
詳解機(jī)器學(xué)習(xí)中的7種交叉驗(yàn)證方法

來(lái)源:機(jī)器學(xué)習(xí)社區(qū)、數(shù)據(jù)派THU
本文約3400字,建議閱讀10分鐘
本文與你分享7種最常用的交叉驗(yàn)證技術(shù)及其優(yōu)缺點(diǎn),提供了每種技術(shù)的代碼片段。在任何有監(jiān)督機(jī)器學(xué)習(xí)項(xiàng)目的模型構(gòu)建階段,我們訓(xùn)練模型的目的是從標(biāo)記的示例中學(xué)習(xí)所有權(quán)重和偏差的最佳值。
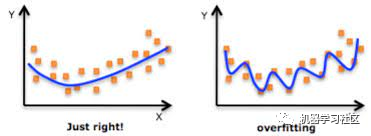
如果我們使用相同的標(biāo)記示例來(lái)測(cè)試我們的模型,那么這將是一個(gè)方法論錯(cuò)誤,因?yàn)橐粋€(gè)只會(huì)重復(fù)剛剛看到的樣本標(biāo)簽的模型將獲得完美的分?jǐn)?shù),但無(wú)法預(yù)測(cè)任何有用的東西 - 未來(lái)的數(shù)據(jù),這種情況稱為過(guò)擬合。
為了克服過(guò)度擬合的問(wèn)題,我們使用交叉驗(yàn)證。所以你必須知道什么是交叉驗(yàn)證?以及如何解決過(guò)擬合的問(wèn)題?
什么是交叉驗(yàn)證?
它是如何解決過(guò)擬合問(wèn)題的?
在本文中,我將分享 7 種最常用的交叉驗(yàn)證技術(shù)及其優(yōu)缺點(diǎn),我還提供了每種技術(shù)的代碼片段,歡迎收藏學(xué)習(xí),喜歡點(diǎn)贊支持。
下面列出了這些技術(shù)方法:
- HoldOut 交叉驗(yàn)證
- K-Fold 交叉驗(yàn)證
- 分層 K-Fold交叉驗(yàn)證
- Leave P Out 交叉驗(yàn)證
- 留一交叉驗(yàn)證
- 蒙特卡洛 (Shuffle-Split)
- 時(shí)間序列(滾動(dòng)交叉驗(yàn)證)
1、HoldOut 交叉驗(yàn)證
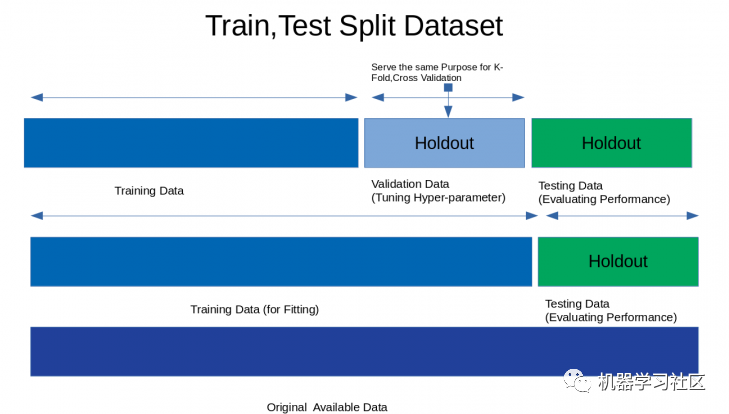
優(yōu)點(diǎn):
1.快速執(zhí)行:因?yàn)槲覀儽仨殞?shù)據(jù)集拆分為訓(xùn)練集和驗(yàn)證集一次,并且模型將在訓(xùn)練集上僅構(gòu)建一次,因此可以快速執(zhí)行。
缺點(diǎn):
1. 不適合不平衡數(shù)據(jù)集:假設(shè)我們有一個(gè)不平衡數(shù)據(jù)集,它具有“0”類和“1”類。假設(shè) 80% 的數(shù)據(jù)屬于“0”類,其余 20% 的數(shù)據(jù)屬于“1”類。在訓(xùn)練集大小為 80%,測(cè)試數(shù)據(jù)大小為數(shù)據(jù)集的 20% 的情況下進(jìn)行訓(xùn)練-測(cè)試分割。可能會(huì)發(fā)生“0”類的所有 80% 數(shù)據(jù)都在訓(xùn)練集中,而“1”類的所有數(shù)據(jù)都在測(cè)試集中。所以我們的模型不能很好地概括我們的測(cè)試數(shù)據(jù),因?yàn)樗皼](méi)有看到過(guò)“1”類的數(shù)據(jù);
2. 大量數(shù)據(jù)無(wú)法訓(xùn)練模型。
在小數(shù)據(jù)集的情況下,將保留一部分用于測(cè)試模型,其中可能具有我們的模型可能會(huì)錯(cuò)過(guò)的重要特征,因?yàn)樗鼪](méi)有對(duì)該數(shù)據(jù)進(jìn)行訓(xùn)練。
代碼片段:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_scoreiris=load_iris()X=iris.dataY=iris.targetprint("Size of Dataset {}".format(len(X)))logreg=LogisticRegression()x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)logreg.fit(x_train,y_train)predict=logreg.predict(x_test)print("Accuracy score on training set is {}".format(accuracy_score(logreg.predict(x_train),y_train)))print("Accuracy score on test set is {}".format(accuracy_score(predict,y_test)))

