
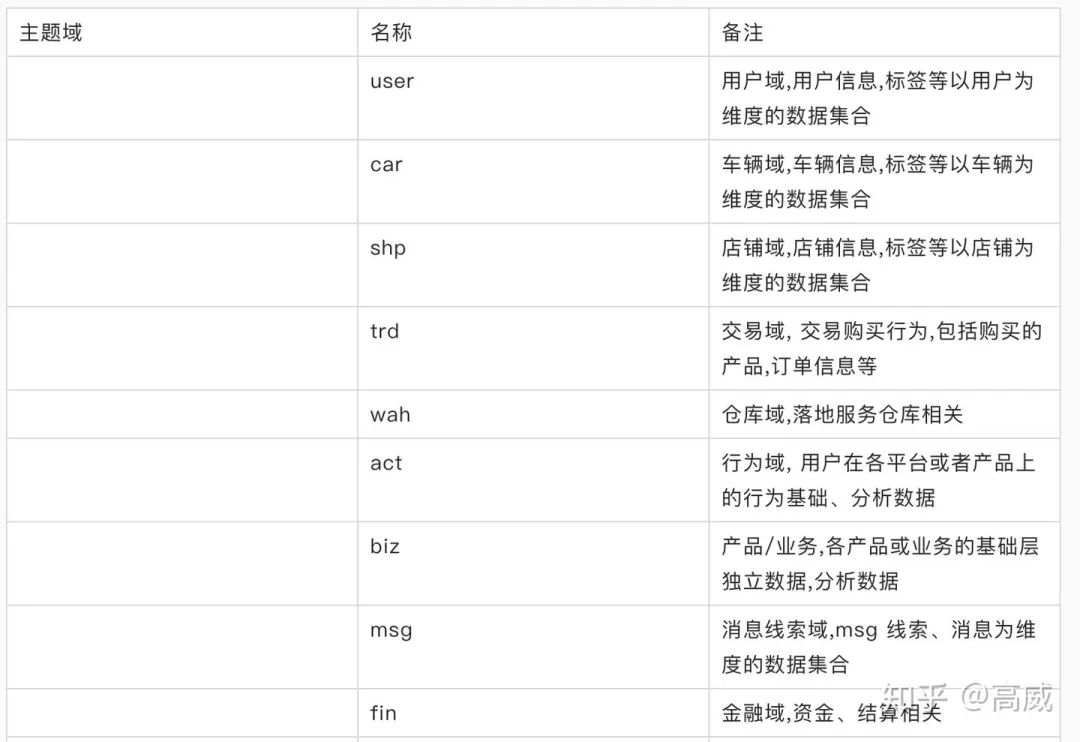
淺談數(shù)倉模型(維度建模)
背景
數(shù)據(jù)倉庫的核心是展現(xiàn)層和提供優(yōu)質(zhì)的服務(wù)。ETL 及其規(guī)范、分層等所做的一切都是為了一個更清晰易用的展現(xiàn)層。
數(shù)倉架構(gòu)的原則:
1、底層業(yè)務(wù)的數(shù)據(jù)驅(qū)動為導(dǎo)向同時結(jié)合業(yè)務(wù)需求驅(qū)動
2、便于數(shù)據(jù)分析
屏蔽底層復(fù)雜業(yè)務(wù)
簡單、完整、集成的將數(shù)據(jù)暴露給分析層
3、底層業(yè)務(wù)變動與上層需求變動對模型沖擊最小化
業(yè)務(wù)系統(tǒng)變化影響削弱在基礎(chǔ)數(shù)據(jù)層(資金訂單改造)
結(jié)合自上而下的建設(shè)方法削弱需求變動對模型的影響
數(shù)據(jù)水平層次清晰化
3、高內(nèi)聚松耦合
主題之內(nèi)或各個完整意義的系統(tǒng)內(nèi)數(shù)據(jù)的高內(nèi)聚
主題之間或各個完整意義的系統(tǒng)間數(shù)據(jù)的松耦合
4、構(gòu)建倉庫基礎(chǔ)數(shù)據(jù)層
使得底層業(yè)務(wù)數(shù)據(jù)整合工作與上層應(yīng)用開發(fā)工作相隔離,為倉庫大規(guī)模開發(fā)奠定基礎(chǔ)
倉庫層次更加清晰,對外暴露數(shù)據(jù)更加統(tǒng)一
數(shù)倉模型不只是考慮如何設(shè)計和實(shí)現(xiàn)功能,設(shè)計原則應(yīng)該從訪問性能、數(shù)據(jù)成本、使用成本、數(shù)據(jù)質(zhì)量、擴(kuò)展性來考慮。
如何搭建一個好的數(shù)據(jù)倉庫:
數(shù)倉設(shè)計的3個維度:
當(dāng)前主流建模方法為:ER模型、維度模型。
1、ER模型常用于OLTP數(shù)據(jù)庫建模,應(yīng)用到構(gòu)建數(shù)倉時更偏重數(shù)據(jù)整合, 站在企業(yè)整體考慮,將各個系統(tǒng)的數(shù)據(jù)按相似性一致性、合并處理,為數(shù)據(jù)分析、決策服務(wù),但并不便于直接用來支持分析。缺陷:需要全面梳理企業(yè)所有的業(yè)務(wù)和數(shù)據(jù)流,周期長,人員要求高。
2、維度建模是面向分析場景而生,針對分析場景構(gòu)建數(shù)倉模型;重點(diǎn)關(guān)注快速、靈活的解決分析需求,同時能夠提供大規(guī)模數(shù)據(jù)的快速響應(yīng)性能。針對性強(qiáng),主要應(yīng)用于數(shù)據(jù)倉庫構(gòu)建和OLAP引擎低層數(shù)據(jù)模型。優(yōu)點(diǎn):不需要完整的梳理企業(yè)業(yè)務(wù)流程和數(shù)據(jù),實(shí)施周期根據(jù)主題邊界而定,容易快速實(shí)現(xiàn)demo,而且相對來說便于理解、提高查詢性能、對稱并易擴(kuò)展。
作為大數(shù)據(jù)板塊,數(shù)據(jù)來源更加廣泛,針對的業(yè)務(wù)域也更加寬廣,所以維度建模相對來說更加靈活并適用。
在討論維度建模之前,關(guān)注數(shù)倉和BI的基本目標(biāo)是非常有意義的,在做日常的數(shù)據(jù)需求的時候,經(jīng)常會遇到如下幾個痛點(diǎn):
收集了海量數(shù)據(jù),不知道如何去做ETL;
不同來源的數(shù)據(jù)該如何去聚合;
