
【深度學(xué)習(xí)】一文看懂 (Transfer Learning)遷移學(xué)習(xí)(pytorch實(shí)現(xiàn))
前言
你會(huì)發(fā)現(xiàn)聰明人都喜歡”偷懶”, 因?yàn)檫@樣的偷懶能幫我們節(jié)省大量的時(shí)間, 提高效率. 還有一種偷懶是 “站在巨人的肩膀上”. 不僅能看得更遠(yuǎn), 還能看到更多. 這也用來表達(dá)我們要善于學(xué)習(xí)先輩的經(jīng)驗(yàn), 一個(gè)人的成功往往還取決于先輩們累積的知識(shí). 這句話, 放在機(jī)器學(xué)習(xí)中, 這就是今天要說的遷移學(xué)習(xí)了, transfer learning.
什么是遷移學(xué)習(xí)?
遷移學(xué)習(xí)通俗來講,就是運(yùn)用已有的知識(shí)來學(xué)習(xí)新的知識(shí),核心是找到已有知識(shí)和新知識(shí)之間的相似性,用成語(yǔ)來說就是舉一反三。由于直接對(duì)目標(biāo)域從頭開始學(xué)習(xí)成本太高,我們故而轉(zhuǎn)向運(yùn)用已有的相關(guān)知識(shí)來輔助盡快地學(xué)習(xí)新知識(shí)。比如,已經(jīng)會(huì)下中國(guó)象棋,就可以類比著來學(xué)習(xí)國(guó)際象棋;已經(jīng)會(huì)編寫Java程序,就可以類比著來學(xué)習(xí)C#;已經(jīng)學(xué)會(huì)英語(yǔ),就可以類比著來學(xué)習(xí)法語(yǔ);等等。世間萬事萬物皆有共性,如何合理地找尋它們之間的相似性,進(jìn)而利用這個(gè)橋梁來幫助學(xué)習(xí)新知識(shí),是遷移學(xué)習(xí)的核心問題。
為什么需要遷移學(xué)習(xí)?
 現(xiàn)在的機(jī)器人視覺已經(jīng)非常先進(jìn)了, 有些甚至超過了人類. 99.99%的識(shí)別準(zhǔn)確率都不在話下. 這樣的成功, 依賴于強(qiáng)大的機(jī)器學(xué)習(xí)技術(shù), 其中, 神經(jīng)網(wǎng)絡(luò)成為了領(lǐng)軍人物. 而 CNN 等, 像人一樣擁有千千萬萬個(gè)神經(jīng)聯(lián)結(jié)的結(jié)構(gòu), 為這種成功貢獻(xiàn)了巨大力量. 但是為了更厲害的 CNN, 我們的神經(jīng)網(wǎng)絡(luò)設(shè)計(jì), 也從簡(jiǎn)單的幾層網(wǎng)絡(luò), 變得越來越多, 越來越多, 越來越多… 為什么會(huì)越來越多?
現(xiàn)在的機(jī)器人視覺已經(jīng)非常先進(jìn)了, 有些甚至超過了人類. 99.99%的識(shí)別準(zhǔn)確率都不在話下. 這樣的成功, 依賴于強(qiáng)大的機(jī)器學(xué)習(xí)技術(shù), 其中, 神經(jīng)網(wǎng)絡(luò)成為了領(lǐng)軍人物. 而 CNN 等, 像人一樣擁有千千萬萬個(gè)神經(jīng)聯(lián)結(jié)的結(jié)構(gòu), 為這種成功貢獻(xiàn)了巨大力量. 但是為了更厲害的 CNN, 我們的神經(jīng)網(wǎng)絡(luò)設(shè)計(jì), 也從簡(jiǎn)單的幾層網(wǎng)絡(luò), 變得越來越多, 越來越多, 越來越多… 為什么會(huì)越來越多?
因?yàn)橛?jì)算機(jī)硬件, 比如 GPU 變得越來越強(qiáng)大, 能夠更快速地處理龐大的信息. 在同樣的時(shí)間內(nèi), 機(jī)器能學(xué)到更多東西. 可是, 不是所有人都擁有這么龐大的計(jì)算能力. 而且有時(shí)候面對(duì)類似的任務(wù)時(shí), 我們希望能夠借鑒已有的資源.
如何做遷移學(xué)習(xí)?
 這就好比, Google 和百度的關(guān)系, facebook 和人人的關(guān)系, KFC 和 麥當(dāng)勞的關(guān)系, 同一類型的事業(yè), 不用自己完全從頭做, 借鑒對(duì)方的經(jīng)驗(yàn), 往往能節(jié)省很多時(shí)間. 有這樣的思路, 我們也能偷偷懶, 不用花時(shí)間重新訓(xùn)練一個(gè)無比龐大的神經(jīng)網(wǎng)絡(luò), 借鑒借鑒一個(gè)已經(jīng)訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)就行.
