS = 5 # 設置K折驗證的折數(shù)
stats = pd.DataFrame(columns=['K-Fold Variation','CV-RMSE','TEST-RMSE'])
交叉驗證
交叉驗證(Cross Validation) 是在機器學習建立模型和驗證模型參數(shù)時常用的方法。顧名思義,就是重復的使用數(shù)據(jù),把得到的樣本數(shù)據(jù)進行切分,組合為不同的訓練集和測試集。用訓練集來訓練模型,測試集來評估模型的好壞。
交叉驗證的目的
從有限的學習數(shù)據(jù)中獲取盡可能多的有效信息。 交叉驗證從多個方向開始學習樣本的,可以有效地避免陷入局部最小值。 可以在一定程度上避免過擬合問題。
交叉驗證的種類
根據(jù)切分的方法不同,交叉驗證分為下面三種:
第一種是簡單交叉驗證
首先,隨機的將樣本數(shù)據(jù)分為兩部分(比如:70%的訓練集,30%的測試集),然后用訓練集來訓練模型,在測試集上驗證模型及參數(shù)。接著再把樣本打亂,重新選擇訓練集和測試集,繼續(xù)訓練數(shù)據(jù)和檢驗模型。最后選擇損失函數(shù)評估最優(yōu)的模型和參數(shù)。
第二種是K折交叉驗證(K-Fold Cross Validation)
和第一種方法不同, 折交叉驗證會把樣本數(shù)據(jù)隨機的分成 份,每次隨機的選擇 份作為訓練集,剩下的1份做測試集。當這一輪完成后,重新隨機選擇 份來訓練數(shù)據(jù)。若干輪(小于 )之后,選擇損失函數(shù)評估最優(yōu)的模型和參數(shù)。
第三種是留一交叉驗證(Leave-one-out Cross Validation)
它是第二種情況的特例,此時 等于樣本數(shù) ,這樣對于 個樣本,每次選擇 個樣本來訓練數(shù)據(jù),留一個樣本來驗證模型預測的好壞。此方法主要用于樣本量非常少的情況,比如對于普通適中問題, 小于50時,一般采用留一交叉驗證。
下面將用圖解方法詳細介紹12種交叉驗證方法,主要參考scikit-learn官網(wǎng)[2]介紹。
交叉驗證器
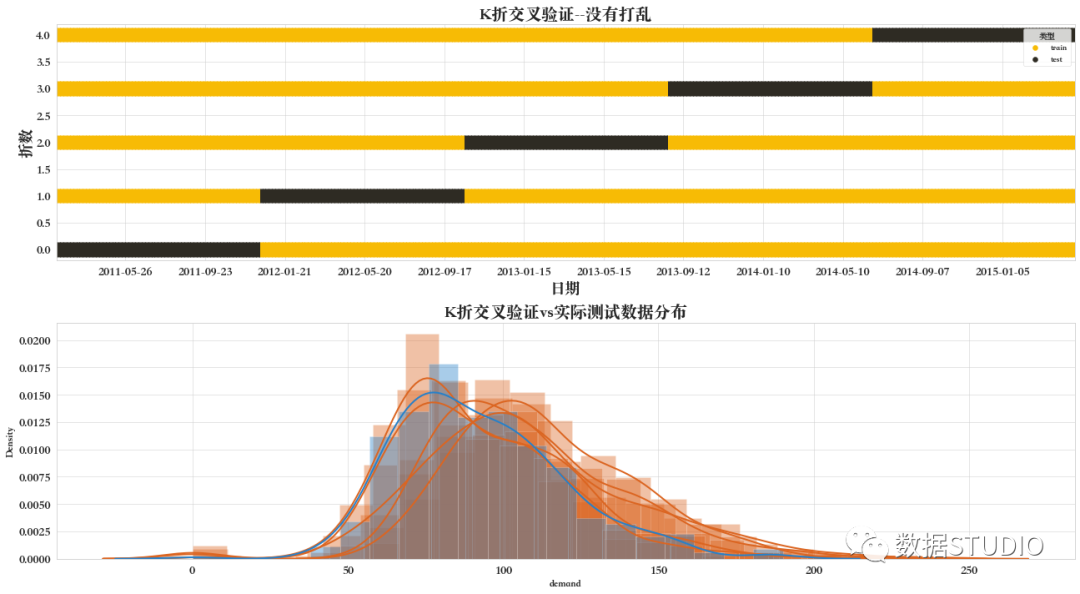
01 K折交叉驗證--沒有打亂
折交叉驗證器 KFold,提供訓練/驗證索引以拆分訓練/驗證集中的數(shù)據(jù)。將數(shù)據(jù)集拆分為 個連續(xù)的折疊(默認情況下不改組)。然后將每個折疊用作一次驗證,而剩余的 個折疊形成訓練集。
from sklearn.model_selection import KFold
KFold(n_splits= NFOLDS, shuffle=False, random_state=None)
CV mean score: 23.64240, std: 1.8744.
Out of sample (test) score: 20.455980
不建議使用這種類型的交叉驗證來處理時間序列數(shù)據(jù),因為它忽略了數(shù)據(jù)的連貫性。實際的測試數(shù)據(jù)是將來的一個時期。
如下圖所示,黑色部分為被用作的驗證的一個折疊,而黃色部分為被用作訓練的 個折疊。
另外數(shù)據(jù)分布圖是5折交叉驗證中每個驗證數(shù)據(jù)集(黑色部分),及實際用作驗證模型的數(shù)據(jù)集的組合分布圖。
02 K折交叉驗證--打亂的
K折交叉驗證器KFold設置參數(shù)shuffle=True
from sklearn.model_selection import KFold
KFold(n_splits= NFOLDS, random_state=SEED, shuffle=True)
CV mean score: 22.65849, std: 1.4224.
