
居然用 Numpy 實(shí)現(xiàn)了一個(gè)深度學(xué)習(xí)框架
今天跟大家分享一個(gè)牛逼的開(kāi)源項(xiàng)目,該項(xiàng)目只用Numpy就實(shí)現(xiàn)了一個(gè)深度學(xué)習(xí)框架。
它不是一個(gè)demo, 而是一個(gè)實(shí)實(shí)在在能應(yīng)用的深度學(xué)習(xí)框架,它的語(yǔ)法與PyTorch一致,用它可以實(shí)現(xiàn)CNN、RNN、DNN等經(jīng)典的神經(jīng)網(wǎng)絡(luò)。
該框架對(duì)正在學(xué)習(xí)深度學(xué)習(xí)的朋友非常友好,因?yàn)樗拇a量不到 2000 行,大家完全可以通過(guò)閱讀源碼來(lái)深入了解神經(jīng)網(wǎng)絡(luò)內(nèi)部的細(xì)節(jié)。
如果大家讀完源碼自己也能做一個(gè)類(lèi)似的深度學(xué)習(xí)框架,就更完美了。
1. 與 PyTorch 對(duì)比
接下來(lái),我用該框架搭建一個(gè)簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò),并與PyTorch對(duì)比。
我們用這個(gè)神經(jīng)網(wǎng)絡(luò)來(lái)實(shí)現(xiàn)線(xiàn)性回歸:
用下面的函數(shù)來(lái)生成訓(xùn)練樣本
def?synthetic_data(w,?b,?num_examples):?
????"""生成y=w1*x1+w2*x2+b訓(xùn)練樣本"""
????X?=?np.random.normal(0,?1,?(num_examples,?len(w)))
????y?=?np.dot(X,?w)?+?b
????y?+=?np.random.normal(0,?0.01,?y.shape)
????return?X,?y.reshape((-1,?1))
w?=?np.array([2,?-3.4])
b?=?4.2
features,?labels?=?synthetic_data(w,?b,?1000)
這里我們令w1=2、w2=-3.4、b=4.2,隨機(jī)生成1000個(gè)訓(xùn)練樣本,x1、x2存放在features變量中,y存放在labels變量中。
下面我們要做的是將這些樣本輸入神經(jīng)網(wǎng)絡(luò)中,訓(xùn)練出參數(shù)w1、w2和b,我們希望模型訓(xùn)練出來(lái)的參數(shù)跟實(shí)際的w1、w2和b越接近越好。
先用PyTorch來(lái)搭建神經(jīng)網(wǎng)絡(luò),并訓(xùn)練模型。
from?torch?import?nn,?Tensor
import?torch
#?只有一個(gè)神經(jīng)元,并且是線(xiàn)性神經(jīng)元
#?2代表有2個(gè)特征(x1、x2),1代表輸出1個(gè)特征(y)
net?=?nn.Linear(2,?1)
print(f'初始w:{net.weight.data}')
print(f'初始b:{net.bias.data}')
#?用均方誤差作為線(xiàn)性回歸損失函數(shù)
loss?=?nn.MSELoss()
#?采用梯度下降算法優(yōu)化參數(shù),lr是學(xué)習(xí)速率
trainer?=?torch.optim.SGD(net.parameters(),?lr=0.03)
#?轉(zhuǎn)?Tensor
X?=?Tensor(features)
y?=?Tensor(labels)
#?迭代次數(shù)
num_epochs?=?300
for?epoch?in?range(num_epochs):
????l?=?loss(net(X),?y)??#?計(jì)算損失
????trainer.zero_grad()
????l.backward()??#?反向傳播,求導(dǎo)
????trainer.step()??#?更新參數(shù)
????l?=?loss(net(X),?y)?#?參數(shù)更新后,再次計(jì)算損失
????print(f'epoch?{epoch?+?1},?loss?{round(float(l.data),?8)}')
print(f'模型訓(xùn)練后的w:{net.weight.data}')
print(f'模型訓(xùn)練后的b:{net.bias.data}')
這里我們用的是最簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò),只有一個(gè)神經(jīng)元。
代碼也比較簡(jiǎn)單,每行都做了注釋。
輸出的結(jié)果也是符合我們的預(yù)期,輸出的損失如下:
epoch?1,?loss?33.65092468
epoch?2,?loss?29.78330231
epoch?3,?loss?26.36030769
...
epoch?298,?loss?0.0001022
epoch?299,?loss?0.0001022
epoch?300,?loss?0.0001022
前幾輪損失比較大,等迭代300次后,損失已經(jīng)非常小了。再看訓(xùn)練出來(lái)的參數(shù):
初始w:tensor([[0.5753, 0.6624]])
初始b:tensor([-0.5713])
...
模型訓(xùn)練后的w:tensor([[ 1.9995, -3.4001]])
模型訓(xùn)練后的b:tensor([4.1998])
可以看到,經(jīng)過(guò)訓(xùn)練后,模型的參數(shù)與設(shè)定的參數(shù)也是非常接近的。
下面,我們?cè)儆媒裉旖榻B的框架再來(lái)實(shí)現(xiàn)一遍。
from?pydynet?import?nn,?Tensor
from?pydynet.optimizer?import?SGD
net?=?nn.Linear(2,?1)
print(f'初始w:{net.weight.data}')
print(f'初始b:{net.bias.data}')
loss?=?nn.MSELoss()
trainer?=?SGD(net.parameters(),?lr=0.03)
X?=?Tensor(features)
y?=?Tensor(labels)
num_epochs?=?300
for?epoch?in?range(num_epochs):
????l?=?loss(net(X),?y)??#?計(jì)算損失
????trainer.zero_grad()
????l.backward()??#?反向傳播,求導(dǎo)
????trainer.step()??#?更新參數(shù)
????l?=?loss(net(X),?y)??#?參數(shù)更新后,再次計(jì)算損失
????print(f'epoch?{epoch?+?1},?loss?{round(float(l.data),?8)}')
????
print(f'模型訓(xùn)練后的w:{net.weight.data}')
print(f'模型訓(xùn)練后的b:{net.bias.data}')
代碼從pydynet目錄引入的,可以看到,用法跟PyTorch幾乎是一模一樣,輸出參數(shù)如下:
初始w:[[-0.25983338]
?[-0.29252936]]
初始b:[-0.65241649]
...
