
上市公司地址相似度計算&構(gòu)建關(guān)系圖譜
作?者:?凌岸??來源1: https://zhuanlan.zhihu.com/p/111203086來源2: https://zhuanlan.zhihu.com/p/459309174文末點擊閱讀原文跳轉(zhuǎn)知乎,閱讀作者更多精彩文章
今天和各位小伙伴分析一個在搭建知識圖譜的時候遇到的一個麻煩的問題。在構(gòu)建知識圖譜的圖關(guān)系,基礎(chǔ)的原始數(shù)據(jù)來自很多不同的數(shù)據(jù)源。比如在金融風(fēng)控領(lǐng)域,我們要構(gòu)建的知識圖譜中,包含地址、公司等出現(xiàn)頻率比較高,并且名稱一模一樣的可能性很低的詞匯。比如下面兩個是同一個地址么?
本文目錄如下:一、地址數(shù)據(jù)預(yù)處理二、數(shù)據(jù)地址標(biāo)準(zhǔn)化處理三、相似度計算四、構(gòu)造節(jié)點表和關(guān)系表五、導(dǎo)入節(jié)點表和關(guān)系表構(gòu)建圖譜
對數(shù)據(jù)做一個預(yù)覽,所幸我們本次下載的公開數(shù)據(jù)質(zhì)量很高,地址中并未出現(xiàn)一些質(zhì)量差的數(shù)據(jù),省去了多余的要做的一些處理。
二、地址數(shù)據(jù)標(biāo)準(zhǔn)化處理
地址中有很多存在不標(biāo)準(zhǔn)的情況存在,所以使用capa的包進行標(biāo)準(zhǔn)化處理。寫到這里,提一句,本身我是想自己去開發(fā)這個一個功能,但是發(fā)現(xiàn)了有開源工具,全稱為:chinese_province_city_area_mapper。他也提供了全文模式和分詞模式兩種。那他的功能也很強大,可以將地址數(shù)據(jù)補全: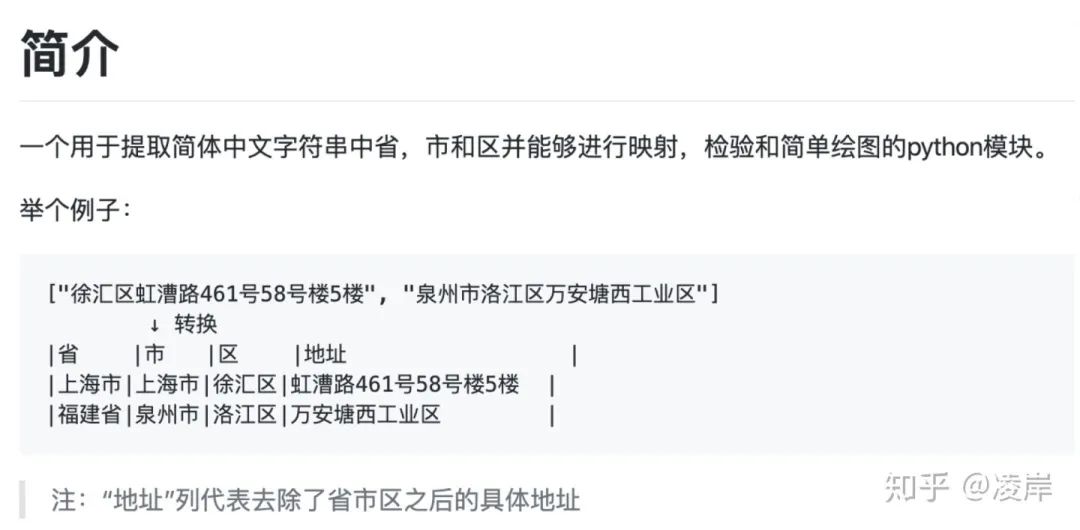 我也附出這個cpca包的github鏈接:
我也附出這個cpca包的github鏈接:
處理結(jié)束的樣例如下: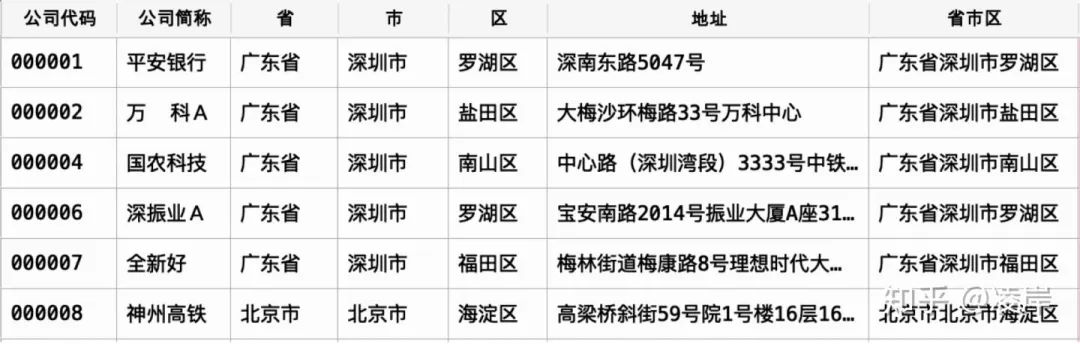