Out of sample (test) score: 20.508801
在每次迭代中,五分之一的數(shù)據(jù)仍然是驗證集,但這一次它是隨機分布在整個數(shù)據(jù)中。與前面一樣,在一個迭代中用作驗證的每個示例永遠不會在另一個迭代中用作驗證。
如下圖所示,黑色部分為被用作驗證的數(shù)據(jù)集,很明顯,驗證集數(shù)據(jù)是被打亂了的。
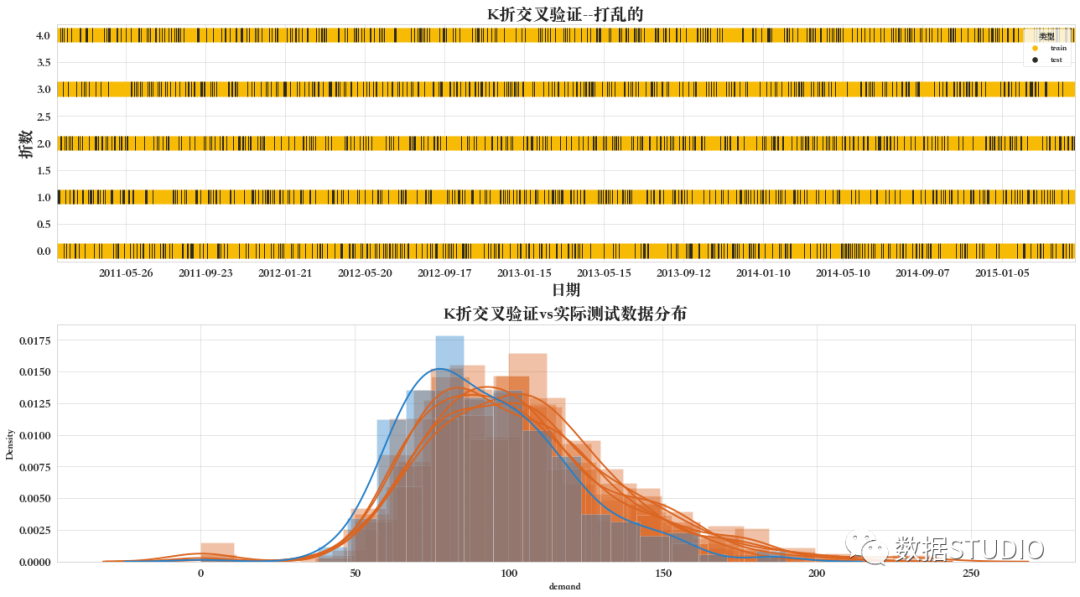
03 隨機排列交叉驗證
隨機排列交叉驗證器ShuffleSplit,生成索引以將數(shù)據(jù)拆分為訓練集和驗證集。
注意:與其他交叉驗證策略相反,隨機拆分并不能保證所有折疊都會不同,盡管對于大型數(shù)據(jù)集來說z這是很有可能。
from sklearn.model_selection import ShuffleSplit
ShuffleSplit(n_splits= NFOLDS,
random_state=SEED,
train_size=0.7,
test_size=0.2)
# 還有0.1的數(shù)據(jù)是沒有被取到的
CV mean score: 22.93248, std: 1.0090.
Out of sample (test) score: 20.539504
ShuffleSplit將在每次迭代過程中隨機抽取整個數(shù)據(jù)集,生成一個訓練集和一個驗證集。test_size和train_size參數(shù)控制每次迭代的驗證和訓練集的大小。因為我們在每次迭代中都是從整個數(shù)據(jù)集采樣,所以在一次迭代中選擇的值,可以在另一次迭代中再次選擇。
由于部分數(shù)據(jù)未包含在訓練中,該方法比普通的k倍交叉驗證更快。
如下圖所示,黑色部分為被用作驗證的數(shù)據(jù)集,橙色是被用作訓練的數(shù)據(jù)集,而白色部分為未被包含在訓練和驗證集中的數(shù)據(jù)集。
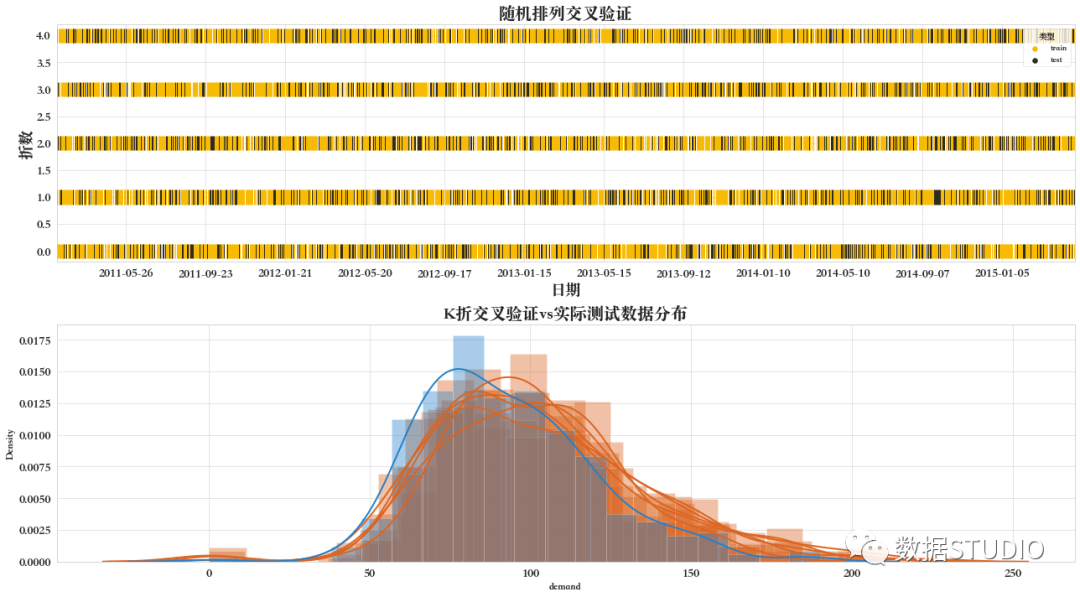
04 分層K折交叉驗證--沒有打亂
分層 折交叉驗證器StratifiedKFold。
提供訓練/驗證索引以拆分訓練/驗證集中的數(shù)據(jù)。這個交叉驗證對象是 KFold 的一種變體,它返回分層折疊。通過保留每個類別的樣本百分比來進行折疊。
from sklearn.model_selection import StratifiedKFold
StratifiedKFold(n_splits= NFOLDS, shuffle=False)
CV mean score: 22.73248, std: 0.4955.