這就好比, Google 和百度的關(guān)系, facebook 和人人的關(guān)系, KFC 和 麥當(dāng)勞的關(guān)系, 同一類型的事業(yè), 不用自己完全從頭做, 借鑒對(duì)方的經(jīng)驗(yàn), 往往能節(jié)省很多時(shí)間. 有這樣的思路, 我們也能偷偷懶, 不用花時(shí)間重新訓(xùn)練一個(gè)無比龐大的神經(jīng)網(wǎng)絡(luò), 借鑒借鑒一個(gè)已經(jīng)訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)就行.
 比如這樣的一個(gè)神經(jīng)網(wǎng)絡(luò), 我花了兩天訓(xùn)練完之后, 它已經(jīng)能正確區(qū)分圖片中具體描述的是男人, 女人還是眼鏡. 說明這個(gè)神經(jīng)網(wǎng)絡(luò)已經(jīng)具備對(duì)圖片信息一定的理解能力. 這些理解能力就以參數(shù)的形式存放在每一個(gè)神經(jīng)節(jié)點(diǎn)中. 不巧, 領(lǐng)導(dǎo)下達(dá)了一個(gè)緊急任務(wù),
比如這樣的一個(gè)神經(jīng)網(wǎng)絡(luò), 我花了兩天訓(xùn)練完之后, 它已經(jīng)能正確區(qū)分圖片中具體描述的是男人, 女人還是眼鏡. 說明這個(gè)神經(jīng)網(wǎng)絡(luò)已經(jīng)具備對(duì)圖片信息一定的理解能力. 這些理解能力就以參數(shù)的形式存放在每一個(gè)神經(jīng)節(jié)點(diǎn)中. 不巧, 領(lǐng)導(dǎo)下達(dá)了一個(gè)緊急任務(wù),
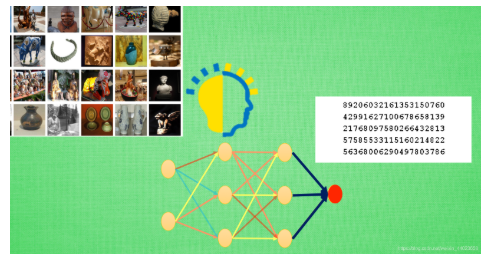
要求今天之內(nèi)訓(xùn)練出來一個(gè)預(yù)測(cè)圖片里實(shí)物價(jià)值的模型. 我想這可完蛋了, 上一個(gè)圖片模型都要花兩天, 如果要再搭個(gè)模型重新訓(xùn)練, 今天肯定出不來呀.
這時(shí), 遷移學(xué)習(xí)來拯救我了. 因?yàn)檫@個(gè)訓(xùn)練好的模型中已經(jīng)有了一些對(duì)圖片的理解能力, 而模型最后輸出層的作用是分類之前的圖片, 對(duì)于現(xiàn)在計(jì)算價(jià)值的任務(wù)是用不到的, #所以我將最后一層替換掉, 變?yōu)榉?wù)于現(xiàn)在這個(gè)任務(wù)的輸出層. #接著只訓(xùn)練新加的輸出層, 讓理解力保持始終不變. 前面的神經(jīng)層龐大的參數(shù)不用再訓(xùn)練, 節(jié)省了我很多時(shí)間, 我也在一天時(shí)間內(nèi), 將這個(gè)任務(wù)順利完成.
 但并不是所有時(shí)候我們都需要遷移學(xué)習(xí). 比如神經(jīng)網(wǎng)絡(luò)很簡(jiǎn)單, 相比起計(jì)算機(jī)視覺中龐大的 CNN 或者語(yǔ)音識(shí)別的 RNN, 訓(xùn)練小的神經(jīng)網(wǎng)絡(luò)并不需要特別多的時(shí)間, 我們完全可以直接重頭開始訓(xùn)練. 從頭開始訓(xùn)練也是有好處的.
但并不是所有時(shí)候我們都需要遷移學(xué)習(xí). 比如神經(jīng)網(wǎng)絡(luò)很簡(jiǎn)單, 相比起計(jì)算機(jī)視覺中龐大的 CNN 或者語(yǔ)音識(shí)別的 RNN, 訓(xùn)練小的神經(jīng)網(wǎng)絡(luò)并不需要特別多的時(shí)間, 我們完全可以直接重頭開始訓(xùn)練. 從頭開始訓(xùn)練也是有好處的.
