
不同品種貓貓有多相似呢,Python 文本相似度計算


前言
之前小編呢爬過貓貓 20w 的交易數(shù)據(jù),做了一個簡單的數(shù)據(jù)分析,詳情看這篇文章:
《爬取 20W 貓貓數(shù)據(jù),來了解一下喵喵~》
最近碰到了文本相似度的問題,想到了貓貓數(shù)據(jù)中有品種的相關描述,于是用品種描述文本來研究一下文本相似度計算的。
查找了一下資料找到了幾種實現(xiàn)方法,實現(xiàn)的目的都一樣,小編就做了一個對比。
數(shù)據(jù)處理

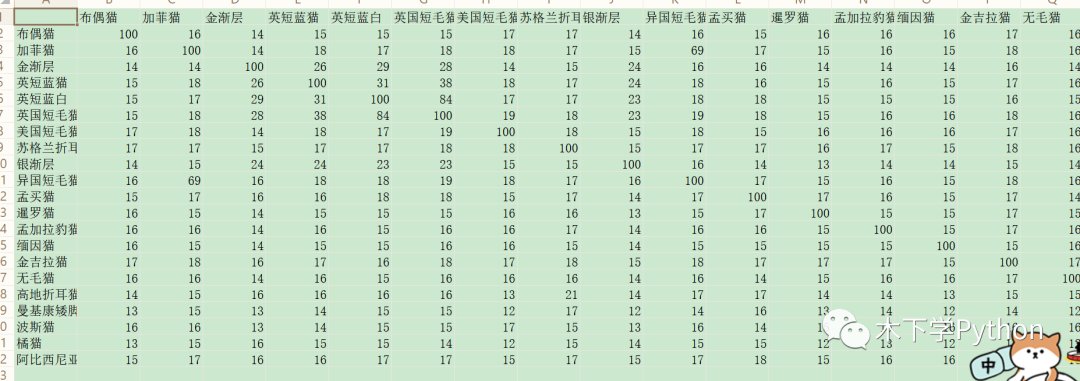
數(shù)據(jù)原始有很多列,我們需要把 O 列直至末尾的這些描述每個品種貓貓的文本合為一列:


以此計算每個品種的描述與其他品種描述的相似度,把“描述”列作為文本列表,“品種”作為索引,兩兩計算。
合并后的文本指數(shù)其實是挺多的,這樣便于對比出那種方法更快。
difflib
difflib 是 Python 的內(nèi)置庫,基于 Ratcliff-Obershelp 算法(格式塔模式匹配)。
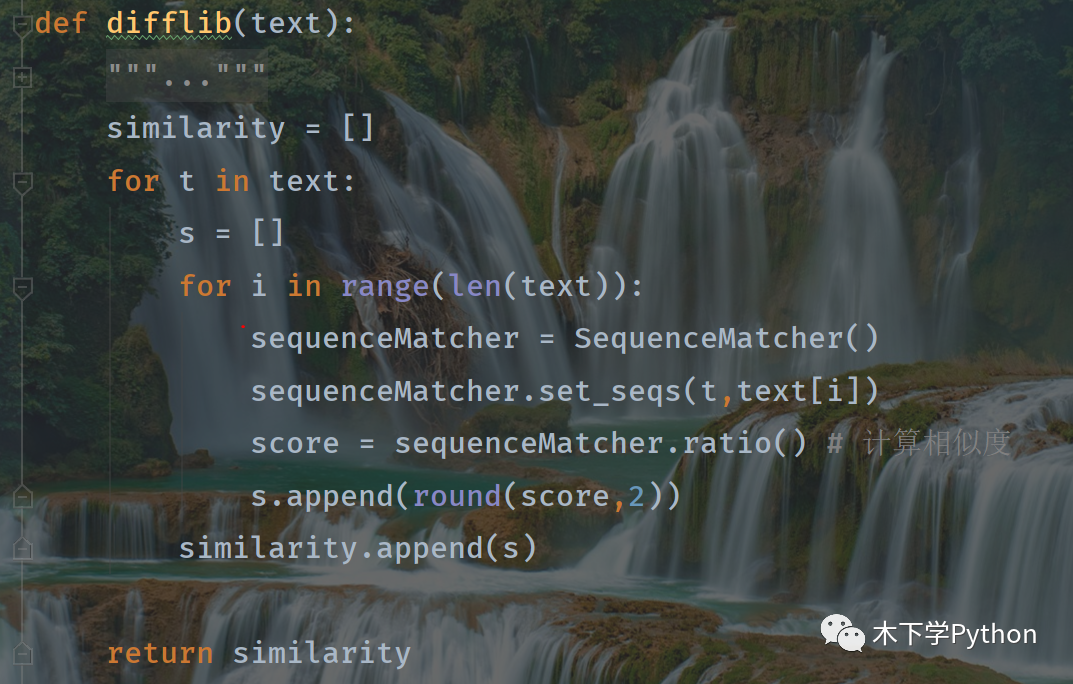