Out of sample (test) score: 20.599119
就跟普通的 折交叉驗證類似,但是每折包含每個目標樣本的大約相同的百分比。更好地使用分類而不是回歸。
其中有幾點需要注意:
生成驗證集中,使每次切分的訓練/驗證集中的包含類別分布相同或盡可能接近。 當 shuffle=False時,將保留數(shù)據(jù)集排序中的順序依賴關系。也就是說,某些驗證集中來自類 k 的所有樣本在 y 中是連續(xù)的。生成驗證集大小一致,即最小和最大驗證集數(shù)據(jù)數(shù)量,最多也就相差一個樣本。
如下圖所示,在沒有打亂的情況下,驗證集(圖中黑色部分)分布是有一定的規(guī)律的。
且從下面的數(shù)據(jù)分布圖可見,5折交叉驗證數(shù)據(jù)密度分布曲線基本重合,說明雖然劃分的樣本不同,但其分布基本一致。
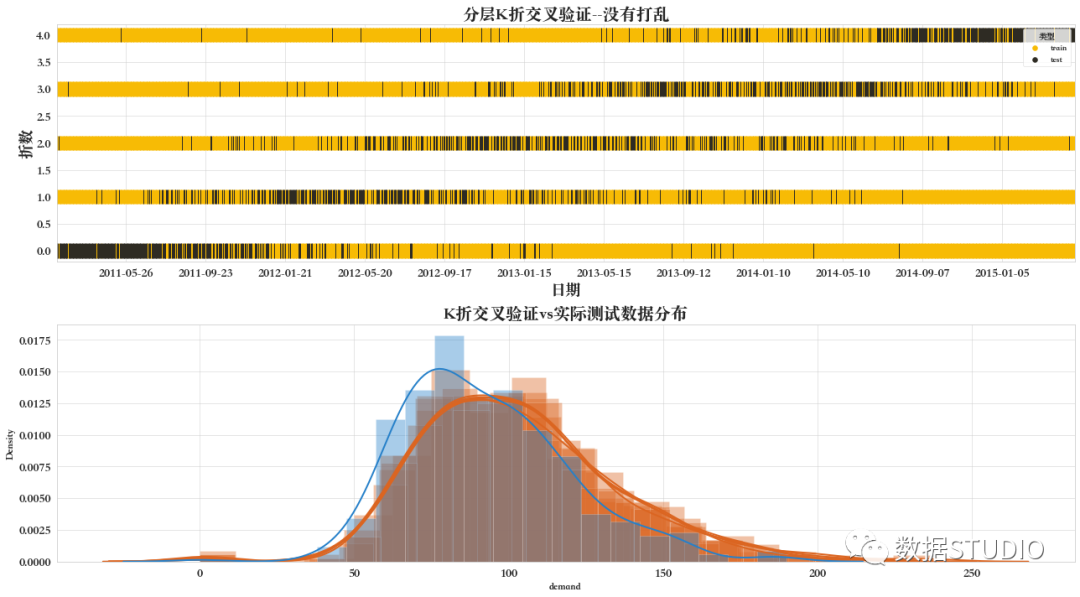
05 分層K折交叉驗證--打亂的
對于每個目標,折疊包大約相同百分比的樣本,但首先數(shù)據(jù)被打亂。這里需要注意的是,該交叉驗證的拆分數(shù)據(jù)方法是一致的,僅僅是在拆分前,先打亂數(shù)據(jù)的排列,再進行分層 折交叉驗證。
from sklearn.model_selection import StratifiedKFold
StratifiedKFold(n_splits= NFOLDS, random_state=SEED,
shuffle=True)
CV mean score: 22.47692, std: 0.9594.
Out of sample (test) score: 20.618389
如下圖所示,打亂的分層K折交叉驗證的驗證集是沒有規(guī)律、隨機分布的。
該交叉驗證的數(shù)據(jù)分布與未被打亂的分層K折交叉驗證基本一致。
06 分組K折交叉驗證
具有非重疊組的 折迭代器變體GroupKFold。
同一組不會出現(xiàn)在兩個不同的折疊中(不同組的數(shù)量必須至少等于折疊的數(shù)量)。這些折疊是近似平衡的,因為每個折疊中不同組的數(shù)量是近似相同的。
可以從數(shù)據(jù)集的另一特定列(年)來定義組。確保同一組中不同時處于訓練集和驗證集中。
該交叉驗證器分組是在方法split中參數(shù)groups來體現(xiàn)出來的。
from sklearn.model_selection import GroupKFold
groups = train['year'].tolist()
groupfolds = GroupKFold(n_splits=NFOLDS)
groupfolds.split(X_train,Y_train, groups=groups)
CV mean score: 23.21066, std: 2.7148.