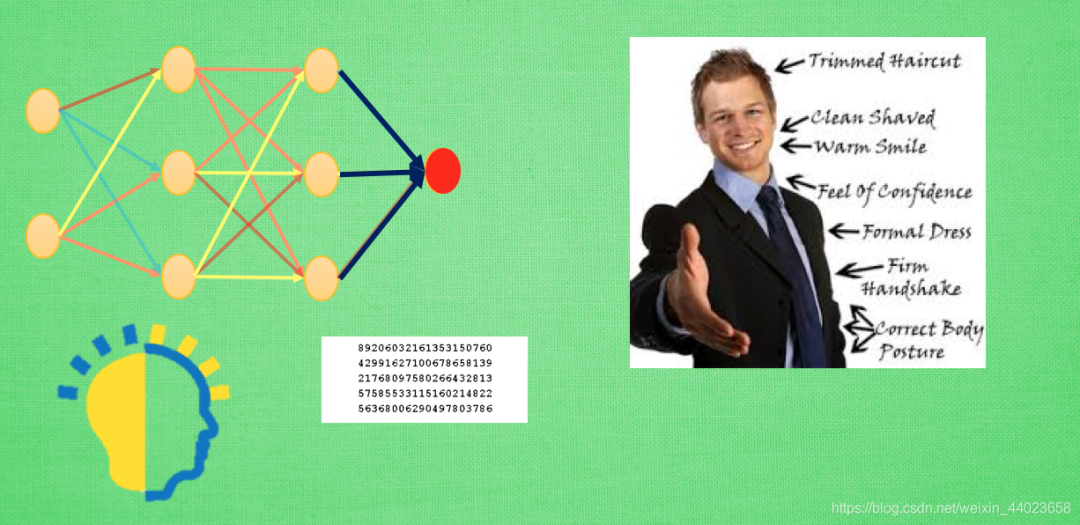 如果固定住之前的理解力, 或者使用更小的學(xué)習(xí)率來更新借鑒來的模型, 就變得有點(diǎn)像認(rèn)識(shí)一個(gè)人時(shí)的第一印象, 如果遷移前的數(shù)據(jù)和遷移后的數(shù)據(jù)差距很大, 或者說我對(duì)于這個(gè)人的第一印象和后續(xù)印象差距很大, 我還不如不要管我的第一印象, 同理, 這時(shí), 遷移來的模型并不會(huì)起多大作用, 還可能干擾我后續(xù)的決策.
如果固定住之前的理解力, 或者使用更小的學(xué)習(xí)率來更新借鑒來的模型, 就變得有點(diǎn)像認(rèn)識(shí)一個(gè)人時(shí)的第一印象, 如果遷移前的數(shù)據(jù)和遷移后的數(shù)據(jù)差距很大, 或者說我對(duì)于這個(gè)人的第一印象和后續(xù)印象差距很大, 我還不如不要管我的第一印象, 同理, 這時(shí), 遷移來的模型并不會(huì)起多大作用, 還可能干擾我后續(xù)的決策.
遷移學(xué)習(xí)的限制
比如說,我們不能隨意移除預(yù)訓(xùn)練網(wǎng)絡(luò)中的卷積層。但由于參數(shù)共享的關(guān)系,我們可以很輕松地在不同空間尺寸的圖像上運(yùn)行一個(gè)預(yù)訓(xùn)練網(wǎng)絡(luò)。這在卷積層和池化層和情況下是顯而易見的,因?yàn)樗鼈兊那跋蚝瘮?shù)(forward function)獨(dú)立于輸入內(nèi)容的空間尺寸。在全連接層(FC)的情形中,這仍然成立,因?yàn)槿B接層可被轉(zhuǎn)化成一個(gè)卷積層。所以當(dāng)我們導(dǎo)入一個(gè)預(yù)訓(xùn)練的模型時(shí),網(wǎng)絡(luò)結(jié)構(gòu)需要與預(yù)訓(xùn)練的網(wǎng)絡(luò)結(jié)構(gòu)相同,然后再針對(duì)特定的場(chǎng)景和任務(wù)進(jìn)行訓(xùn)練。
常見的遷移學(xué)習(xí)方式:
載權(quán)重后訓(xùn)練所有參數(shù) 載入權(quán)重后只訓(xùn)練最后幾層參數(shù) 載入權(quán)重后在原網(wǎng)絡(luò)基礎(chǔ)上再添加一層全鏈接層,僅訓(xùn)練最后一個(gè)全鏈接層
衍生
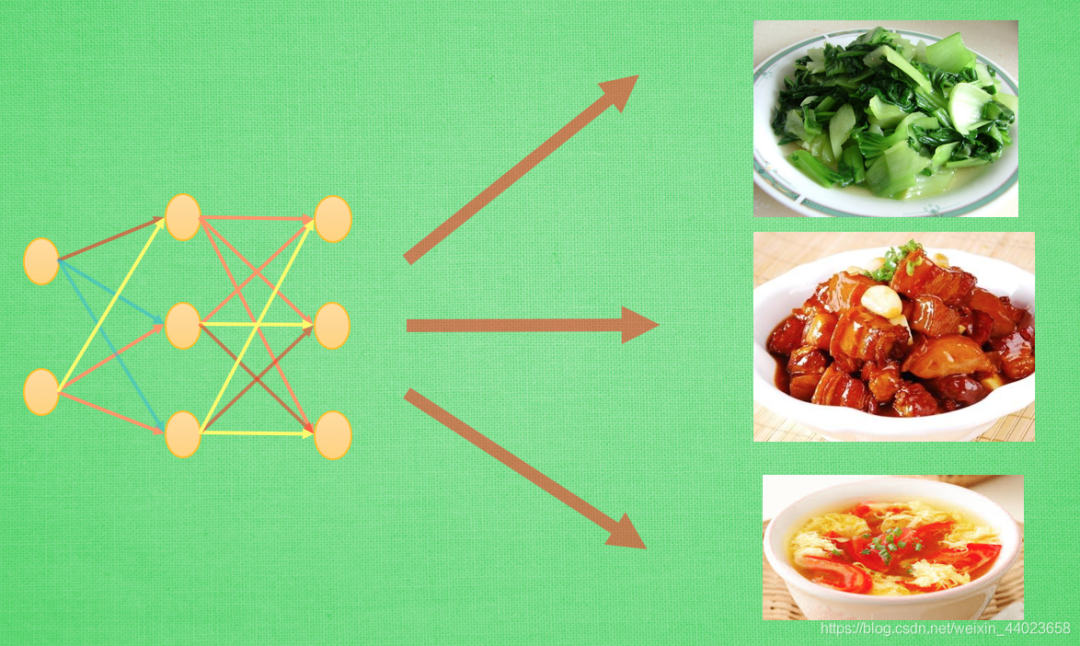 了解了一般的遷移學(xué)習(xí)玩法后, 我們看看前輩們還有哪些新玩法. 多任務(wù)學(xué)習(xí), 或者強(qiáng)化學(xué)習(xí)中的 learning to learn, 遷移機(jī)器人對(duì)運(yùn)作形式的理解, 解決不同的任務(wù). 炒個(gè)蔬菜, 紅燒肉, 番茄蛋花湯雖然菜色不同, 但是做菜的原則是類似的.