如何方便業(yè)務(wù)人員快速方便的獲取數(shù)據(jù);
如何定義重要的數(shù)據(jù)指標(biāo);
如何確保數(shù)據(jù)準(zhǔn)確性;
數(shù)據(jù)如何支持決策;
基于上面的痛點(diǎn),就需要搭建一套DW/BI系統(tǒng)(當(dāng)然現(xiàn)在市面上有很多類似的產(chǎn)品,例如:如:QuickBI、GrowingIO、神策、猛犸等等),但是對于公司而言,適合自己的才是最好的,大部分公司選擇自己搭建或者利用開源的軟件(例如MateBase),這個系統(tǒng)必須滿足:
DW/BI系統(tǒng)能夠方便的存儲信息(或者說能跟現(xiàn)在主流的數(shù)據(jù)庫打通)。也就是說系統(tǒng)展現(xiàn)的內(nèi)容必須是容易理解的,對于業(yè)務(wù)人員必須直觀而且好操作,數(shù)據(jù)結(jié)構(gòu)和標(biāo)示必須符合業(yè)務(wù)思維過程和詞匯,用戶能夠以各種形式切割和分析數(shù)據(jù),同時能夠快速的將查詢結(jié)果反饋。
DW/BI系統(tǒng)必須以一致性的形式展現(xiàn)信息(指標(biāo)的唯一性)。也就是說數(shù)據(jù)必須是可信的,同一指標(biāo)定義在不同的數(shù)據(jù)源中,所含的意義必須相同,既同名同意性。
DW/BI系統(tǒng)能夠適應(yīng)變化(模塊的低耦合)。當(dāng)用戶需求、業(yè)務(wù)維度需要調(diào)整的調(diào)整的時候,設(shè)計的DW模型必須能夠兼容這些變化,已經(jīng)存在數(shù)據(jù)和指標(biāo)不應(yīng)該被破壞或修改,就算一些指標(biāo)的調(diào)整,也要以適當(dāng)?shù)姆绞矫枋鲎兓τ脩敉耆该鳌?/p>
DW/BI系統(tǒng)必須保證數(shù)據(jù)安全(數(shù)據(jù)安全)。能展示的數(shù)據(jù)必須是統(tǒng)計的結(jié)果數(shù)據(jù),一些詳單展現(xiàn)和下載必須和平臺的權(quán)限系統(tǒng)掛鉤,避免數(shù)據(jù)泄漏。
DW/BI系統(tǒng)成功的標(biāo)示是業(yè)務(wù)群體接收并使用,而且必須配套一個展現(xiàn)模塊的監(jiān)控系統(tǒng),能夠讓產(chǎn)品方知道各個模塊的使用情況,對一些訪問量比較少的模塊可以適當(dāng)?shù)恼{(diào)整和優(yōu)化。
介紹
DW/BI架構(gòu):
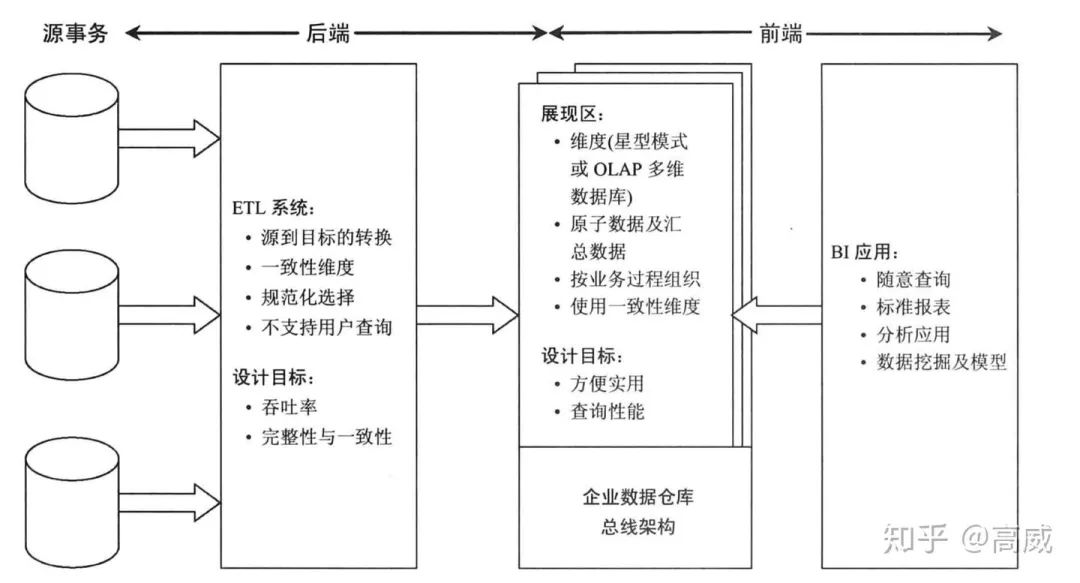
源事務(wù):業(yè)務(wù)庫或者日志等各個方面的數(shù)據(jù)源,一般不維護(hù)歷史信息。
ETL:目的是構(gòu)建和加載數(shù)據(jù)到展現(xiàn)區(qū)的目標(biāo)維度模型中,劃分維度和事實(shí)。
模型:圍繞業(yè)務(wù)過程度量事件進(jìn)行構(gòu)建,為滿足用戶無法預(yù)估的需求,必須包含詳細(xì)的原子數(shù)據(jù)。
為避免數(shù)據(jù)的冗余存儲造成的浪費(fèi)和低效,并方便多業(yè)務(wù)部門查詢方便以及同一指標(biāo)的數(shù)據(jù)準(zhǔn)確性和業(yè)務(wù)的擴(kuò)展性,一般采取以下的架構(gòu)模式:
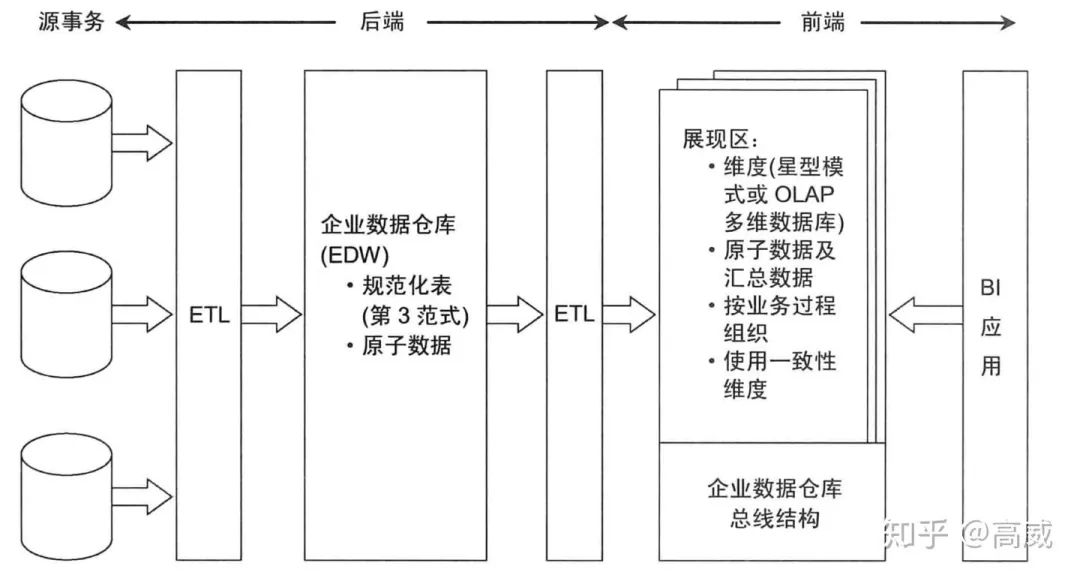
維度建模:
用于度量的事實(shí)表,事實(shí)表一般會有兩個或者多個外健與維度表的主鍵進(jìn)行關(guān)聯(lián)。事實(shí)表的主鍵一般是組合健,表達(dá)多對多的關(guān)系。
