
CVPR 2020 論文合集-動(dòng)作識(shí)別篇
點(diǎn)擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
來(lái)源:我愛(ài)計(jì)算機(jī)視覺(jué)
本文盤(pán)點(diǎn)所有CVPR 2020?動(dòng)作識(shí)別(Action Recognition?)相關(guān)論文,該方向也常被稱為視頻分類(Video Classification?)。從后面的名字可以看出該任務(wù)就是對(duì)含人體動(dòng)作的視頻進(jìn)行分類。
(關(guān)于動(dòng)作檢測(cè)、分割、活動(dòng)識(shí)別等方向?qū)⒃诤罄m(xù)文章整理)
該部分既包含基于普通視頻的動(dòng)作識(shí)別,也包含基于深度圖和基于骨架的動(dòng)作識(shí)別。
因?yàn)橐曨l既包含空域信息,又包含時(shí)域信息,所以時(shí)空信息的融合、特征提取是該領(lǐng)域的重要方向。
因?yàn)橐曨l往往數(shù)據(jù)量大,信息冗余,是典型的計(jì)算密集型任務(wù),以往的方法往往(如3D CNN)計(jì)算代價(jià)很高,提高(訓(xùn)練/推斷)速度也是不少論文研究的方向。
特別值得一提的是斯坦福大學(xué)、MIT、谷歌發(fā)表的兩篇基于視頻的無(wú)監(jiān)督表示學(xué)習(xí),不僅可用于動(dòng)作識(shí)別,其可以看作為通用的視覺(jué)特征提取方法,相信會(huì)對(duì)未來(lái)的計(jì)算機(jī)視覺(jué)研究產(chǎn)生重要影響。
大家可以在:
http://openaccess.thecvf.com/CVPR2020.py
按照題目下載這些論文。
如果想要下載所有CVPR 2020論文,請(qǐng)點(diǎn)擊這里:
CVPR 2020 論文全面開(kāi)放下載,含主會(huì)和workshop
?? 動(dòng)作識(shí)別(Action Recognition)
時(shí)間金字塔網(wǎng)絡(luò)(TPN)用于動(dòng)作識(shí)別,可方便“即插即用”到2D和3D網(wǎng)絡(luò)中,顯著改進(jìn)動(dòng)作識(shí)別的精度。