第2個地址與n-2個地址比較
第3個地址與n-3個地址比較
第n-1個地址與n個地址比較
第n個不執(zhí)行
第三層函數(shù)計算目標(biāo)文檔與被比較文檔之間的地址相似度,其中按照上面的函數(shù)舉例即為,目標(biāo)文檔為第一個地址,被比較文檔為,n-1個所有的地址,這里我們是有使用TF-DF模型對料庫建模,如此即將同一個省市區(qū)下面的地址循環(huán)完成。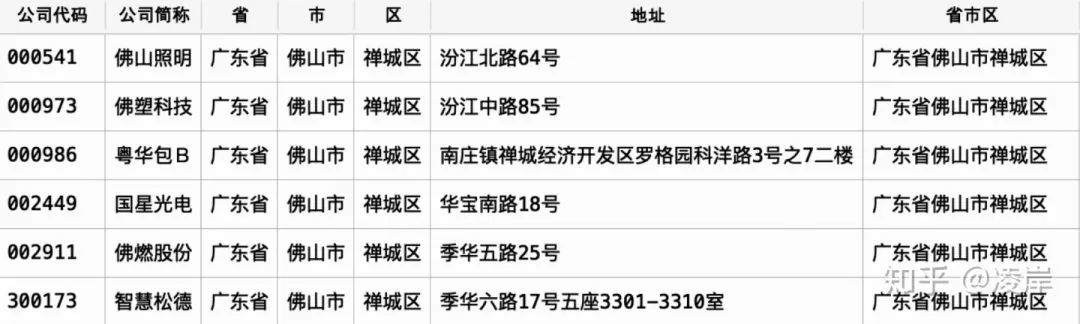 在算法里面,我們將第一個地址即為,佛山照明的地址”汾江北路64號“同時與剩下的5個地址進行比較相似度,
在算法里面,我們將第一個地址即為,佛山照明的地址”汾江北路64號“同時與剩下的5個地址進行比較相似度,
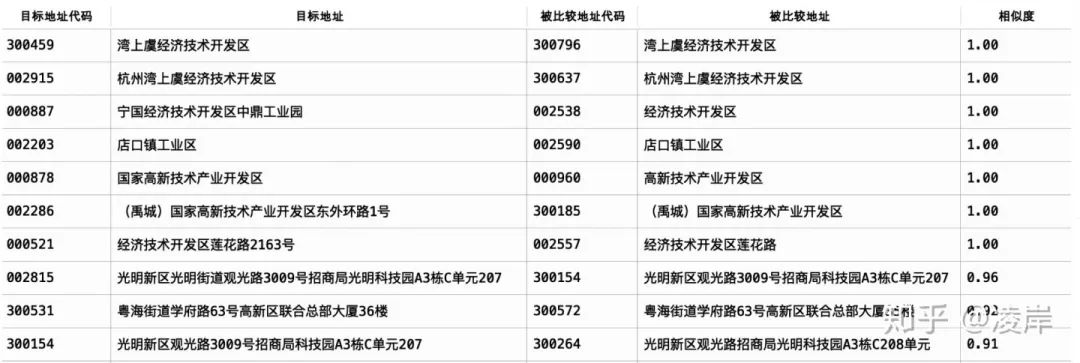 每一行都在同一個省市區(qū)下面,那么最后的地址判斷,我們看到還是準(zhǔn)確的,基本上都識別出來了,特別是相似度為0.9的那個幾組。
每一行都在同一個省市區(qū)下面,那么最后的地址判斷,我們看到還是準(zhǔn)確的,基本上都識別出來了,特別是相似度為0.9的那個幾組。
 添加圖片注釋,不超過 140 字(可選)為了要將結(jié)果數(shù)據(jù)導(dǎo)入到neo4j中,我們要加工好節(jié)點表和關(guān)系,我們順勢采用這個結(jié)果。
添加圖片注釋,不超過 140 字(可選)為了要將結(jié)果數(shù)據(jù)導(dǎo)入到neo4j中,我們要加工好節(jié)點表和關(guān)系,我們順勢采用這個結(jié)果。

今天和各位小伙伴分析一個在搭建知識圖譜的時候遇到的一個麻煩的問題。在構(gòu)建知識圖譜的圖關(guān)系,基礎(chǔ)的原始數(shù)據(jù)來自很多不同的數(shù)據(jù)源。比如在金融風(fēng)控領(lǐng)域,我們要構(gòu)建的知識圖譜中,包含地址、公司等出現(xiàn)頻率比較高,并且名稱一模一樣的可能性很低的詞匯。比如下面兩個是同一個地址么?