計算值是 0-1 之間的,越接近 1 說明文本越相似。
fuzzywuzzy
fuzzywuzzy 是一個第三方庫,基于萊文斯坦距離,需要安裝 python-Levenshtein,fuzzywuzzy,直接 pip 即可。
這個原理最容易說明,萊文斯坦距離一個字符串變?yōu)榱硗庖粋€字符串經(jīng)過刪除,插入,替換的編輯距離。

計算的值介于 0-100,值越大說明兩文本越相似。
余弦距離
接下來介紹的集中距離都是需要先將文本進行向量化的,通過向量化計算顯示距離。
文本向量化必須兩個對比的文本同時向量化操作,確保兩文本向量化的長度一樣才可進行計算,部分代碼:

兩對比文本向量化后,再進行相似度計算:
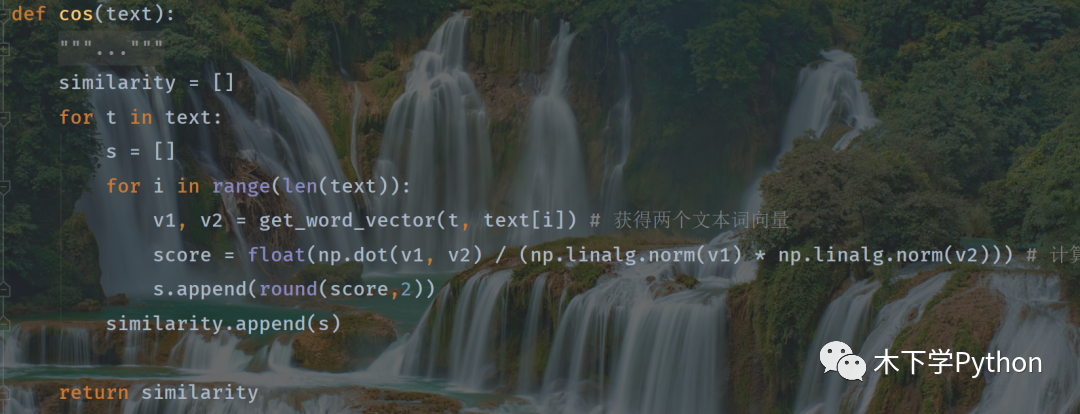
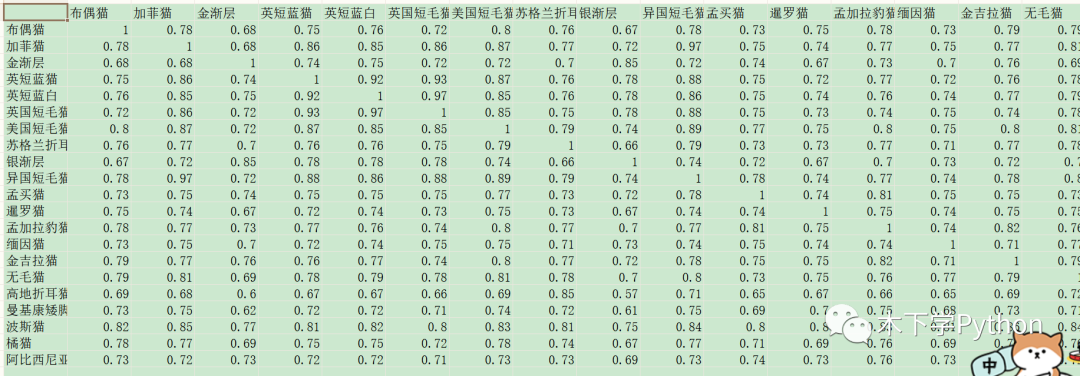
余弦相似度,值介于 0-1,越大說明兩文本越相似。
從結(jié)果上看對比前兩個,值要大于 0.9 才相當于有 60% 以上的相似度,前兩種方法更為直觀。
其他距離
其他距離的計算方法還有歐式距離,曼哈頓距離,切比雪夫距離,杰爾德距離,漢明距離,這些值的范圍沒有上限,越小說明文本越相似。
還有皮爾遜相關系數(shù),這個計算的值介于 0-1,值越大說明文本越相似。
它們的實現(xiàn)方式都與余弦相似,詳細可查看源代碼。
結(jié)果

小編使用了所有方法計算相似度,fuzzywuzz 方法計算的時間最快,其次是 difflib,且結(jié)果比較直觀,其他方法都需要文本向量化在比較,所以在文本較長時,時間有點久。
最后使用 fuzzywuzz 計算的相似度,繪制熱力相關圖直觀的展示貓貓品種哪些描述較為相似:

異國短毛貓與加菲貓描述相似度較高,英囯藍白與英國短毛貓相似度也較高。
這樣一個文本相似度計算就完成了。
源碼獲取
在公眾號對話框回復關鍵字“文本相似度”即可獲取
END
讀者交流群已建立,找到我備注 “交流”,即可獲得加入我們~
聽說點 “在看” 的都變得更好看吶~
關注關注小編唄~小編給你分享爬蟲,數(shù)據(jù)分析,可視化的內(nèi)容噢~
掃一掃下方二維碼即可關注我噢~
-END-