Temporal Pyramid Network for Action Recognition
作者 |?Ceyuan Yang, Yinghao Xu, Jianping Shi, Bo Dai, Bolei Zhou
單位 | 香港中文大學(xué);商湯
代碼?|?Temporal Pyramid Network for Action Recognition
主頁(yè) |?https://decisionforce.github.io/TPN/
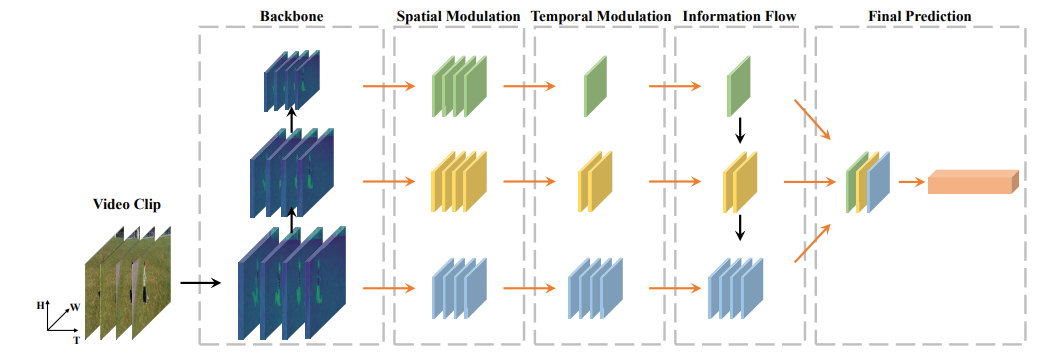
提出motion excitation (ME) 模塊 和 multiple temporal aggregation (MTA) 模塊用于捕獲短程和長(zhǎng)程時(shí)域信息,提高動(dòng)作識(shí)別的速度和精度。
TEA: Temporal Excitation and Aggregation for Action Recognition
作者 |?Yan Li, Bin Ji, Xintian Shi, Jianguo Zhang, Bin Kang, Limin Wang
單位 | 騰訊;南京大學(xué);南方科技大學(xué)
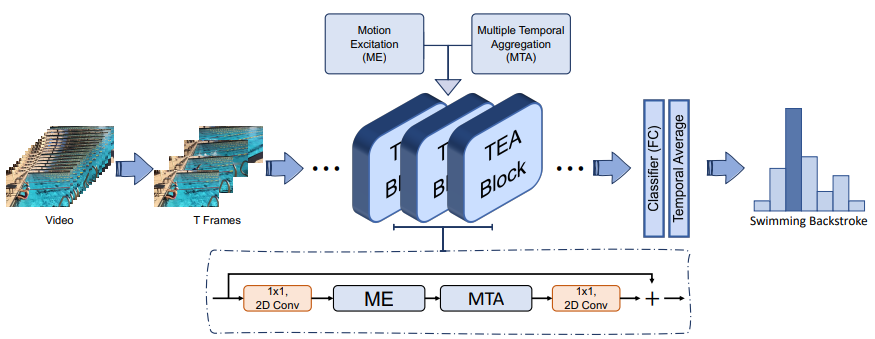
提取視頻特征往往需要計(jì)算密集的3D CNN操作,該文發(fā)明一種 Gate-Shift Module (GSM) 模塊利用分組空間選通方法控制時(shí)空分解交互,大大降低了視頻動(dòng)作識(shí)別算法復(fù)雜度。
Gate-Shift Networks for Video Action Recognition
作者 |?Swathikiran Sudhakaran, Sergio Escalera, Oswald Lanz
單位 | FBK,Trento, Italy;巴塞羅那大學(xué)
代碼 |?https://github.com/swathikirans/GSM

高效視頻識(shí)別的擴(kuò)展架構(gòu),降低參數(shù)量減少計(jì)算量
X3D: Expanding Architectures for Efficient Video Recognition
