
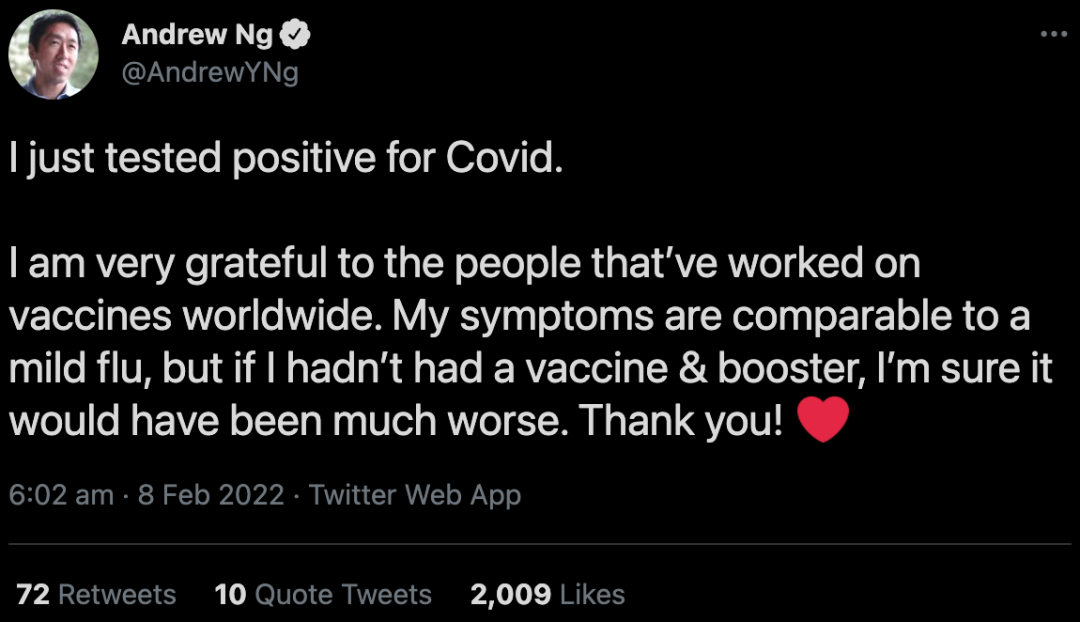
吳恩達,新冠陽性

?
?
吳恩達表示,由于自己已經接種了疫苗和加強針,目前的癥狀和與輕度的流感差不多。感謝全世界從事疫苗工作的人們。
大年初一的時候,他還發(fā)推祝大家虎年快樂。
?
還有不到 3 個月就要過 46 歲生日了,希望大佬好好休息,早日康復。
成就一覽
成就一覽
吳恩達無疑是當代人工智能和機器學習領域最權威的學者之一,同時在商業(yè)上也頗有建樹。
?
吳恩達是斯坦福大學計算機科學系和電氣工程系的客座教授,曾任斯坦福人工智能實驗室主任。
?
吳恩達的理想是讓世界上每個人能夠接受高質量的、免費的教育。于是便與達芙妮?科勒?(機器學習界的一姐和大牛,《Probabilistic Graphical Models: Principles and Techniques》的作者)一起創(chuàng)建了在線教育平臺 Coursera。
?

?
吳恩達于 1976 年出生于英國倫敦。他的父母都是來自香港的移民。在成長過程中,他在香港和新加坡度過了一段時間,后來于 1992 年從新加坡萊佛士書院畢業(yè)。
?
1997 年,他獲得了賓夕法尼亞州匹茲堡卡尼基美隆大學班級頂尖的計算機科學、統(tǒng)計學和經濟學三重專業(yè)大學學位。1996 年至 1998 年間,他在 AT&T 貝爾實驗室進行了強化學習,模型選擇和特征選擇的研究。
?
1998 年,吳恩達在馬薩諸塞州劍橋的麻省理工學院獲得碩士學位。在麻省理工學院,他為網絡上的研究論文建立了第一個公開可用,自動索引的網絡搜索引擎(它是 CiteSeer/ResearchIndex 的前身,但專注于機器學習)。
?