Out of sample (test) score: 20.550477
如下圖所示,由于數(shù)據(jù)集原因(不是包含5個整年(組)),因此5折交叉驗證中,并不能保證沒次都包含相同數(shù)據(jù)數(shù)量的驗證集。
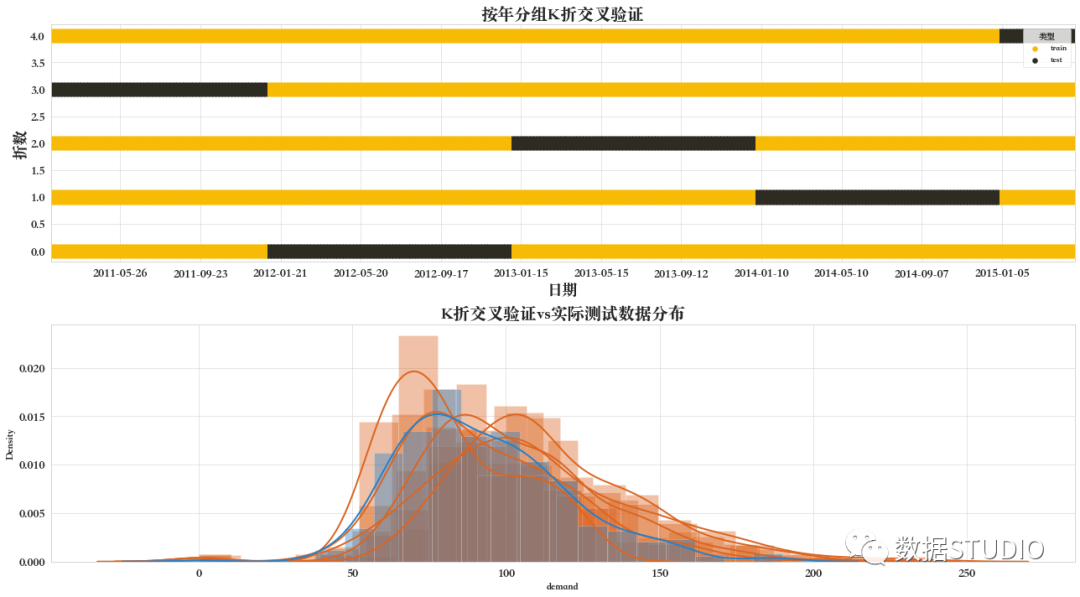
在上一個示例中,我們使用年作為組,在下一個示例中使用月作為組。大家可以通過下面圖可以很明顯地看看有什么區(qū)別。
from sklearn.model_selection import GroupKFold
groups = train['month'].tolist()
groupfolds = GroupKFold(n_splits=NFOLDS)
groupfolds.split(X_train,Y_train, groups=groups)
CV mean score: 22.32342, std: 3.9974.
Out of sample (test) score: 20.481986
如下圖所示,每次迭代均是以月為組來取驗證集。
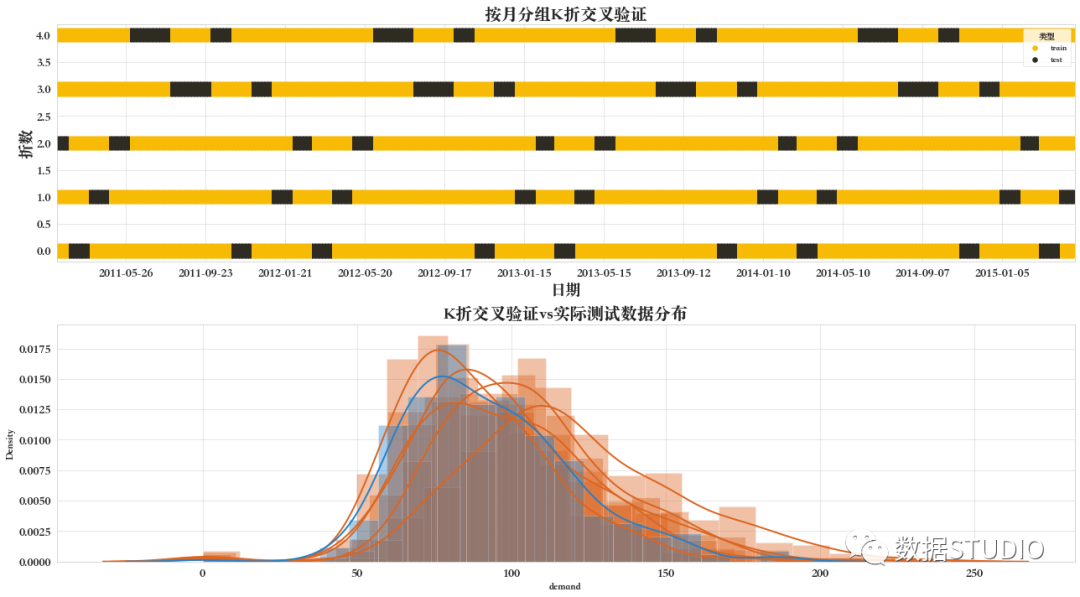
07 分組K折交叉驗證--留一組
留一組交叉驗證器LeaveOneGroupOut。
根據(jù)第三方提供的整數(shù)組數(shù)組保留樣本。此組信息可用于編碼任意特定于域的預定義交叉驗證折疊。
因此,每個訓練集由除與特定組相關的樣本之外的所有樣本構成。
例如,組可以是樣本收集的年份、月份等,因此允許針對基于時間的拆分進行交叉驗證。
from sklearn.model_selection import LeaveOneGroupOut
groups = train['month'].tolist()
n_folds = train['month'].nunique()
logroupfolds = LeaveOneGroupOut()
logroupfolds.split(X_train,Y_train, groups=groups)
CV mean score: 22.48503, std: 5.6201.