作者?|?Christoph Feichtenhofer
單位 |?FAIR
代碼 |?https://github.com/facebookresearch/SlowFast
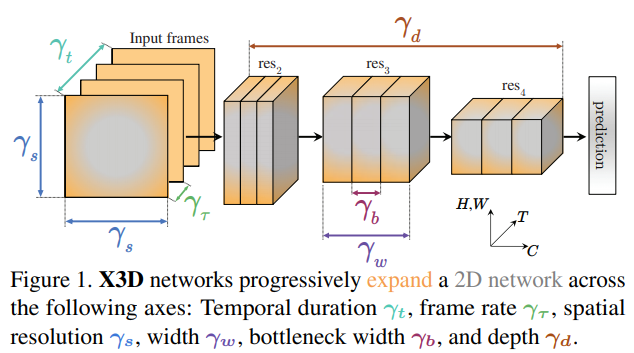
???3D CNN的正則化
該文提出一種簡(jiǎn)單有效的針對(duì)3D CNN 的正則化方法:Random Mean Scaling (RMS),防止過(guò)擬合。
Regularization on Spatio-Temporally Smoothed Feature for Action Recognition
作者 |?Jinhyung Kim, Seunghwan Cha, Dongyoon Wee, Soonmin Bae, Junmo Kim
單位 | KAIST;卡內(nèi)基梅隆大學(xué);Clova AI, NAVER Corp

?? 結(jié)合視覺(jué)、語(yǔ)音、文本的動(dòng)作識(shí)別
動(dòng)作識(shí)別的跨模態(tài)監(jiān)督信息提取(文本-語(yǔ)音-視覺(jué)識(shí)別的結(jié)合)
該文研究了一個(gè)非常有意思的問(wèn)題,通過(guò)電影視頻中語(yǔ)音與對(duì)應(yīng)臺(tái)詞構(gòu)建一個(gè)動(dòng)作識(shí)別的分類器,然后用此模型對(duì)大規(guī)模的視頻數(shù)據(jù)集進(jìn)行了弱監(jiān)督標(biāo)注,使用此標(biāo)注數(shù)據(jù)訓(xùn)練的模型在動(dòng)作識(shí)別問(wèn)題中取得了superior的精度。
Speech2Action: Cross-Modal Supervision for Action Recognition
作者 |?Arsha Nagrani, Chen Sun, David Ross, Rahul Sukthankar, Cordelia Schmid, Andrew?Zisserman
單位 | VGG, Oxford;谷歌;DeepMind

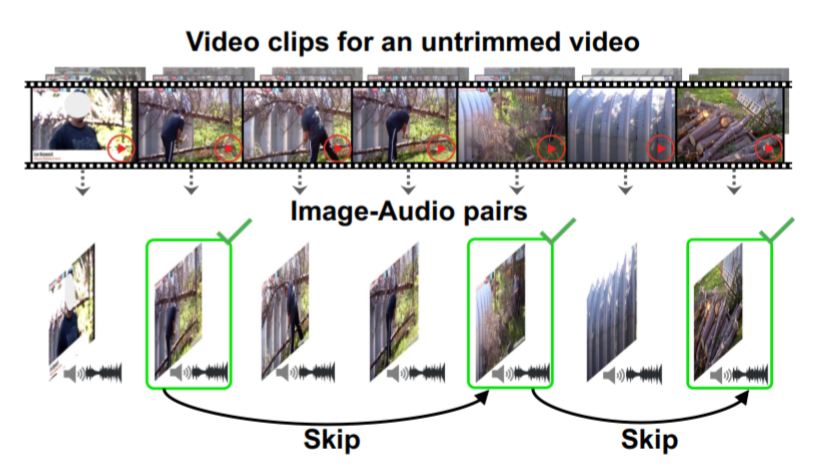
