
百余大佬署名AI論文被爆抄襲!智源現(xiàn)已致歉
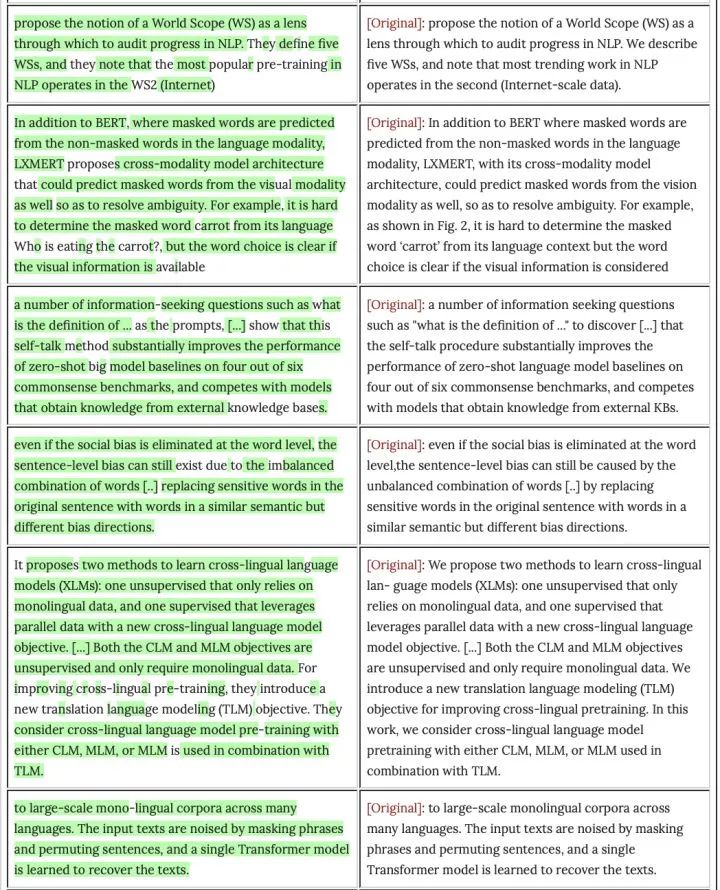
Google Brain研究員Nicholas Carlini近日在一篇博客中指出智源、清華等單位的論文A Roadmap for Big Model中部分段落抄襲了他們的論文Deduplicating Training Data Makes Language Models Better。同時他指出,A Roadmap for Big Model可能同時抄襲了十余篇其他論文。Nicholas Carlini展示了一些抄襲Deduplicating Training Data Makes Language Models Better的片段,抄襲部分用綠色高亮。
北京智源人工智能研究院回答:
關(guān)于“A Roadmap for Big Model”綜述報告問題的致歉信
今天我們從互聯(lián)網(wǎng)上獲悉,智源研究院在預(yù)印本網(wǎng)站arXiv發(fā)布的綜述報告“A Roadmap for Big Model”(大模型路線圖)涉嫌抄襲。對這一情況,研究院立即組織內(nèi)部調(diào)查,確認部分文章存在問題后,已啟動邀請第三方專家開展獨立審查,并進行相關(guān)追責。
對于這一問題的發(fā)生,我們深感愧疚。智源研究院作為一家科研機構(gòu),高度重視學(xué)術(shù)規(guī)范,鼓勵學(xué)術(shù)創(chuàng)新和學(xué)術(shù)交流,對學(xué)術(shù)不端零容忍。在此,我們向相關(guān)原文作者和學(xué)術(shù)界、產(chǎn)業(yè)界的同仁和朋友表示誠摯的道歉。
智源研究院內(nèi)部調(diào)查的初步結(jié)果如下:
1. ? 該報告是一篇大模型領(lǐng)域的綜述,希望盡可能涵蓋國內(nèi)外該領(lǐng)域的所有重要文獻,由智源研究院牽頭,負責框架設(shè)計和稿件匯總,并邀請國內(nèi)外100位科研人員分別撰寫了16篇獨立的專題文章,每篇文章分別邀請了一組作者撰寫并單獨署名,共200頁。報告發(fā)布后,根據(jù)反饋持續(xù)進行修改完善,到4月2日在arXiv網(wǎng)站上已經(jīng)更新到第三版。
2. ? 4月13日,我們獲悉谷歌研究員Nicholas ?Carlini在個人博客上指出該報告抄襲了他們論文的數(shù)個段落,同時還有其他段落和語句抄襲其他論文。我們對此進行了逐項核查,經(jīng)查重確認第2篇文章的第3.1節(jié)179個詞,第8篇文章的第3.1節(jié)74個詞、第12篇文章的第2.3節(jié)55個詞、第14篇文章的第2節(jié)159個詞、第16篇文章的第1節(jié)146個詞與其他論文重復(fù),應(yīng)屬抄襲。我們決定立即從報告中刪除相應(yīng)內(nèi)容,報告修訂版今天將提交arXiv進行更新。目前已通知所有文章的作者對所有內(nèi)容進行全面審查,后續(xù)經(jīng)嚴格審核后再發(fā)布新版本。
3. ?智源作為該報告的組織者,理應(yīng)對各篇文章的所有內(nèi)容進行嚴格審核,出現(xiàn)這樣的問題難辭其咎。對此我們深感自責,特別感謝學(xué)術(shù)界和媒體的朋友們幫助我們發(fā)現(xiàn)問題。我們將深刻吸取教訓(xùn),整改科研管理和論文發(fā)表流程,希望各界朋友監(jiān)督我們工作。
下一步,智源研究院將以此為戒,采取切實措施,加強科研誠信與學(xué)風建設(shè):
(一)即日啟動邀請第三方專家對報告進行獨立審查,根據(jù)正式調(diào)查結(jié)果對相關(guān)責任人作出問責處理。
(二)進一步完善制度管理,通過更加嚴格的審核機制和更加明確的懲戒措施,對研究院內(nèi)部以及支持的科研人員加強學(xué)風教育,防范同類事件的再次發(fā)生。
歡迎各界朋友今后持續(xù)嚴格地監(jiān)督我們的工作,并對我們工作中可能存在的疏漏和不足加以批評和指正。

謝圜不是真名(倫敦瑪麗皇后大學(xué)?音樂人工智能博士在讀)回答:
Update 2:人在歐洲時區(qū),一覺醒來知乎消息已經(jīng)炸了。我身處在AI圈子里,作者列表里有一些人是我尊敬和熟悉的老師,我也follow過智源發(fā)表的不少工作。平心而論,智源里面的很多老師都是對AI學(xué)界有著推動的中堅力量,我也發(fā)自內(nèi)心地相信他們有極高的學(xué)術(shù)操守。因此,我這篇回答的初衷并不是指責和詆毀智源社區(qū)的老師們;對我來說,這也是端正我個人學(xué)術(shù)態(tài)度的又一個警示。
智源的最新回應(yīng)如下,態(tài)度其實已經(jīng)很好了。
看到原作者Nicholas Carlini更新了一段評論:
[Update 4/12: This article has received a lot more attention than I expected. (Context: every hour more people visit this page than viewed my entire website last week.) So a plea: let's not turn this into a witch hunt. I've seen some people say things like this should result in immediate dismissal of all those involved / people should be banned from arXiv / etc. I don't pretend to know the situation that resulted in this paper having copied from so many sources. Without knowing what happened behind the scenes, I'd like to refrain passing judgement. Maybe some junior authors meant well and thought that a citation was enough to then copy text. Maybe there was pressure from above that made some students feel like their only choice to deliver on time was to cut corners. For the part of the senior authors, they may have read over the text and thought that it looked perfectly reasonable and only made a few tweaks to the text here and there without being aware of where it came from. The point is we don't know. With 100 authors on this paper anything could have happened.
[4月12日更新:這篇文章受到的關(guān)注比我預(yù)期的多得多。(背景:每小時訪問這個網(wǎng)頁的人比上周瀏覽我整個網(wǎng)站的人還多)。所以懇請大家:不要把這變成一場獵巫行動。我看到一些人說,像這樣的事情應(yīng)該導(dǎo)致所有相關(guān)人員立即被解雇/人們應(yīng)該被禁止進入arXiv/等等。我并不假裝知道導(dǎo)致這篇論文從這么多來源抄襲的情況。在不知道幕后發(fā)生了什么的情況下,我不想做出判斷。也許一些初級作者本意是好的,認為有了引文就可以復(fù)制文字了。也許上面有壓力,讓一些學(xué)生覺得要按時交稿,唯一的選擇就是偷工減料。對于資深作者來說,他們可能讀了一遍文本,認為它看起來非常合理,只是在這里和那里對文本做了一些調(diào)整,而沒有意識到它的來源。關(guān)鍵是我們不知道。這篇論文有100位作者,任何事情都有可能發(fā)生。
My hope with this post was just to draw some attention to something that I've seen happen not infrequently. For example, roughly 1% of published-and-accepted papers have a higher data-copying-fraction than this paper. I should have given this context when I wrote this post initially. So, again, please let's not come down to harshly on this paper in particular. This is a problem I've noticed with the field in general, this case was just the tipping point for me because it was a paper of mine where this happened. Hopefully we can treat this as a learning experience to improve the field as a whole. With that out of the way, back to your regularly scheduled programming...]
我發(fā)這個帖子的目的只是想讓大家注意一些我見過的不常發(fā)生的事情。例如,大約有1%的已發(fā)表和接受的論文的數(shù)據(jù)復(fù)制率比這篇論文高。我應(yīng)該在最初寫這篇文章的時候給出這個背景。所以,請大家不要對這篇論文過于苛責。這是我注意到的這個領(lǐng)域的普遍問題,這個案例對我來說只是一個轉(zhuǎn)折點,因為這是我的一篇論文發(fā)生的情況。希望我們能把這當作一個學(xué)習(xí)的經(jīng)驗,以改善整個領(lǐng)域的情況。話不多說,回到你們正常的安排上來。]
我統(tǒng)計了一下原文提及的涉嫌抄襲段落出現(xiàn)的地方:2.3.1,2.4.3,8.3.1,10.2,12.2.3,14.2.2……
我震驚地發(fā)現(xiàn),這不是某一處集中出現(xiàn)了抄襲嫌疑,跨度這么大的涉嫌抄襲行為,絕對不止涉及個別作者!
現(xiàn)在推特的相關(guān)討論讓人真心感慨……ViT作者Lucas Beyer毫不留情地說,“我也不確定我會相信一個剽竊團體的聲明;在約130pg的內(nèi)容中,有10個抄襲的區(qū)塊,來自約100個作者。”
如果這類綜述大文章是分工完成的,那可想而知,這個學(xué)術(shù)環(huán)境和學(xué)術(shù)嚴謹性令人頭皮發(fā)麻;
如果這篇文章是一個團隊學(xué)生的結(jié)果,最后卻掛上了不同團隊的名字(是的,我曾見過這樣的文章,而且是一個更可能的解釋),那不過是從一類學(xué)術(shù)不端跳到另一類學(xué)術(shù)不端罷了。
學(xué)術(shù)聲譽的建立是一輩子的事情,然而要推倒只需要一瞬間。
之前一些學(xué)術(shù)不端的工作中,其實有很多大佬討論過關(guān)于論文署名的問題。原則上來說,一篇文章的所有署名人員必須:
(1)對研究工作的思路或設(shè)計有重要貢獻,或者為研究獲取、分析或解釋數(shù)據(jù);
(2)起草研究論文或者在重要的智力性內(nèi)容上對論文進行修改;
(3)對將要發(fā)表的版本作最終定稿;
(4)同意對研究工作的各個方面承擔責任以確保與論文任何部分的準確性或誠信有關(guān)的問題得到恰當?shù)恼{(diào)查和解決。
也就是說,涉及到學(xué)術(shù)不端的論文,其所有署名的作者都負有責任(這類分工式的綜述類大文章可能比較特別,但每章的那些作者是跑不了的)。一開始輕飄飄把名字掛上,后面把自己的責任摘出去的回應(yīng)是不被允許的。
講道理,100多個名字的論文就很離譜。看看這篇文章:

雖然我也見過共同一作很多的文章,但……快一半的人都是共同一作,還有1/4的人是共同通訊,我真的是第一次見到。可能這就是大模型需要的大社群吧。
現(xiàn)在這篇文章因為這樣可悲的錯誤,被Google Brain的研究員一通捶,而且arxiv的頁面下面已經(jīng)添加了文字重合的警示,想必這篇文章在純學(xué)術(shù)上的影響力會跌得很嚴重(畢竟大家都希望引用更具代表性的原創(chuàng)工作),失去了這篇文章本來應(yīng)有的地位和意義。
學(xué)術(shù)聲譽對于一家學(xué)術(shù)機構(gòu)來說還是很重要的。預(yù)測一下智源后面的反映:
在arxiv上撤稿,后續(xù)找時間重新提交修改后的版本。(概率幾乎100%)
機構(gòu)公開道歉。(概率10%)
一些作者以個人身份道歉。(概率80%)
然后當這事沒發(fā)生過。(概率90%)
推特討論節(jié)選:
滑鐵盧大學(xué)教授:即使這篇多作者的論文有分工,我對沒有一個人注意到并采取措施糾正這一點感到吃驚。

ViT作者:他們大概會推一個作者出來背鍋。(臨時工再顯神威?)
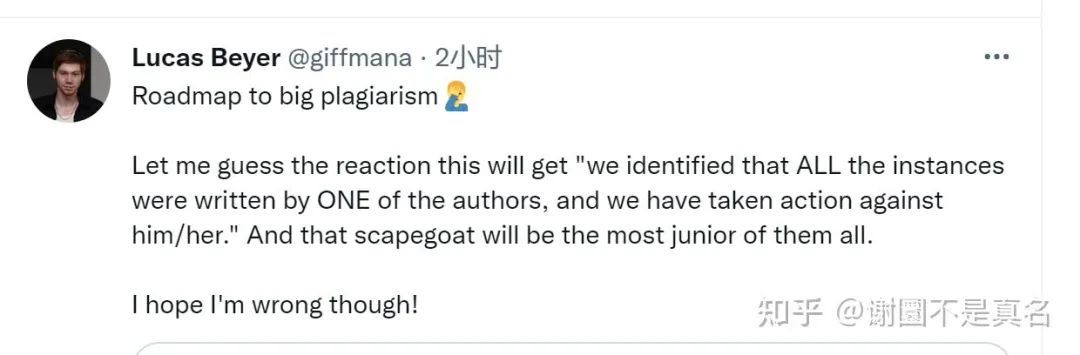
我不確定會相信一個剽竊團體的聲明。在約130頁的內(nèi)容中,有10個區(qū)域被抄襲。
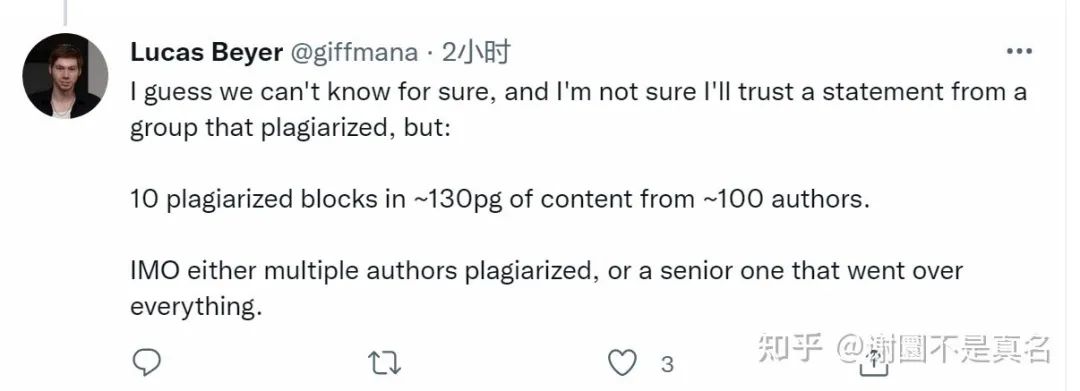
每個人都樂于分享多作者論文的功勞/引文--但當涉及到責任時,也會分享嗎?應(yīng)該嗎?
把原文翻譯過來:
I recently came to be aware of a case of plagiarism in the machine learning research space. The paper A Roadmap for Big Model plagiarized several paragraphs from one of my recent papers Deduplicating Training Data Makes Language Models Better. (There is some irony in the fact that the Big Models paper copies from a paper about data copying. This irony was not lost on us.) This is unfortunate, but to my dismay, our paper was not the only paper copied from: the Big Models paper copied from at least a dozen other papers.
我最近意識到了機器學(xué)習(xí)研究領(lǐng)域的一個抄襲案例。A Roadmap for Big Model這篇論文抄襲了我最近的一篇論文中的幾個段落,即重復(fù)訓(xùn)練數(shù)據(jù)使語言模型更好。(大模型的論文抄襲了一篇關(guān)于數(shù)據(jù)復(fù)制的論文,這有一些諷刺意味。這種諷刺對我們來說并不陌生)。這是不幸的,但令我沮喪的是,我們的論文并不是唯一被抄襲的論文:Big Models的論文至少抄襲了其他十幾篇論文。
In the grand scheme of things, this particular form of copying isn’t the worst thing ever. It’s not like a paper has directly copied the method of a prior result and claimed it as its own. But even putting aside the fact that claiming someone else's writing as one's own is wrong, the value in survey papers is in how they re-frame the field. A survey paper that just copies directly from the prior paper hasn't contributed anything new to the field that couldn't be obtained from a list of references.
從總體上看,這種特殊形式的抄襲并不是最糟糕的事情。這并不像一篇論文直接抄襲先前的結(jié)果的方法,并聲稱它是自己的。但是,即使拋開把別人的文章說成是自己的文章是錯誤的這一事實,調(diào)查報告的價值在于它們?nèi)绾沃匦聵?gòu)筑這個領(lǐng)域。一篇只是直接抄襲前一篇論文的調(diào)查報告并沒有對該領(lǐng)域做出任何新的貢獻,而這是無法從參考文獻列表中獲得的。
(Please note the Big Models paper has a hundred authors. Likely only a few of the authors have participated in this copying. Misconduct by a small fraction of the authors should not be held against the majority of well-behaving authors.)
(請注意,《大模型》論文有一百個作者。很可能只有少數(shù)作者參與了這種抄襲。一小部分作者的不當行為不應(yīng)該被用來指責大多數(shù)行為良好的作者)。
See below for a few of the more egregious examples of this, with text from the Big Models paper on the left and the corresponding text from the original paper on the right. Copied text is highlighted in green.
下面是幾個比較惡劣的例子,左邊是大模型論文的文字,右邊是原始論文的相應(yīng)文字。復(fù)制的文字以綠色標出。
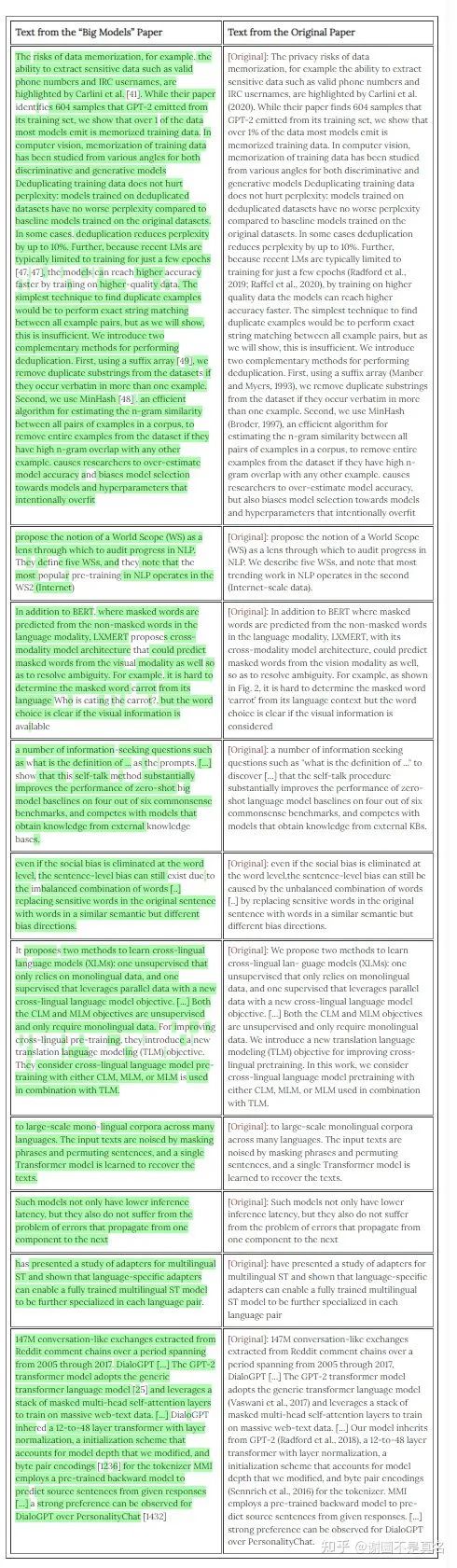
One of my coauthors was reading the Big Models paper and noticed that some of the text seemed oddly familiar, and after quickly looking things over we found that in fact a bunch of the text was directly copied from our paper.
我的一位合作者在閱讀《大模型》的論文時,注意到其中的一些文字似乎很奇怪,在快速查看之后,我們發(fā)現(xiàn)事實上有一堆文字是直接從我們的論文中復(fù)制的。
Given that this happened to us, we then set out to see if there were other examples too. As part of a prior project, I had collected a dataset of PDFs for (almost) every accepted paper at top machine learning venues (ICML/ICLR/NeurIPS/AAAI/ACL/etc). So all I did to find the above copied text was to take these PDFs, extract out all of the text and dump it into a single .txt file, and then run our dataset deduplication tools (that we developed for the paper that was copied from!) to find all repeated sequences that were contained both in the Big Models paper along with some other prior publication. To rule out false positives, I only considered sequences of
鑒于這種情況發(fā)生在我們身上,我們就著手看看是否也有其他的例子。作為之前一個項目的一部分,我收集了一個數(shù)據(jù)集,其中包括頂級機器學(xué)習(xí)場所(ICML/ICLR/NeurIPS/AAAI/ACL/等)接受的每篇論文的PDF文件。因此,為了找到上述復(fù)制的文本,我所做的就是把這些PDF文件提取出來,把所有的文本轉(zhuǎn)儲到一個.txt文件中,然后運行我們的重復(fù)數(shù)據(jù)集工具(這是我們?yōu)楸粡?fù)制的論文開發(fā)的!),找到所有重復(fù)的序列,這些序列既包含在大模型論文中,也包含在其他先前的出版物中。為了排除假陽性,我只考慮:
1. at least 10 words (after whitespace normalization),
2. that are contained sequentially in the Big Models paper,
3. and also present in a prior paper,
4. but are not present in more than one prior paper.
至少10個字的序列(經(jīng)過空白規(guī)范化處理)。
2. 按順序出現(xiàn)在《大模型》論文中。
3. 并且也出現(xiàn)在之前的論文中。
4. 沒有出現(xiàn)在一篇以上的論文中。
This ensures that I won’t flag any common phrases as copied (e.g., copyright blocks, citations to prior paper titles or author names, etc).
這確保了我不會將任何常見的短語標記為抄襲(例如,版權(quán)塊、對先前論文標題或作者姓名的引用,等等)。
And then from there, it was just a matter of quickly manually reviewing a few of the most egregious cases (shown above). There were other examples of self-plagiarism where the paper that was copied from shared an author with the new paper that I have omitted–while this isn’t an ideal practice, it’s less concerning.
然后,從那里開始,只是快速地手動審查一些最令人震驚的案例(如上圖所示)。還有一些自我抄襲的例子,其中被抄襲的論文與我省略的新論文有共同的作者--雖然這不是一個理想的做法,但它不太令人擔憂。
Because of this filtering process, and because my dataset of papers is not exhaustive over all prior publications (notably, it only contains accepted papers, not arXiv preprints), it is possible there is more copying going on here than I have identified. However even what we have found so far is already more than should happen, and I am saddened that this is happening at all.
由于這個過濾過程,以及我的論文數(shù)據(jù)集并不包括所有先前的出版物(特別是,它只包含被接受的論文,而不是arXiv預(yù)印本),這里有可能存在比我所發(fā)現(xiàn)的更多的抄襲。然而,即使是我們目前發(fā)現(xiàn)的情況也已經(jīng)超過了應(yīng)該發(fā)生的程度,我對這種情況的發(fā)生感到悲哀。
這篇文章具體涉嫌抄襲的位置和相應(yīng)的分析可以看這篇回答:
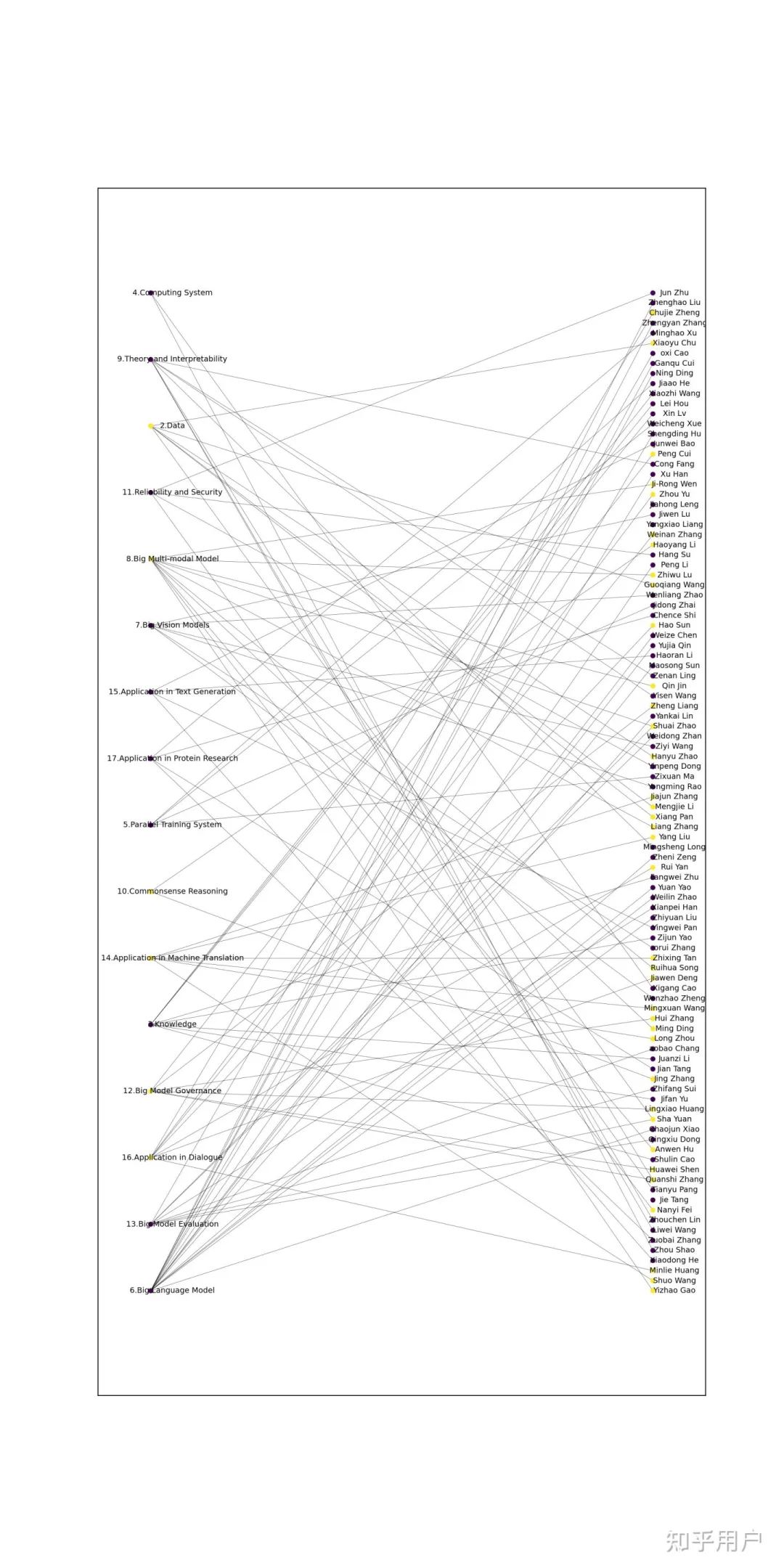
2.3.1, 2.4.3(Data): Hanyu Zhao, Guoqiang Wang, Xiang Pan, Mengjie Li, Xiaoyu Chu, Sha Yuan
8.3.1(Big Multi-modal Model): Shuai Zhao*, Yizhao Gao*, Liang Zhang*, Ming Ding*, Nanyi Fei, Anwen Hu, Zhiwu Lu, Qin Jin, Ruihua Song, Ji-Rong Wen
10.2(Commonsense Reasoning): Jing Zhang, Haoyang Li
12.2.3(Big Model Governance): Peng Cui, Lingxiao Huang, Zheng Liang, Huawei Shen, Hui Zhang, Quanshi Zhang
14.2.1, 14.2.2, 14.2.3(Application in Machine Translation): Zhixing Tan*, Mingxuan Wang*, Shuo Wang*, Long Zhou*, Jiajun Zhang, Yang Liu
16.2.1(Application in Dialogue): Weinan Zhang*, Zhou Yu*, Rui Yan*, Hao Sun, Jiawen Deng, Chujie Zheng, Minlie Huang
疑似作者之一出沒:

匿名用戶回答:
按這種大型工作,一般是可以看成多篇小文章整合的。按照文中給的署名規(guī)范,大致可以認為每章是一篇小文章。大文章層面,可能作者不知道別的章節(jié)內(nèi)容,沒有互相check。但是小文章內(nèi)部作者們可能還是要站出來說說話的。
主要出現(xiàn)抄襲的章節(jié)有
2.3.1, 2.4.3(Data): Hanyu Zhao, Guoqiang Wang, Xiang Pan, Mengjie Li, Xiaoyu Chu, Sha Yuan
8.3.1(Big Multi-modal Model): Shuai Zhao*, Yizhao Gao*, Liang Zhang*, Ming Ding*, Nanyi Fei, Anwen Hu, Zhiwu Lu, Qin Jin, Ruihua Song, Ji-Rong Wen
10.2(Commonsense Reasoning): Jing Zhang, Haoyang Li
12.2.3(Big Model Governance): Peng Cui, Lingxiao Huang, Zheng Liang, Huawei Shen, Hui Zhang, Quanshi Zhang
14.2.1, 14.2.2, 14.2.3(Application in Machine Translation): Zhixing Tan*, Mingxuan Wang*, Shuo Wang*, Long Zhou*, Jiajun Zhang, Yang Liu
16.2.1(Application in Dialogue): Weinan Zhang*, Zhou Yu*, Rui Yan*, Hao Sun, Jiawen Deng, Chujie Zheng, Minlie Huang
由于目前文章的作者只精確到了章節(jié),所以出現(xiàn)在上面的人不一定真的抄襲了,可能這里面仍然有很多人是被拉下水的。
稍微做了一個圖,紫色的是無抄襲的,黃色的是涉嫌抄襲的。部分作者沒有出現(xiàn)在具體章節(jié)里但是在總作者名單里。
文章轉(zhuǎn)載自知乎,著作權(quán)歸屬原作者,侵刪
——The ?End——