Out of sample (test) score: 20.468222
在每次迭代中,模型都使用留一組之外的所有組的樣本進行訓練。如果以月份為組,則執(zhí)行12次迭代。
由下圖可以看到該分組K折交叉驗證的拆分數(shù)據(jù)方法。
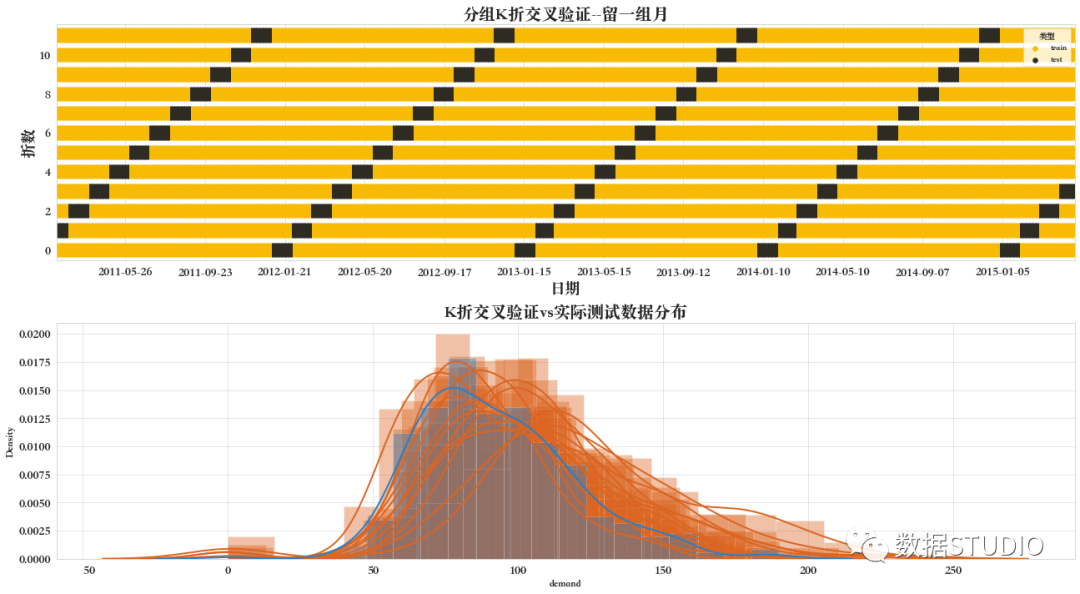
08 分組K折交叉驗證--留N組
LeavePGroupsOut將 P 組留在交叉驗證器之外,例如,組可以是樣本收集的年份,因此允許針對基于時間的拆分進行交叉驗證。
LeavePGroupsOut 和 LeaveOneGroupOut 的區(qū)別在于,前者使用所有樣本分配到P不同的組值來構建測試集,而后者使用所有分配到相同組的樣本。
通過參數(shù)n_groups設置要在測試拆分中排除的組數(shù)。
from sklearn.model_selection import LeavePGroupsOut
groups = train['year'].tolist()
lpgroupfolds = LeavePGroupsOut(n_groups=2)
lpgroupfolds.split(X_train,Y_train, groups=groups)
CV mean score: 23.92578, std: 1.2573.
Out of sample (test) score: 90.222850
由下圖可知,因K=5,n_groups=2,所以共分為10種情況,每種劃分的驗證集均不相同。
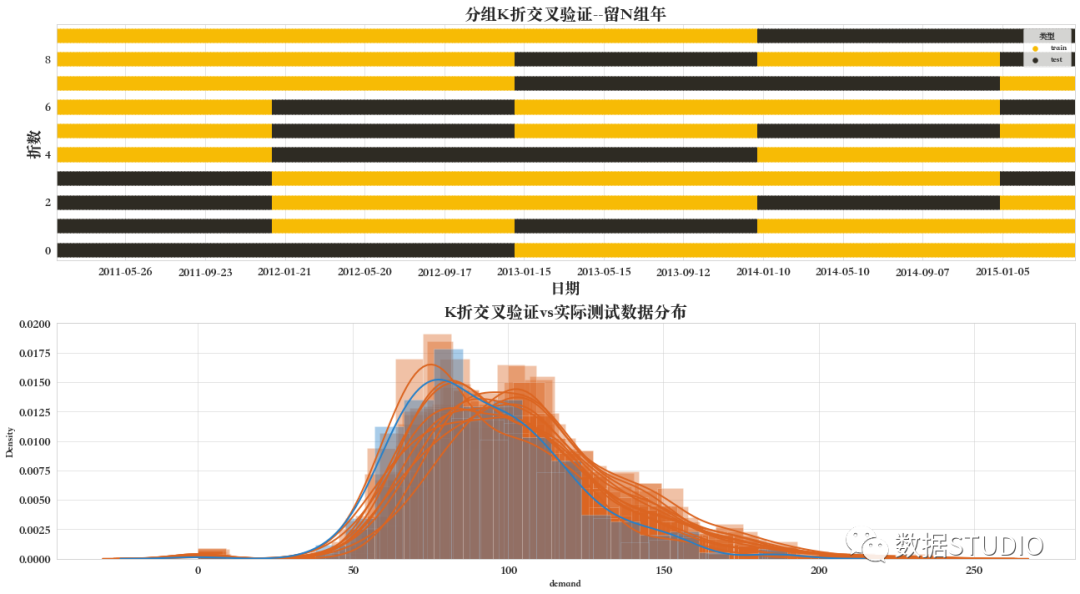
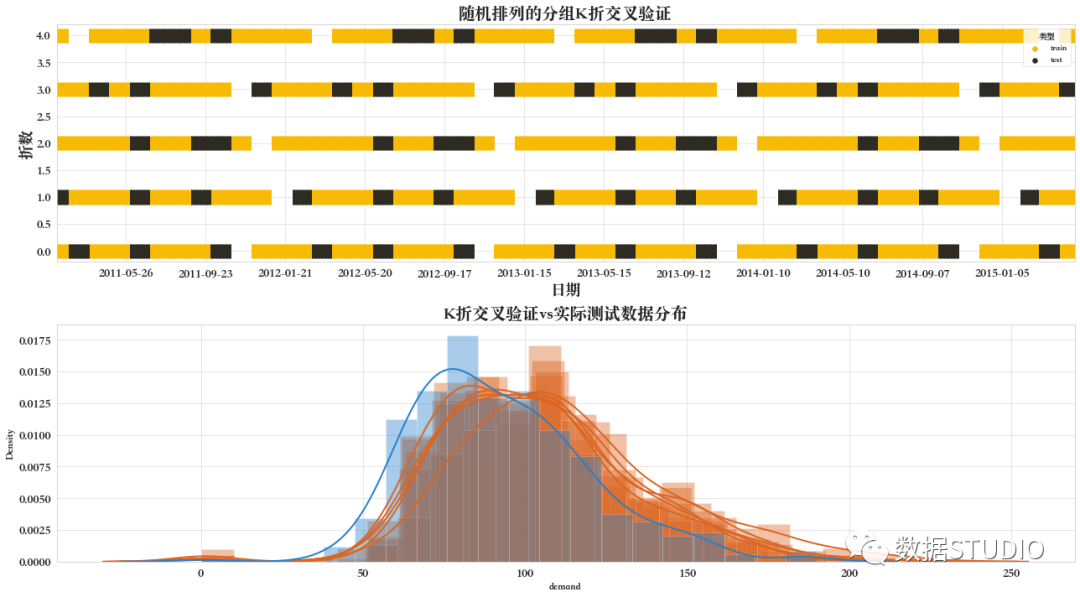
09 隨機排列的分組K折交叉驗證
Shuffle-Group(s)-Out 交叉驗證迭代器GroupShuffleSplit
GroupShuffleSplit迭代器為ShuffleSplit和LeavePGroupsOut的兩種方法的結合,并生成一個隨機分區(qū)序列,其中每個分區(qū)都會保留組的一個子集。
例如,組可以是樣本收集的年份,因此允許針對基于時間的拆分進行交叉驗證。
LeavePGroupsOut 和 GroupShuffleSplit 之間的區(qū)別在于,前者使用大小P唯一組的所有子集生成拆分,而 GroupShuffleSplit 生成用戶確定數(shù)量的隨機驗證拆分,每個拆分都有用戶確定的唯一組比例。
例如,與LeavePGroupsOut(p=10)相比,一個計算強度較小的替代方案是 GroupShuffleSplit(test_size=10, n_splits=100)。
注意:參數(shù)test_size和train_size指的是組,而不是樣本,像在 ShuffleSplit 中一樣
定義組,并在每次迭代中隨機抽樣整個數(shù)據(jù)集,以生成一個訓練集和一個驗證集。
from sklearn.model_selection import GroupShuffleSplit
groups = train['month'].tolist()
rpgroupfolds = GroupShuffleSplit(n_splits=NFOLDS, train_size=0.7,
test_size=0.2, random_state=SEED)
rpgroupfolds.split(X_train,Y_train, groups=groups)
CV mean score: 21.62334, std: 2.5657.