了解了一般的遷移學(xué)習(xí)玩法后, 我們看看前輩們還有哪些新玩法. 多任務(wù)學(xué)習(xí), 或者強(qiáng)化學(xué)習(xí)中的 learning to learn, 遷移機(jī)器人對(duì)運(yùn)作形式的理解, 解決不同的任務(wù). 炒個(gè)蔬菜, 紅燒肉, 番茄蛋花湯雖然菜色不同, 但是做菜的原則是類似的.
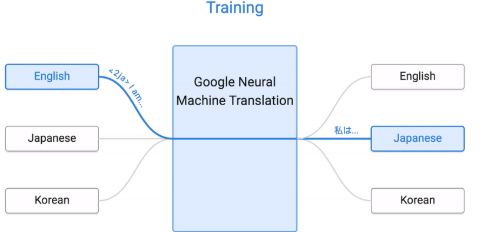
又或者 google 的翻譯模型, 在某些語(yǔ)言上訓(xùn)練, 產(chǎn)生出對(duì)語(yǔ)言的理解模型, 將這個(gè)理解模型當(dāng)做遷移模型在另外的語(yǔ)言上訓(xùn)練. 其實(shí)說白了, 那個(gè)遷移的模型就能看成機(jī)器自己發(fā)明的一種只有它自己才能看懂的語(yǔ)言. 然后用自己的這個(gè)語(yǔ)言模型當(dāng)成翻譯中轉(zhuǎn)站, 將某種語(yǔ)言轉(zhuǎn)成自己的語(yǔ)言, 然后再翻譯成另外的語(yǔ)言. 遷移學(xué)習(xí)的腦洞還有很多, 相信這種站在巨人肩膀上繼續(xù)學(xué)習(xí)的方法, 還會(huì)帶來更多有趣的應(yīng)用.
使用圖像數(shù)據(jù)進(jìn)行遷移學(xué)習(xí)
牛津 VGG 模型(http://www.robots.ox.ac.uk/~vgg/research/very_deep/) 谷歌 Inception模型(https://github.com/tensorflow/models/tree/master/inception) 微軟 ResNet 模型(https://github.com/KaimingHe/deep-residual-networks)
可以在 Caffe Model Zoo(https://github.com/BVLC/caffe/wiki/Model-Zoo)中找到更多的例子,那里分享了很多預(yù)訓(xùn)練的模型。
實(shí)例:
注:如何獲取官方的.pth文件,以resnet為例子
import torchvision.models.resnet
在腳本中輸入以上代碼,將鼠標(biāo)對(duì)住resnet并按ctrl鍵,發(fā)現(xiàn)改變顏色,點(diǎn)擊進(jìn)入resnet.py腳本,在最開始有url,如下圖所示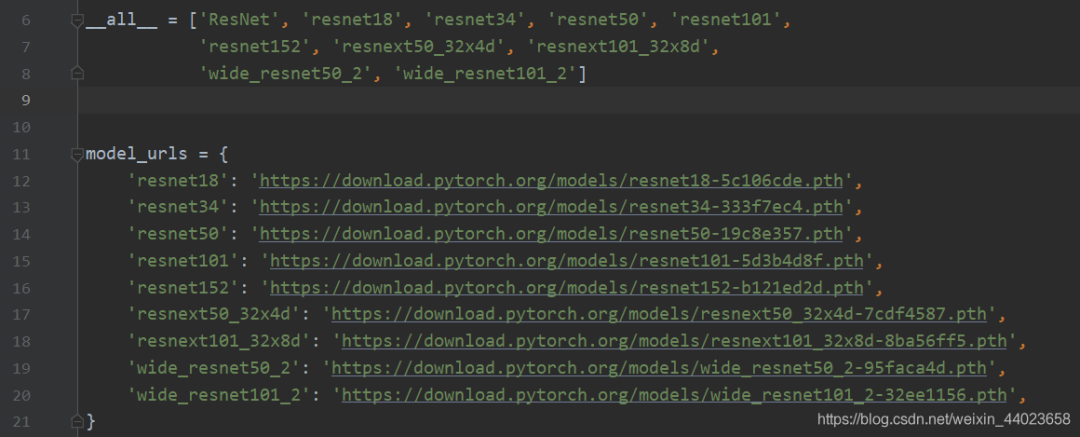 選擇你要下載的模型,copy到瀏覽器即可,若是覺得慢可以用迅雷等等。
選擇你要下載的模型,copy到瀏覽器即可,若是覺得慢可以用迅雷等等。
ResNet詳細(xì)講解在這篇博文里:ResNet——CNN經(jīng)典網(wǎng)絡(luò)模型詳解(pytorch實(shí)現(xiàn))
#train.py
import?torch
import?torch.nn?as?nn
from?torchvision?import?transforms,?datasets
import?json
import?matplotlib.pyplot?as?plt
import?os
import?torch.optim?as?optim
from?model?import?resnet34,?resnet101
import?torchvision.models.resnet
device?=?torch.device("cuda:0"?if?torch.cuda.is_available()?else?"cpu")
print(device)
data_transform?=?{
????"train":?transforms.Compose([transforms.RandomResizedCrop(224),
?????????????????????????????????transforms.RandomHorizontalFlip(),
?????????????????????????????????transforms.ToTensor(),
?????????????????????????????????transforms.Normalize([0.485,?0.456,?0.406],?[0.229,?0.224,?0.225])]),#來自官網(wǎng)參數(shù)
????"val":?transforms.Compose([transforms.Resize(256),#將最小邊長(zhǎng)縮放到256
???????????????????????????????transforms.CenterCrop(224),
???????????????????????????????transforms.ToTensor(),
???????????????????????????????transforms.Normalize([0.485,?0.456,?0.406],?[0.229,?0.224,?0.225])])}
data_root?=?os.getcwd()
image_path?=?data_root?+?"/flower_data/"??#?flower?data?set?path
train_dataset?=?datasets.ImageFolder(root=image_path?+?"train",
?????????????????????????????????????transform=data_transform["train"])
train_num?=?len(train_dataset)
#?{'daisy':0,?'dandelion':1,?'roses':2,?'sunflower':3,?'tulips':4}
flower_list?=?train_dataset.class_to_idx
cla_dict?=?dict((val,?key)?for?key,?val?in?flower_list.items())
#?write?dict?into?json?file
json_str?=?json.dumps(cla_dict,?indent=4)
with?open('class_indices.json',?'w')?as?json_file:
????json_file.write(json_str)
batch_size?=?16
train_loader?=?torch.utils.data.DataLoader(train_dataset,
???????????????????????????????????????????batch_size=batch_size,?shuffle=True,
???????????????????????????????????????????num_workers=0)