2、K 折交叉驗(yàn)證
該技術(shù)重復(fù) K 次,直到每個(gè)折疊用作驗(yàn)證集,其余折疊用作訓(xùn)練集。
模型的最終精度是通過(guò)取 k-models 驗(yàn)證數(shù)據(jù)的平均精度來(lái)計(jì)算的。
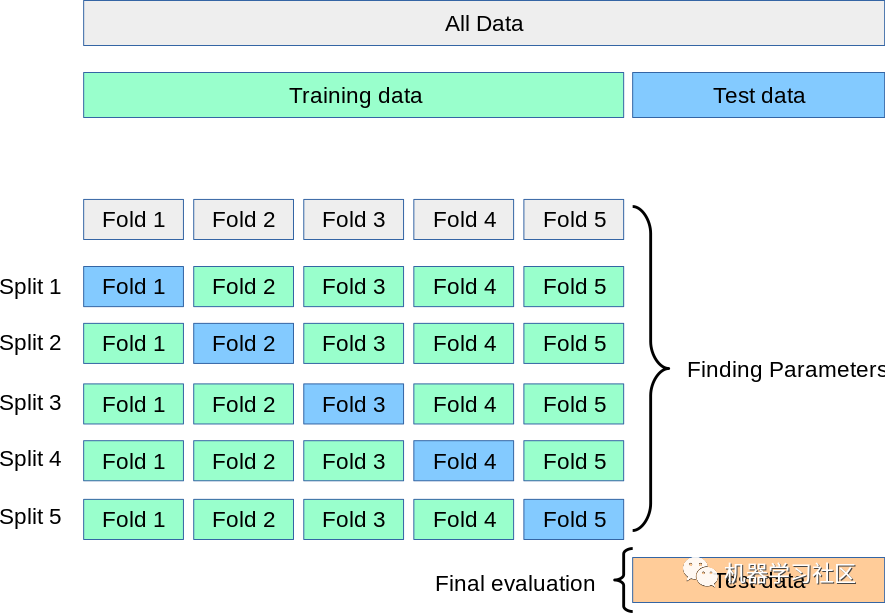
1. 整個(gè)數(shù)據(jù)集既用作訓(xùn)練集又用作驗(yàn)證集。
缺點(diǎn):
1. 不用于不平衡的數(shù)據(jù)集:正如在 HoldOut 交叉驗(yàn)證的情況下所討論的,在 K-Fold 驗(yàn)證的情況下也可能發(fā)生訓(xùn)練集的所有樣本都沒(méi)有樣本形式類“1”,并且只有 類“0”。驗(yàn)證集將有一個(gè)類“1”的樣本;2. 不適合時(shí)間序列數(shù)據(jù):對(duì)于時(shí)間序列數(shù)據(jù),樣本的順序很重要。但是在 K 折交叉驗(yàn)證中,樣本是按隨機(jī)順序選擇的。
代碼片段:
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_score,KFoldfrom sklearn.linear_model import LogisticRegressioniris=load_iris()X=iris.dataY=iris.targetlogreg=LogisticRegression()kf=KFold(n_splits=5)score=cross_val_score(logreg,X,Y,cv=kf)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))