深圳市京基100大廈寫字樓深圳市羅湖區(qū)深南東路5016號京基100大廈那在圖關(guān)系的構(gòu)建中,如果把上地址作為兩個地址進行處理的話,那么就會創(chuàng)建兩個實體,并且這兩個實體之間并沒有什么關(guān)聯(lián)關(guān)系,這種處理方法,肯定是有問題的。此時,我們衍生出了兩個問題:1、第一,對于以上的問題做地址消歧,把兩個地址經(jīng)過處理后,變成同一個地址。2、或者說,我們做一個兩個實體之間的地址相似度,如在圖譜中表現(xiàn)為 A節(jié)點與B節(jié)點的相似度為0.9以上。這個時候我們需要做的是進行相似度計算。我們在深圳證券交易所找到了公開的數(shù)據(jù)集。發(fā)現(xiàn)深交所數(shù)據(jù)已經(jīng)失效了,給出百度鏈接在這里。鏈接: https://pan.baidu.com/wap/init?surl=qAOb17tGPg_HDKsaZ8w5xw 密碼: 7ojt
本文目錄如下:一、地址數(shù)據(jù)預(yù)處理二、數(shù)據(jù)地址標(biāo)準(zhǔn)化處理三、相似度計算四、構(gòu)造節(jié)點表和關(guān)系表五、導(dǎo)入節(jié)點表和關(guān)系表構(gòu)建圖譜
一、地址數(shù)據(jù)預(yù)處理
我們先導(dǎo)入一些后續(xù)用的上的python包,如下:下面,我們導(dǎo)入public_company這個數(shù)據(jù)集,可以預(yù)覽一下,該部分?jǐn)?shù)據(jù)有哪些字段。import numpy as npimport pandas as pdfrom csv import readerimport timeimport cpcaimport jiebafrom gensim import corpora, models, similarities
我們選取公司代碼、公司簡稱、公司地址三個字段,并將字段中地址進行去空處理。df.columnsIndex(['公司代碼', '公司簡稱', '公司全稱', '英文名稱', '注冊地址', 'A股代碼', 'A股簡稱', 'A股上市日期','A股總股本', 'A股流通股本', '地 區(qū)', '省 份', '城 市', '所屬行業(yè)', '公司網(wǎng)址'],dtype='object')
對數(shù)據(jù)做一個預(yù)覽,所幸我們本次下載的公開數(shù)據(jù)質(zhì)量很高,地址中并未出現(xiàn)一些質(zhì)量差的數(shù)據(jù),省去了多余的要做的一些處理。
def read_data():#導(dǎo)入數(shù)據(jù),并對數(shù)據(jù)做一些處理df = pd.read_excel("../public_company.xlsx", dtype={'公司代碼': 'str'})addr_df = df[["公司代碼", "公司簡稱", "注冊地址"]]addr_df["注冊地址"]= addr_df["注冊地址"].apply(lambda x: str(x).strip())return addr_df
二、地址數(shù)據(jù)標(biāo)準(zhǔn)化處理
地址中有很多存在不標(biāo)準(zhǔn)的情況存在,所以使用capa的包進行標(biāo)準(zhǔn)化處理。寫到這里,提一句,本身我是想自己去開發(fā)這個一個功能,但是發(fā)現(xiàn)了有開源工具,全稱為:chinese_province_city_area_mapper。他也提供了全文模式和分詞模式兩種。那他的功能也很強大,可以將地址數(shù)據(jù)補全:我也附出這個cpca包的github鏈接:處理結(jié)束的樣例如下:
def get_dataset(addr_df):'''#對地址做一個標(biāo)準(zhǔn)化處理,其中導(dǎo)入cpca的包進行處理'''start = time.clock()location_str = []for i in addr_df['注冊地址']:location_str.append(i.strip())addr_cp = cpca.transform(location_str,cut=False,open_warning=False)#給結(jié)果表拼接唯一識別代碼e_data = addr_df[["公司代碼", "公司簡稱"]]addr_cpca = pd.concat([e_data, addr_cp], axis=1)#1.區(qū)不為空addr_cpca_1 = addr_cpca[(addr_cpca['省']!= '')&(addr_cpca['市']!= '') & (addr_cpca['區(qū)']!= '')]addr_cpca_1= addr_cpca_1.dropna()addr_cpca_11= addr_cpca_1[(addr_cpca['地址']!='')]addr_cpca_12= addr_cpca_11. dropna(subset=['地址'])#將前三個字段完全拼接在一起進行分組然后組內(nèi)進行相似度分析addr_cpca_12['省市區(qū)'] = addr_cpca_12['省'] + addr_cpca_12['市'] + addr_cpca_12['區(qū)']addr_cpca_12['省市區(qū)長度']=addr_cpca_12['省市區(qū)'].apply(lambda x: len(x))count_1 = addr_cpca_12['省市區(qū)'].value_counts().reset_index()count_1= count_1.rename(columns={'index':'省市區(qū)', '省市區(qū)':'個數(shù)'})count_delete_1= count_1[count_1['個數(shù)']==1]dataset_1 = pd.merge(addr_cpca_12, count_delete_1, on = '省市區(qū)', how = 'left')dataset_1= dataset_1[dataset_1['個數(shù)']!=1]#2.區(qū)為空addr_cpca_2 = addr_cpca[(addr_cpca['省']!= '')&(addr_cpca['市']!= '') & (addr_cpca['區(qū)']== '')]addr_cpca_2 = addr_cpca_2.dropna()addr_cpca_21= addr_cpca_2[(addr_cpca['地址']!='')]addr_cpca_22= addr_cpca_21. dropna(subset=['地址'])#將前三個字段完全拼接在一起進行分組然后組內(nèi)進行相似度分析addr_cpca_22['省市區(qū)'] = addr_cpca_22['省'] + addr_cpca_22['市']addr_cpca_22['省市區(qū)長度']=addr_cpca_22['省市區(qū)'].apply(lambda x: len(x))count_2 = addr_cpca_22['省市區(qū)'].value_counts().reset_index()count_2= count_2.rename(columns={'index':'省市區(qū)', '省市區(qū)':'個數(shù)'})count_delete_2 = count_2[count_2['個數(shù)']==1]dataset_2 = pd.merge(addr_cpca_22, count_delete_2, on = '省市區(qū)', how = 'left')????dataset_2?=?dataset_2[dataset_2['個數(shù)']!=1]print("Time used:", (time. clock()-start), "s")return dataset_1, dataset_2
三、相似度計算
在開始計算相似度時候,較為復(fù)雜,就是要比較表里面所有數(shù)據(jù)之間的相似度,那就是兩兩之間都要比較,如果有N表數(shù)據(jù),就要比較(N-1)!?次。但是我們只是不同省份或者不同城市不同區(qū)之間的地址其實是不會相似的,我們接著上面的思路,按照區(qū)與區(qū)地址的地址進行循環(huán)比較即可。我們套用兩層循環(huán)函數(shù)即可,第一層循環(huán),函數(shù)為get_collect(),我們獲取字段省市區(qū),的單個省市區(qū)的文檔,然后再調(diào)用調(diào)用第二層循環(huán)函數(shù),函數(shù)為cycle_first(),第二層循環(huán)函數(shù)的思想是:第1個地址與n-1個地址比較第2個地址與n-2個地址比較
第3個地址與n-3個地址比較
第n-1個地址與n個地址比較
第n個不執(zhí)行
第三層函數(shù)計算目標(biāo)文檔與被比較文檔之間的地址相似度,其中按照上面的函數(shù)舉例即為,目標(biāo)文檔為第一個地址,被比較文檔為,n-1個所有的地址,這里我們是有使用TF-DF模型對料庫建模,如此即將同一個省市區(qū)下面的地址循環(huán)完成。
在算法里面,我們將第一個地址即為,佛山照明的地址”汾江北路64號“同時與剩下的5個地址進行比較相似度,def cal_similar(doc_goal, document, ssim = 0.1):#def cal_similar(doc_goai, document):'''分詞;計算文本相似度doc_goal,短文本,目標(biāo)文檔document,多個文本,被比較的多個文檔'''all_doc_list=[]for doc in document:doc= "".join(doc)doc_list=[word for word in jieba.cut(doc)]all_doc_list.append(doc_list)#目標(biāo)文檔doc_goal = "".join(doc_goal)doc_goal_list = [word for word in jieba.cut(doc_goal)]#被比較的多個文檔dictionary = corpora.Dictionary(all_doc_list) #先用dictionary方法獲詞袋corpus = [dictionary.doc2bow(doc) for doc in all_doc_list] #使用doc2bow制作預(yù)料庫#目標(biāo)文檔doc_goal_vec = dictionary.doc2bow(doc_goal_list)tfidf = models.TfidfModel(corpus)#使用TF-DF模型對料庫建模index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features = len(dictionary.keys()))#對每個目標(biāo)文檔,分析測文檔的相似度#開始比較sims = index[tfidf[doc_goal_vec]]#similary= sorted(enumerate(sims),key=lambda item: -item[1])#根據(jù)相似度排序addr_dict={"被比較地址": document, "相似度": list(sims)}similary = pd.DataFrame(addr_dict)similary["目標(biāo)地址"] = doc_goalsimilary_data = similary[["目標(biāo)地址", "被比較地址", "相似度"]]similary_data= similary_data[similary_data["相似度"]>=ssim]return similary_datadef cycle_first(single_data):single_value = single_data.loc[:,["公司代碼","地址"]].values #提取地址cycle_data = pd. DataFrame([])for key, value in enumerate(single_value):if key < len(single_data)-1:doc_goal=list(value)[1:]document=list(single_data["地址"])[key+1:]cycle = cal_similar(doc_goal, document, ssim=0)cycle['目標(biāo)地址代碼'] = list(single_data["公司代碼"])[key]cycle['被比較地址代碼'] = list(single_data["公司代碼"])[key+1:]cycle = cycle[["目標(biāo)地址代碼","目標(biāo)地址", "被比較地址代碼", "被比較地址", "相似度"]]#print("循環(huán)第",key,"個地址,得到表的行數(shù),",len(cycle),",當(dāng)前子循環(huán)計算進度,",key/len(cycle))cycle_data = cycle_data.append(cycle)cycle_data = cycle_data.drop_duplicates()return cycle_datadef get_collect(dataset):start = time. clock()#獲取單個省市區(qū)的文檔collect_data = pd.DataFrame([])ssq=list(set(dataset['省市區(qū)']))for v, word in enumerate(ssq):single_data = dataset[dataset['省市區(qū)'] == word]print("循環(huán)第",v,"個省市區(qū)地址為:",word,",當(dāng)前此區(qū)地址有:",len(single_data),",當(dāng)前計算進度為:{:.1f}%" .format(v*100/len(ssq)))cycle_data = cycle_first(single_data)collect_data = collect_data.append(cycle_data)#將每個市區(qū)得到的結(jié)果放入一張表print("Time: %s" %time.ctime())print("-----------------------------------------------------------------------")print("Time used:",(time.clock() - start), "s")return collect_data
我們最終只需要調(diào)用總函數(shù),就可以運行上述代碼,def run_(par = 0):#調(diào)用上述函數(shù)addr_df = read_data()dataset_1, dataset_2 = get_dataset(addr_df)#dataset. to_csv("../data/addr_data/document_address.csv", index =False)#dataset. to_csv( ". /data/addr_data/document_address. csv", index False)collect_data_1 = get_collect(dataset_1)collect_data_2 = get_collect(dataset_2)collect_data = pd.concat([collect_data_1, collect_data_2], axis=0)collect_data = collect_data[collect_data["相似度"]>=par].sort_values(by=["相似度"], ascending=[False])collect_data["相似度"] = collect_data["相似度"].apply(lambda x: ('%.2f' % x))return collect_data
可以看到,其實整個代碼運行的速度很快,2000多條地址,5秒就通過我們自己組合起來的算法計算完成。我們可以打印一下前5行結(jié)果,看一下相似度計算的結(jié)果,肉眼觀察一下結(jié)果如何:In [23]: collect_data = run_(par = 0.1)Time used: 0.2949850000000005 s0 個省市區(qū)地址為: 山東省青島市嶗山區(qū) ,當(dāng)前此區(qū)地址有: 5 ,當(dāng)前計算進度為:0.0%Loading model cost 0.633 seconds.Prefix dict has been built succesfully.Time: Thu Mar 5 21:52:31 2020-----------------------------------------------------------------------1 個省市區(qū)地址為: 廣東省珠海市金灣區(qū) ,當(dāng)前此區(qū)地址有: 4 ,當(dāng)前計算進度為:0.5%Time: Thu Mar 5 21:52:31 2020...97 個省市區(qū)地址為: 四川省自貢市 ,當(dāng)前此區(qū)地址有: 2 ,當(dāng)前計算進度為:98.0%Time: Wed Mar 4 16:19:32 2020-----------------------------------------------------------------------98 個省市區(qū)地址為: 山東省聊城市 ,當(dāng)前此區(qū)地址有: 2 ,當(dāng)前計算進度為:99.0%Time: Wed Mar 4 16:19:32 2020-----------------------------------------------------------------------Time used: 5.461850999999999 s
每一行都在同一個省市區(qū)下面,那么最后的地址判斷,我們看到還是準(zhǔn)確的,基本上都識別出來了,特別是相似度為0.9的那個幾組。四、構(gòu)造節(jié)點表和關(guān)系表
構(gòu)造節(jié)點表和關(guān)系表、以及使用neo4j-admin工具導(dǎo)入數(shù)據(jù),我們可以看下官網(wǎng)要求的數(shù)據(jù)格式,以及導(dǎo)入語句的要求:官網(wǎng)網(wǎng)址如下:https://neo4j.com/docs/operations-manual/4.0/tutorial/import-tool/添加圖片注釋,不超過 140 字(可選)為了要將結(jié)果數(shù)據(jù)導(dǎo)入到neo4j中,我們要加工好節(jié)點表和關(guān)系,我們順勢采用這個結(jié)果。接下來,我們需要在電腦上裝neo4j,假設(shè)你已經(jīng)部署了neo4j。我們先看ne4j是否已經(jīng)在開啟狀態(tài),#建表:一張節(jié)點表,一張關(guān)系表df = pd.read_excel("../public_company.xlsx", dtype={'公司代碼': 'str'})df_node = df[['公司代碼', '公司簡稱', '公司全稱', '注冊地址', '所屬行業(yè)']]df_node = df_node.rename(columns = {"公司代碼": ":ID"})df_node.to_csv("/../node.csv", index =False)df_rela = collect_data[collect_data["相似度"]>= 0.6]df_rela = df_rela[["目標(biāo)地址代碼", "被比較地址代碼", "相似度"]]df_relation = df_rela.rename(columns = {"目標(biāo)地址代碼": ":START_ID", "被比較地址代碼": ":END_ID", "相似度":":TYPE"})df_relation.to_csv("../relationship.csv", index = False)
發(fā)現(xiàn)已經(jīng)正在運行了,先停止掉,neo4j社區(qū)版,只有再關(guān)掉圖數(shù)據(jù)庫的時候,才能導(dǎo)入數(shù)據(jù)bogon:bin mbp$ ./neo4j statusNeo4j is running at pid 11074
停掉圖數(shù)據(jù)庫以后,我們還要進去database,刪掉之前存在graph.db,才能導(dǎo)入數(shù)據(jù),否則,導(dǎo)入會報錯。bogon:bin mbp$ ./neo4j stopStopping Neo4j.. stopped
bogon:bin mbp$ cd /Users/mbp/neo4j-community-3.5.4/data/databasesbogon:databases mbp$ rm -rf graph.dbbogon:databases mbp$ cd /Users/mbp/neo4j-community-3.5.4/binbogon:bin mbp$ ./neo4j-admin import --mode=csv --database=graph.db --nodes:公司 "/Users/mbp/neo4j-community-3.5.4/import/node.csv" --relationships:地址相似 "/Users/mbp/neo4j-community-3.5.4/import/relationship.csv" --ignore-duplicate-nodes=true --ignore-missing-nodes=trueNeo4j version: 3.5.4Importing the contents of these files into /Users/mbp/neo4j-community-3.5.4/data/databases/graph.db:Nodes::公司/Users/mbp/neo4j-community-3.5.4/import/node.csvRelationships::地址相似/Users/mbp/neo4j-community-3.5.4/import/relationship.csvAvailable resources:Total machine memory: 8.00 GBFree machine memory: 54.28 MBMax heap memory : 1.78 GBProcessors: 4Configured max memory: 5.60 GBHigh-IO: true...(1/4) Node import 2020-03-03 12:43:15.718+0800Estimated number of nodes: 5.30 kEstimated disk space usage: 1.78 MBEstimated required memory usage: 1020.07 MB-......... .......... .......... .......... .......... 5% ?62ms.......... .......... .......... .......... .......... 10% ?0ms............. .......... .......... .......... .......... 95% ?0ms.......... .......... .......... .......... .......... 100% ?1ms(2/4) Relationship import 2020-03-03 12:43:16.205+0800Estimated number of relationships: 216.00Estimated disk space usage: 7.17 kBEstimated required memory usage: 1.00 GB.......... .......... .......... .......... .......... 5% ?45ms.......... .......... .......... .......... .......... 10% ?0ms............. .......... .......... .......... .......... 95% ?0ms.......... .......... .......... .......... .......... 100% ?0ms(3/4) Relationship linking 2020-03-03 12:43:16.257+0800Estimated required memory usage: 1020.03 MB-......... .......... .......... .......... .......... 5% ?34ms............. .......... .......... .......... .......... 90% ?0ms.......... .......... .......... .......... .......... 95% ?0ms.......... .......... .......... .......... .........(4/4) Post processing 2020-03-03 12:43:16.398+0800Estimated required memory usage: 1020.01 MB-......... .......... .......... .......... .......... 5% ?55ms.......... .......... .......... .......... .......... 10% ?0ms............. .......... .......... .......... .......... 100% ?0msIMPORT DONE in 1s 261ms.Imported:2214 nodes216 relationships8856 propertiesPeak memory usage: 1.00 GBbogon:bin mbp$
然后再次開啟neo4j圖數(shù)據(jù)庫,
bogon:bin mbp$ ./neo4j startActive database: graph.dbDirectories in use:home: /Users/mbp/neo4j-community-3.5.4config: /Users/mbp/neo4j-community-3.5.4/conflogs: /Users/mbp/neo4j-community-3.5.4/logsplugins: /Users/mbp/neo4j-community-3.5.4/pluginsimport: /Users/mbp/neo4j-community-3.5.4/importdata: /Users/mbp/neo4j-community-3.5.4/datacertificates: /Users/mbp/neo4j-community-3.5.4/certificatesrun: /Users/mbp/neo4j-community-3.5.4/runStarting Neo4j.Started neo4j (pid 11074). It is available at http://localhost:7474/There may be a short delay until the server is ready.See /Users/mbp/neo4j-community-3.5.4/logs/neo4j.log for current status.
我們打開瀏覽器,輸入網(wǎng)址?localhost:7474/browser/
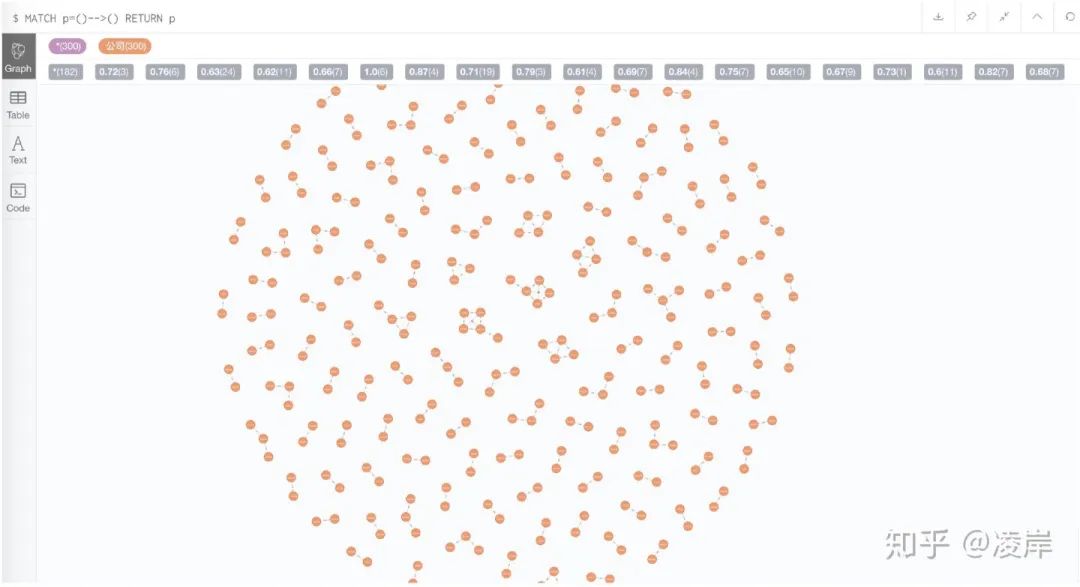
我們看到節(jié)點和關(guān)系以及屬性都成功導(dǎo)入了,標(biāo)簽也導(dǎo)入了。
一共有2214個節(jié)點,219個關(guān)系,其中節(jié)點的屬性為 公司全稱、公司簡稱、所屬行業(yè)、注冊地址。
實際上關(guān)系做成這樣,我們是不建議這樣做的,因為目前我們的數(shù)字種類不多,neo4j不會報錯,實際上他的官網(wǎng)有要求,關(guān)系總的種類大于6萬多條導(dǎo)入時候會報錯。
我們在網(wǎng)頁端輸入cypher語句,看一下節(jié)點與節(jié)點之間的效果:
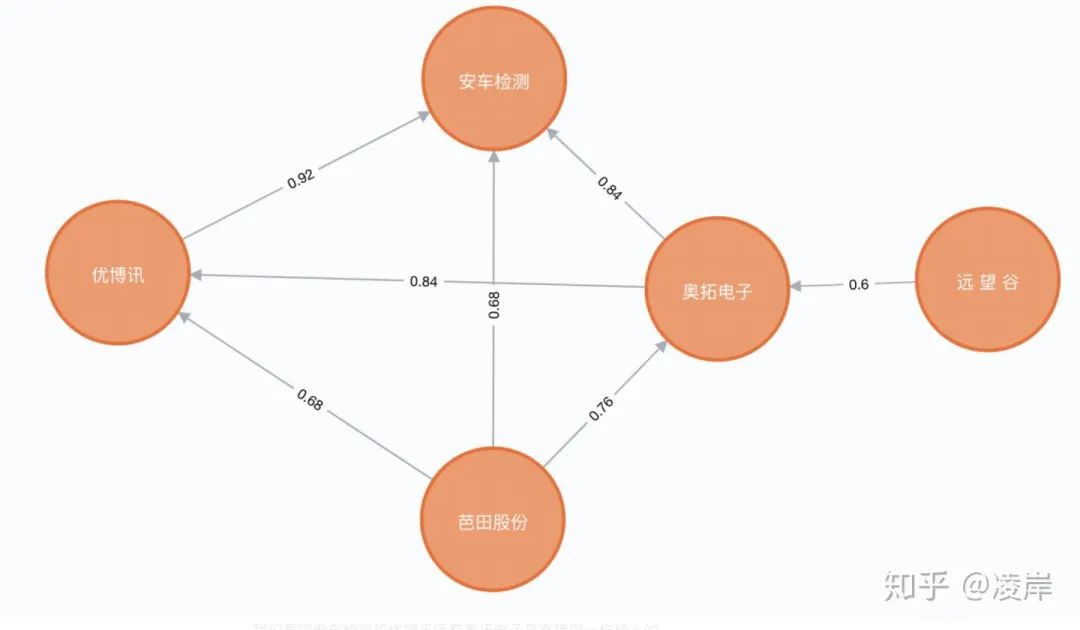
MATCH p=()-->() RETURN p我們選取其中一個小強連通閉環(huán)圖看一下:
我們看到安車檢測和優(yōu)博訊還有奧拓電子是直接同一棟樓上的。
雖然安車檢測與芭田股份以及遠望谷所填寫的地址貌似看起來不在一起,但是發(fā)現(xiàn)他們?nèi)慷际窃?聯(lián)合總部大廈的。
題外話,如果這些節(jié)點是 申請小額貸款的客戶,他們地址高度相似,集中在同一個小區(qū),在關(guān)系圖譜上面,他們被通過地址相似的方式計算出來,有一個強連通圖,那么是否他們有團伙欺詐的嫌疑?我認(rèn)為這是一個很好的應(yīng)用場景。
···? END? ···
評論
圖片
表情