
解決 K8s 調(diào)度不均衡問題
關(guān)注")
前言
在近期的工作中,我們發(fā)現(xiàn) K8s 集群中有些節(jié)點資源使用率很高,有些節(jié)點資源使用率很低,我們嘗試重新部署應(yīng)用和驅(qū)逐 Pod,發(fā)現(xiàn)并不能有效解決負(fù)載不均衡問題。在學(xué)習(xí)了 Kubernetes 調(diào)度原理之后,重新調(diào)整了 Request 配置,引入了調(diào)度插件,才最終解決問題。這篇就來跟大家分享 Kubernetes 資源和調(diào)度相關(guān)知識,以及如何解決 K8s 調(diào)度不均衡問題。
Kubernetes 的資源模型
在 Kubernetes 里,Pod 是最小的原子調(diào)度單位。這也就意味著,所有跟調(diào)度和資源管理相關(guān)的屬性都應(yīng)該是屬于 Pod 對象的字段。而這其中最重要的部分,就是 Pod 的 CPU 和內(nèi)存配置。像 CPU 這樣的資源被稱作“可壓縮資源”(compressible resources)。它的典型特點是,當(dāng)可壓縮資源不足時,Pod 只會“饑餓”,但不會退出。而像內(nèi)存這樣的資源,則被稱作“不可壓縮資源(incompressible resources)。當(dāng)不可壓縮資源不足時,Pod 就會因為 OOM(Out-Of-Memory)被內(nèi)核殺掉。Pod 可以由多個 Container 組成,所以 CPU 和內(nèi)存資源的限額,是要配置在每個 Container 的定義上的。這樣,Pod 整體的資源配置,就由這些 Container 的配置值累加得到。Kubernetes 里 Pod 的 CPU 和內(nèi)存資源,實際上還要分為 limits 和 requests 兩種情況:
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
這兩者的區(qū)別其實非常簡單:在調(diào)度的時候,kube-scheduler 只會按照 requests 的值進(jìn)行調(diào)度。而在真正設(shè)置 Cgroups 限制的時候,kubelet 則會按照 limits 的值來進(jìn)行設(shè)置。這是因為在實際場景中,大多數(shù)作業(yè)使用到的資源其實遠(yuǎn)小于它所請求的資源限額,這種策略能有效的提高整體資源的利用率。
Kubernetes 的服務(wù)質(zhì)量
服務(wù)質(zhì)量 QoS 的英文全稱為 Quality of Service。在 Kubernetes 中,每個 Pod 都有個 QoS 標(biāo)記,通過這個 Qos 標(biāo)記來對 Pod 進(jìn)行服務(wù)質(zhì)量管理,它確定 Pod 的調(diào)度和驅(qū)逐優(yōu)先級。在 Kubernetes 中,Pod 的 QoS 服務(wù)質(zhì)量一共有三個級別:
Guaranteed:當(dāng) Pod 里的每一個 Container 都同時設(shè)置了 requests 和 limits,并且 requests 和 limits 值相等的時候,這個 Pod 就屬于 Guaranteed 類別 。 Burstable:而當(dāng) Pod 不滿足 Guaranteed 的條件,但至少有一個 Container 設(shè)置了 requests。那么這個 Pod 就會被劃分到 Burstable 類別。 BestEffort:而如果一個 Pod 既沒有設(shè)置 requests,也沒有設(shè)置 limits,那么它的 QoS 類別就是 BestEffort。