面對(duì)視頻分類中巨大的數(shù)據(jù)冗余,該文提出圖像-音頻對(duì)的概念,圖像表示了視頻中絕大部分表觀信息,音頻表示了視頻中的動(dòng)態(tài)信息,找到這些圖像-音頻對(duì)后再選擇一部分用于視頻分類,精度達(dá)到SOTA,還大大提高了動(dòng)作識(shí)別的速度。
Listen to Look: Action Recognition by Previewing Audio
作者 |?Ruohan Gao, Tae-Hyun Oh, Kristen Grauman, Lorenzo Torresani
單位 | 得克薩斯大學(xué)奧斯汀分校;FAIR
代碼 |?https://github.com/facebookresearch/Listen-to-Look
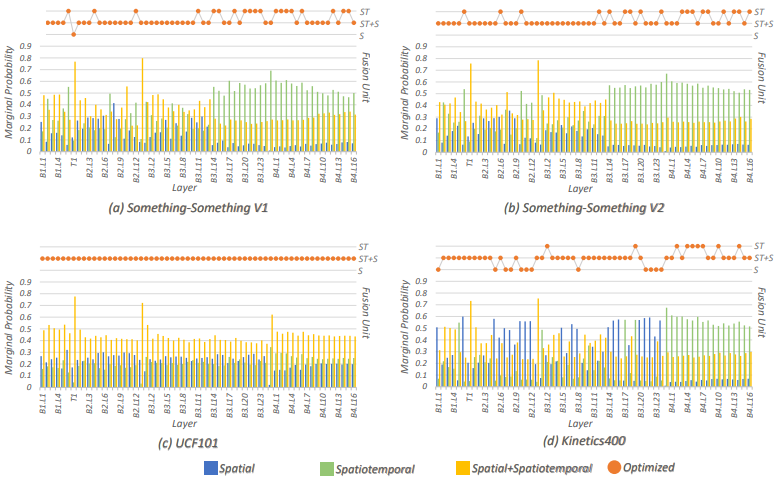
?? 動(dòng)作識(shí)別中的時(shí)空信息融合
如何在動(dòng)作識(shí)別中進(jìn)行更好的時(shí)空信息融合是涉及更好的動(dòng)作識(shí)別算法的關(guān)鍵,該文提出在概率空間理解、分析時(shí)空融合策略,大大提高分析效率,并提出新的融合策略,實(shí)驗(yàn)證明該策略大大提高了識(shí)別精度。
Spatiotemporal Fusion in 3D CNNs: A Probabilistic View
作者 |?Yizhou Zhou,?Xiaoyan Sun,?Chong Luo,?Zheng-Jun Zha,?Wenjun Zeng
單位 |?中國(guó)科學(xué)技術(shù)大學(xué);微軟亞洲研究院
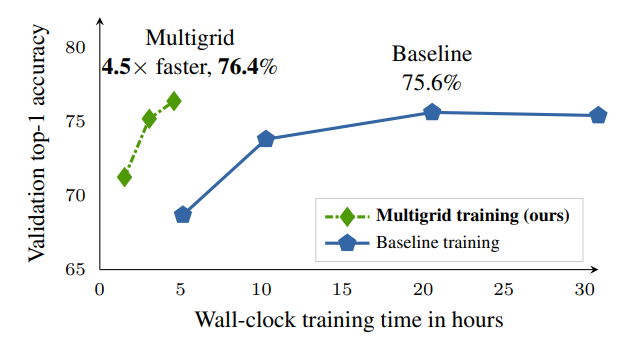
?? 視頻模型訓(xùn)練策略
何愷明團(tuán)隊(duì)作品。該文提出一種多網(wǎng)格訓(xùn)練策略訓(xùn)練視頻分類模型,大大降低訓(xùn)練時(shí)間,精度得以保持,甚至還有提高。
A Multigrid Method for Efficiently Training Video Models
作者 |?Chao-Yuan Wu,?Ross Girshick,?Kaiming He,?Christoph Feichtenhofer,?Philipp Krahenbuhl
單位 |?得克薩斯大學(xué)奧斯汀分校;FAIR