Out of sample (test) score: 20.354134
從圖中可見,斷開(白色)部分為未取到的數(shù)據(jù)集,每一行中每段(以白色空白為界)中驗證集(黑色)比例及位置都是一致的。而不同行之間驗證集的位置是不同的。
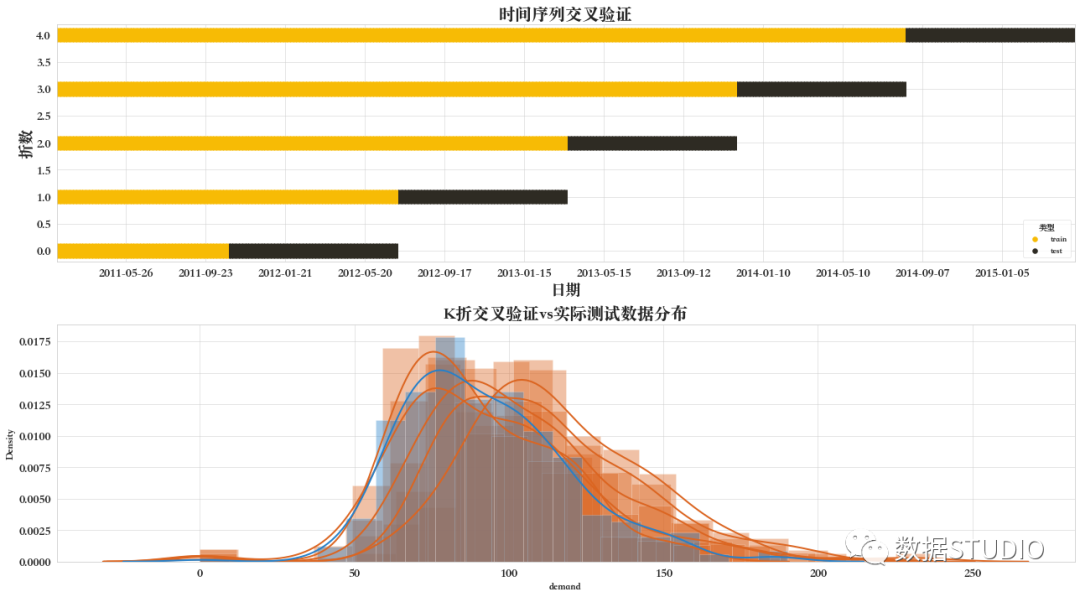
10 時間序列交叉驗證
時間序列數(shù)據(jù)的特征在于時間上接近的觀測值之間的相關性(自相關)。然而,經典的交叉驗證技術,例如 KFold 和 ShuffleSplit假設樣本是獨立的和同分布的,并且會導致時間序列數(shù)據(jù)的訓練和測試實例之間不合理的相關性(產生對泛化誤差的不良估計)。
因此,在“未來”觀察中評估我們的模型的時間序列數(shù)據(jù)非常重要,這與用于訓練模型的觀察最不相似。為了實現(xiàn)這一點,提供了一種解決方案TimeSeriesSplit。
TimeSeriesSplit是KFold的變體,它首先返回 折疊成訓練集和 第 折疊作為驗證集。請注意,與標準交叉驗證方法不同,連續(xù)訓練集是它們之前的超集。此外,它將所有剩余數(shù)據(jù)添加到第一個訓練分區(qū),該分區(qū)始終用于訓練模型。
from sklearn.model_selection import TimeSeriesSplit
timeSeriesSplit = TimeSeriesSplit(n_splits= NFOLDS)
CV mean score: 24.32591, std: 2.0312.