3、分層 K 折交叉驗(yàn)證
但是在這種技術(shù)中,每個(gè)折疊將具有與整個(gè)數(shù)據(jù)集中相同的目標(biāo)變量實(shí)例比率。
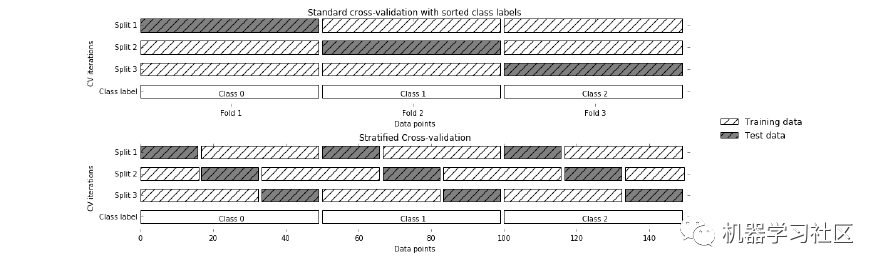
1. 對(duì)于不平衡數(shù)據(jù)非常有效:分層交叉驗(yàn)證中的每個(gè)折疊都會(huì)以與整個(gè)數(shù)據(jù)集中相同的比率表示所有類別的數(shù)據(jù)。
缺點(diǎn):
1. 不適合時(shí)間序列數(shù)據(jù):對(duì)于時(shí)間序列數(shù)據(jù),樣本的順序很重要。但在分層交叉驗(yàn)證中,樣本是按隨機(jī)順序選擇的。
代碼片段:
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_score,StratifiedKFoldfrom sklearn.linear_model import LogisticRegressioniris=load_iris()X=iris.dataY=iris.targetlogreg=LogisticRegression()stratifiedkf=StratifiedKFold(n_splits=5)score=cross_val_score(logreg,X,Y,cv=stratifiedkf)print("Cross Validation Scores are {}".format(score))print("Average?Cross?Validation?score?:{}".format(score.mean()))

4、Leave P Out ?交叉驗(yàn)證
假設(shè)我們?cè)跀?shù)據(jù)集中有 100 個(gè)樣本。如果我們使用 p=10,那么在每次迭代中,10 個(gè)值將用作驗(yàn)證集,其余 90 個(gè)樣本將用作訓(xùn)練集。
重復(fù)這個(gè)過(guò)程,直到整個(gè)數(shù)據(jù)集在 p 樣本和 n-p 訓(xùn)練樣本的驗(yàn)證集上被劃分。
優(yōu)點(diǎn):
1. 所有數(shù)據(jù)樣本都用作訓(xùn)練和驗(yàn)證樣本。
缺點(diǎn):
1. 計(jì)算時(shí)間長(zhǎng):由于上述技術(shù)會(huì)不斷重復(fù),直到所有樣本都用作驗(yàn)證集,因此計(jì)算時(shí)間會(huì)更長(zhǎng);2. 不適合不平衡數(shù)據(jù)集:與 K 折交叉驗(yàn)證相同,如果在訓(xùn)練集中我們只有 1 個(gè)類的樣本,那么我們的模型將無(wú)法推廣到驗(yàn)證集。
代碼片段:
from sklearn.model_selection import LeavePOut,cross_val_scorefrom sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifieriris=load_iris()X=iris.dataY=iris.targetlpo=LeavePOut(p=2)lpo.get_n_splits(X)tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)score=cross_val_score(tree,X,Y,cv=lpo)print("Cross Validation Scores are {}".format(score))print("Average?Cross?Validation?score?:{}".format(score.mean()))

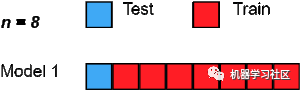
5、留一交叉驗(yàn)證
假設(shè)我們?cè)跀?shù)據(jù)集中有 100 個(gè)樣本。然后在每次迭代中,1 個(gè)值將用作驗(yàn)證集,其余 99 個(gè)樣本作為訓(xùn)練集。因此,重復(fù)該過(guò)程,直到數(shù)據(jù)集的每個(gè)樣本都用作驗(yàn)證點(diǎn)。
它與使用 p=1 的 LeavePOut 交叉驗(yàn)證相同。
代碼片段:
from sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import LeaveOneOut,cross_val_scoreiris=load_iris()X=iris.dataY=iris.targetloo=LeaveOneOut()tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)score=cross_val_score(tree,X,Y,cv=loo)print("Cross Validation Scores are {}".format(score))print("Average?Cross?Validation?score?:{}".format(score.mean()))
6、蒙特卡羅交叉驗(yàn)證(Shuffle Split)
我們已經(jīng)決定了要用作訓(xùn)練集的數(shù)據(jù)集的百分比和用作驗(yàn)證集的百分比。如果訓(xùn)練集和驗(yàn)證集大小的增加百分比總和不是 100,則剩余的數(shù)據(jù)集不會(huì)用于訓(xùn)練集或驗(yàn)證集。
假設(shè)我們有 100 個(gè)樣本,其中 60% 的樣本用作訓(xùn)練集,20% 的樣本用作驗(yàn)證集,那么剩下的 20%( 100-(60+20)) 將不被使用。
這種拆分將重復(fù)我們必須指定的“n”次。