具體地說,當(dāng) Kubernetes 所管理的宿主機上不可壓縮資源短缺時,就有可能觸發(fā) Eviction 驅(qū)逐。目前,Kubernetes 為你設(shè)置的 Eviction 的默認(rèn)閾值如下所示:
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
當(dāng)宿主機的 Eviction 閾值達(dá)到后,就會進(jìn)入 MemoryPressure 或者 DiskPressure 狀態(tài),從而避免新的 Pod 被調(diào)度到這臺宿主機上,然后 kubelet 會根據(jù) QoS 的級別來挑選 Pod 進(jìn)行驅(qū)逐,具體驅(qū)逐優(yōu)先級是:BestEffort -> Burstable -> Guaranteed。QoS 的級別是通過 Linux 內(nèi)核 OOM 分?jǐn)?shù)值來實現(xiàn)的,OOM 分?jǐn)?shù)值取值范圍在-1000 ~1000 之間。在 Kubernetes 中,常用服務(wù)的 OOM 的分值如下:
-1000 => sshd等進(jìn)程
-999 => Kubernetes 管理進(jìn)程
-998 => Guaranteed Pod
0 => 其他進(jìn)程 0
2~999 => Burstable Pod
1000 => BestEffort Pod
OOM 分?jǐn)?shù)越高,就代表這個 Pod 的優(yōu)先級越低,在出現(xiàn)資源競爭的時候,就越早被殺掉,分?jǐn)?shù)為-999 和-1000 的進(jìn)程永遠(yuǎn)不會因為 OOM 而被殺掉。
?劃重點:如果期望 Pod 盡可能的不被驅(qū)逐,就應(yīng)當(dāng)把 Pod 里的每一個 Container 的 requests 和 limits 都設(shè)置齊全,并且 requests 和 limits 值要相等。
Kubernetes 的調(diào)度策略
kube-scheduler 是 Kubernetes 集群的默認(rèn)調(diào)度器,它的主要職責(zé)是為一個新創(chuàng)建出來的 Pod,尋找一個最合適的 Node。kube-scheduler 給一個 Pod 做調(diào)度選擇包含三個步驟:
過濾:調(diào)用一組叫作 Predicate 的調(diào)度算法,將所有滿足 Pod 調(diào)度需求的 Node 選出來; 打分:調(diào)用一組叫作 Priority 的調(diào)度算法,給每一個可調(diào)度 Node 進(jìn)行打分; 綁定:調(diào)度器將 Pod 對象的 nodeName 字段的值,修改為得分最高的 Node。
?Kubernetes 官方過濾和打分編排源碼:https://github.com/kubernetes/kubernetes/blob/281023790fd27eec7bfaa7e26ff1efd45a95fb09/pkg/scheduler/framework/plugins/legacy_registry.go
過濾(Predicate)