趣味哏圖:「當你看到以下片頭標時,就會知道影視產品很棒:20 世紀佛克斯、派拉蒙、華納兄弟、吳恩達微笑」
?
2011 年,吳恩達在谷歌創(chuàng)建了谷歌大腦項目,以通過分布式集群計算器開發(fā)超大規(guī)模的人工神經網絡。
?
2014 年 5 月 16 日,吳恩達加入百度,負責「百度大腦」計劃,并擔任百度公司首席科學家。2017 年 3 月 20 日,吳恩達宣布從百度辭職。
?
2017 年 12 月,吳恩達宣布成立人工智能公司 Landing.ai,擔任公司的首席執(zhí)行官。
?

趣味哏圖:「AI 的文藝形象是終結者,真實形象是吳恩達公開課」
?
作為教師,他保持一項紀錄:在 2013-1014 年斯坦福大學秋季學期的「機器學習」課程中,這門由吳恩達主講的課程有超過 800 名學生選修。這曾是斯坦福歷史上最多人同時選修的課程。
?
沒有任何教室可以容納,所以很多人都是在家看課堂錄像。不過這門計算機專業(yè)的研究生課程比 Coursera 上的同名公開課要難很多,用他自己的話來說就是 “這(和 Coursera 上的相比)可以說是兩門課”。
?

吳教授公開課金句:「聽不懂先不要怕」
?
他在斯坦福公開課與 Coursera 里主講機器學習,效果極佳,在業(yè)界和普羅大眾中都非常受歡迎。

趣味哏圖:「女友:你看泰坦尼克都不哭!難以置信!你究竟有沒有感情!你哭過沒有!AI 學子:有啊,吳恩達公開課結尾出手寫感謝字幕的時候。」
?
吳恩達在 Coursera 上的機器學習課程,平均得分 4.9 分。Coursera 上的課程評分滿分 5 分,大部分公開課處于 4-4.5 分之間,能做到 4.9 分的課程很少,而這門課程有近五萬人給出評分。按 Freecodecamp 的統(tǒng)計,這是機器學習在線課程中最受歡迎的一門。
?

?
吳恩達的公開課程中高數內容相對不多,在同類公開課中比較親善大眾。他解釋過原因:「這門課沒有使用過多數學的原因就是考慮到其受眾廣泛,因此用直覺式的解釋讓大家有信心繼續(xù)堅持學習。」
?