Out of sample (test) score: 20.999613
這種方法建議用于時間序列數(shù)據(jù)。在時間序列分割中,訓練集通常分為兩部分。第一部分始終是訓練集,而后一部分是驗證集。
由下圖可知,驗證集的長度保持不變,而訓練集隨著每次迭代的不斷增大。
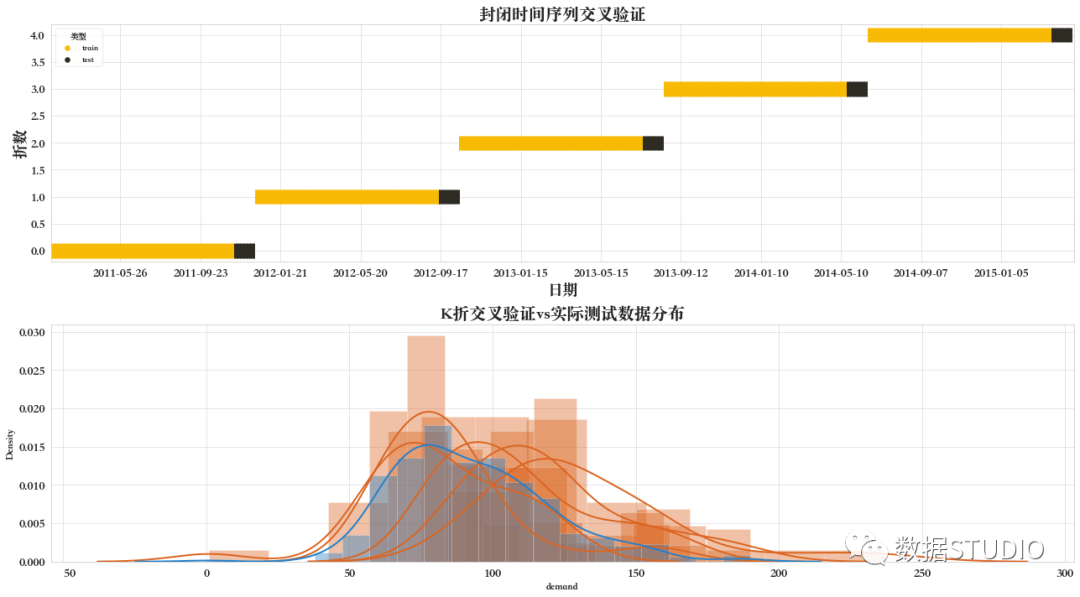
11 封閉時間序列交叉驗證
這是自定義的一種交叉驗證方法。該方法函數(shù)見文末函數(shù)附錄。
btscv = BlockingTimeSeriesSplit(n_splits=NFOLDS)
CV mean score: 22.57081, std: 6.0085.
Out of sample (test) score: 19.896889
由下圖可見,訓練和驗證集在每次迭代中都是唯一的。沒有值被使用兩次。列車集總是在驗證之前。由于在較少的樣本中訓練,它也比其他交叉驗證方法更快。
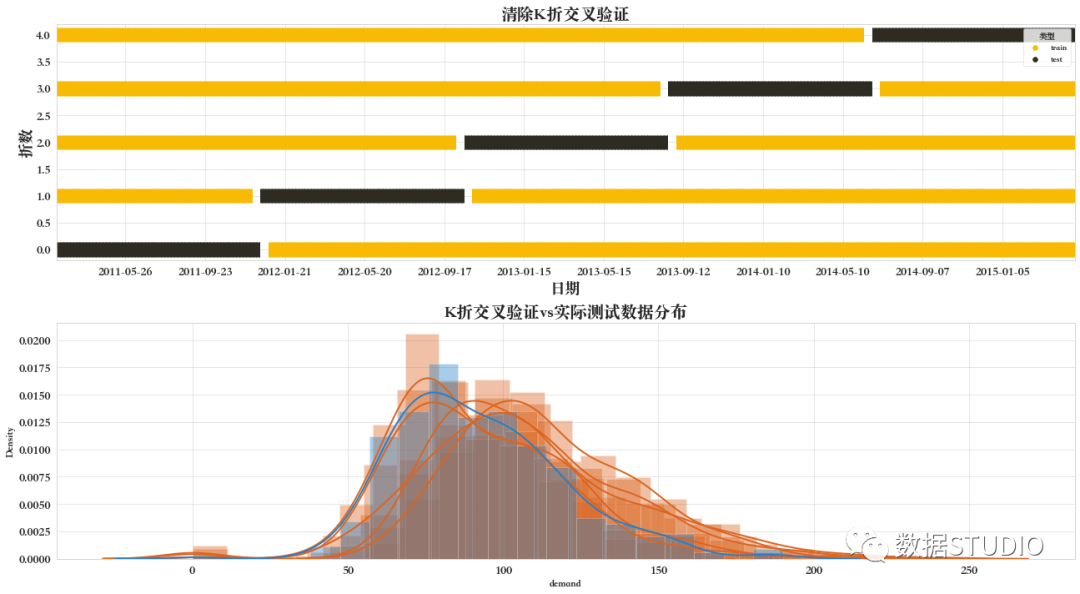
12 清除K折交叉驗證
這是基于_BaseKFold的一種交叉驗證方法。在每次迭代中,在訓練集之前和之后,我們會刪除一些樣本。
cont = pd.Series(train.index)
purgedfolds=PurgedKFold(n_splits=NFOLDS,
t1=cont, pctEmbargo=0.0)
CV mean score: 23.64854, std: 1.9370.
Out of sample (test) score: 20.589597
由下圖可看出,訓練集前后刪除了一些樣本。且其劃分訓練集和驗證集的方法與基礎不打亂的KFold一致。
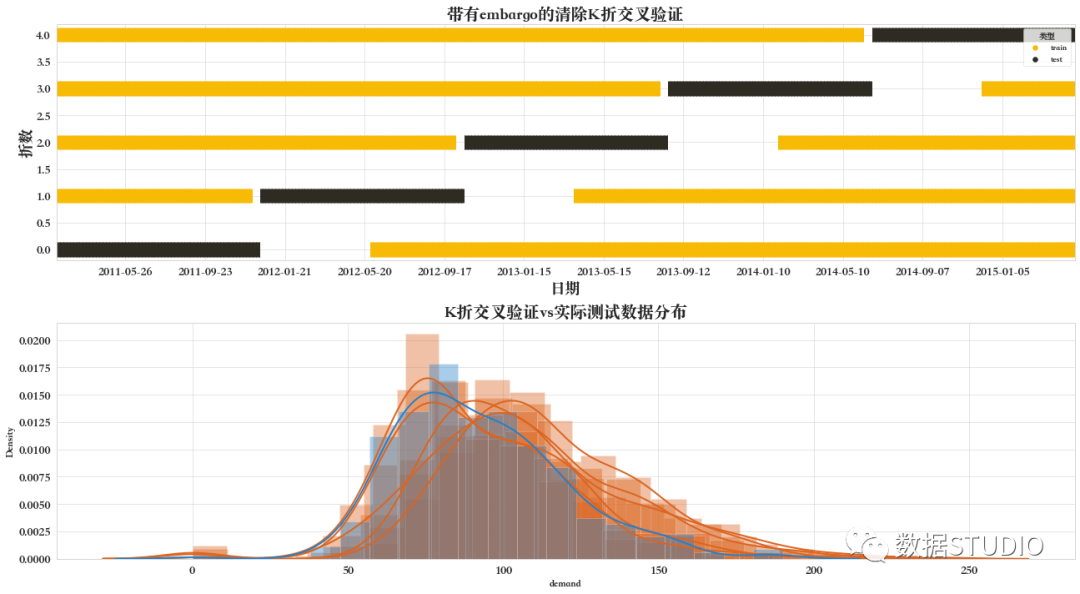
將embargo設置為大于0的值,將在驗證集之后刪除額外的樣本。
cont = pd.Series(train.index)
purgedfolds=PurgedKFold(n_splits=NFOLDS,t1=cont,pctEmbargo=0.1)
CV mean score: 23.87267, std: 1.7693.