過濾階段,首先遍歷全部節(jié)點,過濾掉不滿足條件的節(jié)點,屬于強制性規(guī)則,這一階段輸出的所有滿足要求的 Node 將被記錄并作為第二階段的輸入,如果所有的節(jié)點都不滿足條件,那么 Pod 將會一直處于 Pending 狀態(tài),直到有節(jié)點滿足條件,在這期間調(diào)度器會不斷的重試。調(diào)度器會根據(jù)限制條件和復(fù)雜性依次進(jìn)行以下過濾檢查,檢查順序存儲在一個名為 PredicateOrdering() 的函數(shù)中,具體如下表格:
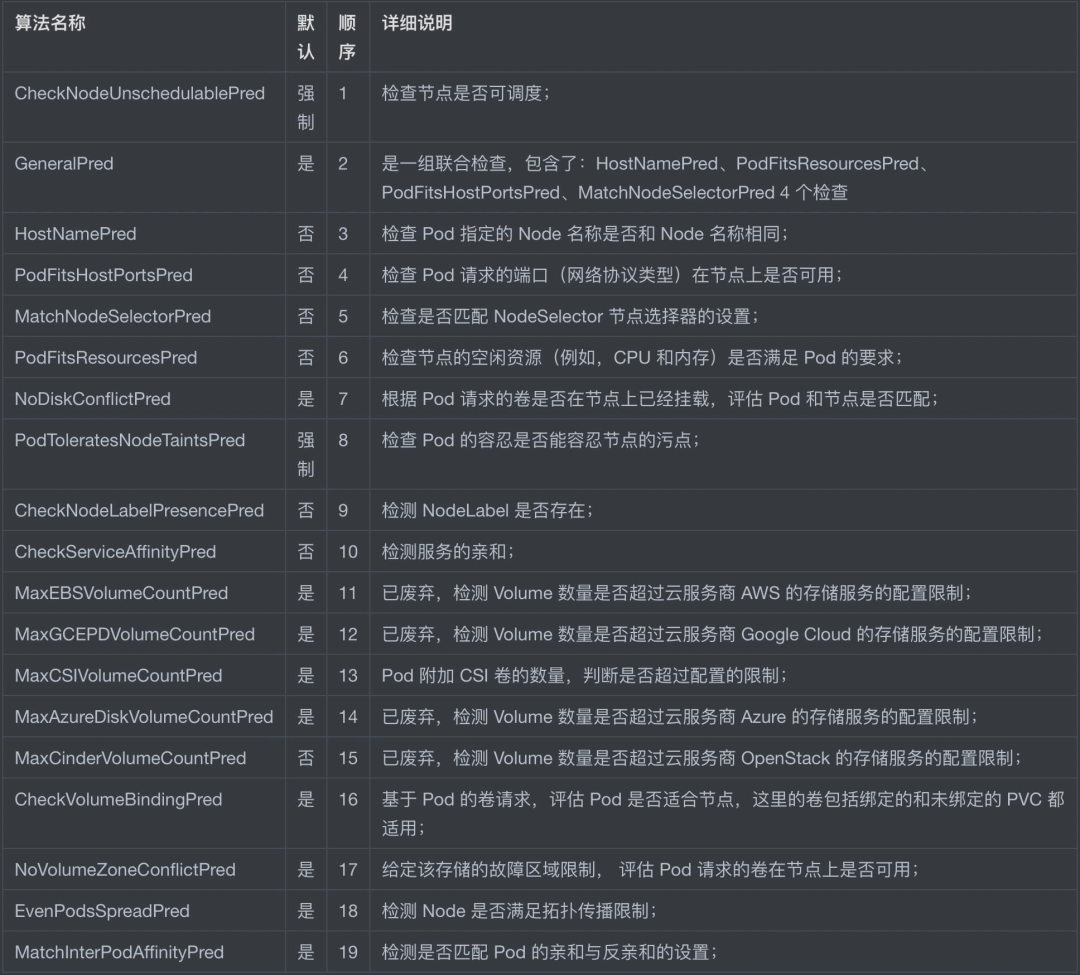
可以看出,Kubernetes 正在逐步移除某個具體云服務(wù)商的服務(wù)的相關(guān)代碼,而使用接口(Interface)來擴展功能。
打分(Priority)
打分階段,通過 Priority 策略對可用節(jié)點進(jìn)行評分,最終選出最優(yōu)節(jié)點。具體是用一組打分函數(shù)處理每一個可用節(jié)點,每一個打分函數(shù)會返回一個 0~100 的分?jǐn)?shù),分?jǐn)?shù)越高表示節(jié)點越優(yōu), 同時每一個函數(shù)也會對應(yīng)一個權(quán)重值。將每個打分函數(shù)的計算得分乘以權(quán)重,然后再將所有打分函數(shù)的得分相加,從而得出節(jié)點的最終優(yōu)先級分值。權(quán)重可以讓管理員定義優(yōu)選函數(shù)傾向性的能力,其計算優(yōu)先級的得分公式如下:
finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + … + (weightn * priorityFuncn)
全部打分函數(shù)如下表格所示:
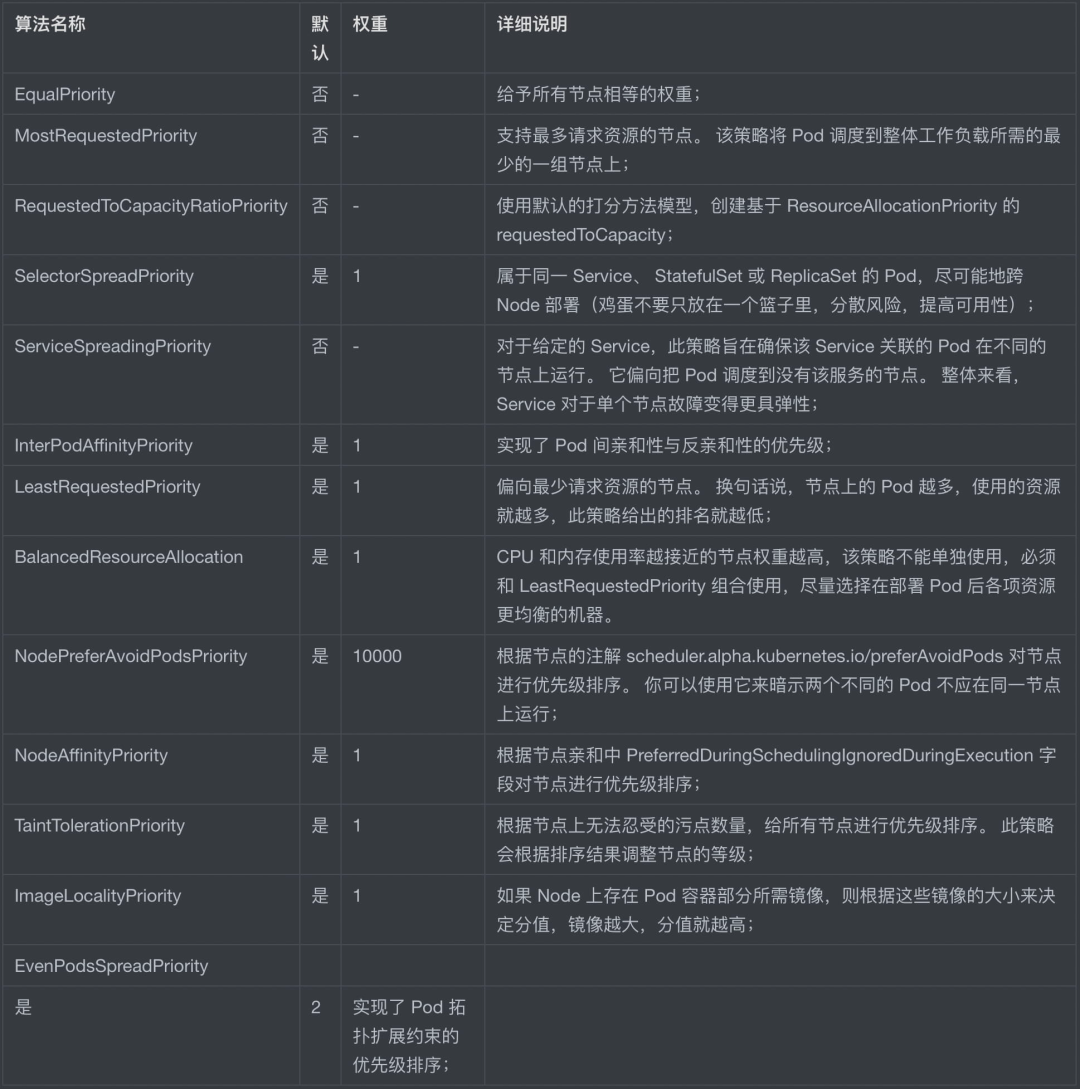
我自己遇到的是“多節(jié)點調(diào)度資源不均衡問題”,所以跟節(jié)點資源相關(guān)的打分算法是我關(guān)注的重點。1、BalancedResourceAllocation(默認(rèn)開啟),它的計算公式如下所示:
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
其中,每種資源的 Fraction 的定義是 :Pod 的 request 資源 / 節(jié)點上的可用資源。而 variance 算法的作用,則是計算每兩種資源 Fraction 之間的“距離”。而最后選擇的,則是資源 Fraction 差距最小的節(jié)點。所以說,BalancedResourceAllocation 選擇的,其實是調(diào)度完成后,所有節(jié)點里各種資源分配最均衡的那個節(jié)點,從而避免一個節(jié)點上 CPU 被大量分配、而 Memory 大量剩余的情況。2、LeastRequestedPriority(默認(rèn)開啟),它的計算公式如下所示:
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
可以看到,這個算法實際上是根據(jù) request 來計算出空閑資源(CPU 和 Memory)最多的宿主機。3、MostRequestedPriority(默認(rèn)不開啟),它的計算公式如下所示:
score = (cpu(10 sum(requested) / capacity) + memory(10 sum(requested) / capacity)) / 2
在 ClusterAutoscalerProvider 中替換 LeastRequestedPriority,給使用多資源的節(jié)點更高的優(yōu)先級。
?你可以修改 /etc/kubernetes/manifests/kube-scheduler.yaml 配置,新增 v=10 參數(shù)來開啟調(diào)度打分日志。
自定義配置
如果官方默認(rèn)的過濾和打分策略,無法滿足實際業(yè)務(wù),我們可以自定義配置:
調(diào)度策略:允許你修改默認(rèn)的過濾 斷言 (Predicates) 和打分 優(yōu)先級 (Priorities) 。 調(diào)度配置:允許你實現(xiàn)不同調(diào)度階段的插件, 包括:QueueSort, Filter, Score, Bind, Reserve, Permit 等等。你也可以配置 kube-scheduler 運行不同的配置文件。
解決 K8s 調(diào)度不均衡問題
一、按實際用量配置 Pod 的 requeste
從上面的調(diào)度策略可以得知,資源相關(guān)的打分算法 LeastRequestedPriority 和 MostRequestedPriority 都是基于 request 來進(jìn)行評分,而不是按 Node 當(dāng)前資源水位進(jìn)行調(diào)度(在沒有安裝 Prometheus 等資源監(jiān)控相關(guān)組件之前,kube-scheduler 也無法實時統(tǒng)計 Node 當(dāng)前的資源情況),所以可以動態(tài)采 Pod 過去一段時間的資源使用率,據(jù)此來設(shè)置 Pod 的 Request,才能契合 kube-scheduler 默認(rèn)打分算法,讓 Pod 的調(diào)度更均衡。
二、為資源占用較高的 Pod 設(shè)置反親和
對一些資源使用率較高的 Pod ,進(jìn)行反親和,防止這些項目同時調(diào)度到同一個 Node,導(dǎo)致 Node 負(fù)載激增。
三、引入實時資源打分插件 Trimaran
但在實際項目中,并不是所有情況都能較為準(zhǔn)確的估算出 Pod 資源用量,所以依賴 request 配置來保障 Pod 調(diào)度的均衡性是不準(zhǔn)確的。那有沒有一種通過 Node 當(dāng)前實時資源進(jìn)行打分調(diào)度的方案呢?Kubernetes 官方社區(qū) SIG 小組提供的調(diào)度插件 Trimaran[1] 就具備這樣的能力。
?Trimaran 官網(wǎng)地址:https://github.com/kubernetes-sigs/scheduler-plugins/tree/master/pkg/trimaran
Trimaran 是一個實時負(fù)載感知調(diào)度插件,它利用 load-watcher 獲取程序資源利用率數(shù)據(jù)。目前,load-watcher 支持三種度量工具:Metrics Server、Prometheus 和 SignalFx。
Kubernetes Metrics Server:是 kubernetes 監(jiān)控體系中的核心組件之一,它負(fù)責(zé)從 kubelet 收集資源指標(biāo),然后對這些指標(biāo)監(jiān)控數(shù)據(jù)進(jìn)行聚合 (依賴 kube-aggregator),并在 Kubernetes Apiserver 中通過 Metrics API( /apis/metrics.k8s.io/) 公開暴露它們; Prometheus Server:是一款基于時序數(shù)據(jù)庫的開源監(jiān)控告警系統(tǒng),非常適合 Kubernetes 集群的監(jiān)控。基本原理是通過 Http 協(xié)議周期性抓取被監(jiān)控組件的狀態(tài),任意組件只要提供對應(yīng)的 Http 接口就可以接入監(jiān)控。不需要任何 SDK 或者其他的集成過程。這樣做非常適合做虛擬化環(huán)境監(jiān)控系統(tǒng),比如 VM、Docker、Kubernetes 等。 SignalFx:是一家基礎(chǔ)設(shè)施及應(yīng)用實時云監(jiān)控服務(wù)商,它采用了一個低延遲、可擴展的流式分析引擎,以監(jiān)視微服務(wù)(松散耦合、獨立部署的應(yīng)用組件集合)和協(xié)調(diào)的容器環(huán)境(如 Kubernetes 和 Docker)。官網(wǎng)地址:https://www.splunk.com/en_us/investor-relations/acquisitions/signalfx.html
Trimaran 的架構(gòu)如下: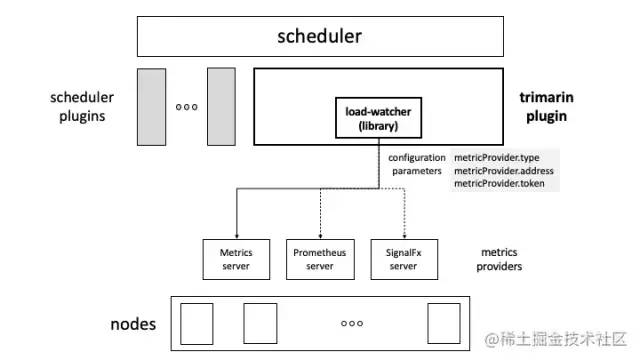 可以看到在 kube-scheduler 打分的過程中,Trimaran 會通過 load-watcher 獲取當(dāng)前 node 的實時資源水位,然后據(jù)此打分從而干預(yù)調(diào)度結(jié)果。
可以看到在 kube-scheduler 打分的過程中,Trimaran 會通過 load-watcher 獲取當(dāng)前 node 的實時資源水位,然后據(jù)此打分從而干預(yù)調(diào)度結(jié)果。
?Trimaran 打分原理:https://github.com/kubernetes-sigs/scheduler-plugins/tree/master/kep/61-Trimaran-real-load-aware-scheduling
四、引入重平衡工具 descheduler
從 kube-scheduler 的角度來看,調(diào)度程序會根據(jù)其當(dāng)時對 Kubernetes 集群的資源描述做出最佳調(diào)度決定,但調(diào)度是靜態(tài)的,Pod 一旦被綁定了節(jié)點是不會觸發(fā)重新調(diào)度的。雖然打分插件可以有效的解決調(diào)度時的資源不均衡問題,但每個 Pod 在長期的運行中所占用的資源也是會有變化的(通常內(nèi)存會增加)。假如一個應(yīng)用在啟動的時候只占 2G 內(nèi)存,但運行一段時間之后就會占用 4G 內(nèi)存,如果這樣的應(yīng)用比較多的話,Kubernetes 集群在運行一段時間后就可能會出現(xiàn)不均衡的狀態(tài),所以需要重新平衡集群。除此之外,也還有一些其他的場景需要重平衡:
集群添加新節(jié)點,一些節(jié)點不足或過度使用; 某些節(jié)點發(fā)生故障,其 pod 已移至其他節(jié)點; 原始調(diào)度決策不再適用,因為在節(jié)點中添加或刪除了污點或標(biāo)簽,不再滿足 pod/node 親和性要求。