趣味哏圖:「吳恩達公開課,默默為 AI 新丁擋下了微積分、線代、統(tǒng)計、概率論這些高數火力,讓學子們得以安眠。」
?
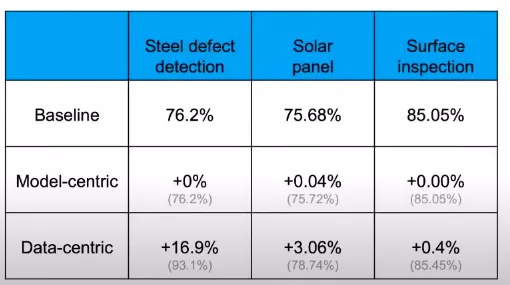
80% 的數據 + 20% 的模型 = 更好的機器學習
80% 的數據 + 20% 的模型 = 更好的機器學習
機器學習的進步是模型帶來的還是數據帶來的,這可能是一個世紀辯題。
?
吳恩達對此的想法是,一個機器學習團隊 80% 的工作應該放在數據準備上,確保數據質量是最重要的工作。
?
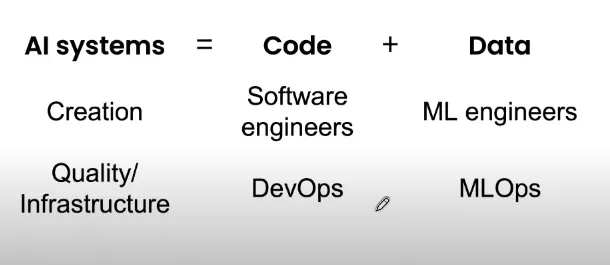
「AI = Data + Code」
?
?
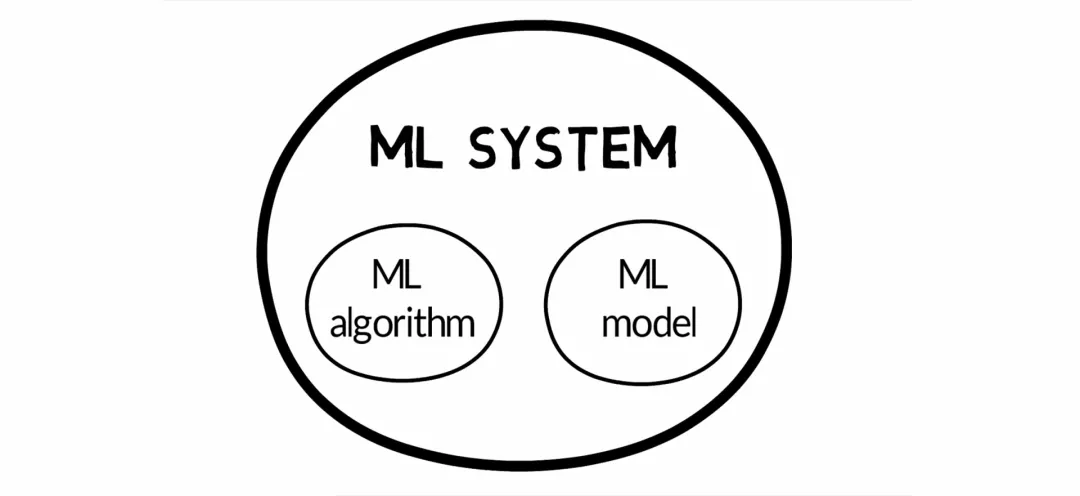
出現問題時,大部分團隊會本能地嘗試改進代碼。但是對于許多實際應用而言,集中精力改善數據會更有效。
?
吳恩達認為,如果更多地強調以數據為中心而不是以模型為中心,那么機器學習將快速發(fā)展。
?
?
我們都知道 Google 的 BERT,OpenAI 的 GPT-3。但是,這些神奇的模型僅解決了業(yè)務問題的 20%。而剩下 80% 就是數據的質量。
?
?
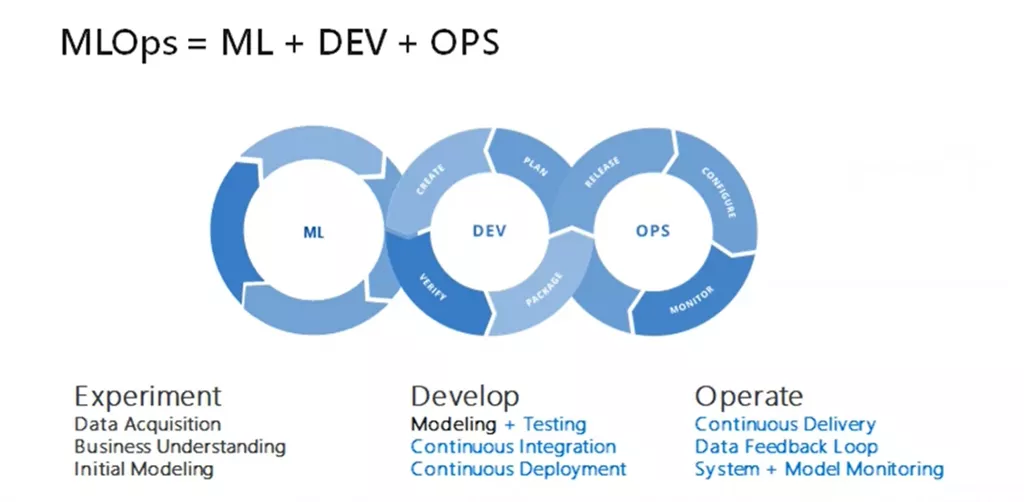
MLOps 是什么?
MLOps 是什么?
?