模型訓(xùn)練后的w:[[ 2.00030734]
?[-3.39951581]]
模型訓(xùn)練后的b:[4.20060585]
訓(xùn)練出來(lái)的結(jié)果也是符合預(yù)期的。
2. 項(xiàng)目結(jié)構(gòu)
pydynet項(xiàng)目架構(gòu)如下:
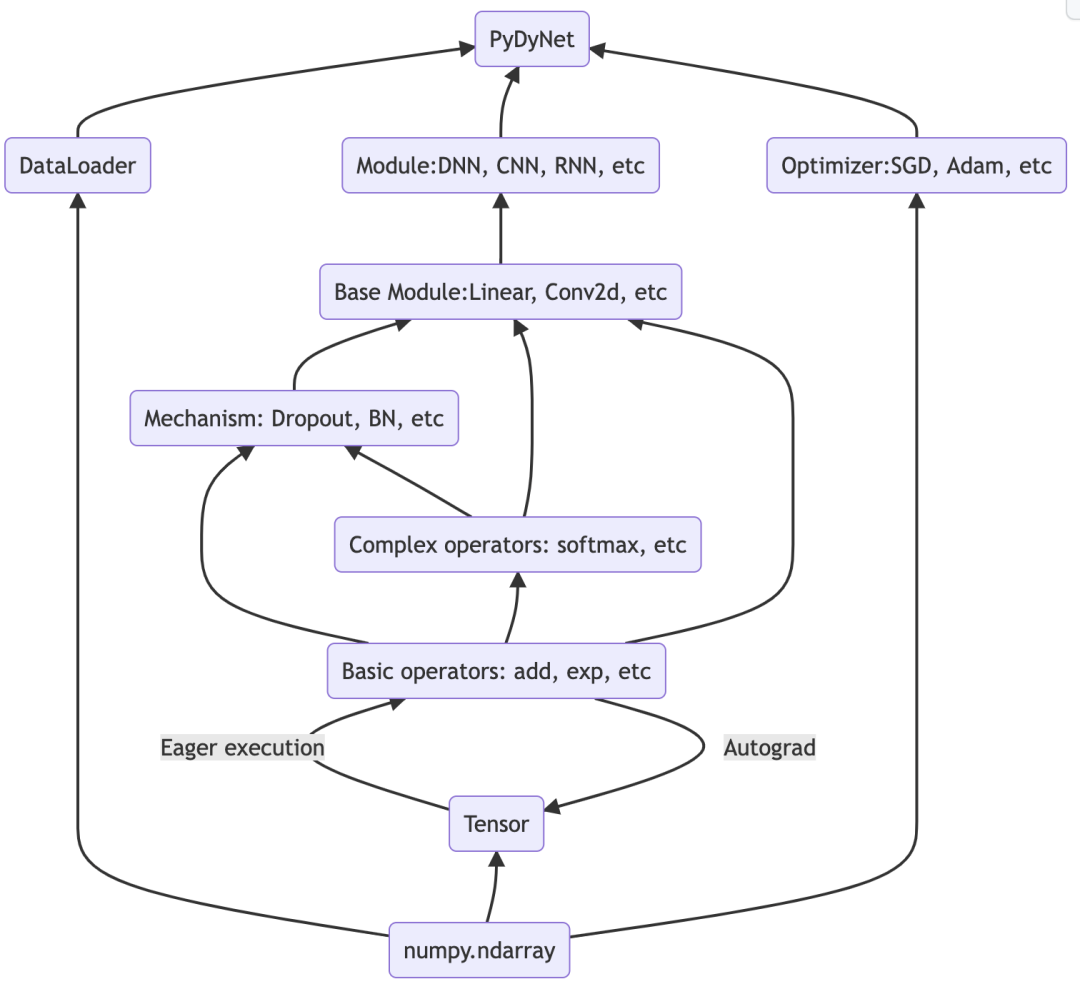
目前只有 5 個(gè) Python源文件,不到 2000 行代碼。
第一小節(jié)我們只實(shí)現(xiàn)最簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò),其他經(jīng)典的神經(jīng)網(wǎng)絡(luò),也有源碼,大家可以自行查閱
項(xiàng)目地址:https://github.com/Kaslanarian/PyDyNet
我非常喜歡這個(gè)項(xiàng)目,佩服這個(gè)項(xiàng)目的作者。如果你也正好在學(xué)習(xí)人工智能,強(qiáng)烈建議學(xué)習(xí)學(xué)習(xí)這個(gè)項(xiàng)目。
希望今天的內(nèi)容對(duì)你有用,感謝你的關(guān)注,我將持續(xù)分享優(yōu)秀的 AI 項(xiàng)目。
--end-- 掃碼即可加我微信
學(xué)習(xí)交流
老表朋友圈經(jīng)常有贈(zèng)書(shū)/紅包福利活動(dòng)