validate_dataset?=?datasets.ImageFolder(root=image_path?+?"/val",
????????????????????????????????????????transform=data_transform["val"])
val_num?=?len(validate_dataset)
validate_loader?=?torch.utils.data.DataLoader(validate_dataset,
??????????????????????????????????????????????batch_size=batch_size,?shuffle=False,
??????????????????????????????????????????????num_workers=0)
net?=?resnet34()
#?net?=?resnet34(num_classes=5)
#?load?pretrain?weights
model_weight_path?=?"./resnet34-pre.pth"
missing_keys,?unexpected_keys?=?net.load_state_dict(torch.load(model_weight_path),?strict=False)#載入模型參數(shù)
#?for?param?in?net.parameters():
#?????param.requires_grad?=?False
#?change?fc?layer?structure
inchannel?=?net.fc.in_features
net.fc?=?nn.Linear(inchannel,?5)
net.to(device)
loss_function?=?nn.CrossEntropyLoss()
optimizer?=?optim.Adam(net.parameters(),?lr=0.0001)
best_acc?=?0.0
save_path?=?'./resNet34.pth'
for?epoch?in?range(3):
????#?train
????net.train()
????running_loss?=?0.0
????for?step,?data?in?enumerate(train_loader,?start=0):
????????images,?labels?=?data
????????optimizer.zero_grad()
????????logits?=?net(images.to(device))
????????loss?=?loss_function(logits,?labels.to(device))
????????loss.backward()
????????optimizer.step()
????????#?print?statistics
????????running_loss?+=?loss.item()
????????#?print?train?process
????????rate?=?(step+1)/len(train_loader)
????????a?=?"*"?*?int(rate?*?50)
????????b?=?"."?*?int((1?-?rate)?*?50)
????????print("\rtrain?loss:?{:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100),?a,?b,?loss),?end="")
????print()
????#?validate
????net.eval()
????acc?=?0.0??#?accumulate?accurate?number?/?epoch
????with?torch.no_grad():
????????for?val_data?in?validate_loader:
????????????val_images,?val_labels?=?val_data
????????????outputs?=?net(val_images.to(device))??#?eval?model?only?have?last?output?layer
????????????#?loss?=?loss_function(outputs,?test_labels)
????????????predict_y?=?torch.max(outputs,?dim=1)[1]
????????????acc?+=?(predict_y?==?val_labels.to(device)).sum().item()
????????val_accurate?=?acc?/?val_num
????????if?val_accurate?>?best_acc:
????????????best_acc?=?val_accurate
????????????torch.save(net.state_dict(),?save_path)
????????print('[epoch?%d]?train_loss:?%.3f??test_accuracy:?%.3f'?%
??????????????(epoch?+?1,?running_loss?/?step,?val_accurate))
print('Finished?Training')
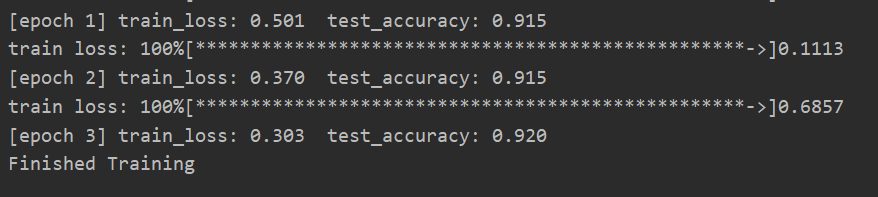 未使用遷移學(xué)習(xí)
未使用遷移學(xué)習(xí)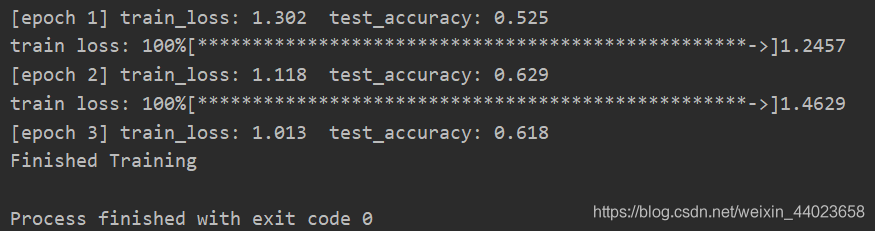 VGG16
VGG16
#train.py
import?torch.nn?as?nn
from?torchvision?import?transforms,?datasets
import?json
import?os
import?torch.optim?as?optim
from?model?import?vgg
import?torch
import?time
import?torchvision.models.vgg
from?torchvision?import?models
device?=?torch.device("cuda:0"?if?torch.cuda.is_available()?else?"cpu")
print(device)
#數(shù)據(jù)預(yù)處理,從頭
data_transform?=?{
????"train":?transforms.Compose([transforms.RandomResizedCrop(224),
?????????????????????????????????transforms.RandomHorizontalFlip(),
?????????????????????????????????transforms.ToTensor(),