用于描述環(huán)境的維度表,單一主鍵。維度表的屬性是所有查詢約束和報表標(biāo)示的來源。維度提供數(shù)據(jù)的入口點(diǎn),提供所有DW/BI分析的最終標(biāo)識和分組。
所以維度建模表示每個業(yè)務(wù)過程包含的事實(shí)表,事實(shí)表里面存儲事件的數(shù)值化度量,圍繞事實(shí)表的是多個維度表,維度表包含事件發(fā)生的實(shí)際存在的文本環(huán)境。
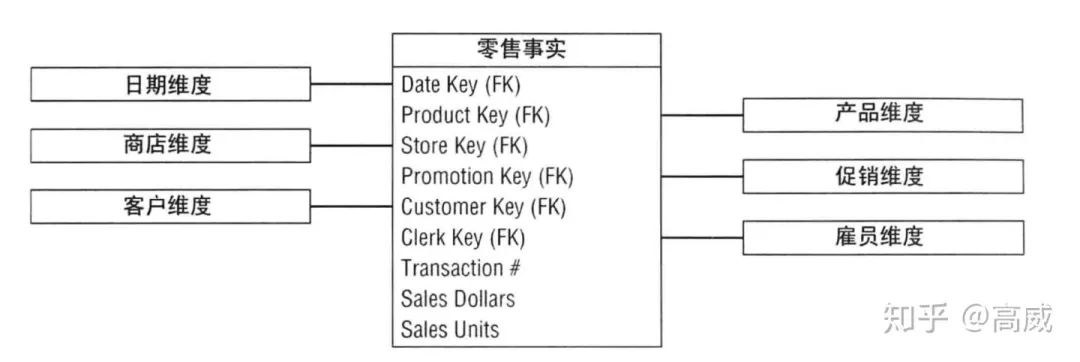
從圖表中能看出來,維度模型(星型模型)比較簡單,而且適于變化,各個維度的地位相同。可根據(jù)業(yè)務(wù)情況進(jìn)行新增或者修改(只要維度的單一值已經(jīng)存在事實(shí)表中)。
雪花模型:
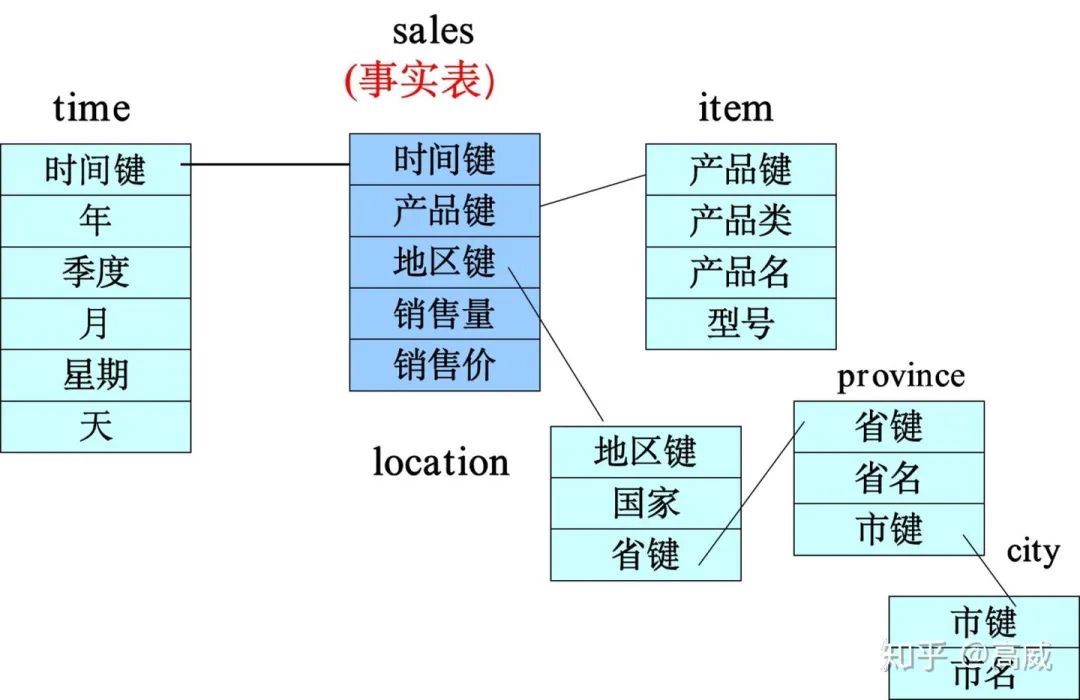
維度建模的主要是4個主要決策:
1、選擇業(yè)務(wù)過程
業(yè)務(wù)過程是通常表示的是業(yè)務(wù)執(zhí)行的活動,與之相關(guān)的維度描述和每個業(yè)務(wù)過程事件關(guān)聯(lián)的描述性環(huán)境。
通常由某個操作型系統(tǒng)支持,例如:訂單系統(tǒng)。
業(yè)務(wù)過程建立或獲取關(guān)鍵性能度量。
一系列過程產(chǎn)生一系列事實(shí)表。
2、聲明粒度
粒度傳遞的是與事實(shí)表度量有關(guān)的細(xì)節(jié)級別。
精確定義某個事實(shí)表的每一行表示什么。
對事實(shí)表的粒度要達(dá)成共識。
3、確認(rèn)維度
健壯的維度集合來粉飾事實(shí)表。
維度表示承擔(dān)每個度量環(huán)境中所有可能的單值描述符。
4、確認(rèn)事實(shí)
不同粒度的事實(shí)必須放在不同的事實(shí)表中。
事實(shí)表的設(shè)計完全依賴物理活動,不受最終報表的影響。
事實(shí)表通過外健關(guān)聯(lián)與之相關(guān)的維度。
查詢操作主要是基于事實(shí)表開展計算和聚合。
其中粒度是非常重要的,粒度用于確定事實(shí)表的行表示什么,建議從關(guān)注原子級別的粒度數(shù)據(jù)開始設(shè)計,因?yàn)樵恿6饶軌虺惺軣o法預(yù)估的用戶查詢,而且原子數(shù)據(jù)可以以各種可能的方式進(jìn)行上卷,而一旦選擇了高粒度,則無法滿足用戶下鉆細(xì)節(jié)的需求。
事實(shí)是整個維度建模的核心,其中雪花模型或者星型模型都是基于一張事實(shí)表通過外健關(guān)聯(lián)維表進(jìn)行擴(kuò)展,生成一份能夠支撐可預(yù)知查詢需求的模型寬表,而且最后的查詢也是落在事實(shí)表中進(jìn)行。
目前常見的維度模型:
星型模型
每一個維表都與都與事實(shí)表相關(guān)聯(lián)。數(shù)據(jù)冗余量較大
雪花模型
有些維表可能不與事實(shí)表直接關(guān)聯(lián),而是通過其他維表關(guān)聯(lián)到事實(shí)表。數(shù)據(jù)冗余量較小
星座模型
由多個事實(shí)表相組合,維表是公共的。企業(yè)中一般都是星座模型
注意:
維度表的唯一主鍵應(yīng)該是代理健而不是來自系統(tǒng)的標(biāo)示符,也就是所謂的自然健,因?yàn)樽匀绘I通常具有一定的業(yè)務(wù)含義,但日久天長,這些信息是有可能發(fā)生變化的,而代理健可以提高關(guān)聯(lián)效率并將關(guān)系數(shù)據(jù)庫設(shè)計和業(yè)務(wù)的解耦。
維度表和事實(shí)表關(guān)聯(lián)的每個連接應(yīng)該基于無含義的整數(shù)代理健。
固定深度層次在維度表中應(yīng)該扁平化,規(guī)范化的雪花模型不利于多屬性瀏覽,而且大量的表和連接操作會影響性能。
非完全獨(dú)立的維度應(yīng)該合并為一個維度,將同一層次的元素標(biāo)示為事實(shí)表中不同維度是錯誤的,會增加查詢和存儲負(fù)擔(dān),最后變成蜈蚣表,例如:日維度、周維度、月維度等可以合并為一個周期維度。
案例
維度建模是一個迭代設(shè)計過程,設(shè)計工作從總線矩陣中抽取實(shí)體級別的初始圖形化模型開始,詳細(xì)建模過程要深入定義、資源、關(guān)系、數(shù)據(jù)質(zhì)量問題以及每張表的數(shù)據(jù)轉(zhuǎn)換,主要目標(biāo)是建立滿足用戶需求的模型,校驗(yàn)可加載到模型中的數(shù)據(jù),為ETL提供明確的方向。
這是一個以客戶創(chuàng)建為事實(shí)表的售前流程的雪花模型。
事實(shí)表:客戶創(chuàng)建信息表
維度表:銷售信息表、店鋪信息表、跟進(jìn)表/約見表/風(fēng)控通過表/訂單表的維度上卷。
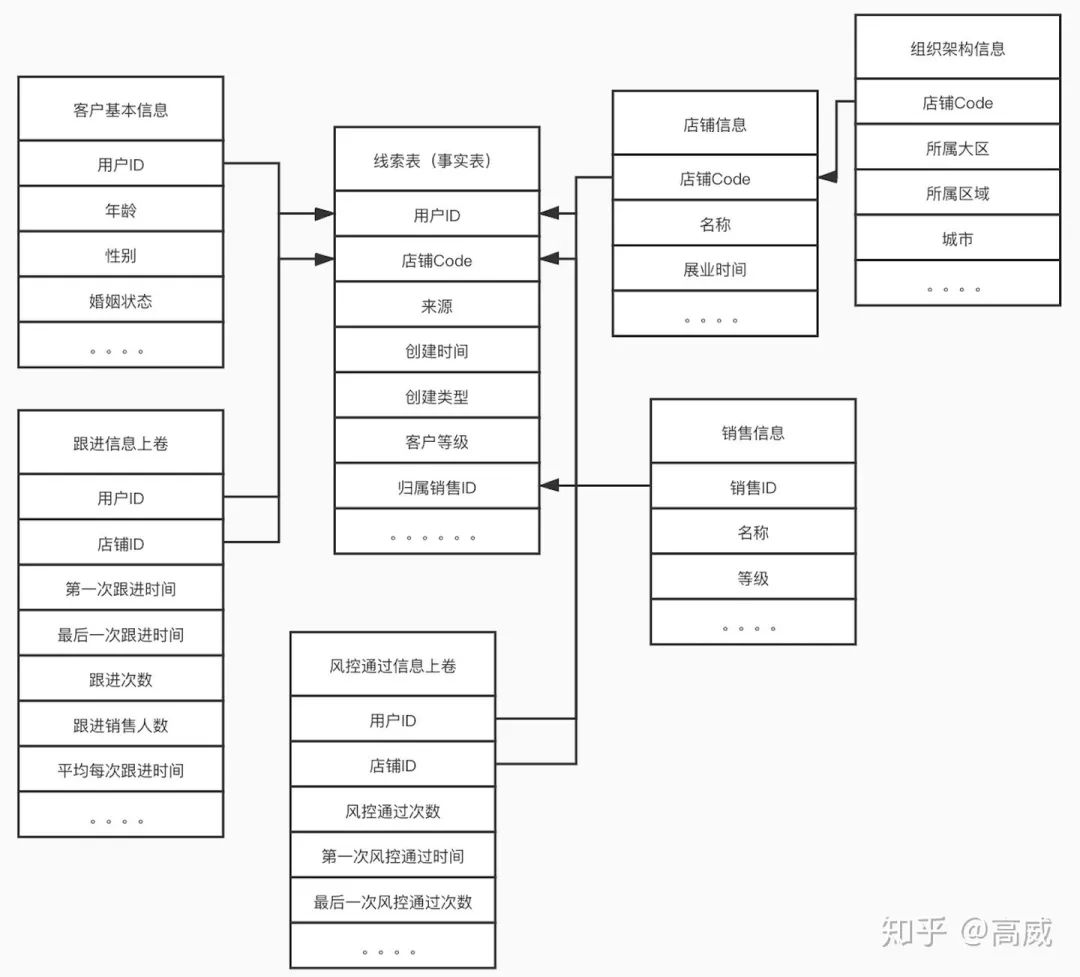
以上面的維度模型可以聚合出創(chuàng)建、跟進(jìn)、風(fēng)控等各個維度的上層展現(xiàn)的數(shù)據(jù)。
擴(kuò)展:實(shí)時即未來
目前不少公司都在嘗試以Flink、Kudu為基礎(chǔ)的實(shí)時數(shù)倉架構(gòu),里面的數(shù)倉分層模型和離線的數(shù)倉架構(gòu)基本相同。
下圖為實(shí)時數(shù)倉架構(gòu),離線和實(shí)時的差不多,畫圖好難 ,所以在網(wǎng)上拷貝了這個圖,如侵刪,具體實(shí)時的架構(gòu)圖見:
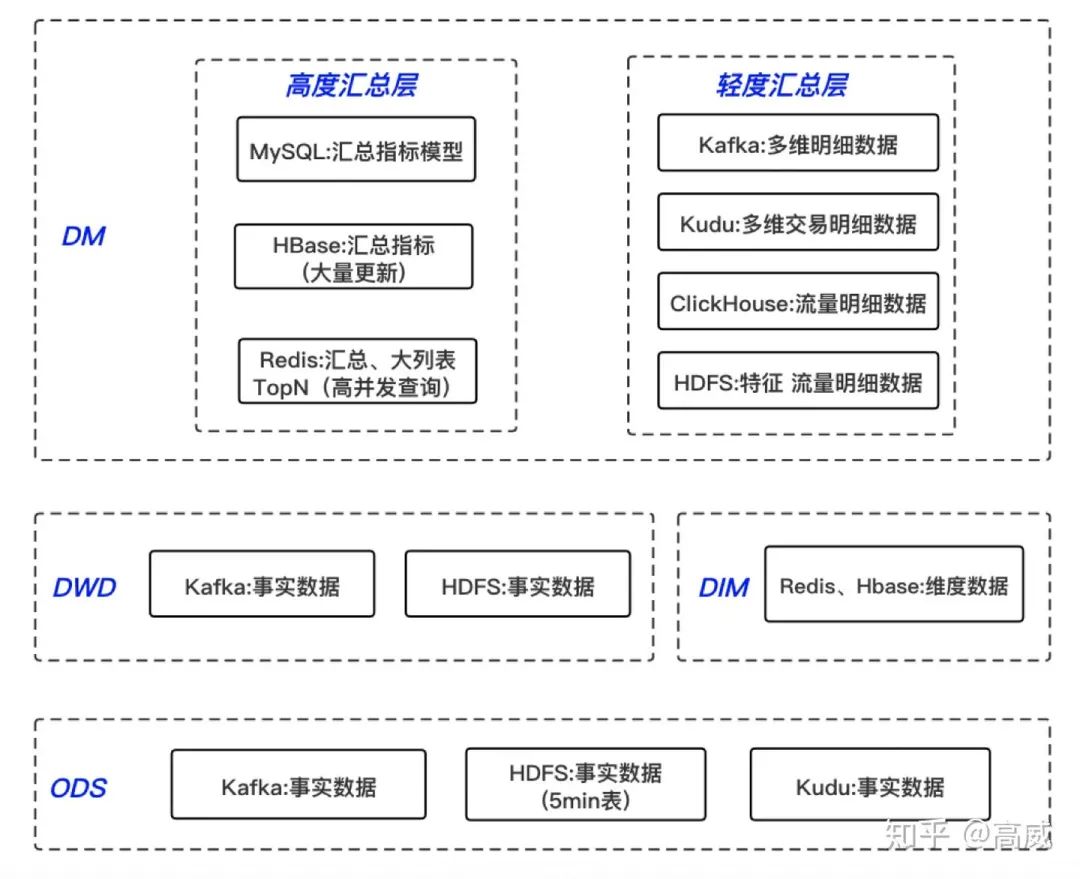
1、ODS原始層是存放原始數(shù)據(jù),主要是埋點(diǎn)數(shù)據(jù)(日志數(shù)據(jù))和業(yè)務(wù)操作數(shù)據(jù)(binlong),數(shù)據(jù)源主要是Mysql、HDFS、Kafka等
2、DW中間層主要存放ETL和主題匯總之后的中間層數(shù)據(jù),這塊又分為:
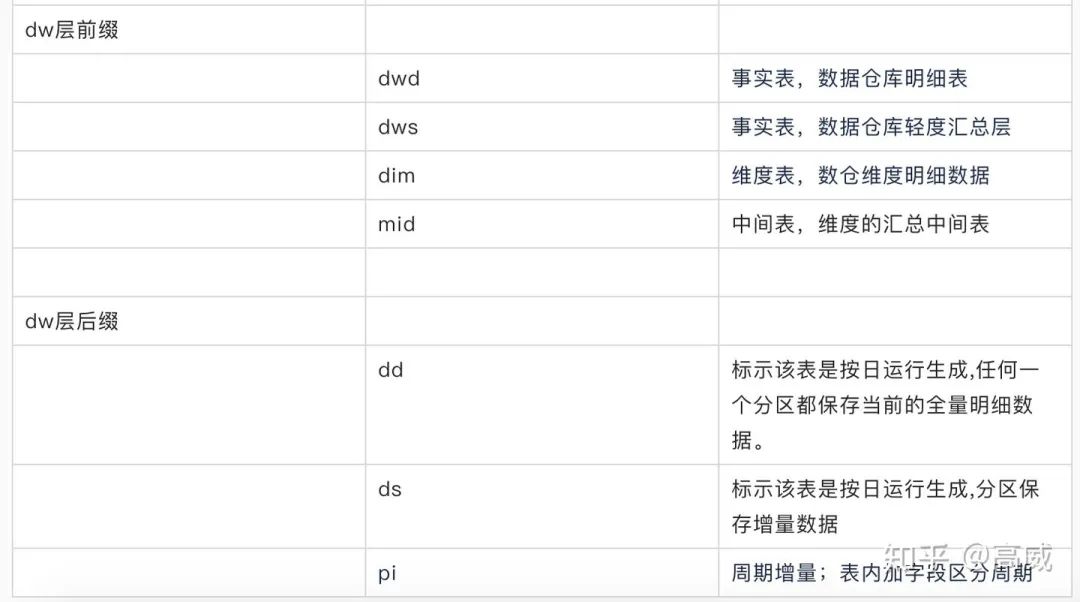
DWD:事實(shí)表(data warehouse detail) 數(shù)據(jù)倉庫明細(xì)表,以業(yè)務(wù)過程作為建模驅(qū)動,基于每個具體的業(yè)務(wù)過程特點(diǎn),構(gòu)建最細(xì)粒度的明細(xì)層事實(shí)表。
DWS:事實(shí)表 (data warehouse summary) 數(shù)據(jù)倉庫輕度匯總層,按照各個業(yè)務(wù)域進(jìn)行輕度匯總成分析某一個主題域的服務(wù)數(shù)據(jù),一般是寬表。
DIM:維度表,公共維度層,基于維度建模理念思想,建立整個業(yè)務(wù)過程的一致性維度,主要使用 MySQL、Hbase、Redis 三種存儲引擎,對于維表數(shù)據(jù)比較少的情況可以使用 MySQL,對于單條數(shù)據(jù)大小比較小,查詢 QPS 比較高的情況,可以使用 Redis 存儲,降低機(jī)器內(nèi)存資源占用,對于數(shù)據(jù)量比較大,對維表數(shù)據(jù)變化不是特別敏感的場景,可以使用HBase 存儲。
3、DM數(shù)據(jù)集市層,以數(shù)據(jù)域+業(yè)務(wù)域的理念建設(shè)公共匯總層,對于DM層比較復(fù)雜,需要綜合考慮對于數(shù)據(jù)落地的要求以及具體的查詢引擎來選擇不同的存儲方式,分為輕度匯總層和高度匯總層。
輕度匯總層以寬表的形式存在,主要是針對業(yè)務(wù)域進(jìn)行快速方便的查詢;
高度匯總層由明細(xì)數(shù)據(jù)層或輕度匯總層通過聚合計算后寫入到存儲引擎中,產(chǎn)出一部分實(shí)時數(shù)據(jù)指標(biāo)需求,靈活性比較差,主要做大屏展現(xiàn)。
4、理論上上面還一APP層,應(yīng)用層,主要是通過這幾層之后,生成輕度或者高度匯總的數(shù)據(jù),然后根據(jù)業(yè)務(wù)域進(jìn)行接口封裝提供給上層使用。
但是實(shí)時數(shù)倉面臨以下幾個實(shí)施關(guān)鍵點(diǎn):
端到端數(shù)據(jù)延遲、數(shù)據(jù)流量的監(jiān)控;
故障的快速恢復(fù)能力;
數(shù)據(jù)的回溯處理,系統(tǒng)支持消費(fèi)指定時間段內(nèi)的數(shù)據(jù);
實(shí)時數(shù)據(jù)從實(shí)時數(shù)倉中查詢,T+1數(shù)據(jù)借助離線通道修正;
業(yè)務(wù)數(shù)據(jù)質(zhì)量的實(shí)時監(jiān)控;
思考:
實(shí)時數(shù)倉架構(gòu)和數(shù)據(jù)中臺一樣,雖然都是屬于當(dāng)前比較熱門的概念,但是對于實(shí)時數(shù)倉的狂熱追求大可不必。
首先,在技術(shù)上幾乎沒有難點(diǎn),基于強(qiáng)大的開源中間件(例如:Flink、kudu等)實(shí)現(xiàn)實(shí)時數(shù)據(jù)倉庫的需求已經(jīng)變得沒有那么困難。
其次,實(shí)時數(shù)倉的建設(shè)一定是伴隨著業(yè)務(wù)的發(fā)展而發(fā)展,武斷的認(rèn)為實(shí)時數(shù)倉架構(gòu)最符合當(dāng)前公司的需求是不對的。實(shí)際情況中隨著業(yè)務(wù)的發(fā)展數(shù)倉的架構(gòu)變得沒有那么非此即彼。
最后,如何順暢的將傳統(tǒng)的離線數(shù)倉+實(shí)時鏈路處理流程升級到實(shí)時數(shù)倉架構(gòu)是個很大的問題,畢竟中間涉及到很多的數(shù)據(jù)模式、技術(shù)中間件、計算引擎都不太一樣。
常見的數(shù)倉命名規(guī)則:
前綴(ODS/DWD/MID)+主題域(user/shp)+業(yè)務(wù)類型+自定義表名+后綴(dd/ds/pi)
問題
維度建模的缺點(diǎn)
維度建模之前需要進(jìn)行大量的數(shù)據(jù)預(yù)處理,因此會導(dǎo)致大量的數(shù)據(jù)處理工作(ETL)。
當(dāng)業(yè)務(wù)發(fā)生變化,需要重新進(jìn)行維度的定義時,往往需要重新進(jìn)行維度數(shù)據(jù)的預(yù)處理。而在這些與處理過程中,往往會導(dǎo)致大量的數(shù)據(jù)冗余。
如果只是依靠單純的維度建模,不能保證數(shù)據(jù)來源的一致性和準(zhǔn)確性,而且在數(shù)據(jù)倉庫的底層,不是特別適用于維度建模的方法。
維度建模的領(lǐng)域主要適用與數(shù)據(jù)集市層,它的最大的作用其實(shí)是為了解決數(shù)據(jù)倉庫建模中的性能問題。維度建模很難能夠提供一個完整地描述真實(shí)業(yè)務(wù)實(shí)體之間的復(fù)雜關(guān)系的抽象方法。
當(dāng)前公司的數(shù)倉模型架構(gòu):
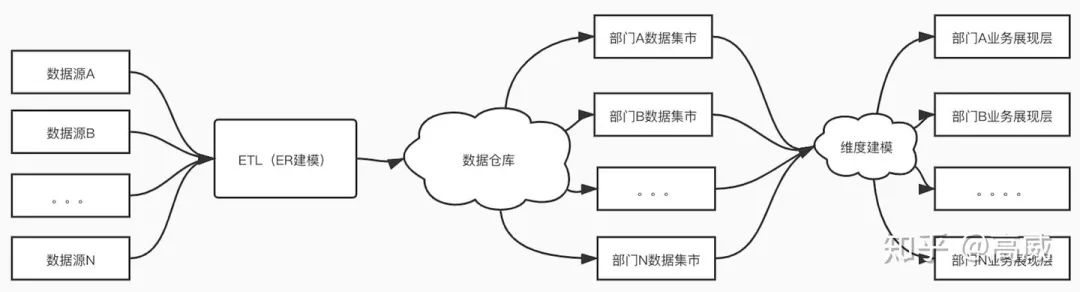
首先對ETL得到的數(shù)據(jù)進(jìn)行ER建模,關(guān)系建模,得到一個規(guī)范化的公司層面的數(shù)據(jù)倉庫模式。然后用這個中心倉數(shù)據(jù)庫為公司各部門建立基于維度建模的數(shù)據(jù)集市。
而維度建模都集中在各個DM層里面,也就是針對具體的業(yè)務(wù)線或者主題域,這樣緊緊圍繞著業(yè)務(wù)模型,可以直觀的反映出業(yè)務(wù)模型中的業(yè)務(wù)問題。
分層的誤區(qū)
數(shù)倉層內(nèi)部的劃分不是為了分層而分層,分層是為了解決 ETL 任務(wù)及工作流的組織、數(shù)據(jù)的流向、讀寫權(quán)限的控制、不同需求的滿足等各類問題。
業(yè)界較為通行的做法將整個數(shù)倉層又劃分成了 dwd、dwb、dws、dim、mid 等等很多層。然而我們卻始終說不清楚這幾層之間清晰的界限是什么,或者說我們能說清楚它們之間的界限,復(fù)雜的業(yè)務(wù)場景卻令我們無法真正落地執(zhí)行。
所以數(shù)據(jù)分層這塊一般來說三層是最基礎(chǔ)的:
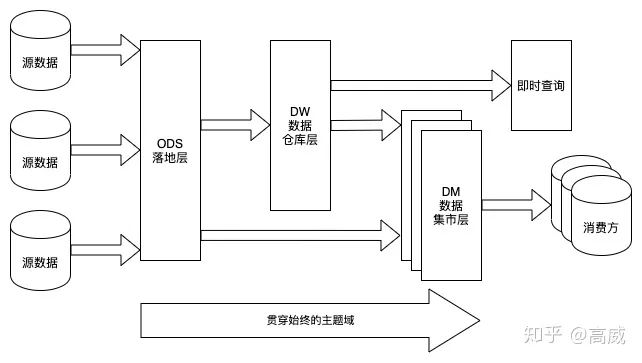
至于DW層如何進(jìn)行切分,是根據(jù)具體的業(yè)務(wù)需求和公司場景自己去定義,一般來說需要:
1、分層是解決數(shù)據(jù)流向和快速支撐業(yè)務(wù)的目的;
2、必須按照主題域和業(yè)務(wù)域進(jìn)行貫穿;
3、層級之間不可逆向依賴。
4、如果依賴ODS層數(shù)據(jù)可以完成數(shù)據(jù)支撐,那么業(yè)務(wù)方直接使用落地層這也有利于快速、低成本地進(jìn)行一些數(shù)據(jù)方面的探索和嘗試。
5、確定分層規(guī)范后,后續(xù)最好都遵循這個架構(gòu),約定成俗即可;
6、血緣關(guān)系、數(shù)據(jù)依賴、數(shù)據(jù)字典、數(shù)據(jù)命名規(guī)范等配套先行;
DW 內(nèi)的分層沒有最正確的,只有最適合你的。
寬表的誤區(qū)
在數(shù)倉層開始引入了寬表。所謂寬表,迄今為止并沒有一個明確的定義。通常做法是把很多的維度、事實(shí)上卷或者下鉆之后關(guān)聯(lián)到某一個事實(shí)表中,形成一張既包含了大量維度又包含了相關(guān)事實(shí)的表。
寬表的使用,有其一定的便利性。使用方不需要再去考慮跟維度表的關(guān)聯(lián),也不需要了解維度表和事實(shí)表是什么東西。
但是隨著業(yè)務(wù)的增長,我們始終無法預(yù)見性地設(shè)計和定義寬表究竟該冗余多少維度,也無法清晰地定義出寬表冗余維度的底線在哪里。
一個可能存在的情況是,為了滿足使用上的需求,要不斷地將維表中已經(jīng)存在的列增加到寬表中。這直接導(dǎo)致了寬表的表結(jié)構(gòu)頻繁發(fā)生變動。
目前我們所采用的做法是:
1、根據(jù)主題域和業(yè)務(wù)域,將某個業(yè)務(wù)的所有節(jié)點(diǎn)梳理清楚;
2、將關(guān)鍵節(jié)點(diǎn)的數(shù)據(jù)作為事實(shí)表依據(jù),然后橫向擴(kuò)充其他事實(shí)表上卷數(shù)據(jù)(包含一些統(tǒng)計指標(biāo)),同時縱向的添加該節(jié)點(diǎn)上一些主鍵對應(yīng)的維度;
3、寬表的涉及不依賴具體的業(yè)務(wù)需求而是根據(jù)整體業(yè)務(wù)線相匹配;
4、盡量用維度建模代替寬表;
為什么說盡量用維度建模代替寬表,就算字段和數(shù)據(jù)會冗余,維度建模的方式也會表全量數(shù)據(jù)的寬表模式較好,原因:
1、維度建模是以某一個既定的事實(shí)為依據(jù),既然是事實(shí)表,那么這塊的業(yè)務(wù)如果不變動的情況下,事實(shí)表的粒度基本不會改變;
2、事實(shí)表和維度表解耦,維度表的變更事實(shí)表基本不會影響,結(jié)果表也只需要回刷一下數(shù)據(jù)流程即可;
3、新增維度完全可以按照星型模型或者雪花模型動態(tài)添加新維度;
4、維度模型可以作為寬表的基礎(chǔ),一旦確定全部的數(shù)據(jù)流程,可以通過維度模型再生成對應(yīng)寬表進(jìn)行快速的業(yè)務(wù)支撐;
指標(biāo)管理
數(shù)倉模型中,最重要的模塊可能就是數(shù)據(jù)治理,我們在建立數(shù)倉分層的時候,雖然解決 ETL 任務(wù)及工作流的組織、數(shù)據(jù)的流向、讀寫權(quán)限的控制、不同需求的滿足等各類問題,但是在給業(yè)務(wù)方提供不同數(shù)據(jù)需求的情況下不可避免的會發(fā)生一下幾個問題:
1、指標(biāo)定義不夠清晰明確,兩個頁面上的指標(biāo)定義其實(shí)是不同的,但是展示給商家看到的可能是同一個中文名稱。又或者同樣一個含義的指標(biāo)在不同的界面上展示的名稱卻不相同,讓人產(chǎn)生歧義。
2、同一個指標(biāo)因?yàn)橛刹煌臄?shù)據(jù)開發(fā)同學(xué)來制作,可能會被重復(fù)開發(fā),不但造成資源浪費(fèi),還會造成維護(hù)困難。
3、對于需要新開發(fā)的指標(biāo),不僅缺少開發(fā)工具簡化開發(fā)流程,甚至該使用哪些表,不該使用哪些表很大程度上都要憑借數(shù)據(jù)開發(fā)同學(xué)與數(shù)倉同學(xué)的經(jīng)驗(yàn)。如果稍微馬虎一點(diǎn)或者缺乏經(jīng)驗(yàn),比如使用了某些業(yè)務(wù)域下特有的表或者不是由數(shù)倉提供的統(tǒng)一中間層的表就可能會使用錯誤的數(shù)據(jù),造成后期返工等情況。
而且在數(shù)據(jù)需求越來越多,數(shù)據(jù)中臺提供的指標(biāo)也日益豐富。但是指標(biāo)定義混亂,描述不清會嚴(yán)重影響數(shù)據(jù)的可信度和數(shù)據(jù)開發(fā)的成本,所以就需要搭建一個指標(biāo)系統(tǒng),來維護(hù)已有的數(shù)據(jù)指標(biāo),并為未來可能新增的指標(biāo)建立相應(yīng)的規(guī)范。
如何去建立好這個指標(biāo)庫或者指標(biāo)系統(tǒng)呢。
一般來說指標(biāo)系統(tǒng)主要分為:原子指標(biāo)和派生指標(biāo)
1、在數(shù)倉分層的時候,進(jìn)行維度建模,那么就必須指定好相應(yīng)的主題域和事實(shí)表處理的最小邏輯(也就是事實(shí)),那么在這個基礎(chǔ)上可以先定義原子指標(biāo)。
原子指標(biāo):原子指標(biāo)和度量含義相同,基于某一業(yè)務(wù)事件行為下的度量,是業(yè)務(wù)定義中不可再拆分的指標(biāo),具有明確業(yè)務(wù)含義的名詞 ,如支付金額。原子指標(biāo)描述的其實(shí)是一種指標(biāo)的類型,比如訂單支付金額,支付訂單數(shù),下單訂單數(shù),PV,UV 等等。但是僅僅一個原子指標(biāo)是不能直接取數(shù)的。
但業(yè)務(wù)方更關(guān)心的指標(biāo),是有實(shí)際業(yè)務(wù)含義,可以直接取數(shù)據(jù)的指標(biāo)。比如店鋪近1天訂單支付金額就是一個派生指標(biāo),會被直接在產(chǎn)品上展示給商家看。這個指標(biāo)卻不能直接從數(shù)倉的統(tǒng)一中間層里取數(shù)(因?yàn)闆]有現(xiàn)成的事實(shí)字段,數(shù)倉提供的一般都是大寬表)。需要有一個橋梁連接數(shù)倉中間層和業(yè)務(wù)方的指標(biāo)需求,于是便有了派生指標(biāo)。
2、派生指標(biāo)=維度+原子指標(biāo)+修飾詞。當(dāng)維度,原子指標(biāo),修飾詞都確定的時候就可以唯一確定一個派生指標(biāo),同時給出具體數(shù)值。
例如:店鋪近1天訂單支付金額中店鋪是維度,近1天是一個時間類型的修飾詞,支付金額是一個原子指標(biāo)。
業(yè)務(wù)方制作每一個派生指標(biāo)都是通過選擇維度,原子指標(biāo),修飾詞三種元數(shù)據(jù)來定義的,相對于使用名稱來區(qū)別不同指標(biāo),更可以保證指標(biāo)的唯一性。如果2個派生指標(biāo)是不同的,那他們的組成部分一定會有區(qū)別,或是不同維度,或是不同原子指標(biāo),修飾詞。
所以在指標(biāo)管理的過程中,指標(biāo)庫給予每個指標(biāo)一個精確且唯一的定義。通過指標(biāo)庫可以快速且規(guī)范的查詢,開發(fā)和使用指標(biāo)。
指標(biāo)庫主要提供如下服務(wù):
通過設(shè)置指標(biāo)的組成要素來唯一精確定義每個指標(biāo)(派生指標(biāo))。
通過指標(biāo)在業(yè)務(wù)域內(nèi)唯一的性質(zhì),解決指標(biāo)重復(fù)定義,重復(fù)開發(fā),部分?jǐn)?shù)據(jù)對不上的問題。
通過將數(shù)倉中間層錄入指標(biāo)庫為新制作指標(biāo)提供指導(dǎo)性的 SQL 或庫表推薦。
打通其他各數(shù)據(jù)平臺:
打通數(shù)據(jù)開發(fā)平臺和統(tǒng)一數(shù)據(jù)服務(wù)平臺,為指標(biāo)的定義,調(diào)度,在線使用提供一條龍服務(wù),簡化開發(fā)流程。
打通數(shù)據(jù)資產(chǎn)管理平臺,沉淀指標(biāo)的資產(chǎn)價值。
打通 BI 平臺,提供拖拽維度,指標(biāo)生成報表的功能。
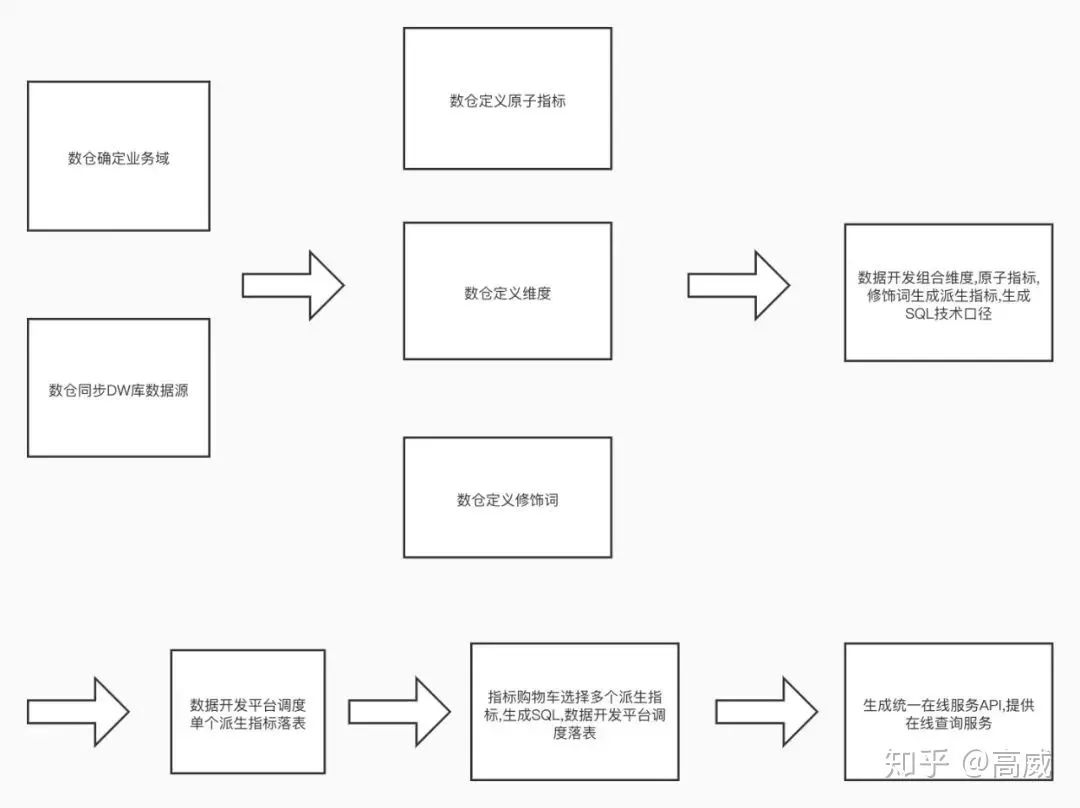
其中派生指標(biāo)的生成是通過:業(yè)務(wù)域+維度+原子指標(biāo)+修飾詞來唯一確定的。
在數(shù)倉搭建的時候,業(yè)務(wù)域、維度、原子指標(biāo)都是已經(jīng)明確的,而修飾詞是維度的某一些特殊的值,對應(yīng) SQL 中的 where 過濾條件。所以如果在數(shù)據(jù)產(chǎn)品的層面在某個業(yè)務(wù)域?qū)χ笜?biāo)數(shù)據(jù)定義、生產(chǎn)、使用等過程的流程規(guī)范化與平臺化,那么就能夠從源頭上解決上面出現(xiàn)的數(shù)據(jù)指標(biāo)不統(tǒng)一、重復(fù)開發(fā)、指標(biāo)體系不好維護(hù)的問題。