優(yōu)點(diǎn):
1.我們可以自由使用訓(xùn)練和驗(yàn)證集的大小;2.我們可以選擇重復(fù)的次數(shù),而不依賴于重復(fù)的折疊次數(shù)。
缺點(diǎn):
1. 可能不會(huì)為訓(xùn)練集或驗(yàn)證集選擇很少的樣本;2. 不適合不平衡的數(shù)據(jù)集:在我們定義了訓(xùn)練集和驗(yàn)證集的大小后,所有的樣本都是隨機(jī)選擇的,所以訓(xùn)練集可能沒(méi)有測(cè)試中的數(shù)據(jù)類別 設(shè)置,并且該模型將無(wú)法概括為看不見(jiàn)的數(shù)據(jù)。
代碼片段:
from sklearn.model_selection import ShuffleSplit,cross_val_scorefrom sklearn.datasets import load_irisfrom sklearn.linear_model import LogisticRegressionlogreg=LogisticRegression()shuffle_split=ShuffleSplit(test_size=0.3,train_size=0.5,n_splits=10)scores=cross_val_score(logreg,iris.data,iris.target,cv=shuffle_split)print("cross Validation scores:n {}".format(scores))print("Average?Cross?Validation?score?:{}".format(scores.mean()))

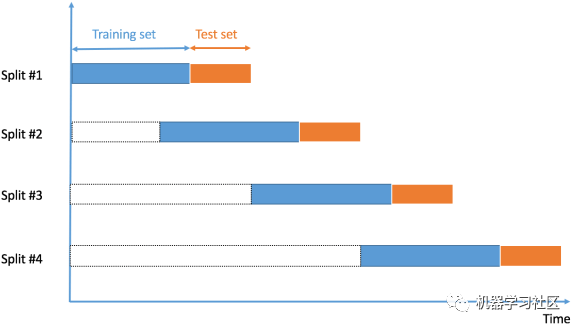
7、時(shí)間序列交叉驗(yàn)證
時(shí)間序列數(shù)據(jù)是在不同時(shí)間點(diǎn)收集的數(shù)據(jù)。由于數(shù)據(jù)點(diǎn)是在相鄰時(shí)間段收集的,因此觀測(cè)值之間可能存在相關(guān)性。這是區(qū)分時(shí)間序列數(shù)據(jù)與橫截面數(shù)據(jù)的特征之一。
在時(shí)間序列數(shù)據(jù)的情況下如何進(jìn)行交叉驗(yàn)證?
在時(shí)間序列數(shù)據(jù)的情況下,我們不能選擇隨機(jī)樣本并將它們分配給訓(xùn)練集或驗(yàn)證集,因?yàn)槭褂梦磥?lái)數(shù)據(jù)中的值來(lái)預(yù)測(cè)過(guò)去數(shù)據(jù)的值是沒(méi)有意義的。
由于數(shù)據(jù)的順序?qū)τ跁r(shí)間序列相關(guān)問(wèn)題非常重要,所以我們根據(jù)時(shí)間將數(shù)據(jù)拆分為訓(xùn)練集和驗(yàn)證集,也稱為“前向鏈”方法或滾動(dòng)交叉驗(yàn)證。
我們從一小部分?jǐn)?shù)據(jù)作為訓(xùn)練集開(kāi)始。基于該集合,我們預(yù)測(cè)稍后的數(shù)據(jù)點(diǎn),然后檢查準(zhǔn)確性。
然后將預(yù)測(cè)樣本作為下一個(gè)訓(xùn)練數(shù)據(jù)集的一部分包括在內(nèi),并對(duì)后續(xù)樣本進(jìn)行預(yù)測(cè)。
優(yōu)點(diǎn):
1. 最好的技術(shù)之一。
缺點(diǎn):
1. 不適用于其他數(shù)據(jù)類型的驗(yàn)證:與其他技術(shù)一樣,我們選擇隨機(jī)樣本作為訓(xùn)練或驗(yàn)證集,但在該技術(shù)中數(shù)據(jù)的順序非常重要。
代碼片段:
import numpy as npfrom sklearn.model_selection import TimeSeriesSplitX = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])y = np.array([1, 2, 3, 4, 5, 6])time_series = TimeSeriesSplit()print(time_series)for train_index, test_index in time_series.split(X):print("TRAIN:", train_index, "TEST:", test_index)X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]
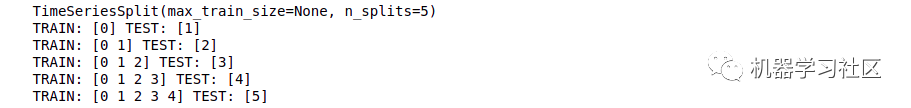
結(jié)論
編輯:黃繼彥
校對(duì):龔力
評(píng)論
圖片
表情