?????????????????????????????????transforms.Normalize((0.5,?0.5,?0.5),?(0.5,?0.5,?0.5))]),
????"val":?transforms.Compose([transforms.Resize((224,?224)),
???????????????????????????????transforms.ToTensor(),
???????????????????????????????transforms.Normalize((0.5,?0.5,?0.5),?(0.5,?0.5,?0.5))])}
data_root?=?os.path.abspath(os.path.join(os.getcwd(),?"../../.."))??#?get?data?root?path
image_path?=?data_root?+?"/data_set/flower_data/"??#?flower?data?set?pathh
train_dataset?=?datasets.ImageFolder(root=image_path?+?"/train",
?????????????????????????????????????transform=data_transform["train"])
train_num?=?len(train_dataset)
#?{'daisy':0,?'dandelion':1,?'roses':2,?'sunflower':3,?'tulips':4}
flower_list?=?train_dataset.class_to_idx
cla_dict?=?dict((val,?key)?for?key,?val?in?flower_list.items())
#?write?dict?into?json?file
json_str?=?json.dumps(cla_dict,?indent=4)
with?open('class_indices.json',?'w')?as?json_file:
????json_file.write(json_str)
batch_size?=?20
train_loader?=?torch.utils.data.DataLoader(train_dataset,
???????????????????????????????????????????batch_size=batch_size,?shuffle=True,
???????????????????????????????????????????num_workers=0)
validate_dataset?=?datasets.ImageFolder(root=image_path?+?"val",
????????????????????????????????????????transform=data_transform["val"])
val_num?=?len(validate_dataset)
validate_loader?=?torch.utils.data.DataLoader(validate_dataset,
??????????????????????????????????????????????batch_size=batch_size,?shuffle=False,
??????????????????????????????????????????????num_workers=0)
#?test_data_iter?=?iter(validate_loader)
#?test_image,?test_label?=?test_data_iter.next()
#?model
#?=?models.vgg16(pretrained=True)
#
#?model_name?=?"vgg16"
#?net?=?vgg(model_name=model_name,?init_weights=True)
#?load?pretrain?weights
net?=?models.vgg16(pretrained=False)
pre?=?torch.load("./vgg16.pth")
net.load_state_dict(pre)
for?parma?in?net.parameters():
????parma.requires_grad?=?False
net.classifier?=?torch.nn.Sequential(torch.nn.Linear(25088,?4096),
???????????????????????????????????????torch.nn.ReLU(),
???????????????????????????????????????torch.nn.Dropout(p=0.5),
???????????????????????????????????????torch.nn.Linear(4096,?4096),
???????????????????????????????????????torch.nn.ReLU(),
???????????????????????????????????????torch.nn.Dropout(p=0.5),
???????????????????????????????????????torch.nn.Linear(4096,?5))
#?model_weight_path?=?"./vgg16.pth"
#?missing_keys,?unexpected_keys?=?net.load_state_dict(torch.load(model_weight_path),?strict=False)#載入模型參數(shù)
#?#?for?param?in?net.parameters():
#?#?????param.requires_grad?=?False
#?#?change?fc?layer?structure
#
#?inchannel?=?512
#?net.classifier?=?nn.Linear(inchannel,?5)
loss_function?=?torch.nn.CrossEntropyLoss()
optimizer?=?optim.Adam(net.classifier.parameters(),?lr=0.001)
#?loss_function?=?nn.CrossEntropyLoss()
#?optimizer?=?optim.Adam(net.parameters(),?lr=0.0001)?#learn?rate
net.to(device)
best_acc?=?0.0
#save_path?=?'./{}Net.pth'.format(model_name)
save_path?=?'./vgg16Net.pth'
for?epoch?in?range(15):
????#?train
????net.train()
????running_loss?=?0.0?#統(tǒng)計(jì)訓(xùn)練過程中的平均損失
????t1?=?time.perf_counter()
????for?step,?data?in?enumerate(train_loader,?start=0):
????????images,?labels?=?data
????????optimizer.zero_grad()
????????#with?torch.no_grad():?#用來消除驗(yàn)證階段的loss,由于梯度在驗(yàn)證階段不能傳回,造成梯度的累計(jì)
????????outputs?=?net(images.to(device))
????????loss?=?loss_function(outputs,?labels.to(device))??#得到預(yù)測(cè)值與真實(shí)值的一個(gè)損失
????????loss.backward()
????????optimizer.step()#更新結(jié)點(diǎn)參數(shù)
????????#?print?statistics
????????running_loss?+=?loss.item()
????????#?print?train?process
????????rate?=?(step?+?1)?/?len(train_loader)
????????a?=?"*"?*?int(rate?*?50)
????????b?=?"."?*?int((1?-?rate)?*?50)
????????print("\rtrain?loss:?{:^3.0f}%[{}->{}]{:.3f}".format(int(rate?*?100),?a,?b,?loss),?end="")
????print()
????print(time.perf_counter()?-?t1)
????#?validate
????net.eval()
????acc?=?0.0??#?accumulate?accurate?number?/?epoch
????with?torch.no_grad():#不去跟蹤損失梯度
????????for?val_data?in?validate_loader:
????????????val_images,?val_labels?=?val_data
????????????#optimizer.zero_grad()
????????????outputs?=?net(val_images.to(device))
????????????predict_y?=?torch.max(outputs,?dim=1)[1]
????????????acc?+=?(predict_y?==?val_labels.to(device)).sum().item()
????????val_accurate?=?acc?/?val_num
????????if?val_accurate?>?best_acc:
????????????best_acc?=?val_accurate
????????????torch.save(net.state_dict(),?save_path)
????????print('[epoch?%d]?train_loss:?%.3f??test_accuracy:?%.3f'?%
??????????????(epoch?+?1,?running_loss?/?step,?val_accurate))
print('Finished?Training')
densenet121
#train.py
import?torch
import?torch.nn?as?nn
from?torchvision?import?transforms,?datasets
import?json
import?matplotlib.pyplot?as?plt
from?model?import?densenet121
import?os
import?torch.optim?as?optim
import?torchvision.models.densenet
import?torchvision.models?as?models
device?=?torch.device("cuda:0"?if?torch.cuda.is_available()?else?"cpu")
print(device)
data_transform?=?{
????"train":?transforms.Compose([transforms.RandomResizedCrop(224),
?????????????????????????????????transforms.RandomHorizontalFlip(),
?????????????????????????????????transforms.ToTensor(),
?????????????????????????????????transforms.Normalize([0.485,?0.456,?0.406],?[0.229,?0.224,?0.225])]),#來自官網(wǎng)參數(shù)
????"val":?transforms.Compose([transforms.Resize(256),#將最小邊長(zhǎng)縮放到256
???????????????????????????????transforms.CenterCrop(224),
???????????????????????????????transforms.ToTensor(),
???????????????????????????????transforms.Normalize([0.485,?0.456,?0.406],?[0.229,?0.224,?0.225])])}
data_root?=?os.path.abspath(os.path.join(os.getcwd(),?"../../.."))??#?get?data?root?path
image_path?=?data_root?+?"/data_set/flower_data/"??#?flower?data?set?path
train_dataset?=?datasets.ImageFolder(root=image_path?+?"train",
?????????????????????????????????????transform=data_transform["train"])
train_num?=?len(train_dataset)
#?{'daisy':0,?'dandelion':1,?'roses':2,?'sunflower':3,?'tulips':4}
flower_list?=?train_dataset.class_to_idx
cla_dict?=?dict((val,?key)?for?key,?val?in?flower_list.items())
#?write?dict?into?json?file
json_str?=?json.dumps(cla_dict,?indent=4)
with?open('class_indices.json',?'w')?as?json_file:
????json_file.write(json_str)
batch_size?=?16
train_loader?=?torch.utils.data.DataLoader(train_dataset,
???????????????????????????????????????????batch_size=batch_size,?shuffle=True,
???????????????????????????????????????????num_workers=0)
validate_dataset?=?datasets.ImageFolder(root=image_path?+?"/val",
????????????????????????????????????????transform=data_transform["val"])
val_num?=?len(validate_dataset)
validate_loader?=?torch.utils.data.DataLoader(validate_dataset,
??????????????????????????????????????????????batch_size=batch_size,?shuffle=False,
??????????????????????????????????????????????num_workers=0)
#遷移學(xué)習(xí)
net?=?models.densenet121(pretrained=False)
model_weight_path="./densenet121-a.pth"
missing_keys,?unexpected_keys?=?net.load_state_dict(torch.load(model_weight_path),?strict=?False)
inchannel?=?net.classifier.in_features
net.classifier?=?nn.Linear(inchannel,?5)
net.to(device)
loss_function?=?nn.CrossEntropyLoss()
optimizer?=?optim.Adam(net.parameters(),?lr=0.0001)
#普通
#?model_name?=?"densenet121"
#?net?=?densenet121(model_name=model_name,?num_classes=5)
best_acc?=?0.0
save_path?=?'./densenet121.pth'
for?epoch?in?range(12):
????#?train
????net.train()
????running_loss?=?0.0
????for?step,?data?in?enumerate(train_loader,?start=0):
????????images,?labels?=?data
????????optimizer.zero_grad()
????????logits?=?net(images.to(device))
????????loss?=?loss_function(logits,?labels.to(device))
????????loss.backward()
????????optimizer.step()
????????#?print?statistics
????????running_loss?+=?loss.item()
????????#?print?train?process
????????rate?=?(step+1)/len(train_loader)
????????a?=?"*"?*?int(rate?*?50)
????????b?=?"."?*?int((1?-?rate)?*?50)
????????print("\rtrain?loss:?{:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100),?a,?b,?loss),?end="")
????print()
????#?validate
????net.eval()
????acc?=?0.0??#?accumulate?accurate?number?/?epoch
????with?torch.no_grad():
????????for?val_data?in?validate_loader:
????????????val_images,?val_labels?=?val_data
????????????outputs?=?net(val_images.to(device))??#?eval?model?only?have?last?output?layer
????????????#?loss?=?loss_function(outputs,?test_labels)
????????????predict_y?=?torch.max(outputs,?dim=1)[1]
????????????acc?+=?(predict_y?==?val_labels.to(device)).sum().item()
????????val_accurate?=?acc?/?val_num
????????if?val_accurate?>?best_acc:
????????????best_acc?=?val_accurate
????????????torch.save(net.state_dict(),?save_path)
????????print('[epoch?%d]?train_loss:?%.3f??test_accuracy:?%.3f'?%
??????????????(epoch?+?1,?running_loss?/?step,?val_accurate))
print('Finished?Training')
使用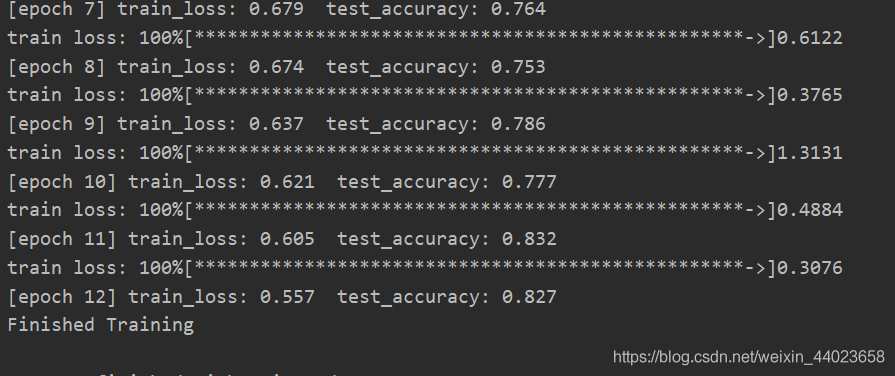
注:部分圖片來自于莫凡python
往期精彩回顧
獲取一折本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請(qǐng)掃碼進(jìn)群(如果是博士或者準(zhǔn)備讀博士請(qǐng)說明):