代碼|?https://github.com/facebookresearch/SlowFast
解讀 |?https://zhuanlan.zhihu.com/p/105287699
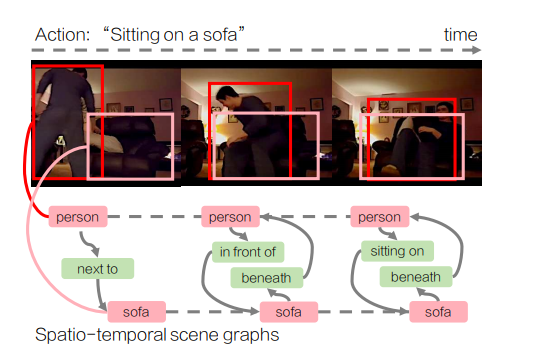
?? 少樣本視頻分類
李飛飛團(tuán)隊(duì)作品。該文提出動(dòng)作基因組(Action?Genome)的概念,將動(dòng)作看作時(shí)空?qǐng)鼍皥D的組合,在少樣本的動(dòng)作識(shí)別問(wèn)題中提高了精度。
Action Genome: Actions As Compositions of Spatio-Temporal Scene Graphs
作者 |?Jingwei Ji,?Ranjay Krishna,?Li Fei-Fei,?Juan Carlos Niebles
單位 |?斯坦福大學(xué)
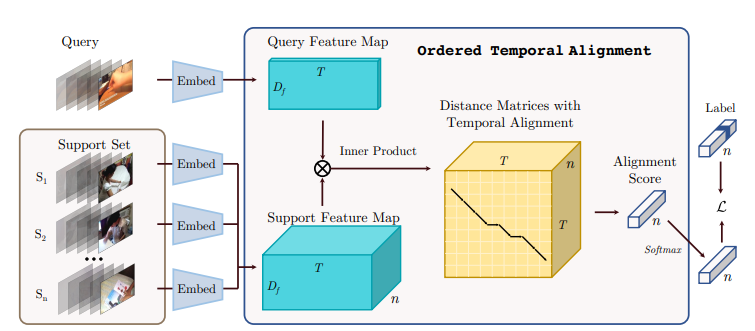
通過(guò)視頻信號(hào)的時(shí)序校正模塊提高少樣本的視頻分類精度
Few-Shot?Video Classification?via Temporal Alignment
作者 |?Kaidi Cao,?Jingwei Ji,?Zhangjie Cao,?Chien-Yi Chang,?Juan Carlos Niebles
單位 | 斯坦福大學(xué)
?? 基于視頻的無(wú)監(jiān)督表示學(xué)習(xí)
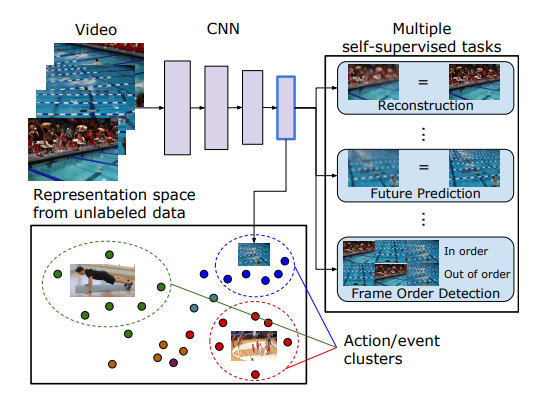
無(wú)監(jiān)督嵌入的視頻表示學(xué)習(xí)。因?yàn)橐曨l中含有豐富的動(dòng)態(tài)結(jié)構(gòu)信息,而且無(wú)處不在,所以是無(wú)監(jiān)督視覺(jué)表示學(xué)習(xí)的最佳素材。本文在視頻中學(xué)習(xí)視覺(jué)嵌入,使得在嵌入空間相似視頻距離近,而無(wú)關(guān)視頻距離遠(yuǎn)。在大量視頻中所學(xué)習(xí)的視覺(jué)表示可大幅提高動(dòng)作識(shí)別、圖像分類的精度。
(感覺(jué)這個(gè)工作很有價(jià)值,代碼開(kāi)源,值得follow)
Unsupervised Learning From Video With Deep Neural Embeddings
作者 |?Chengxu Zhuang,?Tianwei She,?Alex Andonian,?Max Sobol Mark,?Daniel Yamins
單位 |?斯坦福大學(xué);MIT
代碼 |?https://github.com/neuroailab/VIE
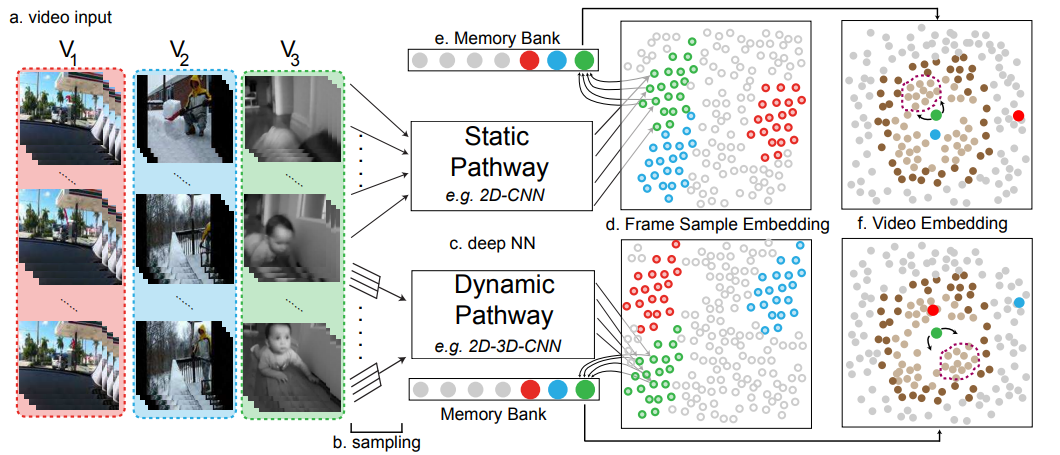
同上一篇,同樣是希望在大規(guī)模視頻數(shù)據(jù)中學(xué)習(xí)視覺(jué)表示。
?? 合成動(dòng)作識(shí)別
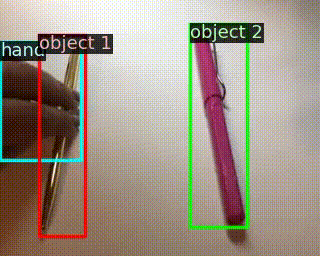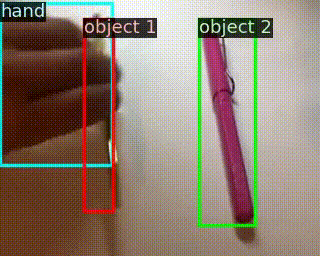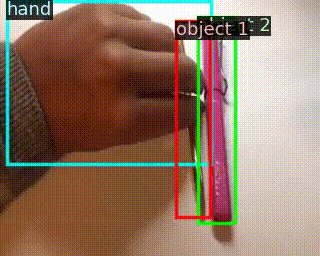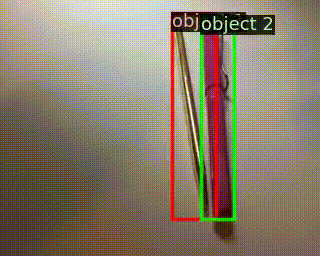
用于識(shí)別訓(xùn)練集沒(méi)有的,對(duì)操作物體進(jìn)行替換的動(dòng)作
Something-Else: Compositional Action Recognition With Spatial-Temporal Interaction Networks
作者 |?Joanna Materzynska, Tete Xiao, Roei Herzig, Huijuan Xu, Xiaolong Wang, Trevor Darrell
單位 | 牛津大學(xué);伯克利;以色列特拉維夫大學(xué)
代碼 |?https://github.com/joaanna/something_else
主頁(yè) |?https://joaanna.github.io/something_else/
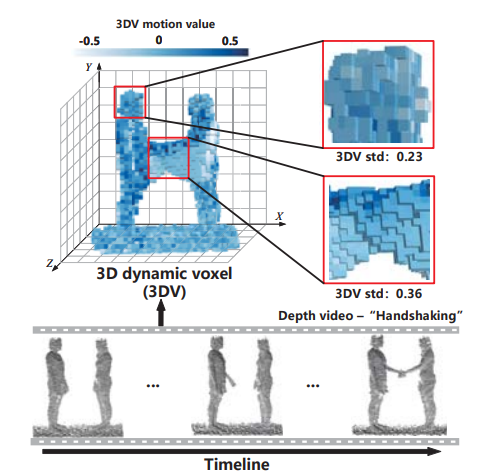
?? 深度視頻的動(dòng)作識(shí)別
3DV: 3D Dynamic Voxel for Action Recognition in Depth Video
作者 |?Yancheng Wang, Yang Xiao, Fu Xiong, Wenxiang Jiang, Zhiguo Cao, Joey Tianyi Zhou, Junsong Yuan
單位 | 華中科技大學(xué);曠視;A*STAR等
代碼?|?https://github.com/3huo/3DV-Action
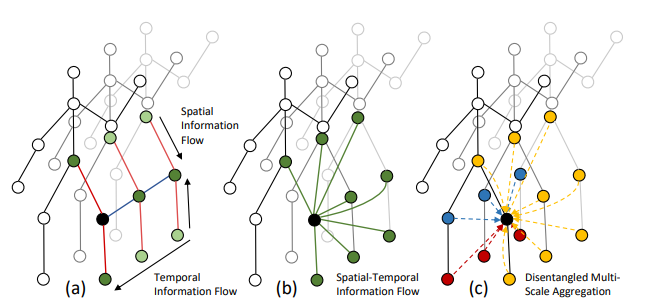
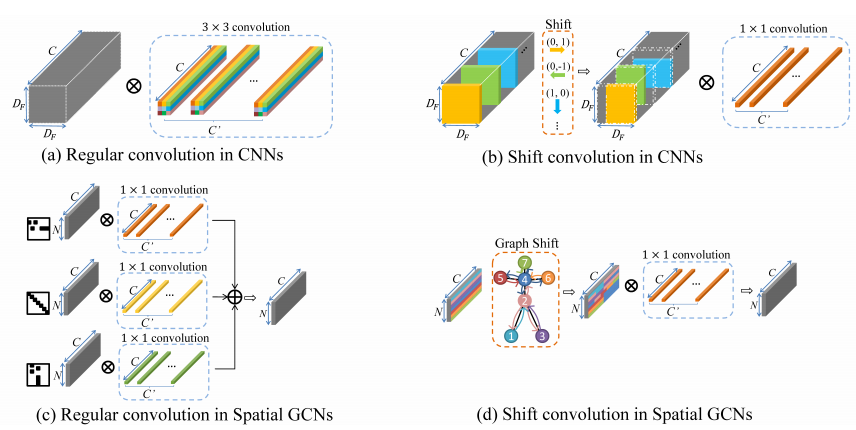
???基于骨架的動(dòng)作識(shí)別
Skeleton-Based的動(dòng)作識(shí)別,基于圖卷積方法
Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition
作者 |?Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, Wanli Ouyang
單位 | 悉尼大學(xué);國(guó)科大&CASIA;悉尼大學(xué)計(jì)算機(jī)視覺(jué)研究小組
代碼?|?https://github.com/kenziyuliu/ms-g3d
Skeleton-Based動(dòng)作識(shí)別,Shift Graph卷積網(wǎng)絡(luò)方法
Skeleton-Based Action Recognition With Shift Graph Convolutional Network
作者 |?Ke Cheng, Yifan Zhang, Xiangyu He, Weihan Chen, Jian Cheng, Hanqing Lu
單位 | 中科院;國(guó)科大等
代碼?|?https://github.com/kchengiva/Shift-GCN
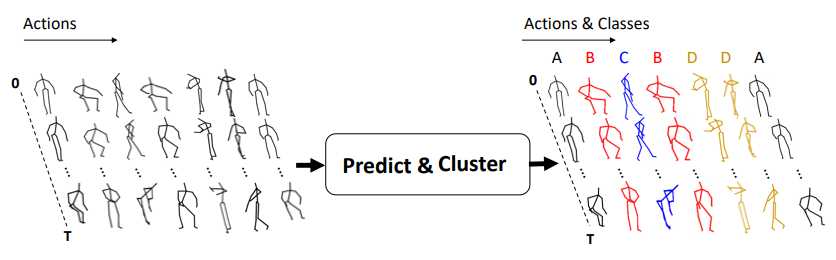
無(wú)監(jiān)督Skeleton-Based的動(dòng)作識(shí)別。該文提出一種編碼器-解碼器的RNN模型,可進(jìn)行無(wú)監(jiān)督的聚類,而此聚類結(jié)果可關(guān)聯(lián)動(dòng)作的類別,即也可以可以堪為預(yù)測(cè)。
此無(wú)監(jiān)督方法在基于骨架的動(dòng)作識(shí)別中取得了與監(jiān)督學(xué)習(xí)方法相相近的精度!
(也許表明:人體動(dòng)作本身類間差異就足夠大?)
PREDICT & CLUSTER: Unsupervised Skeleton Based Action Recognition
作者 |?Kun Su, Xiulong Liu, Eli Shlizerman
單位 |?華盛頓大學(xué)
代碼 |?https://github.com/shlizee/Predict-Cluster
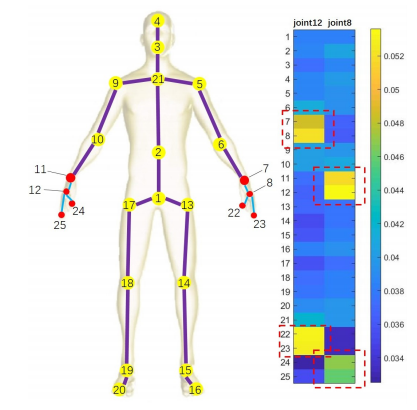
語(yǔ)義引導(dǎo)的神經(jīng)網(wǎng)絡(luò),用于Skeleton-Based人類動(dòng)作識(shí)別,SGN 方案僅需非常小的參數(shù)量(僅0.69M)就實(shí)現(xiàn)了很高的識(shí)別精度。
Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
作者 | Pengfei Zhang,?Cuiling Lan,?Wenjun Zeng,?Junliang Xing,?Jianru Xue,?Nanning Zheng
單位 | 西安交通大學(xué);微軟亞洲研究院;中科院自動(dòng)化所
代碼 | https://github.com/microsoft/SGN
上下文感知的圖卷積,用于Skeleton-Based動(dòng)作識(shí)別
Context Aware Graph Convolution for Skeleton-Based Action Recognition
作者 |?Xikun Zhang, Chang Xu, Dacheng Tao
單位 | UBTECH Sydney AI Centre;悉尼大學(xué)
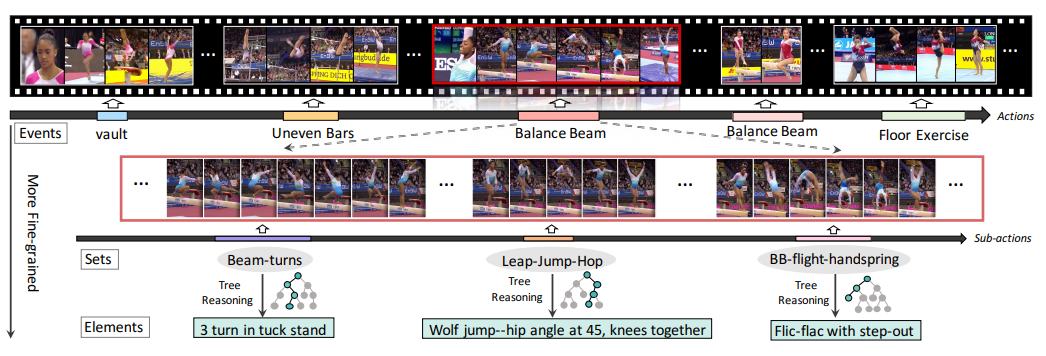
?? 數(shù)據(jù)集
面向細(xì)粒度動(dòng)作分析的層級(jí)化高質(zhì)量數(shù)據(jù)集
FineGym: A Hierarchical Video Dataset for Fine-Grained Action Understanding
作者 |?Dian Shao, Yue Zhao, Bo Dai, Dahua Lin
單位 | 香港中文大學(xué)與商湯聯(lián)合實(shí)驗(yàn)室?
代碼/數(shù)據(jù)?|?https://sdolivia.github.io/FineGym/
備注 | CVPR2020?Oral ,評(píng)審滿分論文
解讀?|?https://zhuanlan.zhihu.com/p/130720627
?
下載1:OpenCV黑魔法
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):OpenCV黑魔法,即可下載小編精心編寫(xiě)整理的計(jì)算機(jī)視覺(jué)趣味實(shí)戰(zhàn)教程
下載2 CVPR2020 在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):CVPR2020,即可下載1467篇CVPR?2020論文 個(gè)人微信(如果沒(méi)有備注不拉群!) 請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱

覺(jué)得有趣就點(diǎn)亮在看吧