Out of sample (test) score: 20.414387
由下圖可看出,不僅在訓練集前后刪除了部分樣本,在驗證集后面也刪除了一些樣本,這些樣本的大小將取決于參數(shù)embargo的大小。
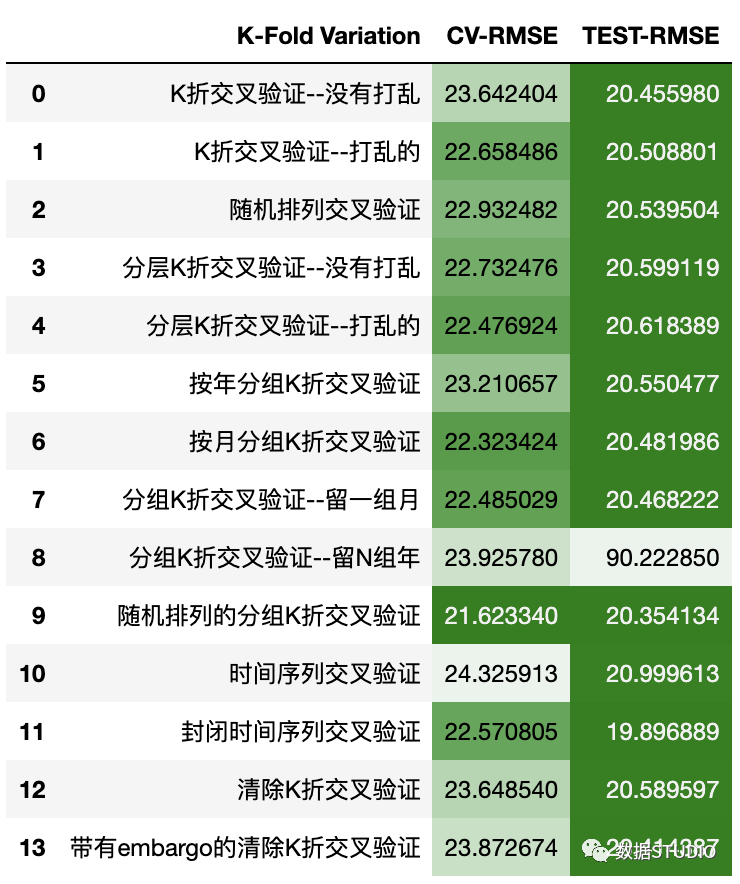
各交叉驗證結果比較
cm = sns.light_palette("green", as_cmap=True, reverse=True)
stats.style.background_gradient(cmap=cm)
附錄
封閉時間序列交叉驗證函數(shù)
class BlockingTimeSeriesSplit():
def __init__(self, n_splits):
self.n_splits = n_splits
def get_n_splits(self, X, y, groups):
return self.n_splits
def split(self, X, y=None, groups=None):
n_samples = len(X)
k_fold_size = n_samples // self.n_splits
indices = np.arange(n_samples)
margin = 0
for i in range(self.n_splits):
start = i * k_fold_size
stop = start + k_fold_size
mid = int(0.9 * (stop - start)) + start
yield indices[start: mid], indices[mid + margin: stop]
清除K折交叉驗證函數(shù)
from sklearn.model_selection._split import _BaseKFold
class PurgedKFold(_BaseKFold):
'''
擴展KFold類以處理跨越間隔的標簽
在訓練集中剔除了重疊的測試標記間隔
假設測試集是連續(xù)的(shuffle=False),中間有w/o訓練樣本
'''
def __init__(self, n_splits=3, t1=None, pctEmbargo=0.1):
if not isinstance(t1, pd.Series):
raise ValueError('Label Through Dates must be a pd.Series')
super(PurgedKFold,self).__init__(n_splits, shuffle=False, random_state=None)
self.t1 = t1
self.pctEmbargo = pctEmbargo
def split(self,X,y=None,groups=None):
X = pd.DataFrame(X)
if (X.index==self.t1.index).sum()!=len(self.t1):
raise ValueError('X and ThruDateValues must have the same index')
indices = np.arange(X.shape[0])
mbrg = int(X.shape[0] * self.pctEmbargo)
test_starts=[(i[0],i[-1]+1) for i in np.array_split(np.arange(X.shape[0]), self.n_splits)]
for i,j in test_starts:
t0 = self.t1.index[i] # 測試集的開始
test_indices = indices[i:j]
maxT1Idx = self.t1.index.searchsorted(self.t1[test_indices].max())
train_indices = self.t1.index.searchsorted(self.t1[self.t1<=t0].index)
if maxT1Idx < X.shape[0]: # 右邊的訓練集帶有 embargo)
train_indices = np.concatenate((train_indices, indices[maxT1Idx+mbrg:]))
yield train_indices,test_indices
參考資料
數(shù)據(jù)集: https://www.kaggle.com/c/m5-forecasting-accuracy
[2]交叉驗證: https://scikit-learn.org/stable/modules/classes.html
往期精彩回顧 本站qq群851320808,加入微信群請掃碼: