
百余大佬署名AI論文被爆抄襲!智源現(xiàn)已致歉
日期?:?2022年05月17日?? ? ??
正文共?:4742字
【導讀】最近,一篇由智源研究院等組織百余名作者的綜述報告「大模型路線圖」被曝抄襲,震撼了整個AI界!

智源官方宣布道歉


一篇綜述引發(fā)的「血案」


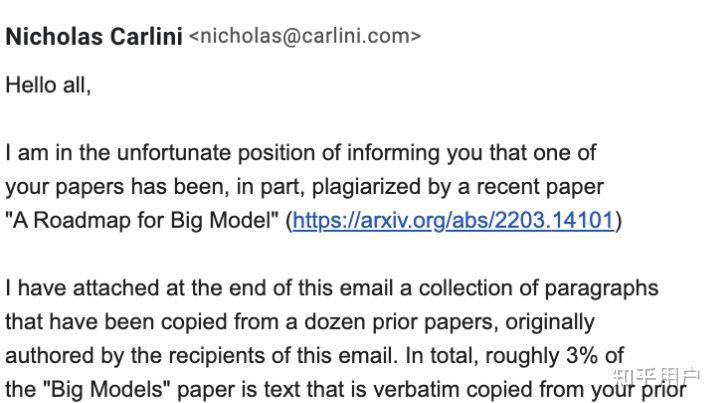
被抄的谷歌研究員親自爆料抄襲
判定流程








學術(shù)不端擦邊球,亟須重視!
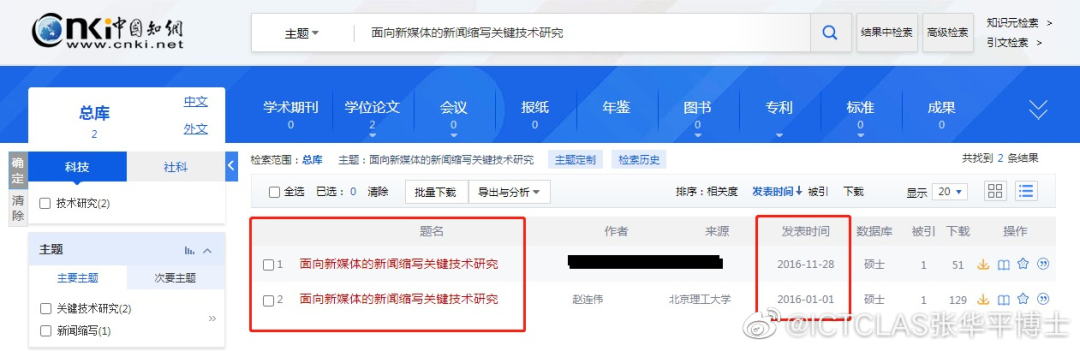
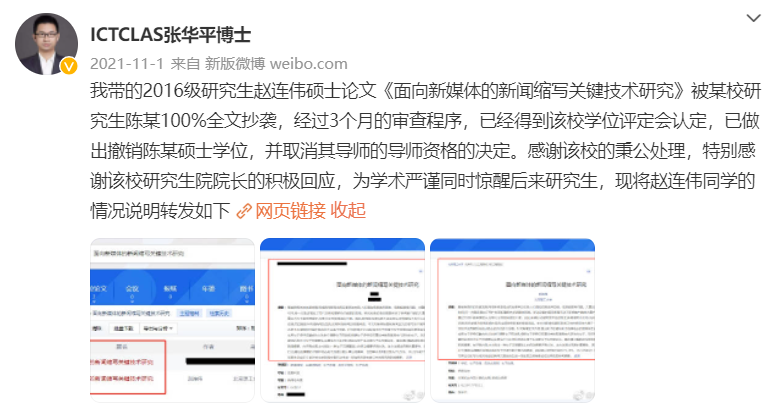
給我翻譯翻譯,什么叫「抄襲」?


掛名掛出一個「海」

學術(shù)規(guī)范,就在地平線上




—?THE END —

評論
圖片
表情