當(dāng)然我們可以去手動做一些集群的平衡,比如手動去刪掉某些 Pod,觸發(fā)重新調(diào)度就可以了,但是顯然這是一個繁瑣的過程,也不是解決問題的方式。為了解決實際運行中集群資源無法充分利用或浪費的問題,可以使用 descheduler 組件對集群的 Pod 進(jìn)行調(diào)度優(yōu)化,descheduler 可以根據(jù)一些規(guī)則和配置策略來幫助我們重新平衡集群狀態(tài),其核心原理是根據(jù)其策略配置找到可以被移除的 Pod 并驅(qū)逐它們,其本身并不會進(jìn)行調(diào)度被驅(qū)逐的 Pod,而是依靠默認(rèn)的調(diào)度器來實現(xiàn),descheduler 重平衡原理可參見官網(wǎng)。
?descheduler 官網(wǎng)地址:https://github.com/kubernetes-sigs/descheduler
參考資料
kubernetes 官網(wǎng)[2] 極客時間《深入剖析 Kubernetes》專欄(40~44 章節(jié)) k8s 調(diào)度不均勻問題解決[3] 最全的 K8s 調(diào)度策略[4] K8s 之 QoS[5] 當(dāng)一個 Pod 被調(diào)度時,k8s 內(nèi)部發(fā)生了什么?[6] K8s 學(xué)習(xí)筆記-調(diào)度介紹[7] Kubernetes 調(diào)度均衡器 Descheduler 使用[8]
引用鏈接
Trimaran: https://github.com/kubernetes-sigs/scheduler-plugins/blob/master/pkg/trimaran/README.md
[2]kubernetes 官網(wǎng): https://kubernetes.io/zh-cn/
[3]k8s 調(diào)度不均勻問題解決: https://blog.csdn.net/trntaken/article/details/122377896
[4]最全的 K8s 調(diào)度策略: https://cloud.tencent.com/developer/article/1644857
[5]K8s 之 QoS: https://blog.csdn.net/zenglingmin8/article/details/121152679
[6]當(dāng)一個 Pod 被調(diào)度時,k8s 內(nèi)部發(fā)生了什么?: https://www.bbsmax.com/A/n2d9Neo0zD/
[7]K8s 學(xué)習(xí)筆記-調(diào)度介紹: https://www.cnblogs.com/centos-python/articles/10884738.html
[8]Kubernetes 調(diào)度均衡器 Descheduler 使用: https://zhuanlan.zhihu.com/p/475102379


你可能還喜歡
點擊下方圖片即可閱讀
2022-06-23

2022-06-20

2022-06-19
2022-06-18


云原生是一種信仰 ??
關(guān)注公眾號
后臺回復(fù)?k8s?獲取史上最方便快捷的 Kubernetes 高可用部署工具,只需一條命令,連 ssh 都不需要!


點擊 "閱讀原文" 獲取更好的閱讀體驗!
發(fā)現(xiàn)朋友圈變“安靜”了嗎?