MLOps,即 Machine Learning 和 Operations 的組合,是 ModelOps 的子集。
?
它是數據科學家與操作專業(yè)人員之間進行協(xié)作和交流以幫助管理機器學習任務生命周期的一種實踐。
?
?
與 DevOps 或 DataOps 方法類似,MLOps 希望提高自動化程度并提高生產 ML 的質量,同時還要關注業(yè)務和法規(guī)要求。
?
比如在缺少數據的應用場景中進行部署 AI 時,例如農業(yè)場景,你不能指望自己有一百萬臺拖拉機為自己收集數據。
?
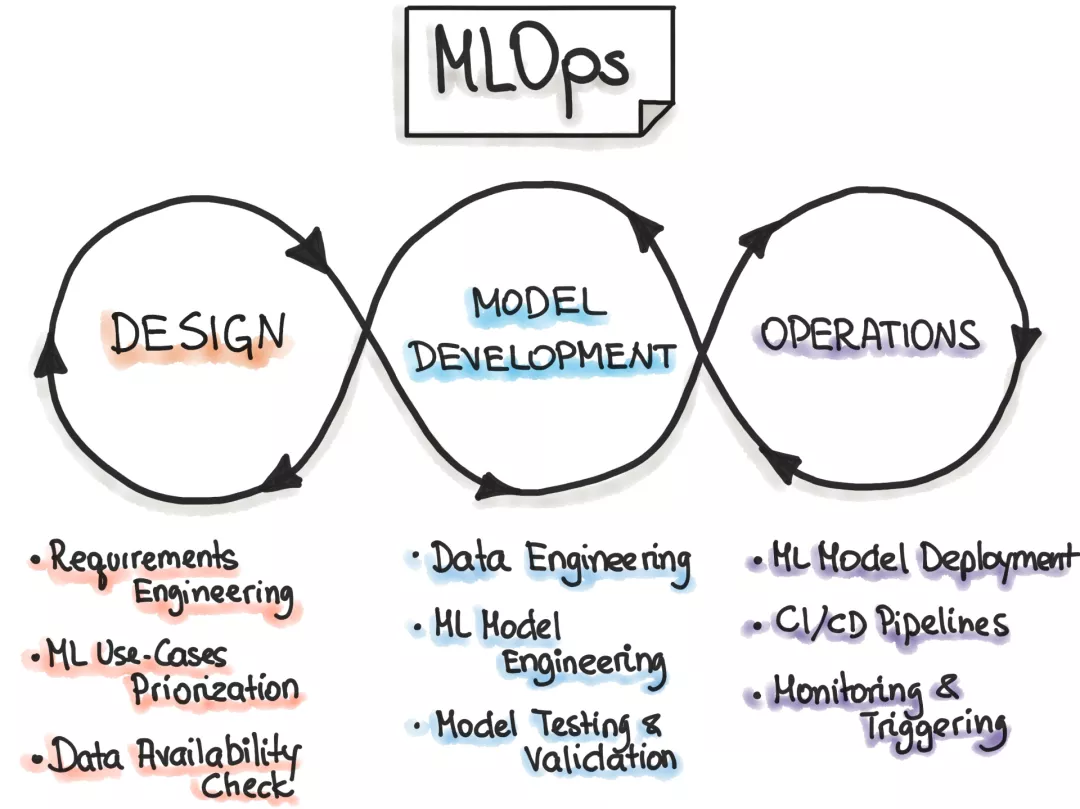
基于 MLOps,吳恩達也提出幾點建議:
?
MLOps 的最重要任務是提供高質量數據。 標簽的一致性也很重要。檢驗標簽是否有自己所管轄的明確界限,即使標簽的定義是好的,缺乏一致性也會導致模型效果不佳。 系統(tǒng)地改善 baseline 模型上的數據質量要比追求具有低質量數據的最新模型要好。 如果訓練期間出現錯誤,那么應當采取以數據為中心的方法。 如果以數據為中心,對于較小的數據集(<10,000 個樣本),則數據容量上存在很大的改進空間。 當使用較小的數據集時,提高數據質量的工具和服務至關重要。
參考資料:
https://twitter.com/AndrewYNg/status/1490808144267673601
